
프로젝트 목적
- 낭설에 이디야 브랜드가 스타벅스 브랜드 근처에 매장을 연다는 소문이 돔
- 실제 이디야 브랜드가 해당 마케팅 전략을 사용하는지 서울시를 기준으로 조사를 진행
- 프로젝트 목적 및 사용 모듈을 실행
- 스타벅스 사이트에서 정보를 웹 크롤링하기 위해 selenium 모듈을 사용
- 먼저 사이트를 열고, 서울시 데이터를 얻기 위해 서울시 포털 검색 html을 입력하고 click()명령어를 통해 사이트 작동
- 이후 사이트의 url을 BeautifulSoup에 저장하고 데이터 추출 준비
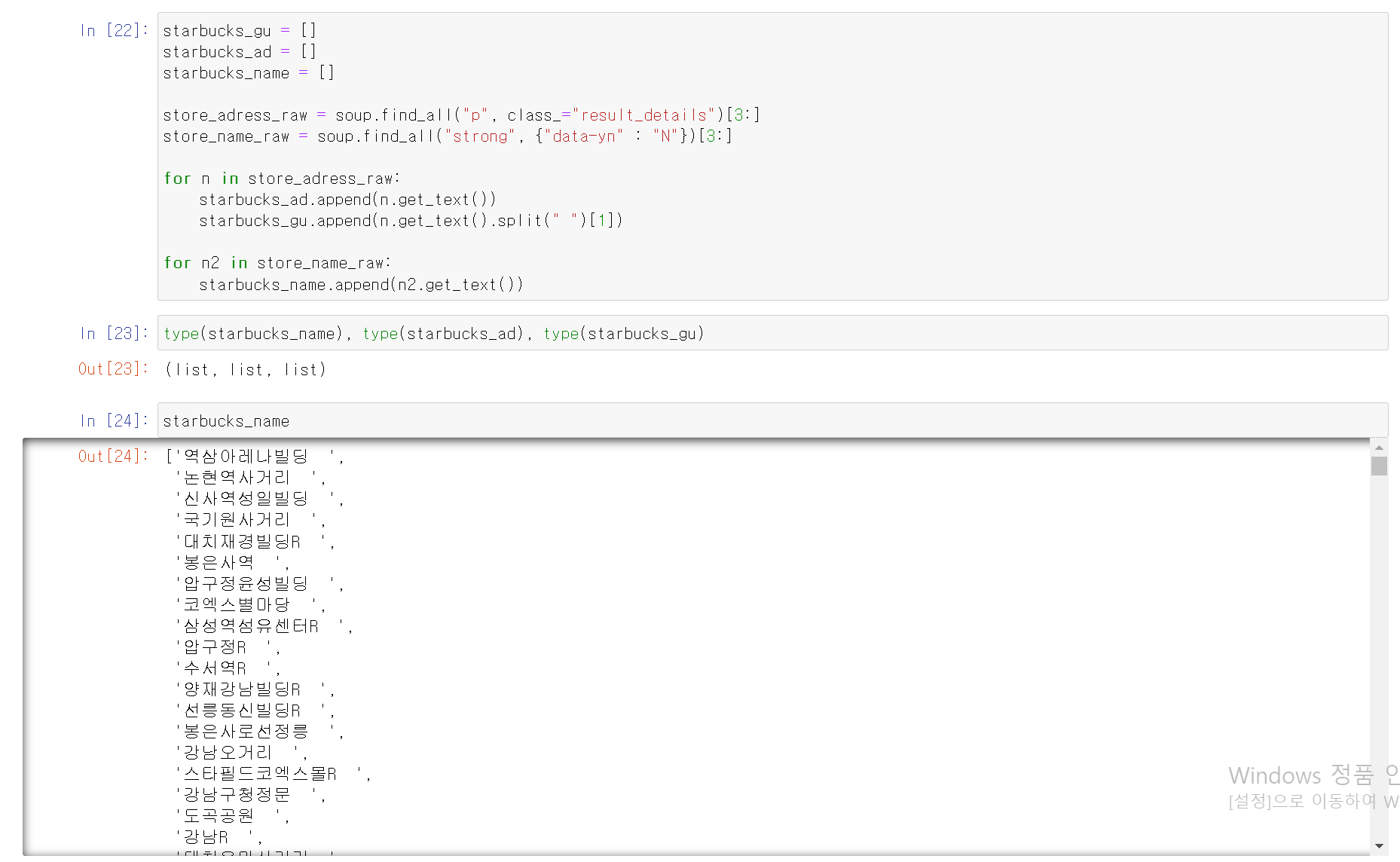
- 이후 서울시 전체 스타벅스 매장(599개)에 대한 데이터를 얻기 위해 for 반복문을 작동
- 추출 데이터의 column(변수)는 매장이름, 주소, 구이름 3가지로 픽스하고 599개 매장에 대한 3항목의 데이터를 추출
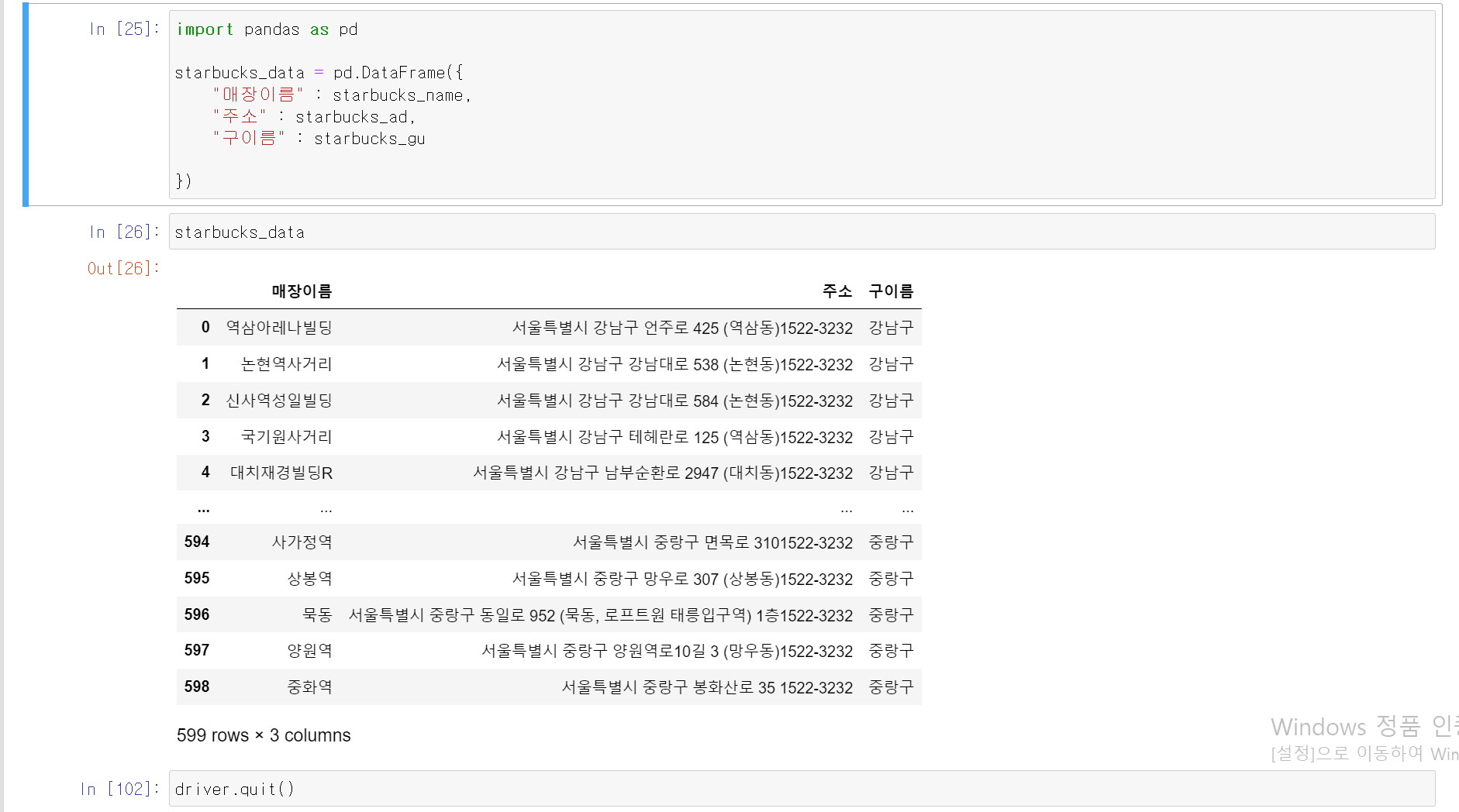
- 추출한 데이터를 통해 pandas의 데이터프레임으로 데이터를 정리
- 총 599개 데이터가 정상적으로 추출된 것을 확인
- 이후 이디야 브랜드 매장에 대한 정보 추출을 위해 스타벅스 사이트에서 한 작업을 다시 작동
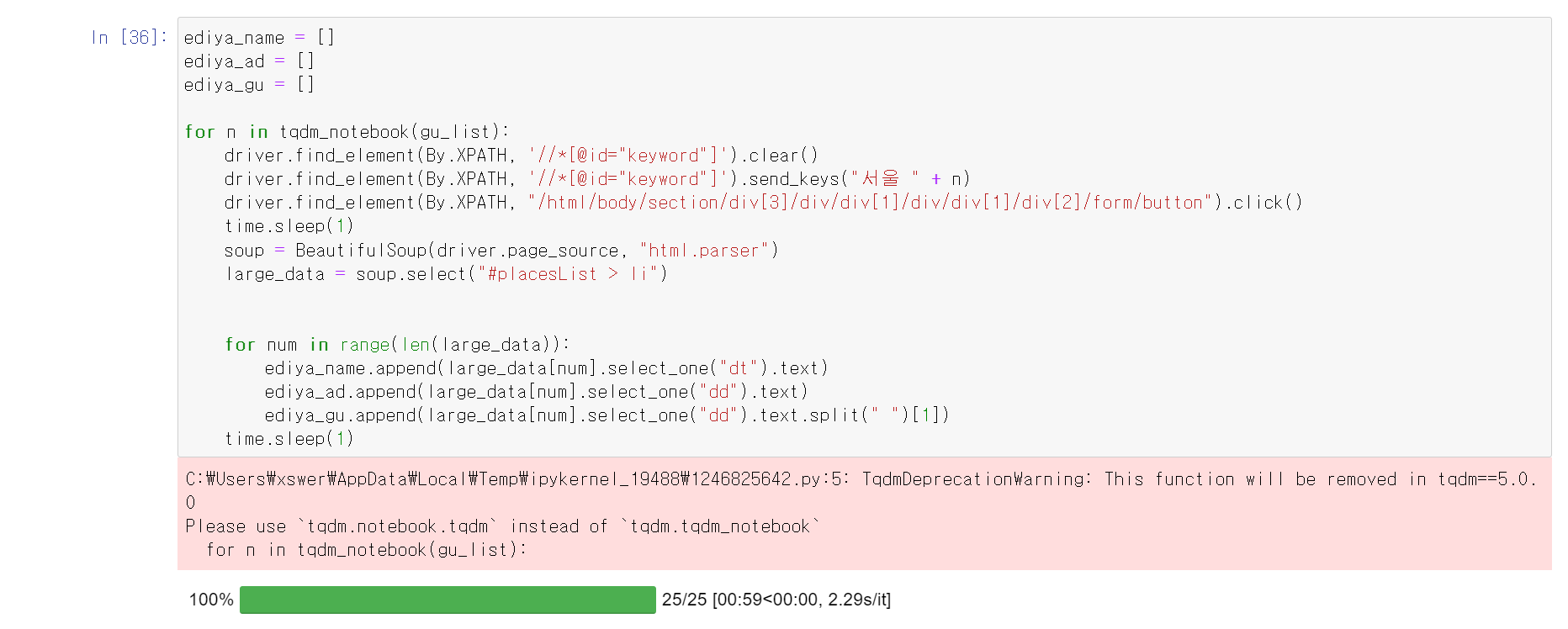
- 다만, 이디야 브랜드는 각 구의 이름을 입력하고, 검색을 함으로써 각 구의 정보를 얻을 수 있기에 selenium 모듈의 send_keys명령어와 스타벅스 작업을 통해 얻은 서울시 25개의 구 정보를 통해 이디야 매정 709개 매장의 데이터를 추출
- 추출하는 과정에서 매장이름, 주소, 구이름 등이 다른 html 위치에 설정되어 있어서 웹 크롤링 과정에서 많은 시간과 노력이 필요했음
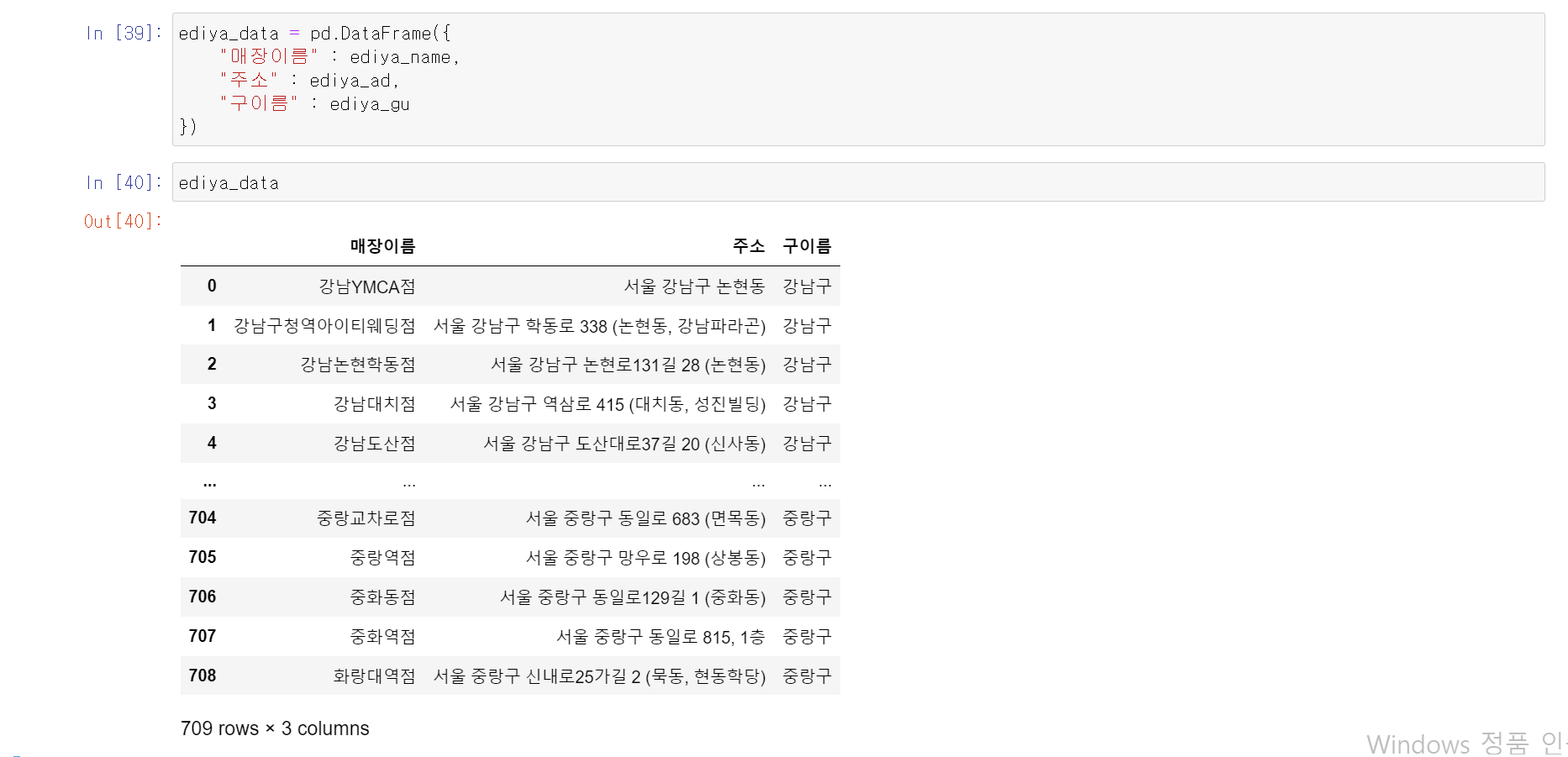
- 이디야 서울시 전체 매장 709개 데이터를 문제없이 추출 성공
- pandas의 DataFrame은 {'column1' : data1, 'column2' : data2}형식으로 간단하게 데이터 설정이 가능
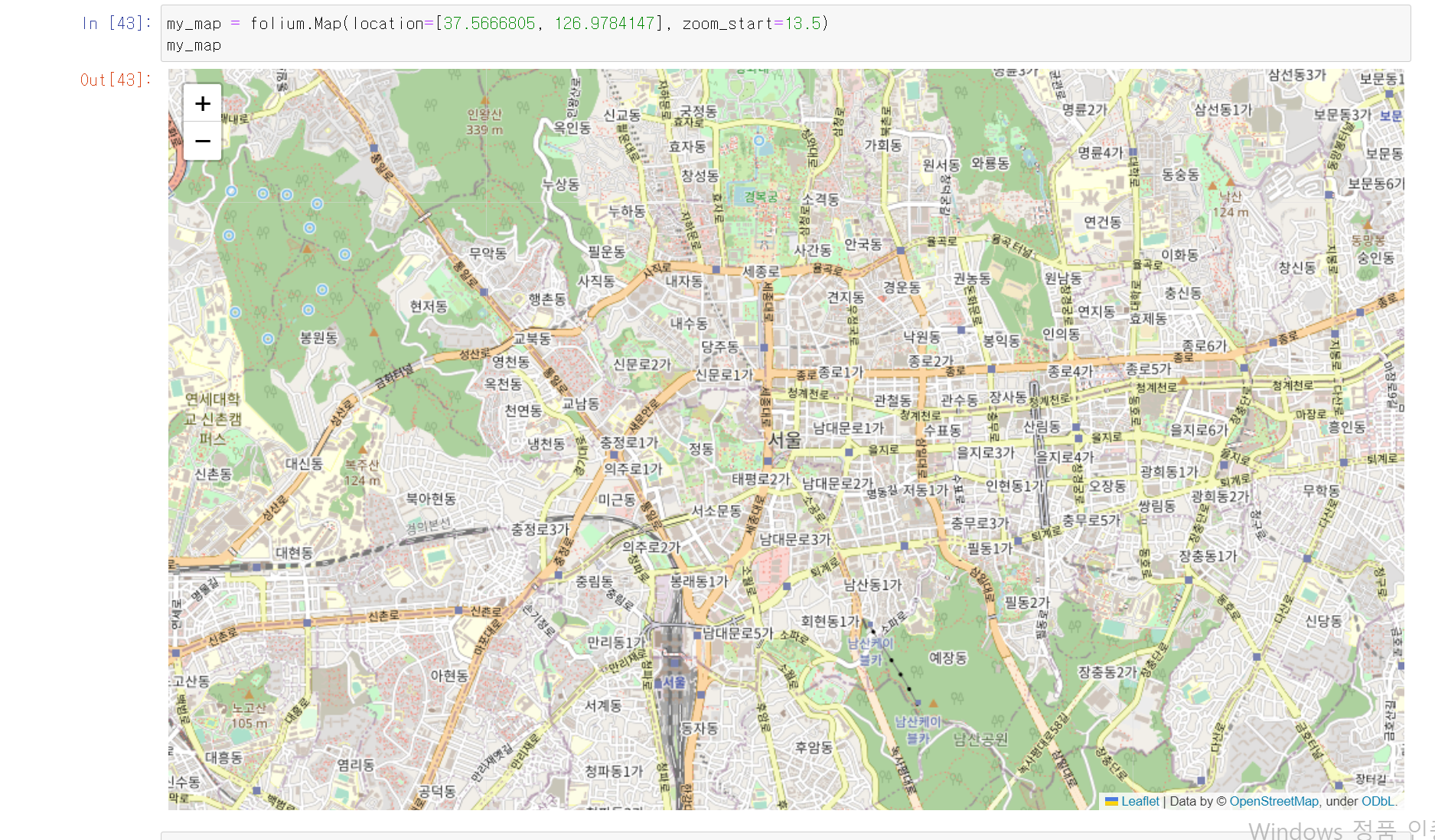
- 서울시 지도에 해당 스타벅스, 이디야 브랜드 위치를 찍기 위해 서울시 지도를 folium모듈을 통해 설정
- google API 및 googlemap을 통해 geocode함수로 각 주소에 대한 경위도를 추출할 준비
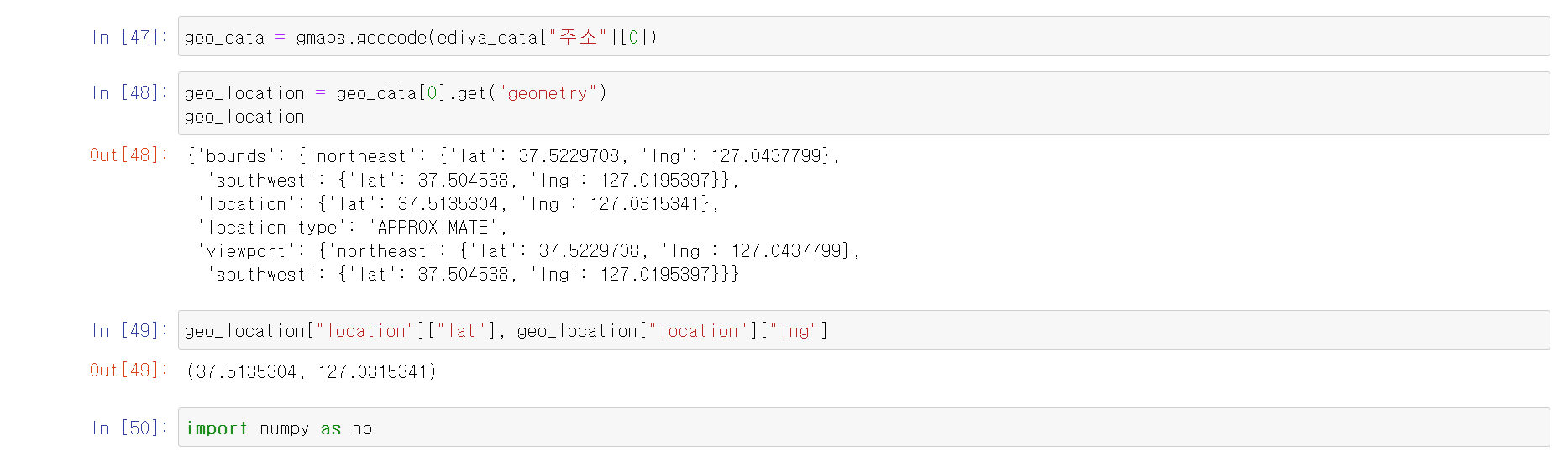
- 먼저 하나의 데이터를 통해 geocode 및 주소에 대한 데이터가 문제없는지 확인
- 확인 결과 정상적으로 데이터가 추출되며, location 위치에 경위도 추출이 가능하다는 것을 확인
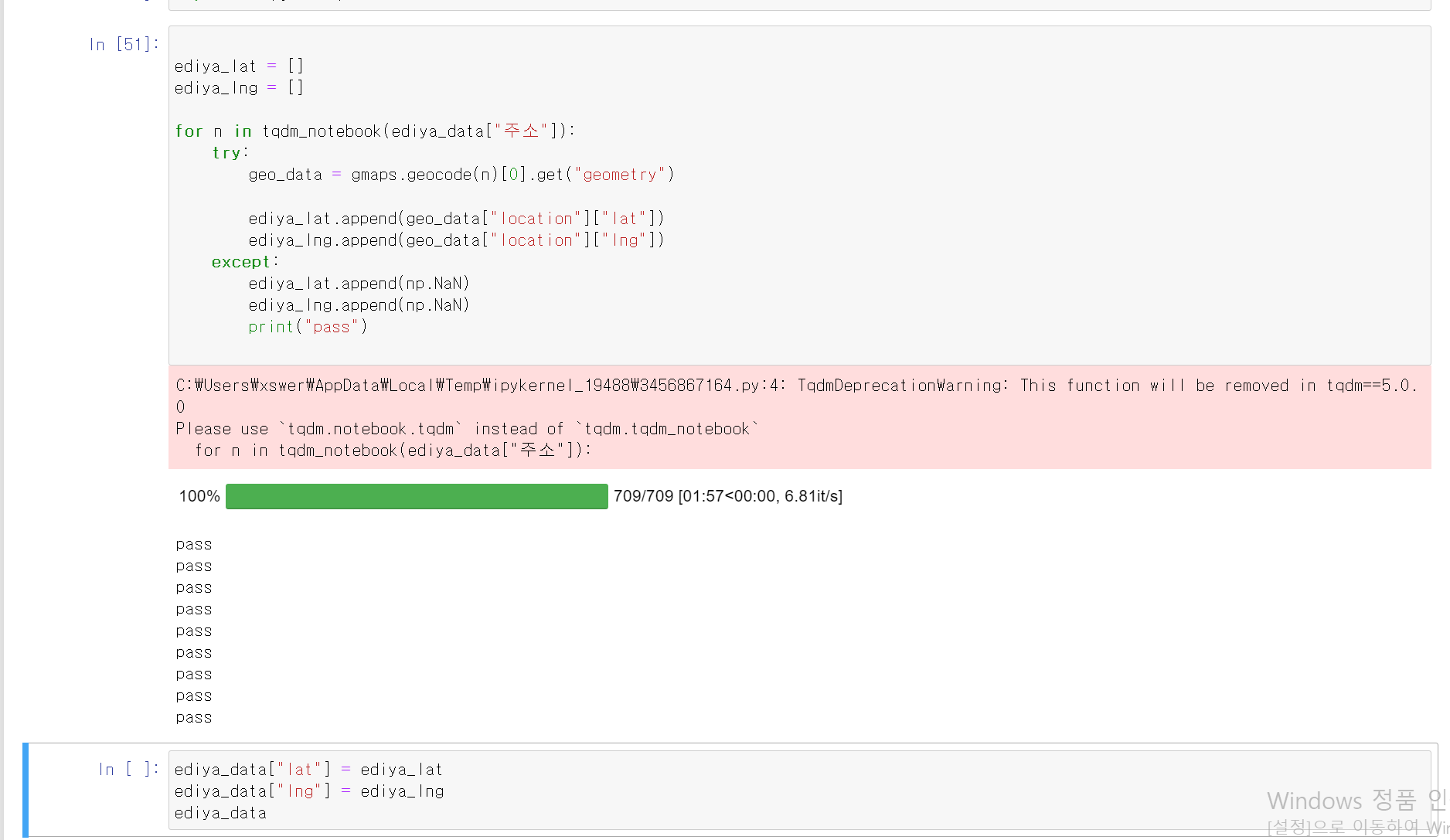
- for 반복문을 통해 이디야 주소에 해당하는 709개의 경위도를 리스트 형태로 geocode로 추출 및 저장
- 추출한 경위도 위치를 이디야 데이터 프레임에 column으로 저장
- 추출 과정에서 오류가 발생하는 경우 try, except를 통해 NaN값으로 저장
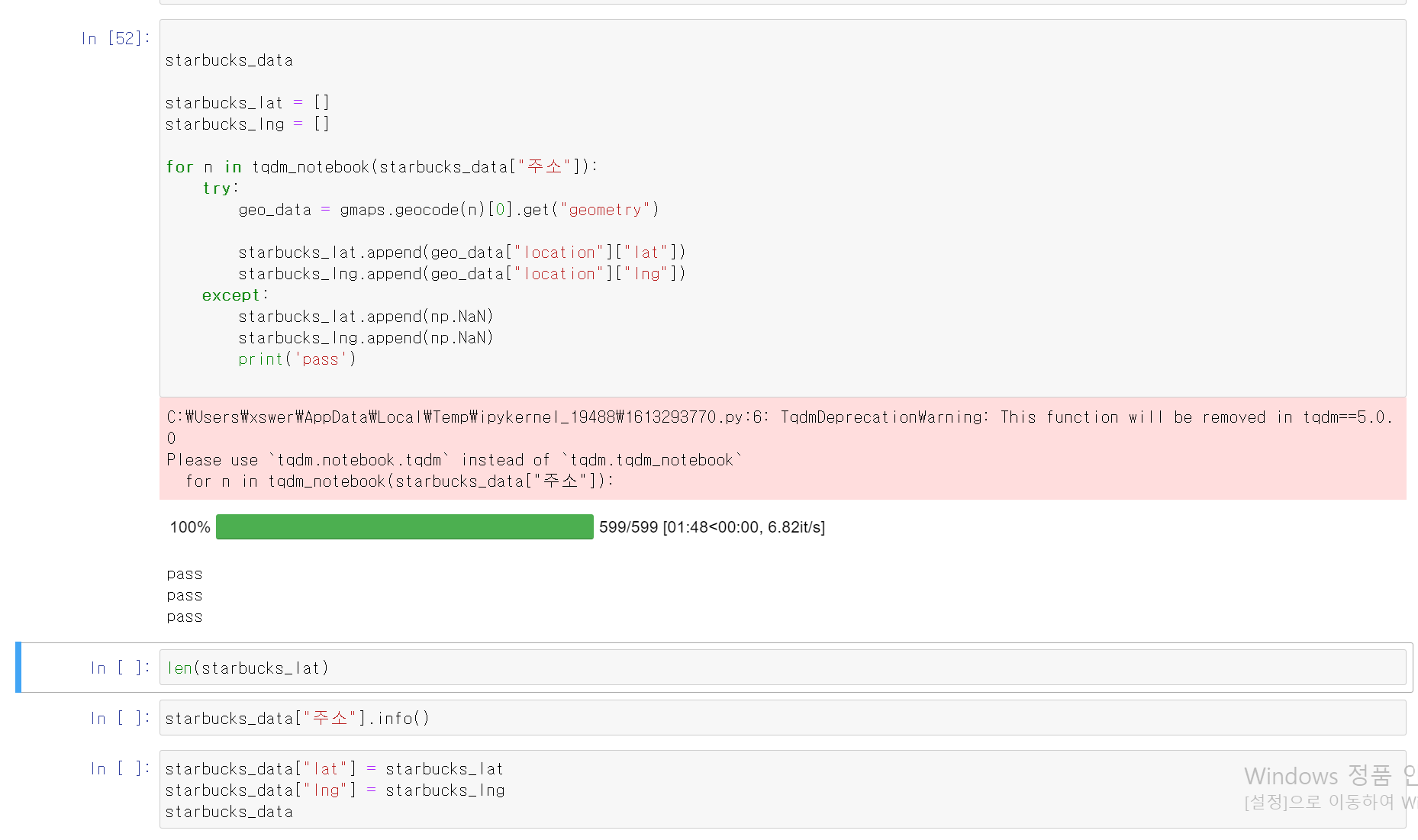
- 위에서 같은 방법으로 스타벅스 주소 599개에 대한 주소를 for 반복문으로 경위도 리스트를 만들고, 해당 데이터를 스타벅스 DataFrame에 column으로 저장

- 데이터 시각화 작업을 위해 스타벅스 및 이디야 데이터를 결합
- 또한, 지도에서 구분을 위해 브랜드 column을 추가
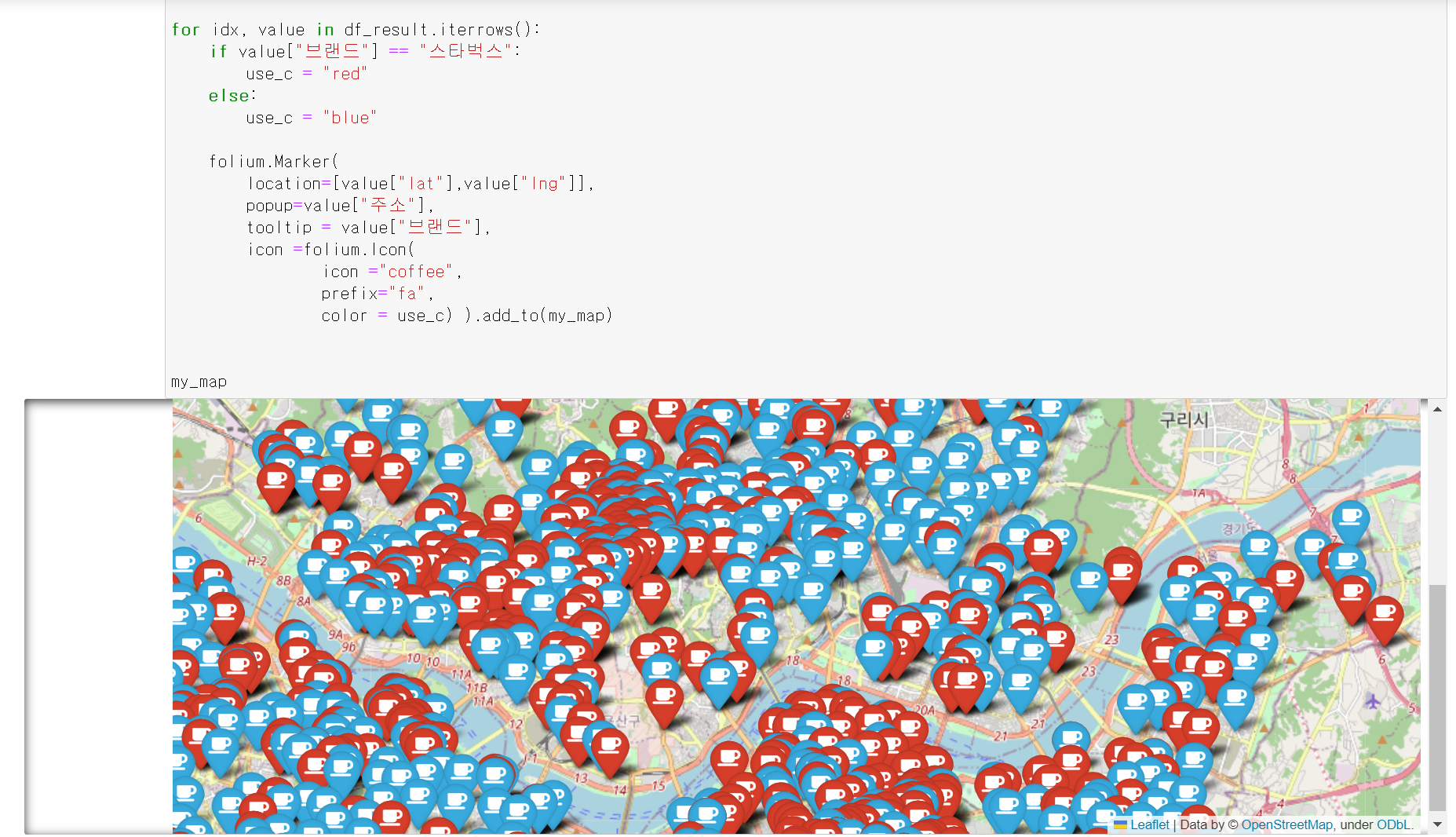
- 서울시 지도에 해당 스타벅스, 이디야 위치에 마커를 통해 위치를 표시

- 해당 자료를 바탕으로 한 정리 및 분석

- 이후 가독성을 높이고 시각적인 분석을 위해 산점도 그래프를 통해 분석을 시실
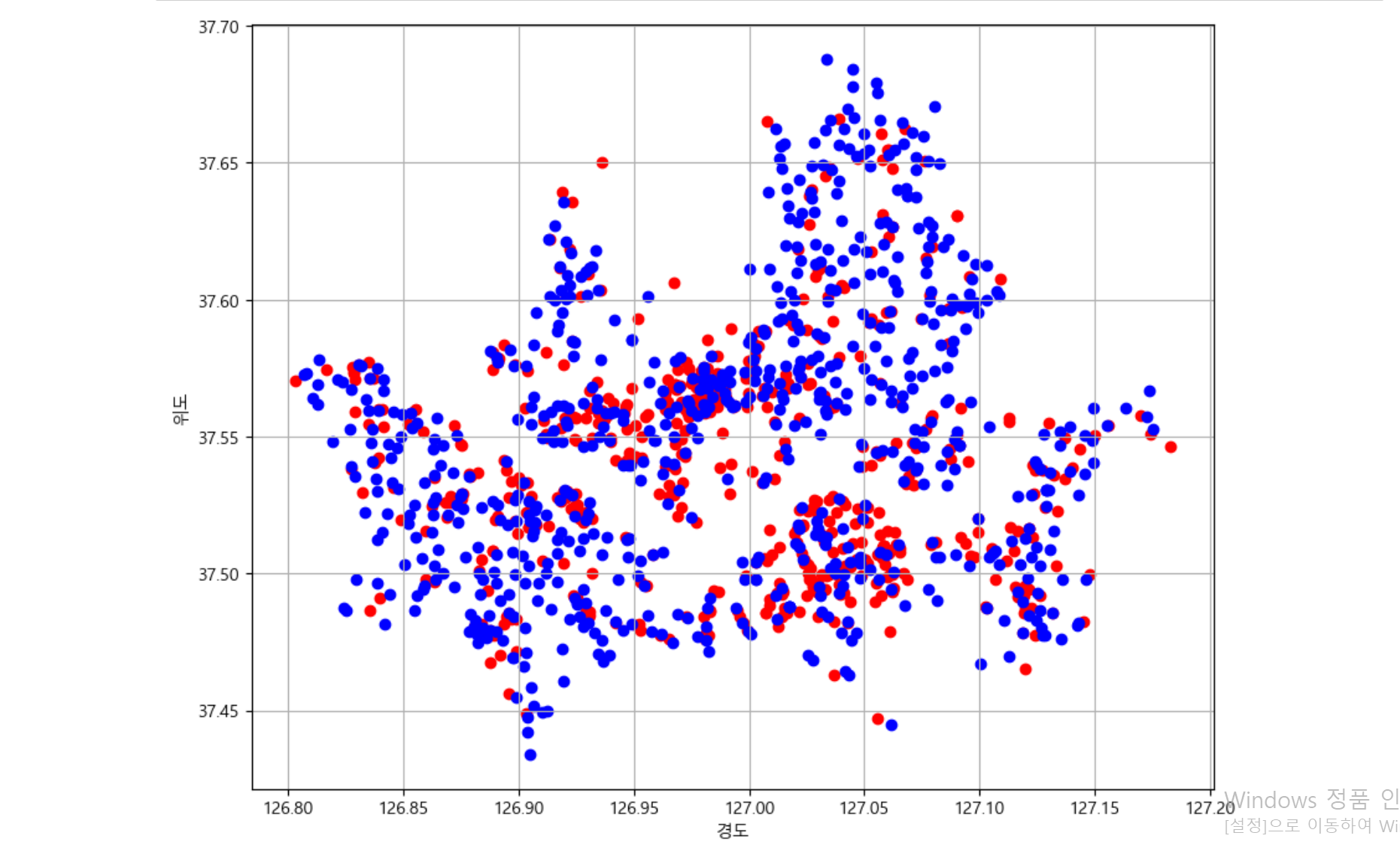
- x축을 경도, y축을 위도로 파란점을 이디야, 빨간점을 스타벅스로 찍고 분석

- 최종 결론 및 분석
마무리
1. 데이터 분석가로서 데이터 분석 및 시각화 작업이 어렵다고 생각하며
프로젝트를 진행했지만, 실무자의 말대로 데이터 전처리 및 가공 단계에서 노력과 시간이
제일 많이 필요했으며 시각화 작업은 상대적으로 적은 시간이 소모됨
2. 통계 자격증 및 기본 통계 지식을 통해 분석을 하려고 시도했으나, 해당 분야에 기본적인
도메인 지식이 부족함으로 깊이 있는 통계가 어려웠으며, 접근 단계에서 구체적인
설정을 못함
3. 다음 프로젝트를 진행할 때 시작단계에서 더욱 깊이 있는 설계와 진행을 통해
프로젝트 진행 중간에 길을 잃지않고, 목적에 맞는 데이터 추출과 분석을 해야겠다고 결심
상황을 바꿀 수 없다면, 나를 바꾸자