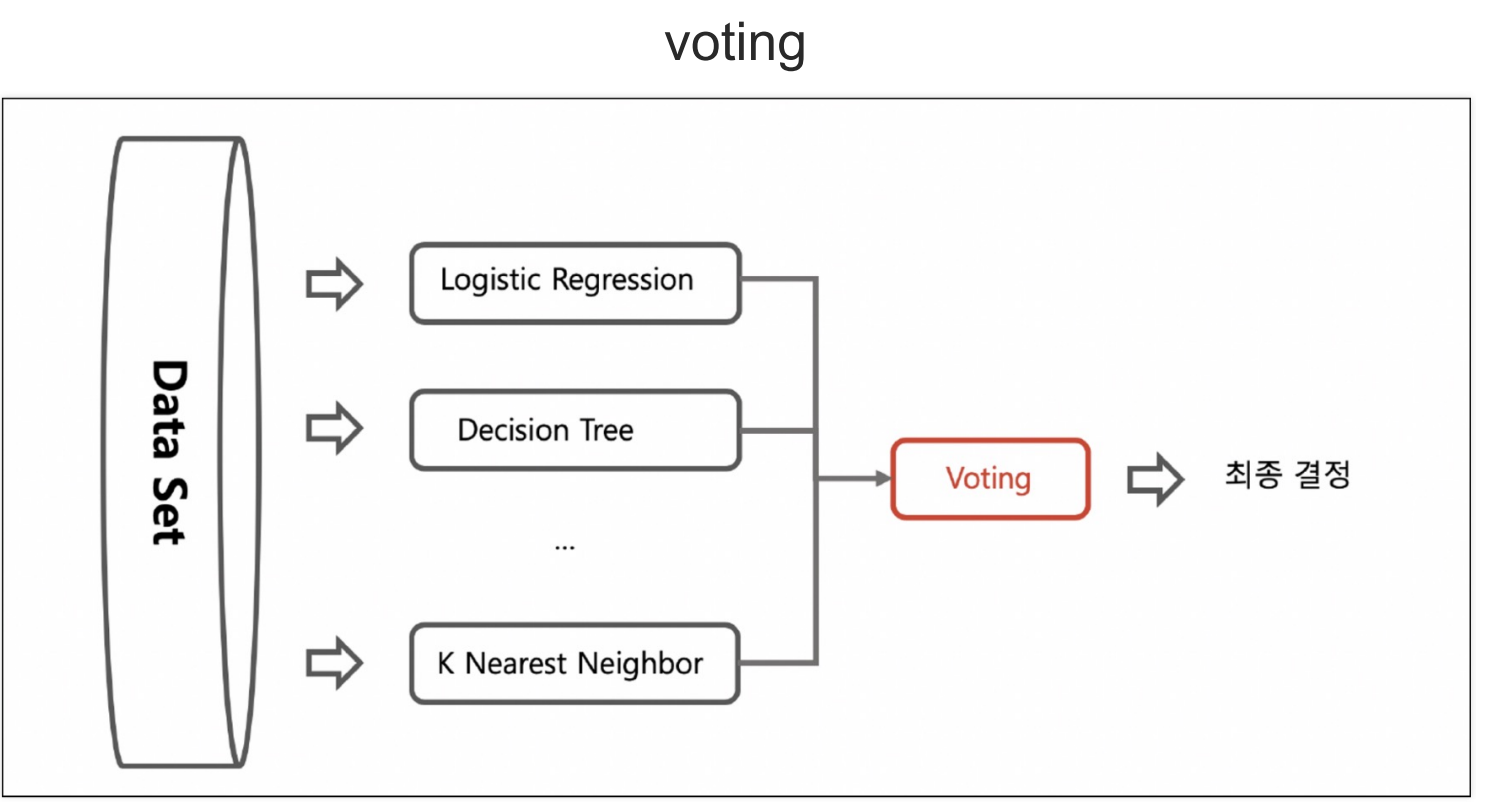
- 앙상블은 머신러닝을 모델링하는 과정에서 단일 알고리즘을 사용하는 것이 아니라, 여러 방법을 통해 성능을 올리는 것을 의미한다.
- 먼저 voting방식은 여러 모델링 기법을 구분해서 성능을 테스트 후 제일 좋은 성능의 기법을 사용하는 방법이다.
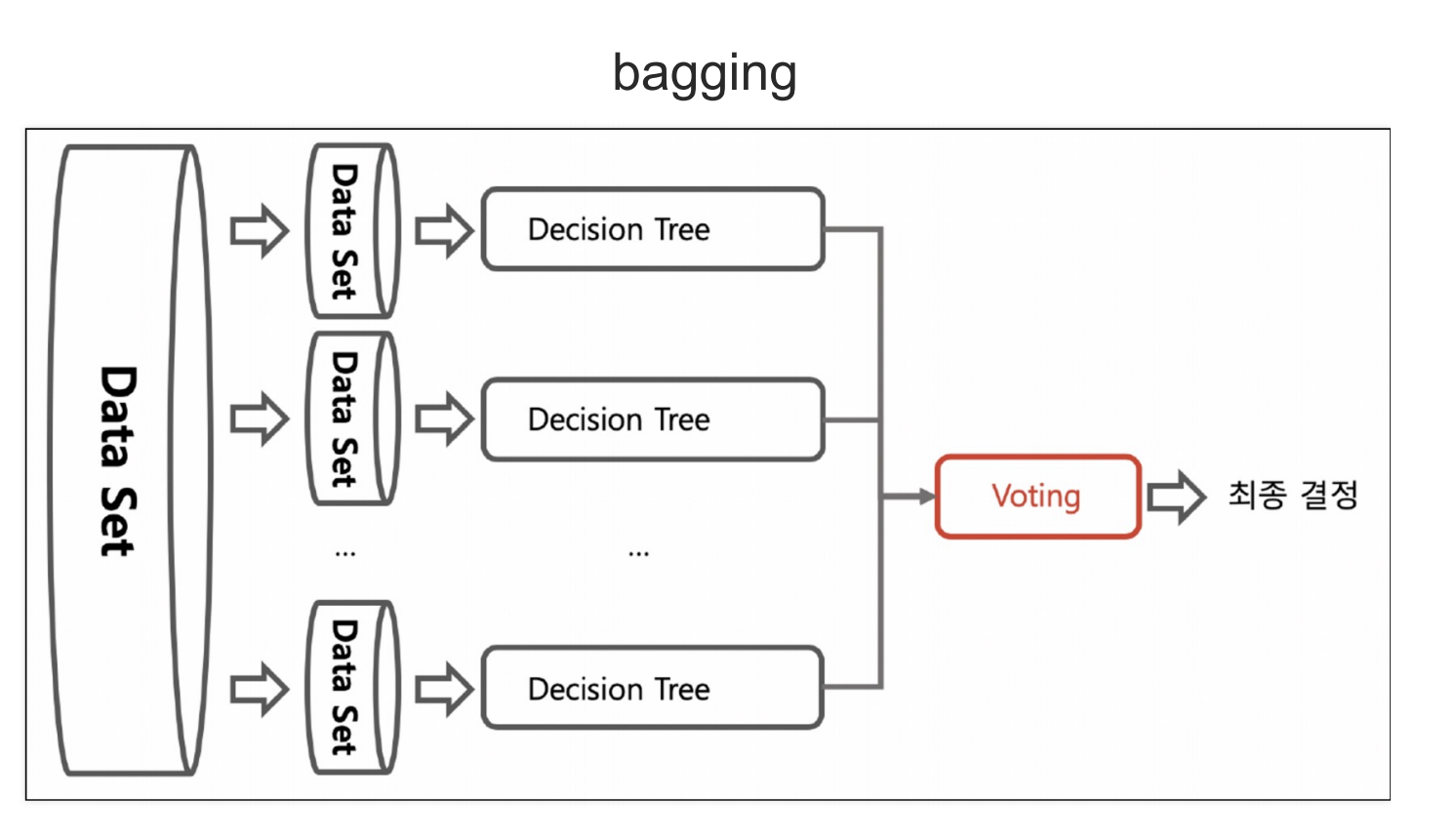
- bagging은 하나의 데이터셋을 여러 데이터셋으로 구분 후 각 데이터셋에서 모델링(DecisionTree)을 실행 후 성능을 비교 및 선택한다.
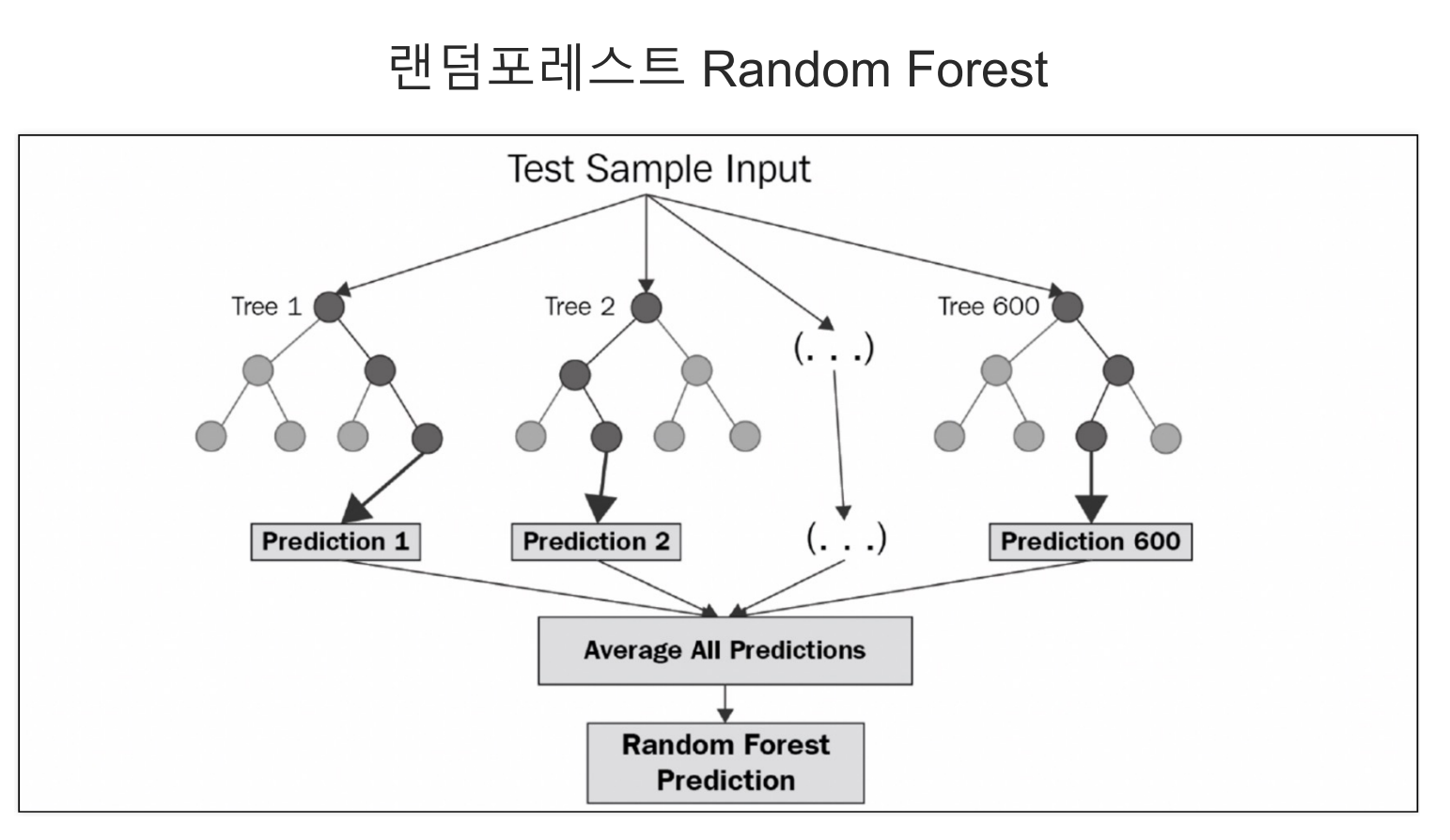
- 랜덤 포레스트는 bagging기법 중 하나로서 이 기법의 경우 성능도 좋게 나오고, 다양한 분야에서 사용이 가능하다.
- 여기서 중요한 포인트는 bagging과정에서 데이터의 중복을 허용하기 때문에 A셋에서 사용한 데이터를 B셋에서도 사용할 수 있다.
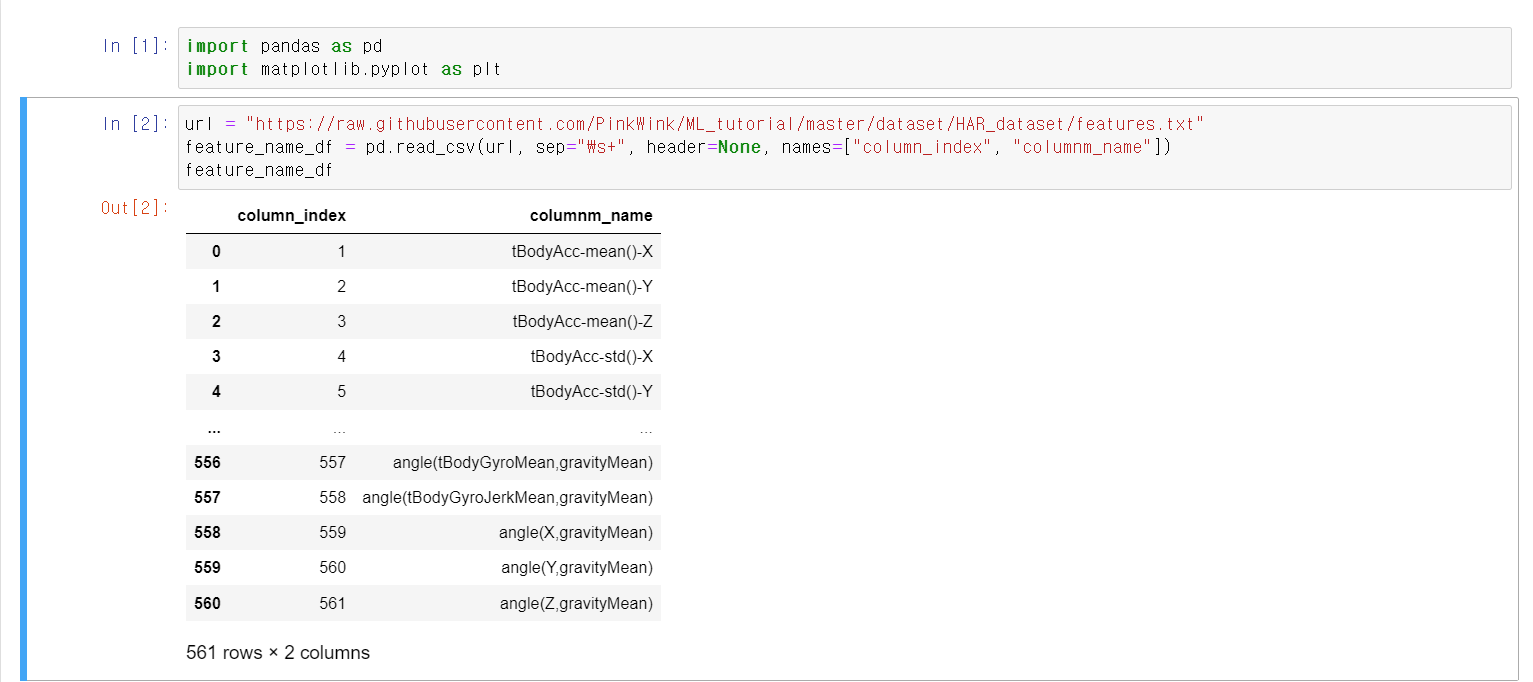
- 이제 실제 HAR(Human Activity Recognition)데이터를 통해 앙상블 머신러닝 기법을 사용해보자
- 먼저 feature_name_df 변수에 데이터에 사용할 column을 저장한다.
- 그리고 x, y에 대한 train, test 데이터를 업로드 후 데이터 자료를 확인한다.
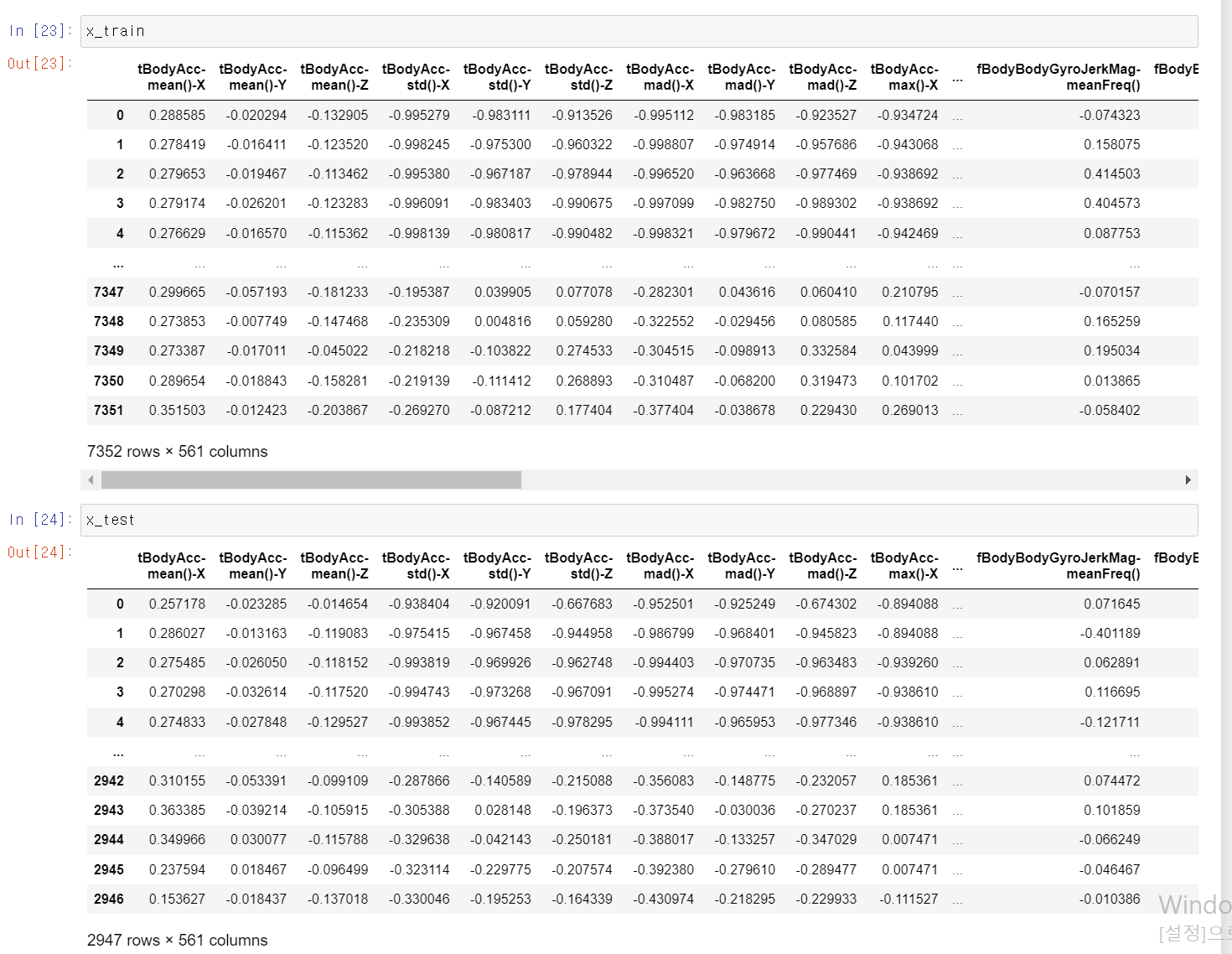
- 먼저 x데이터셋의 경우 train, test 모두 정상적으로 업로드됐다.
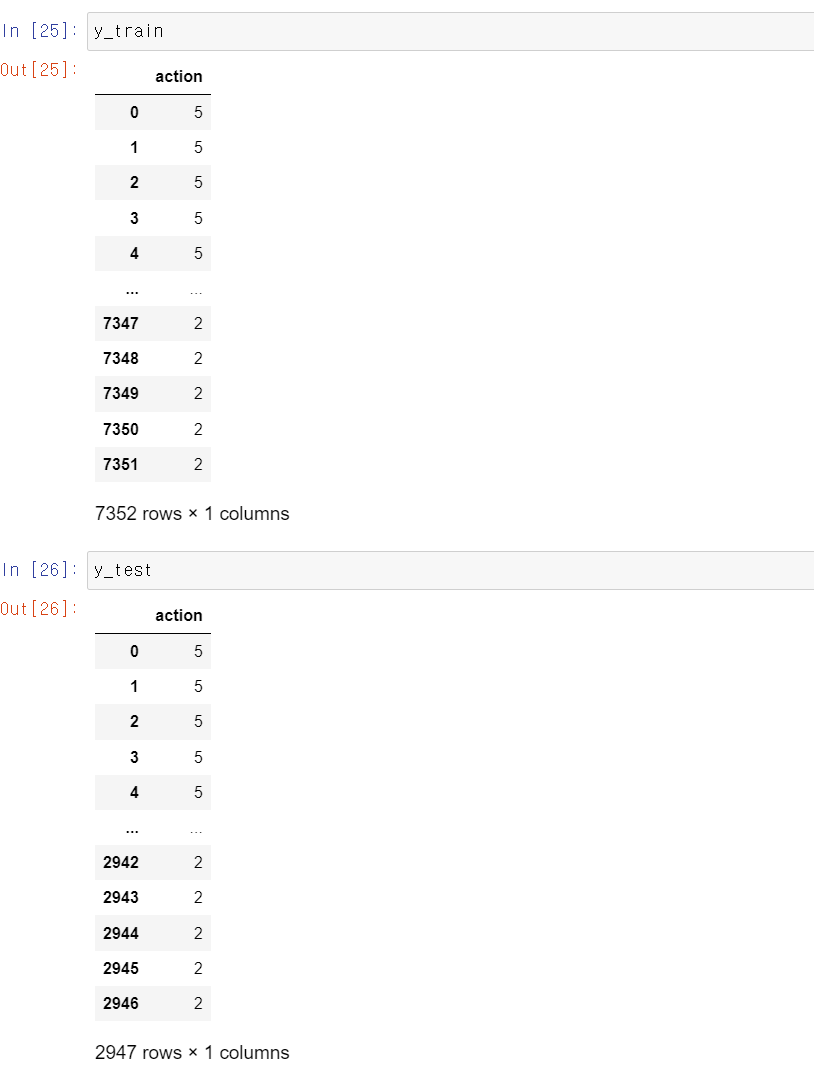
- y데이터셋도 라벨링을 사용하기에 맞춰서 정상적으로 업로드됐다.
- 참고로 action의 번호에 따라 행동이 구분되며, x데이터셋의 data에 따라 행동의 분류를 결정한다.
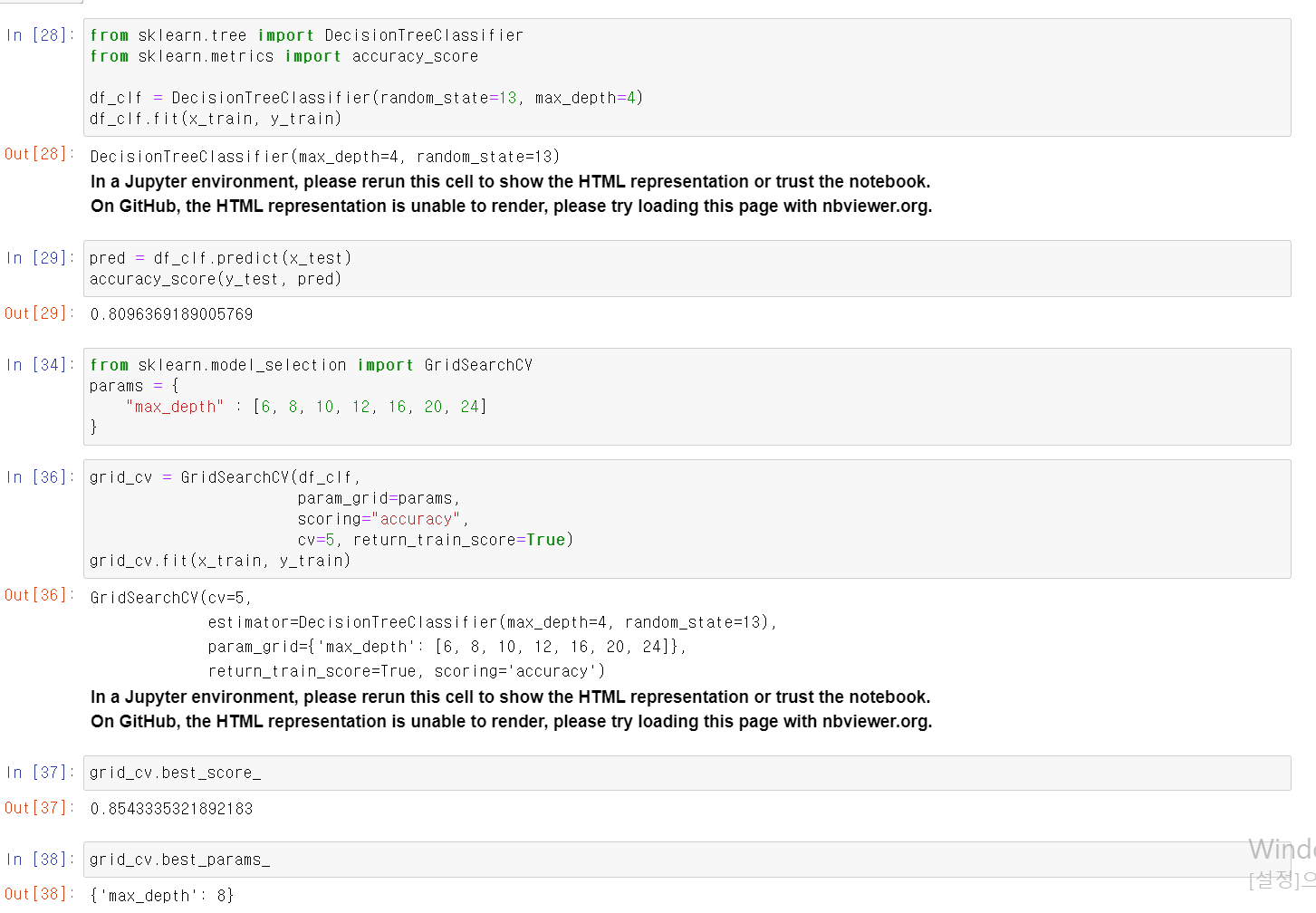
- 먼저 간단하게 DecisionTree를 통해 성능을 테스트한 결과 80%성능이 나온다.
- 그리고 GridSearchCV를 통해 max_depth를 6, 8, 10, 12, 16, 20, 24로 나눈 후 각 depth에 맞는 모델링을 교육시킨 후 성능을 테스트했다.
- 그 결과 max_depth 8에서 85%로 가장 좋은 성능이 나왔다.
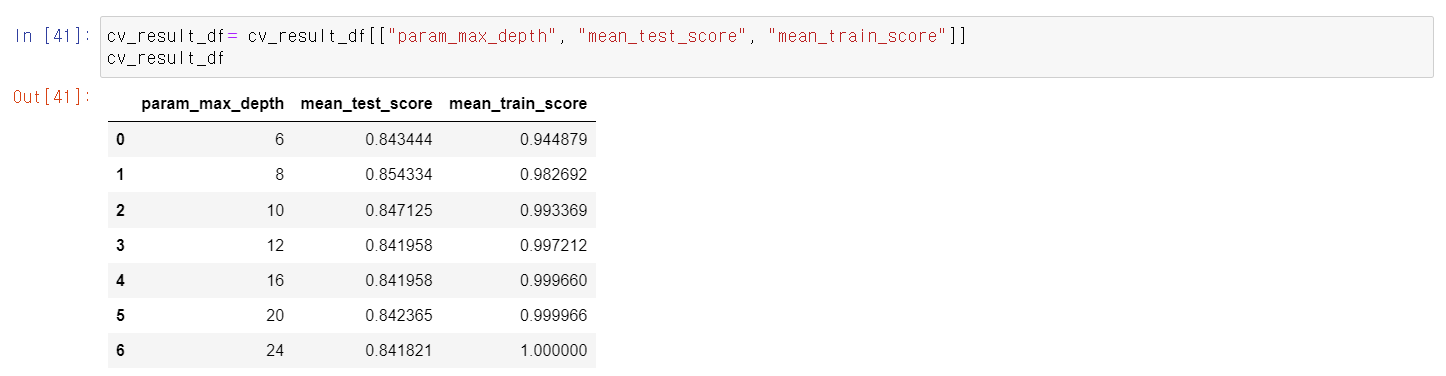
- 결과값을 보기 좋게 DataFrame형태로 바꾸고, 결과를 확인 결과 역시 max_depth 8에서 test데이터 비교 결과 85%로 가장 높다.
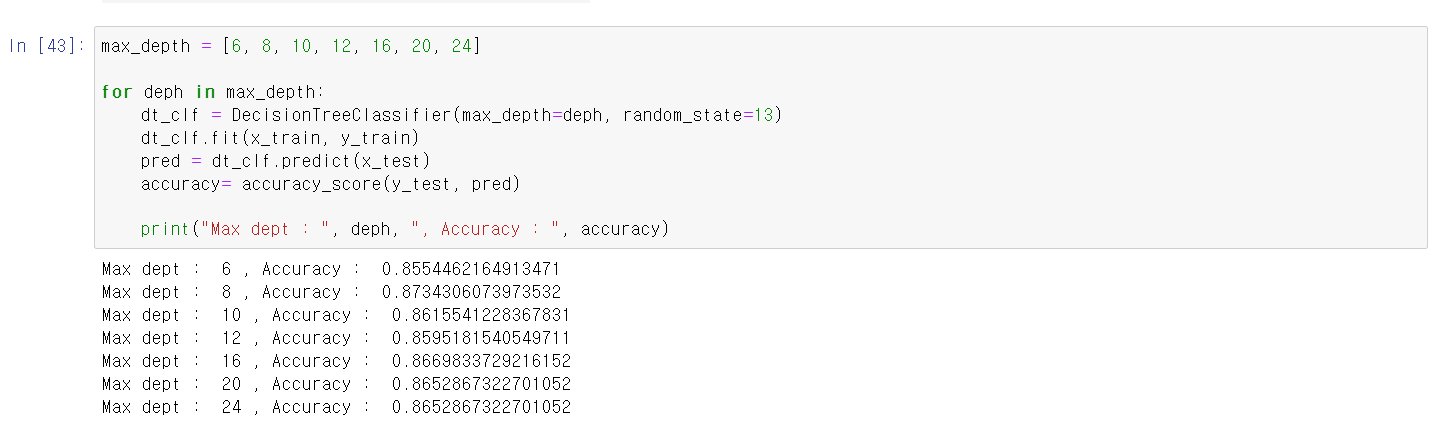
- 이제 train데이터를 통해 교육시킨 모델에 test데이터를 비교한 결과를 for문을 통해 다 보니 교차검증에서와 마찬가지로 max_depth 8에서 제일 좋은 성능이 나왔다.
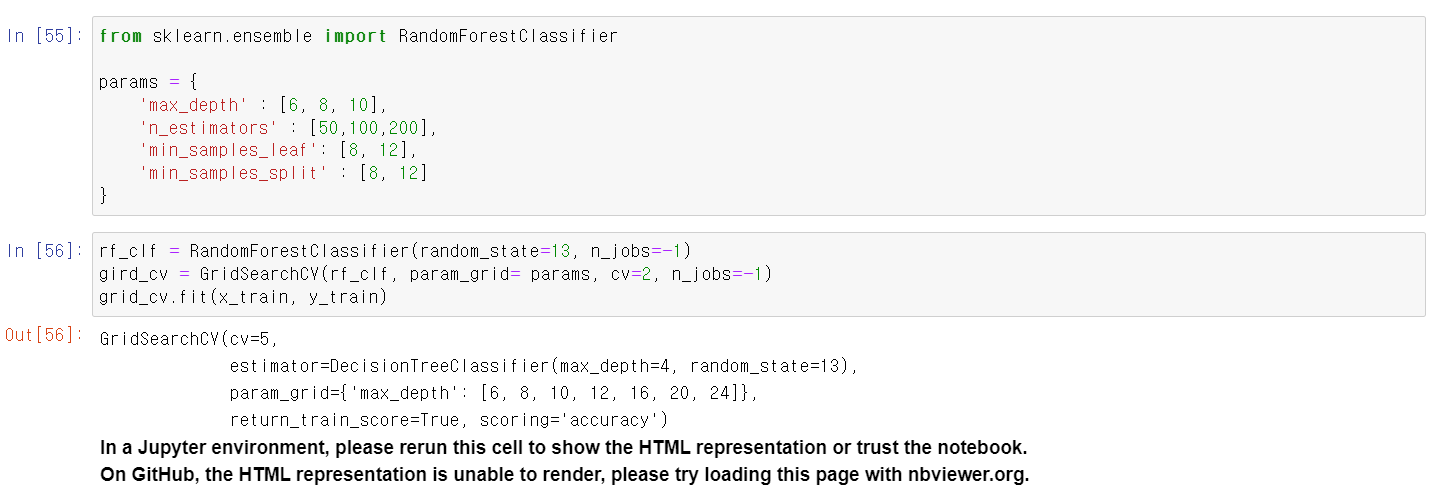
- 이제 앙상블 기법 중 랜덤포레스트를 사용해보자
- max_depth는 6, 8, 10으로 구분하고, 나무트리의 숫자를 50, 100, 200으로 구분 후 모델링을 시켰다.
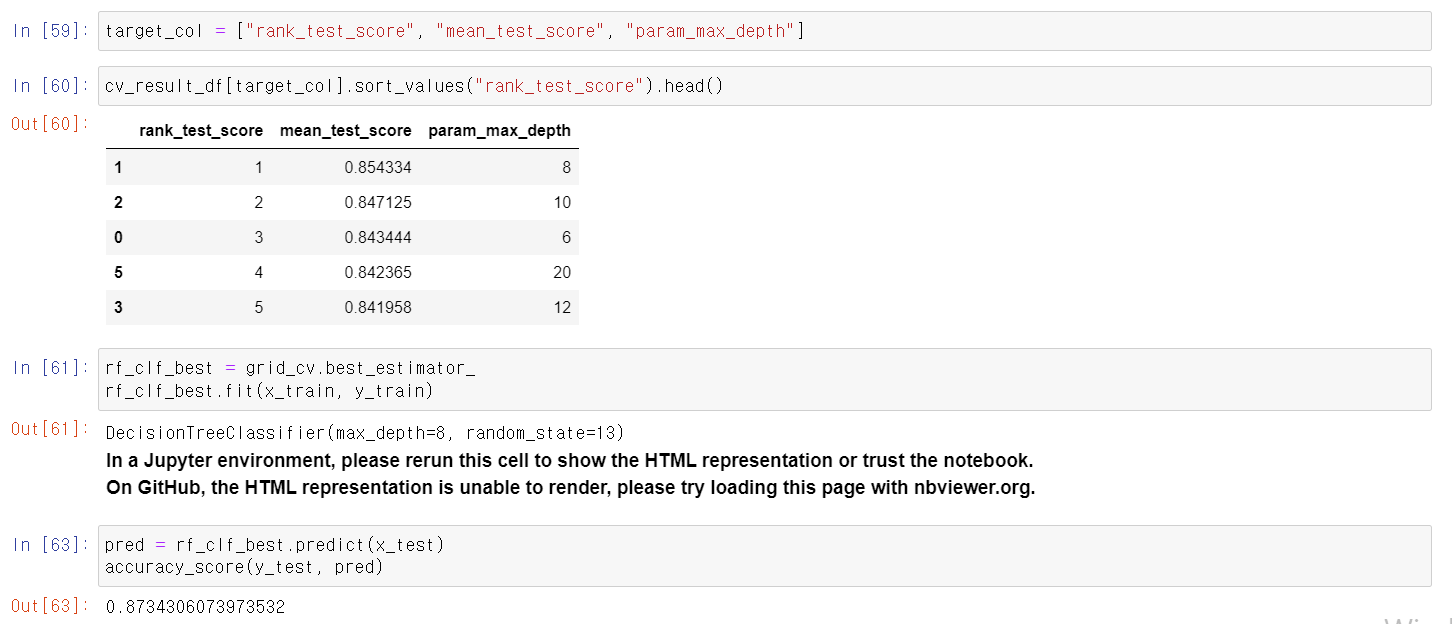
- 성능은 87%로 나왔으며, 상황에 따라 여러 방법을 사용하는 것이 좋다.

상황을 바꿀 수 없다면, 나를 바꾸자