1. 프로젝트 목적
- 서울시 전체(구별 구분) 일반주유소, 셀프주유소의 데이터 전처리, 가공 및 분석
- 분석을 통해 일반주유소와 셀프주유소의 가격 차이에 의미가 있는지 분석
2. WebPage 접근
- jupyter notebook에서 필요한 모듈 import
pandas : 데이터 가공
selenium : 웹 페이지 조작
folium : 지도 시각화
time : 웹 크롤리 과정에서 간격 생성
googlemap : 주소에 대한 경위도 추출
BeautifulSoup : 웹 페이지에서 데이터 추출
- 해당 사이트에서 Data를 추출하기 전에 웹 페이지 클릭, 입력 등 다양한 기능을 명령하기 위해 drive변수에 seleniumDriver 지정
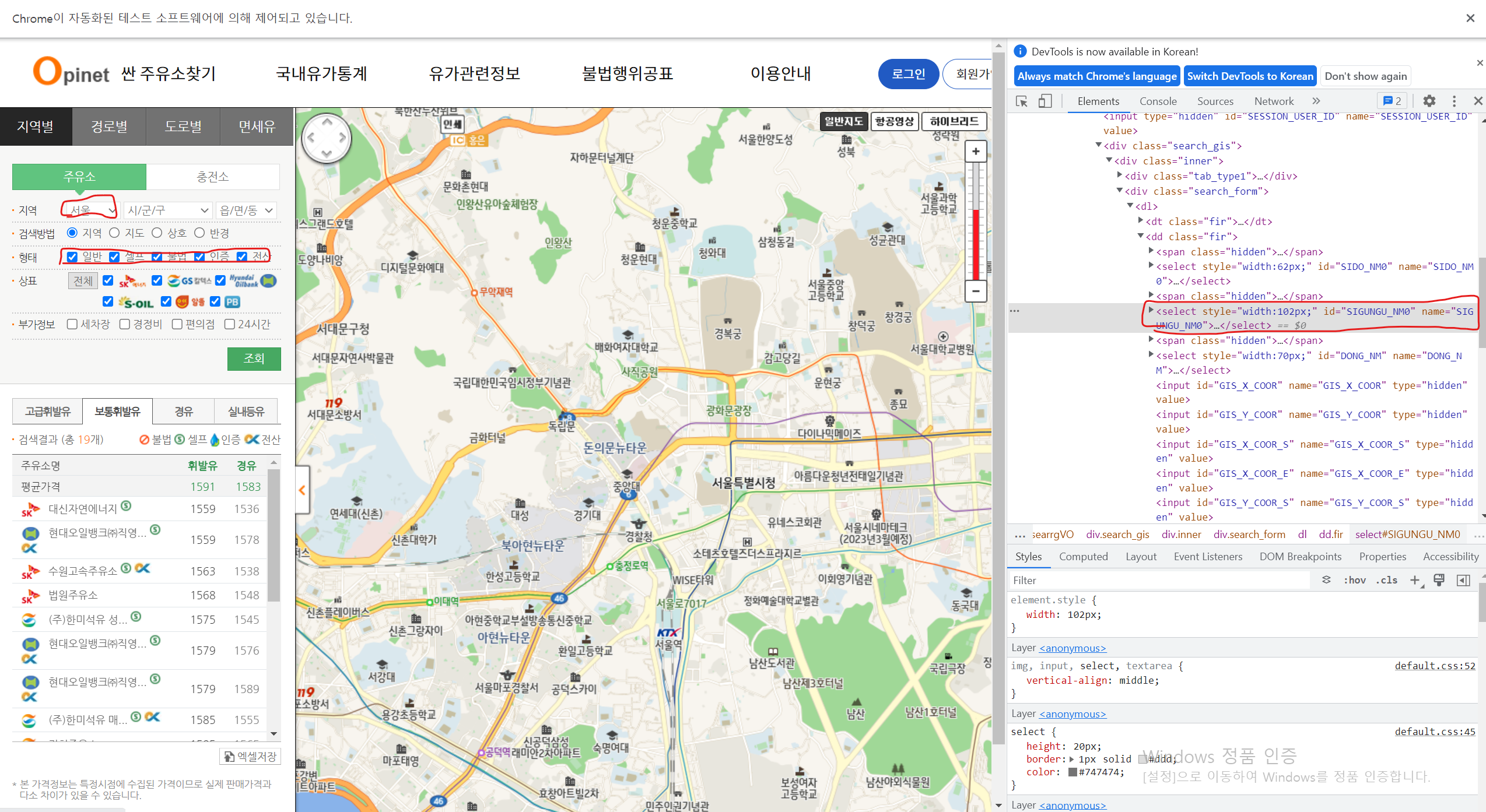
- 해당 페이지에서 해야 할 과제
1. 가장 먼저 지역 부분에 '경기'를 '서울'로 입력하기 위해 명령어 입력
2. 상태에서 일반주유소만 자료를 검색하기 위해 나머지 3개 항목을 click
3. 시/군/구에서 서울시 25개 구 전체 name을 추출하기 위해 html 위치 파악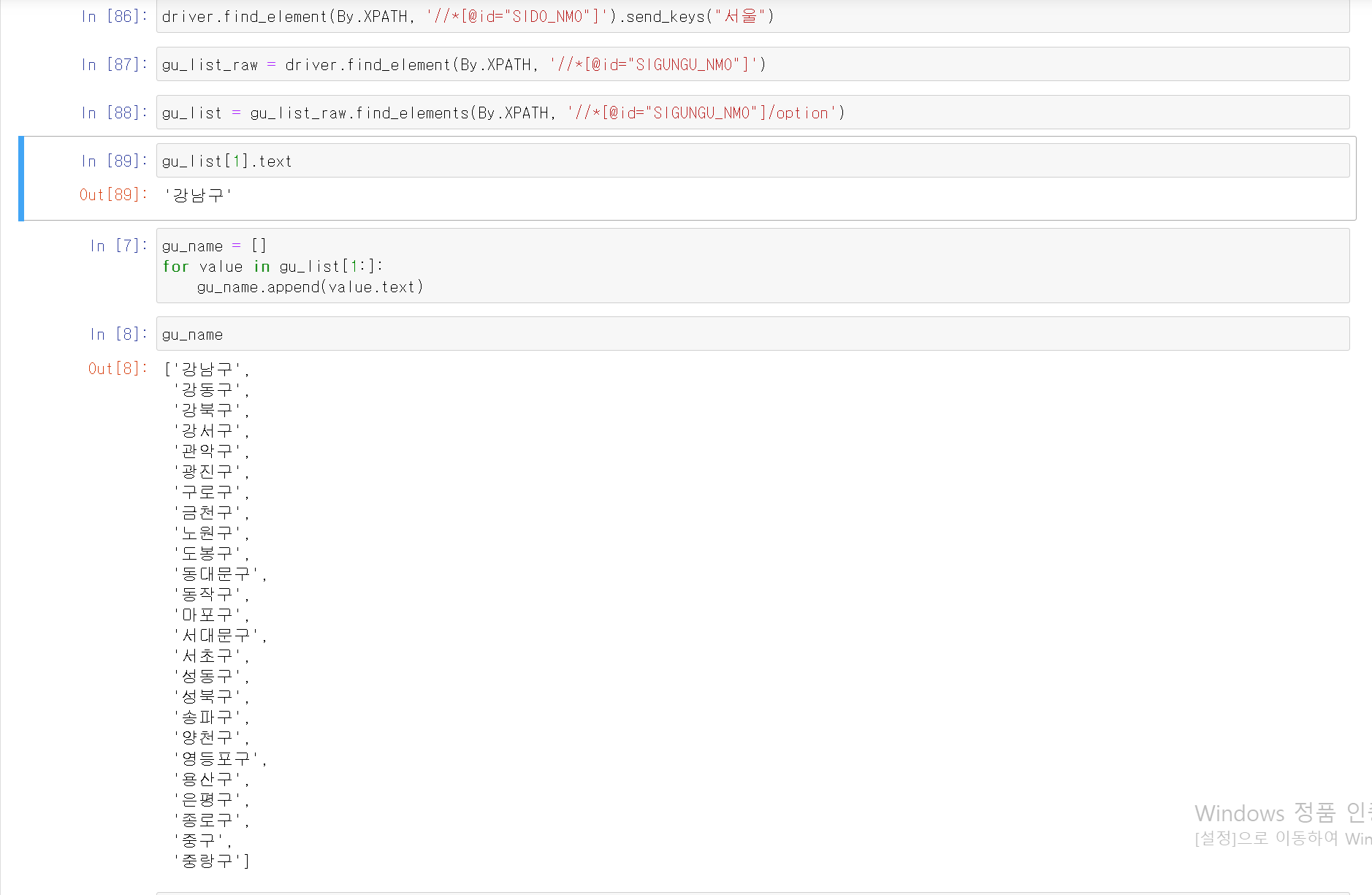
- gu_list에서 두 번째 인덱스부터 '강남구'를 시작으로 데이터 추출 완료
- 해당 데이터를 gu_name에 지정
3. sample Data 추출
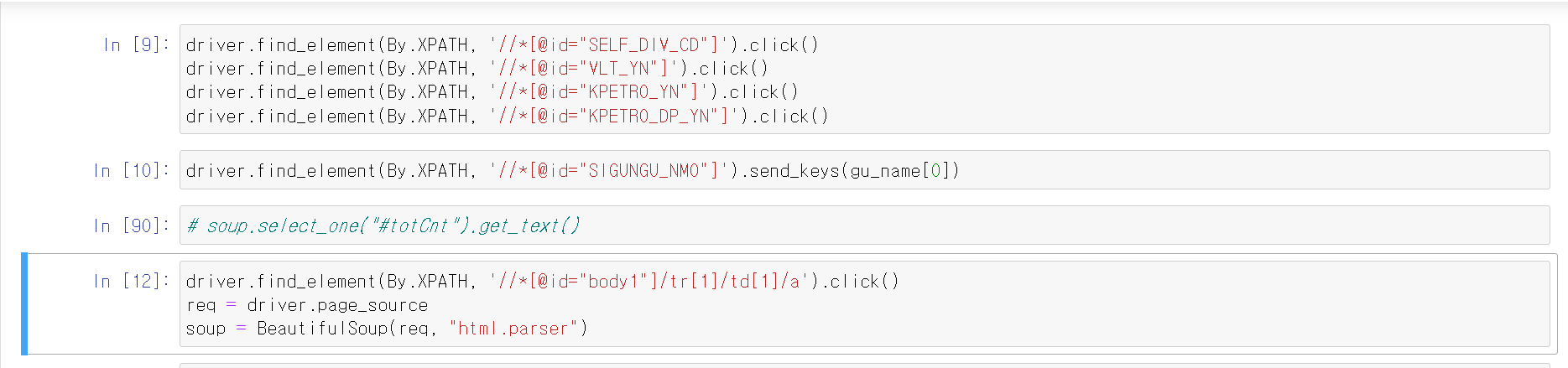
- gu_name 데이터 추출 후 '상태'항목에서 일반 주유소만 체크하기 위해 driver.click()을 통해 나머지 항목 off
- 그리고 해당 페이지 상태를 soup변수에 BeautifulSoup에 저장
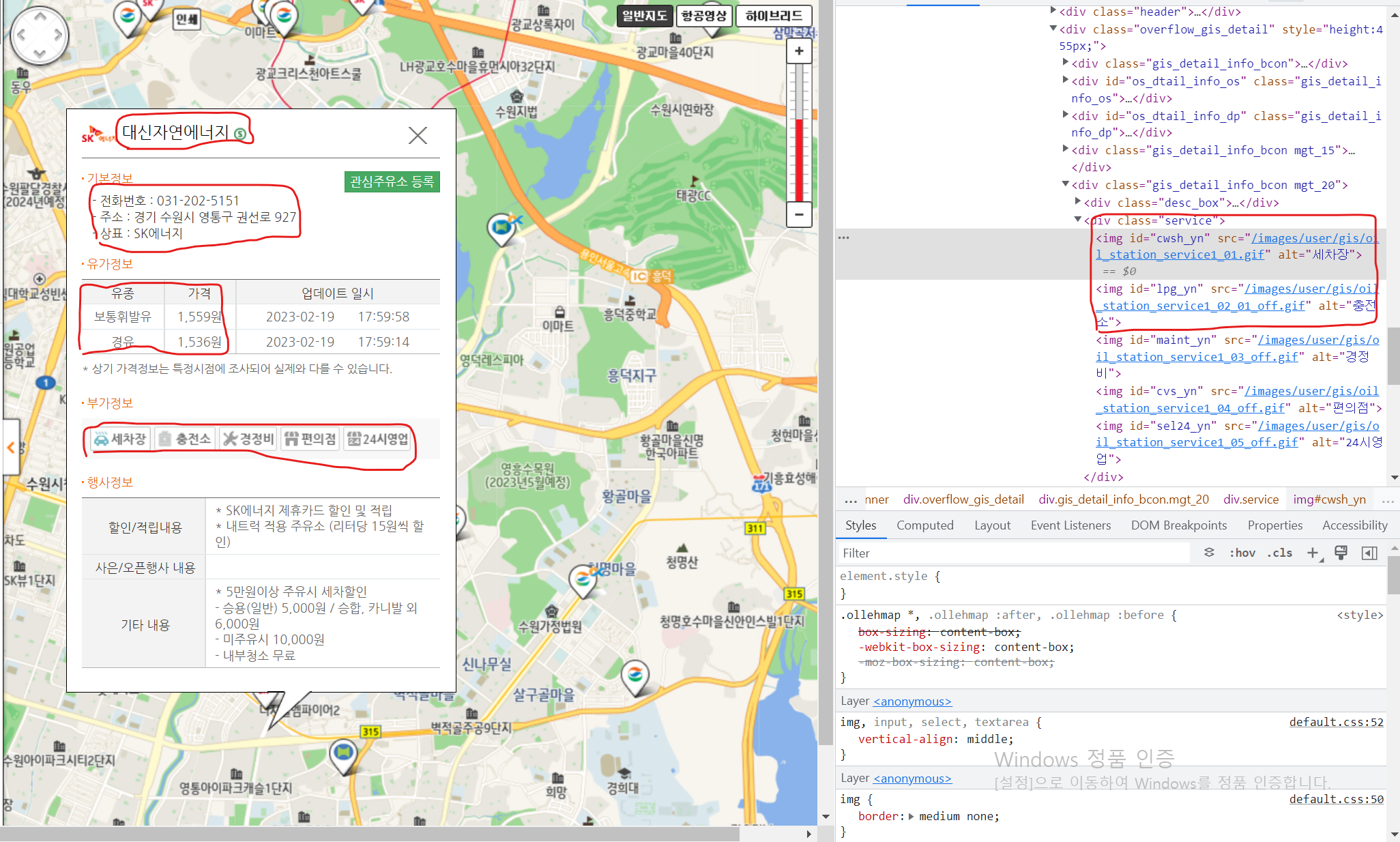
- 해당 페이지에서 주유소명, 주소, 상표, 휘발유 및 경유 가격, 부가정보 4개 정보를 추출
- 어려웠던 점
<문제>
나머지 정보는 text형식으로 추출할 수 있어서 html에서
필요한 부분을 copy함으로써 경로를 뽑고 text로 변환할 수 있지만,
부가정보의 경우 이미지 형식이라 text로 뽑아도 세차장, 충전소 등의 항목 정보만 나오고
해당 주유소의 부가정보에 대한 설치 여부가 Data 뽑히지 않음
<해결법>
html 문법 구조를 살펴본 결과 부가정보가 설치된 경우 'off' 문구가 없고,
설치가 되지 않은 경우 'off'문구가 추가되어 있는 규칙성을 발견함
해당 규칙성을 통해 해당 html 문구를 string형식으로 변환 후 find함수를 사용해
off를 찾을 경우 해당 부가 서비스는 없으며, -1 즉 off가 없다면 설치된 것으로 간주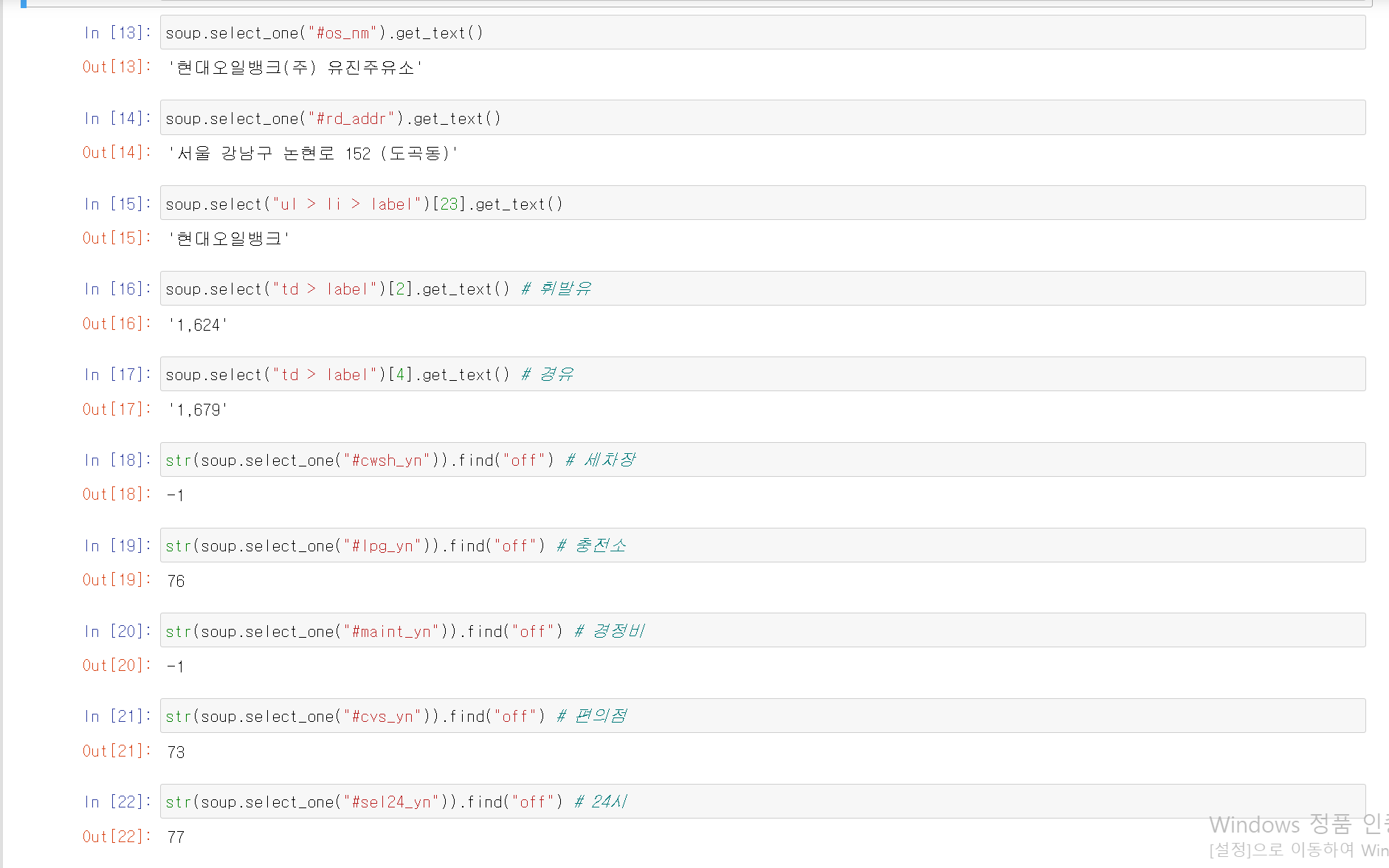
- beaufitulSoup 모듈을 사용해 각 부분의 html정보를 추출
- 부가정보의 경우 string형식으로 변환해 -1 or 'off'위치를 찾아 해당 부가서비스의 설치 여부를 파악
4. 데이터 추출

- 각 정보에 대한 빈 리스트를 작성
- 주유소명, 주소, 브랜드, 휘발유 가격, 경유 가격, 셀프 주유소 여부, 셀프 세차장 여부, 충전소 여부, 정비소 여부, 편의점 여부, 24시 여부, 해당 위치의 구 등 다양한 정보를 추출을 위한 리스트 틀 작성
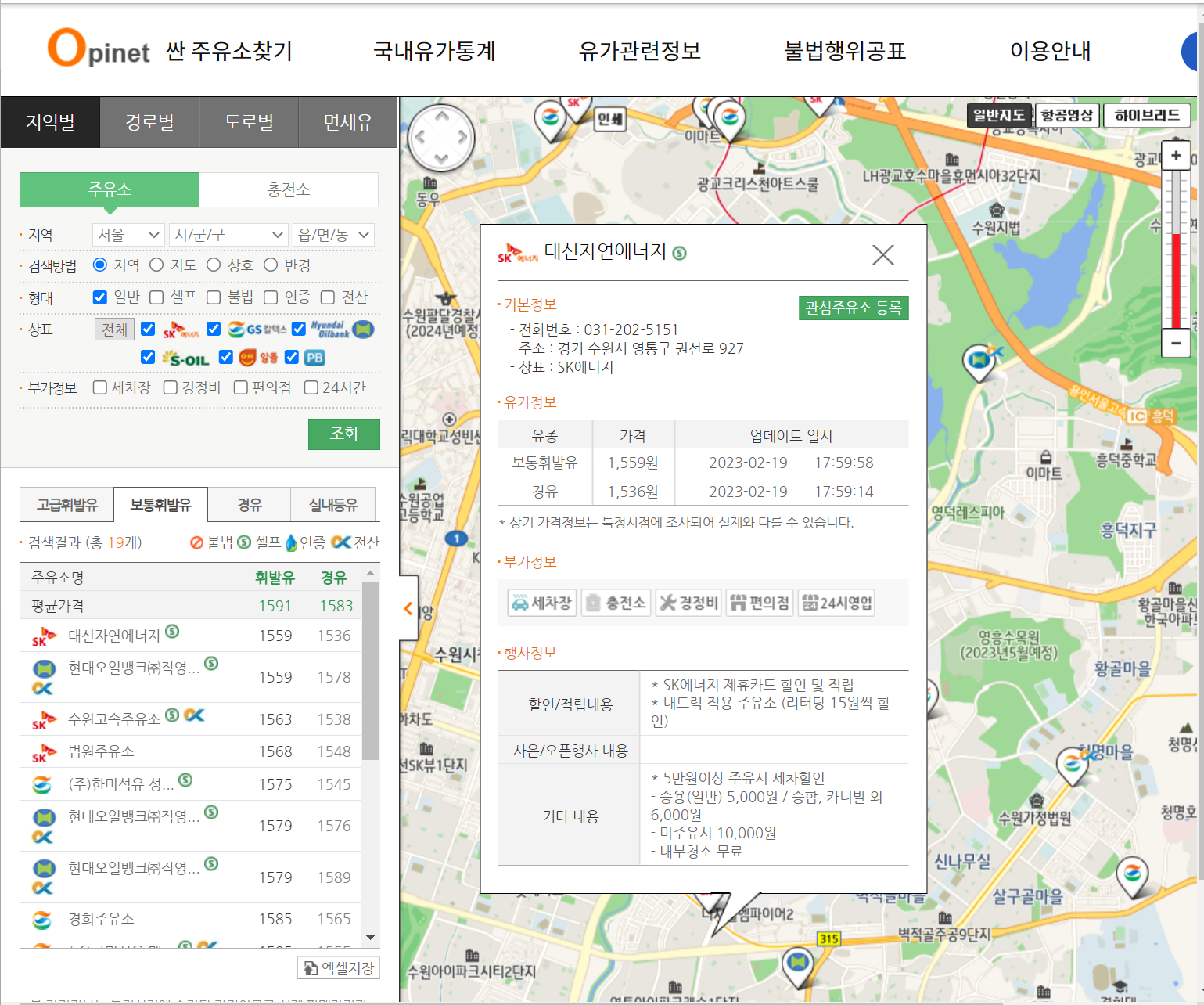
- 해당 페이지에서 각 항목의 정보를 추출
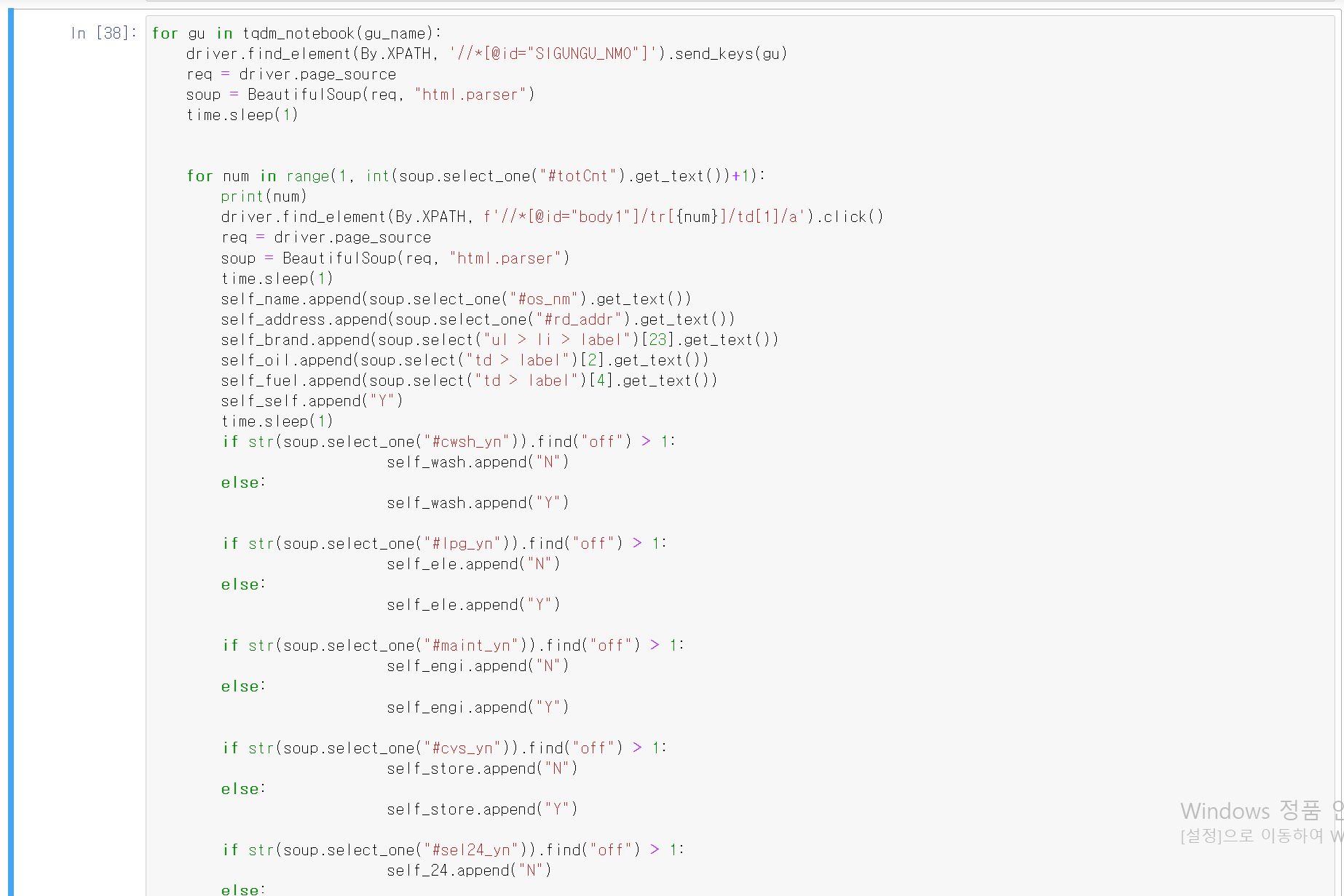
- 첫번 째 for문에는 gu_name에 정보를 driver.send_keys를 통해 25개의 '구'정보를 넣음
- 두번 째 for문을 통해 각 구마다의 주유소가 있는 숫자만큼 range에 len으로 넣음
- 어려웠던 점
<문제>
두번 째 fon문에서 for숫자의 변수를 num으로 넣고 html 위치에서 tr[]안에 넣음
tr안에 0, 1, 2 넣을 때마다 각 구의 첫번 쨰 주유소를 클릭, 두번 째 주유소를 클릭하기
명령어를 입력했으나, ''문구 때문에 num변수가 스트링으로 인식됨
<해결>
정말 기초적이고 간단한 방법이었지만, 해당 방법을 쓸 생각을 못했음
f'my name : {name}'으로 입력 시 스트링 안에 name이 변수로 활성화되는데,
해당 방법을 생각하지 못해 여러 방법을 시도 또한 처음에는 왜 안 되는지 찾는 데도
많은 시간을 투자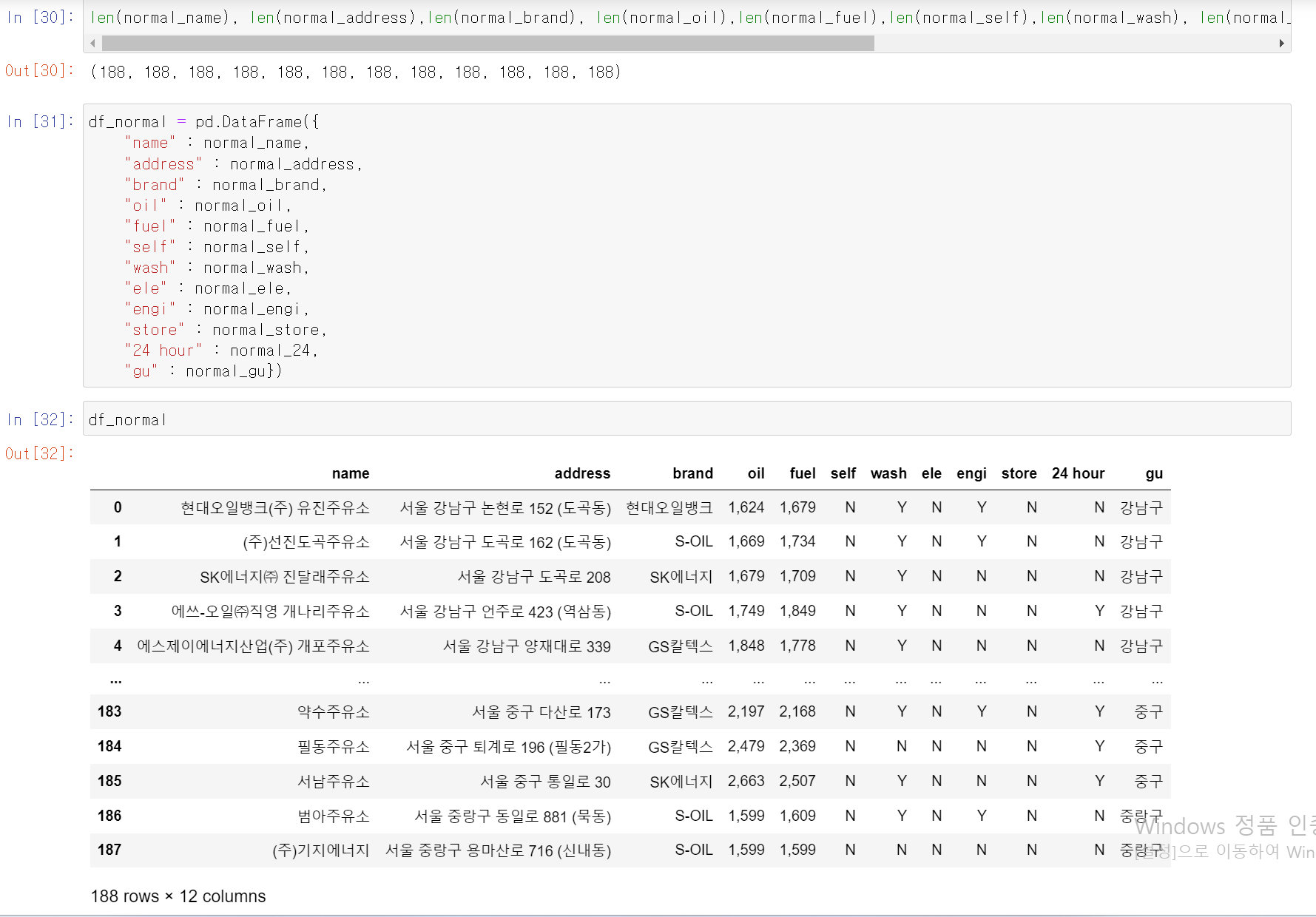
- 각 Data의 길이를 확인 결과 188개로 모든 데이터 이상없이 추출
- 추출한 Data를 바탕으로 Pandas의 Dataframe으로 변환
- 해당 Dataframe을 df_normal 변수에 저장
- 위에와 같은 방법으로 drive.click으로 일반 주유소에서 셀프 주유소로 항목 변경
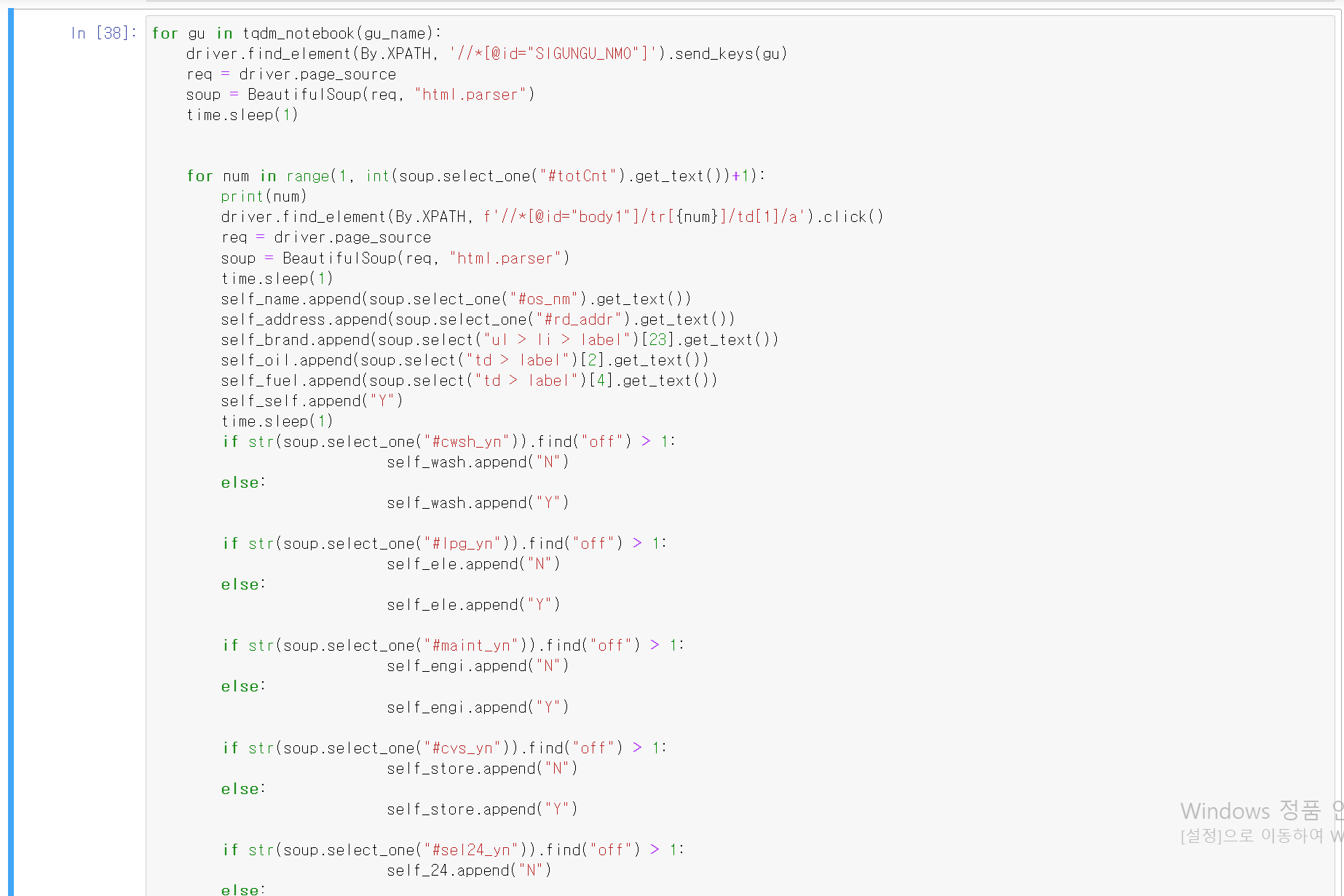
- 두 개의 for 반복문으로 셀프 주유소의 각 데이터 항목을 추출
- 일반 주유소 정보를 추출할 때와 같이 f'{}'문법을 통해 변수를 활성화
- find형식을 통해 세부 정보에 여부 파악
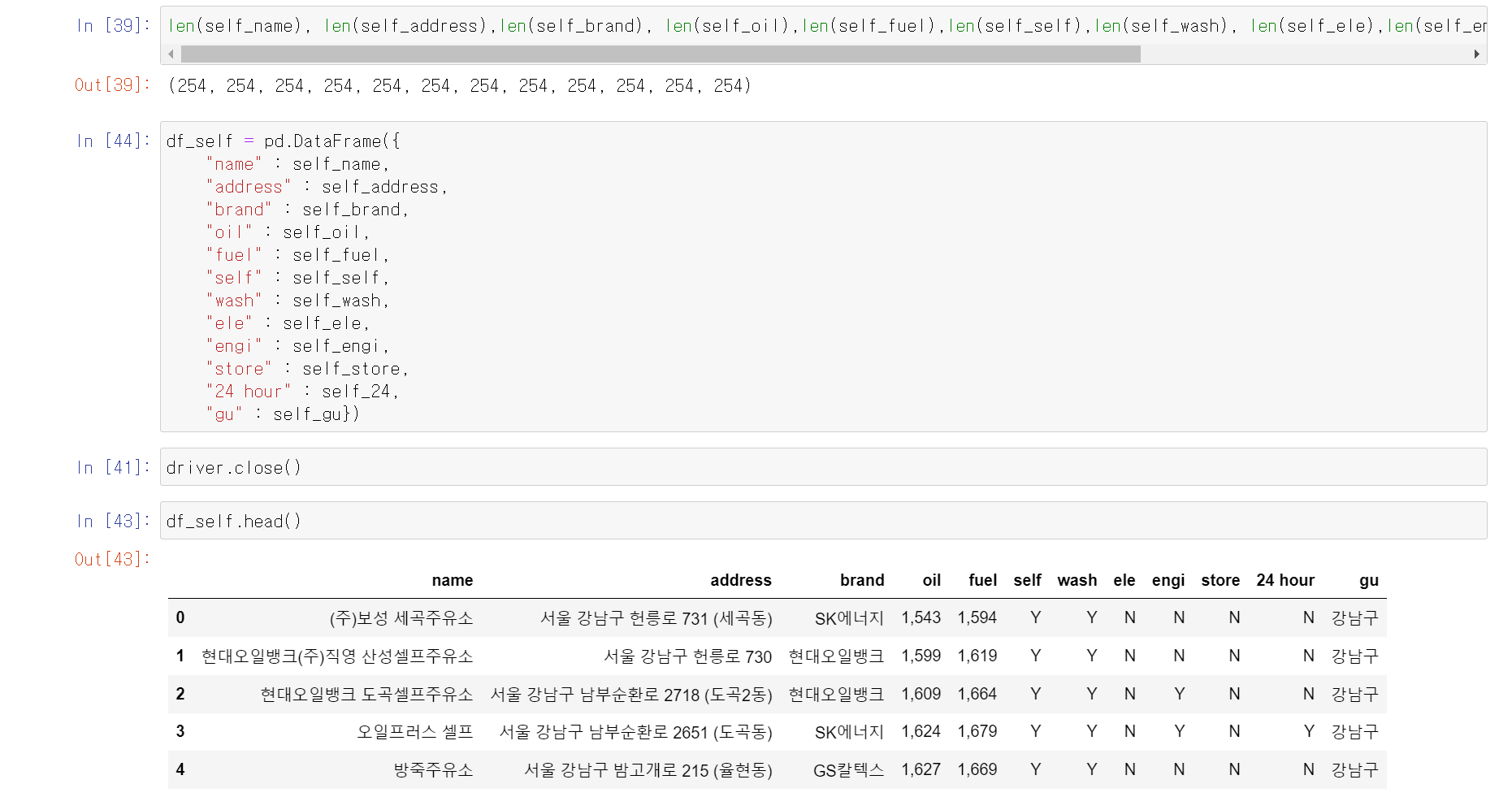
- 셀프 주유소에 대한 데이터를 pandas의 DataFrame형식으로 변환
- 일반 주유소, 셀프 주유소 모두 데이터 추출 완료
5. 데이터 가공
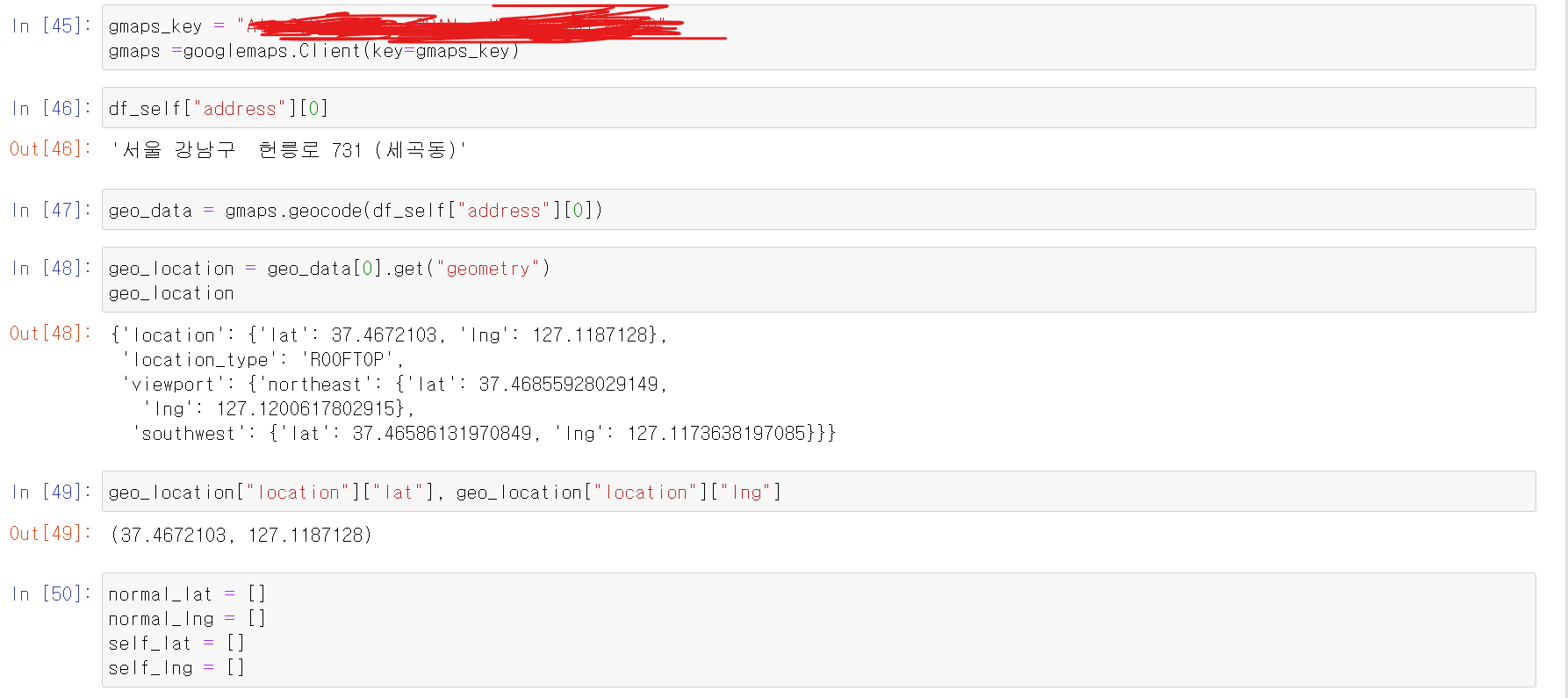
- googlemap을 통해 데이터의 주소에 대한 경위도를 추출
- 샘플 데이터 추출 결과 경도, 위도 이상 없이 추출 가능
- 일반주유소 경위도, 셀프주유소 경위도 리스트 생성
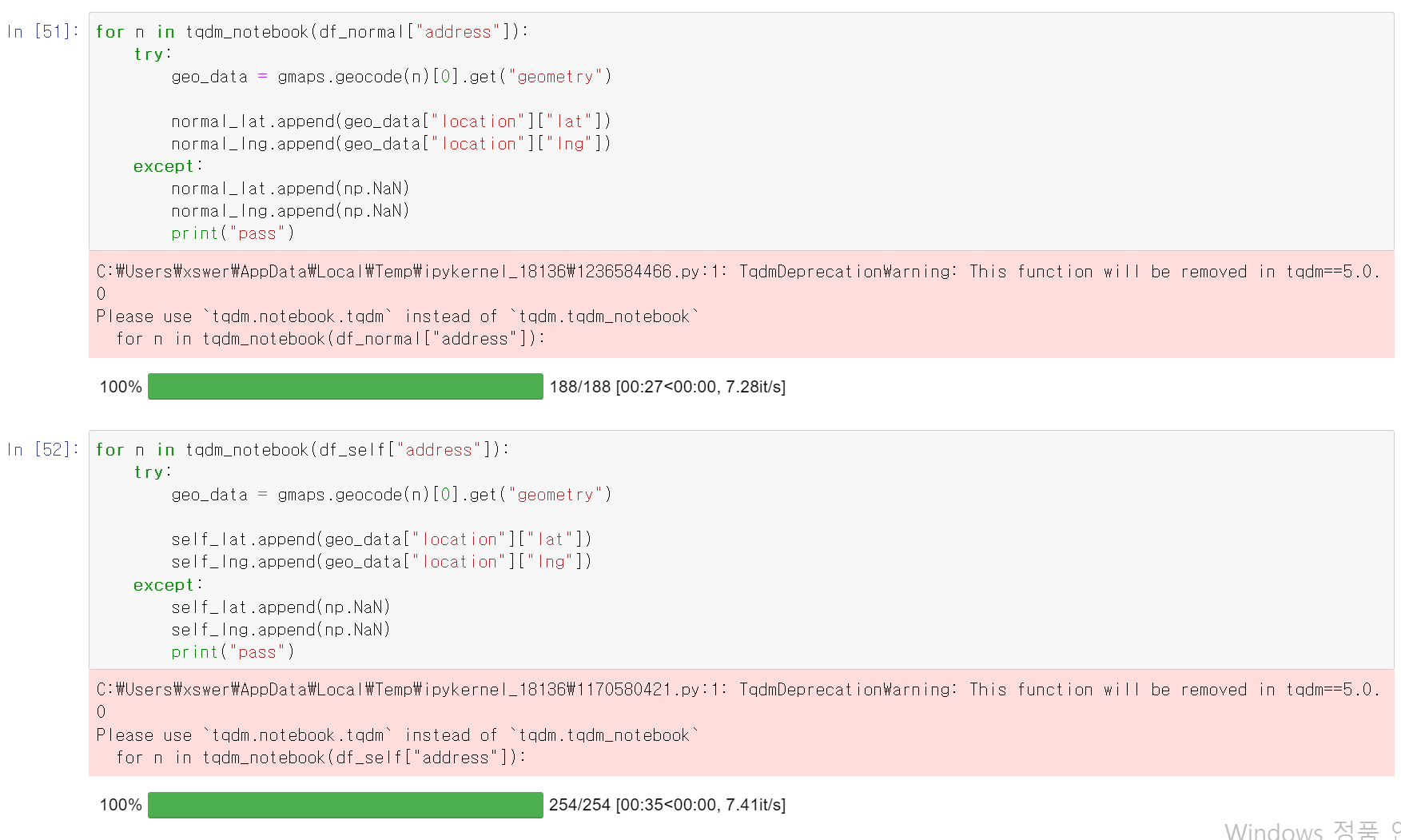
- for 반복문을 통해 주소를 변수로 각 데이터의 주소에 대한 경위도 Data를 추출
- 해당 주소에 대한 경위도 정보가 없을 시 오류 방지를 위한 NaN값을 입력
- 일반주유소 188, 셀프주유소 254개 경위도 Data 추출 완료
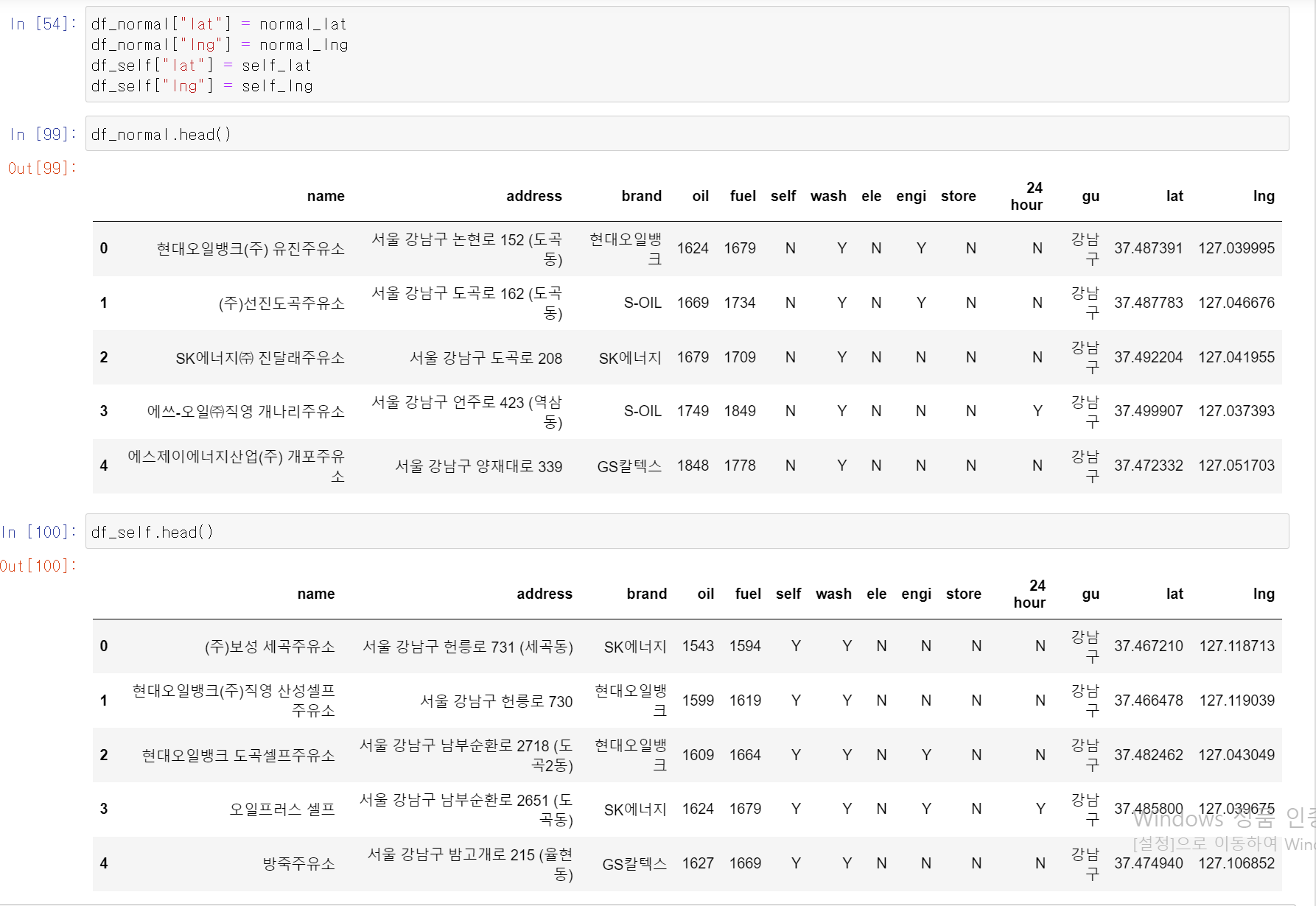
- 해당 경위도 데이터를 기존의 일반주유소, 셀프주유소 프레임에 입력
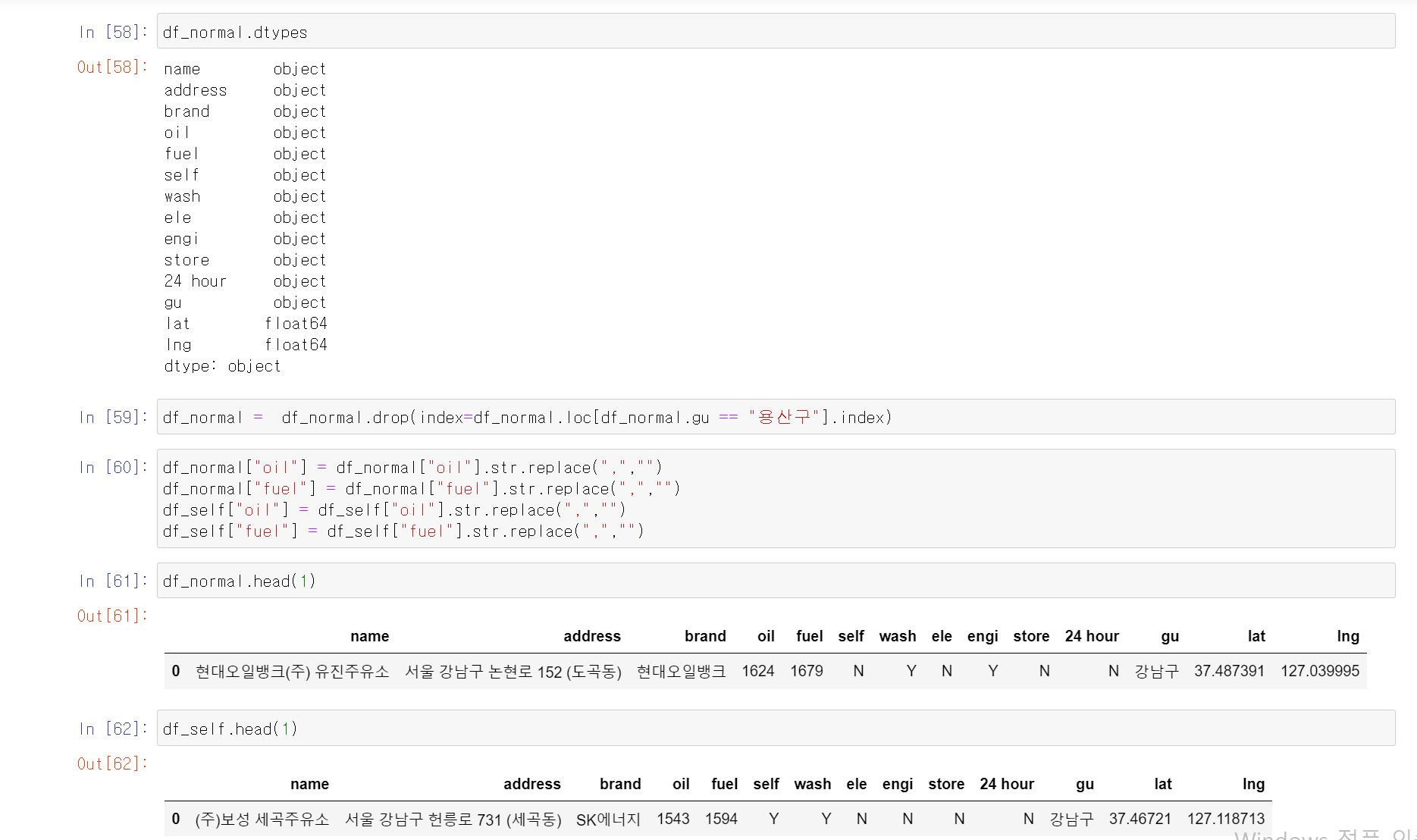
- 문제점 발견
<문제>
1. 휘발유 가격과 경유 가격을 group by를 통해 구별 평균 가격을 추출하려고 했으나,
두 개의 데이터가 int형식이 아니라 계산이 불가
2. 두 개 데이터를 astype으로 변환하려고 했으나, 해당 값에','가 있어 변환이 불가
3. 일반주유소의 경우 '용산구'에 주유소가 있지만, 셀프주유소의 경우 용산구에 데이터가
존재하지 않아 최종 데이터를 만들 때 index의 개수가 맞지 않아 오류 발생
<해결>
1. str.replce명령어를 통해 ","가 있을 경우 공백으로 교환
2. ","를 없앤 데이터를 astype으로 int로 변환
3. drop, loc 명령어를 활용해 'gu'column에 용산구가 있을 경우 해당 index를 삭제
- 일반주유소, 셀프주유소의 휘발유 가격, 경유 가격 4개 column을 int로 변환 완료

- 분석을 위한 최종 데이터 프레임을 df_reulst에 저장
- 구이름, 구별 일반주유소 휘발유 및 경유 가격 평균값, 구별 셀프주유소 휘발유 및 경유 가격 평균값을 변수로 DataFrame생성
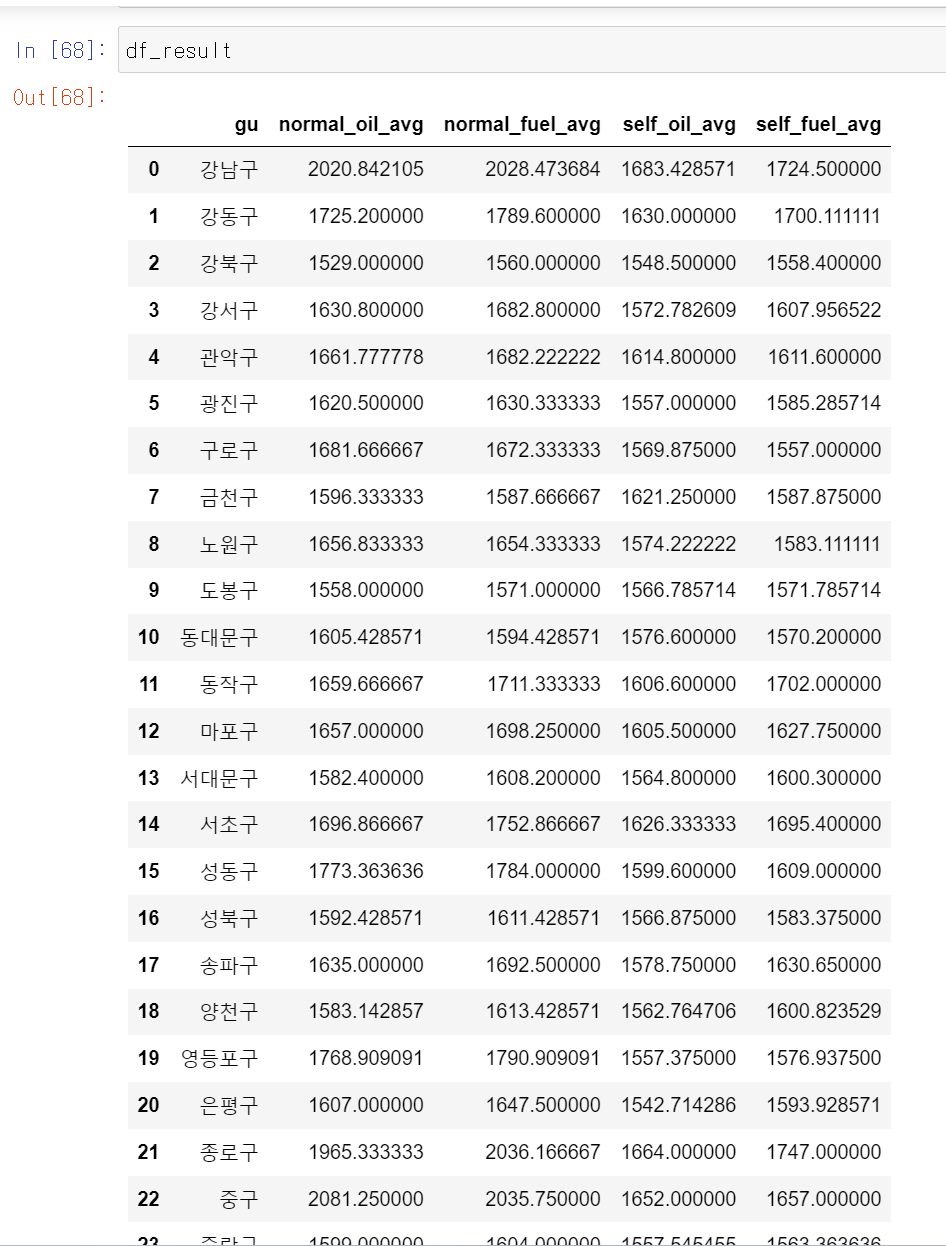
- 용산구 영역을 삭제한 24개 구에 대한 일반 및 셀프 주유소의 휘발유, 경유의 구별 평균가격 Dataframe생성

- 두 형태의 주유소 가격 비교를 위해 휘발유, 경유 구별 평균가격을 뺀 gap column 두 개를 생성

- 지도 시각화 작업을 위해 각 구마다 경위도 위치를 얻기 위해 각 구의 경위도에 대한 평균을 구함
- 다만, 각 구의 정확한 중심 위치는 아니지만 해당 구의 주유소들의 중심 위치에 대한 경위도 값 추출 성공
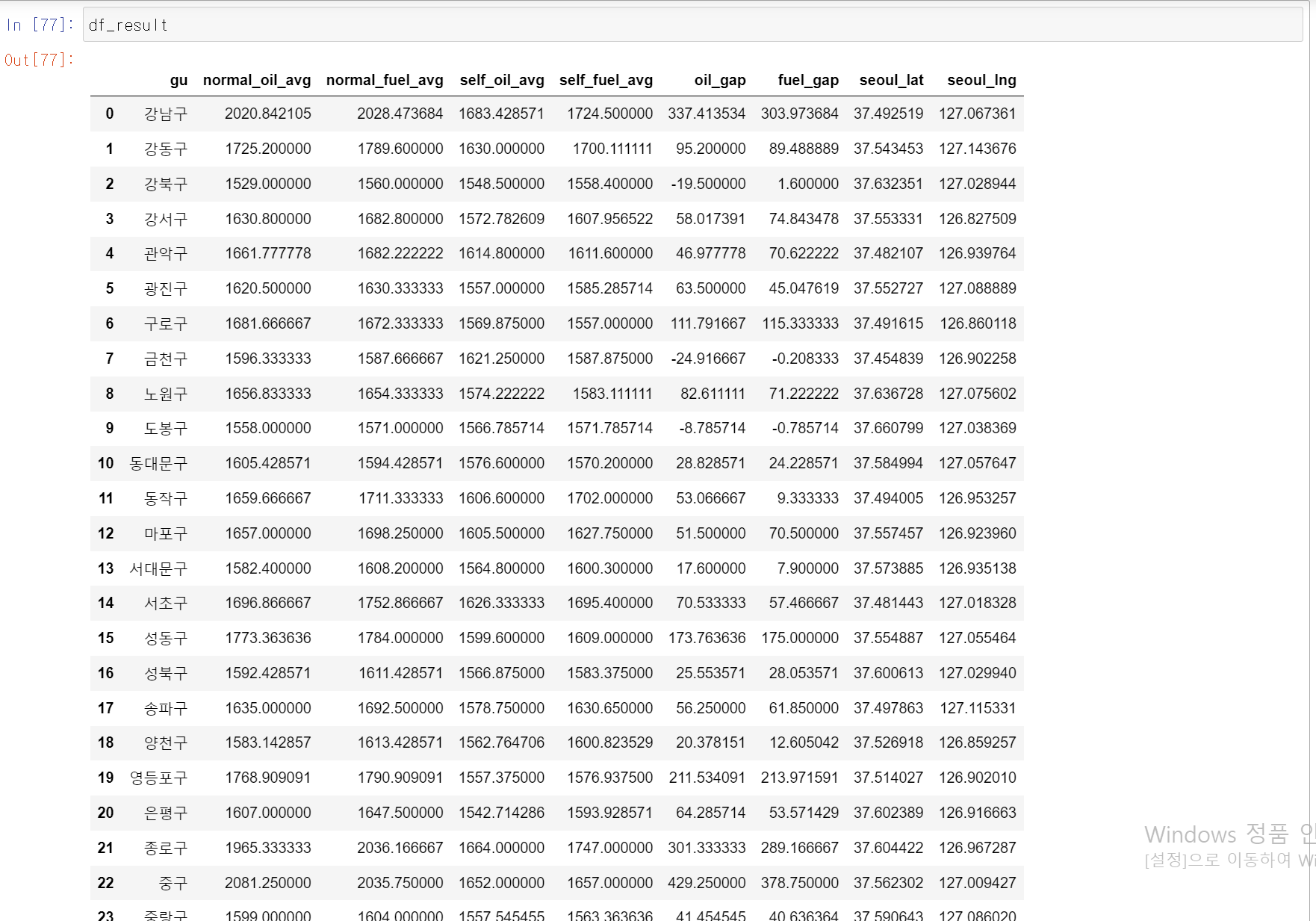
- 각구의 중심 위치를 DataFrame에 저장
6. 지도 시각화 및 분석 결과
- 휘발유 및 경유 가격에 대한 지도 시각화를 위한 밑지도 두 개를 생성
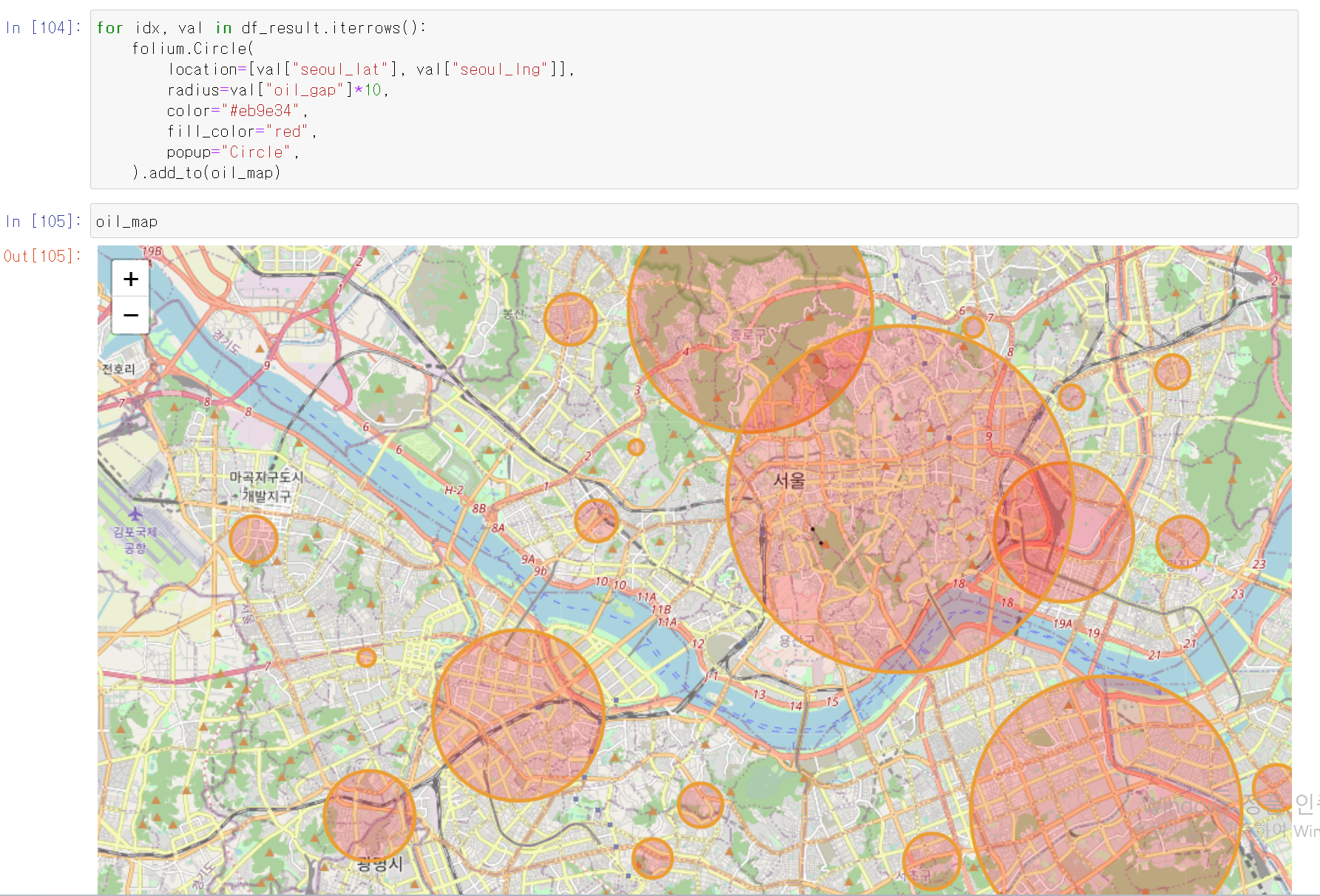
- for 및 circle 명령어를 통해 지도에 빨간원으로 gap 데이터를 표시
- 원의 크기를 두 주유소의 가격 차이로 지정했기에, 원이 클수록 일반 주유소의 가격이 셀프 주유소에 비해 큼
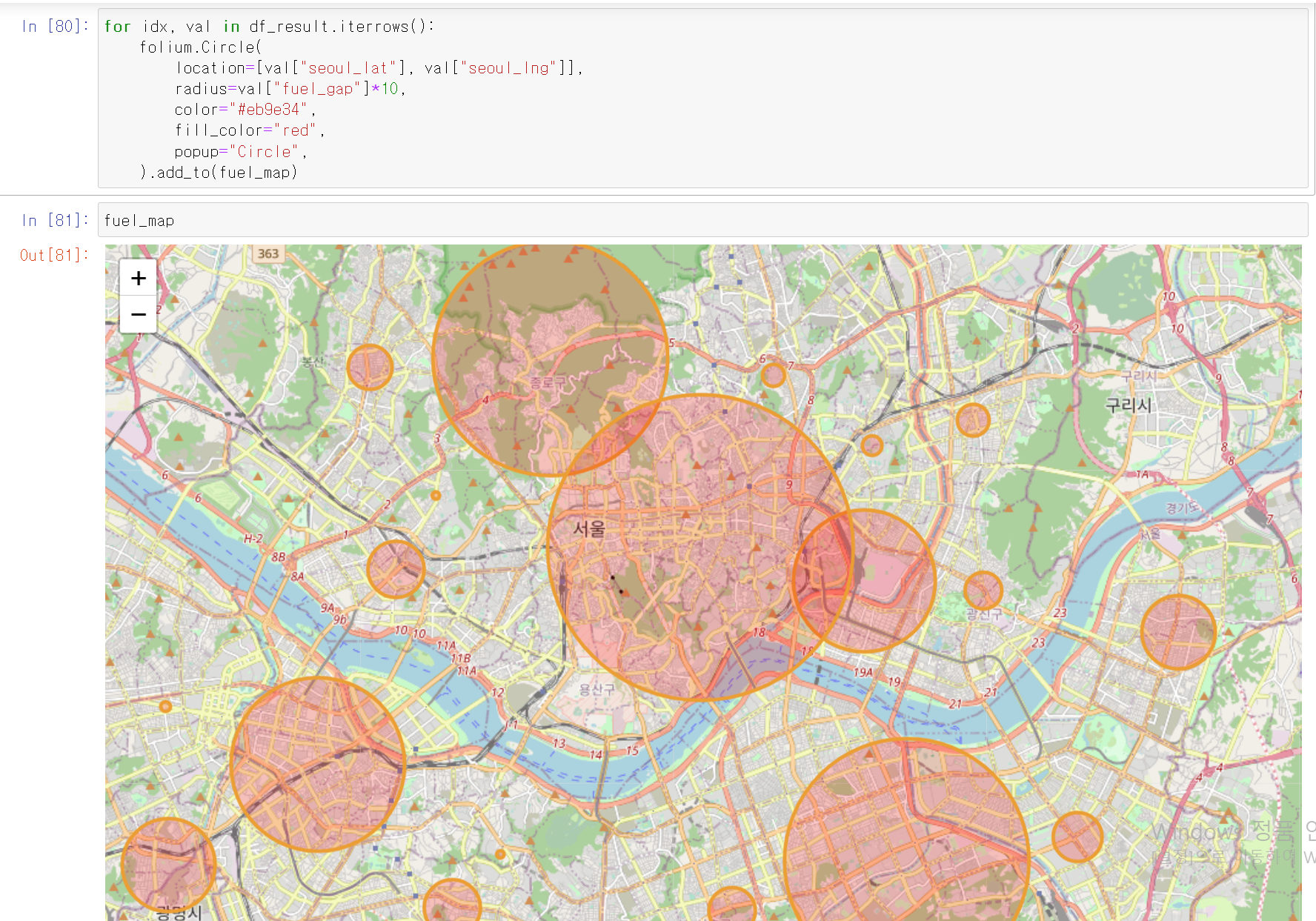
- 휘발유 지도 시각화와 같은 방법을 통해 경유에 대한 두 주유소의 가격 차이만큼 원의 크기를 설정

- 데이터 분석 결과 나의 결론

- 두 번쨰 시각화는 bar그래프 형식으로 표현
- 직관적으로 한눈에 보기에 각 구마다 차이를 보기 쉬움
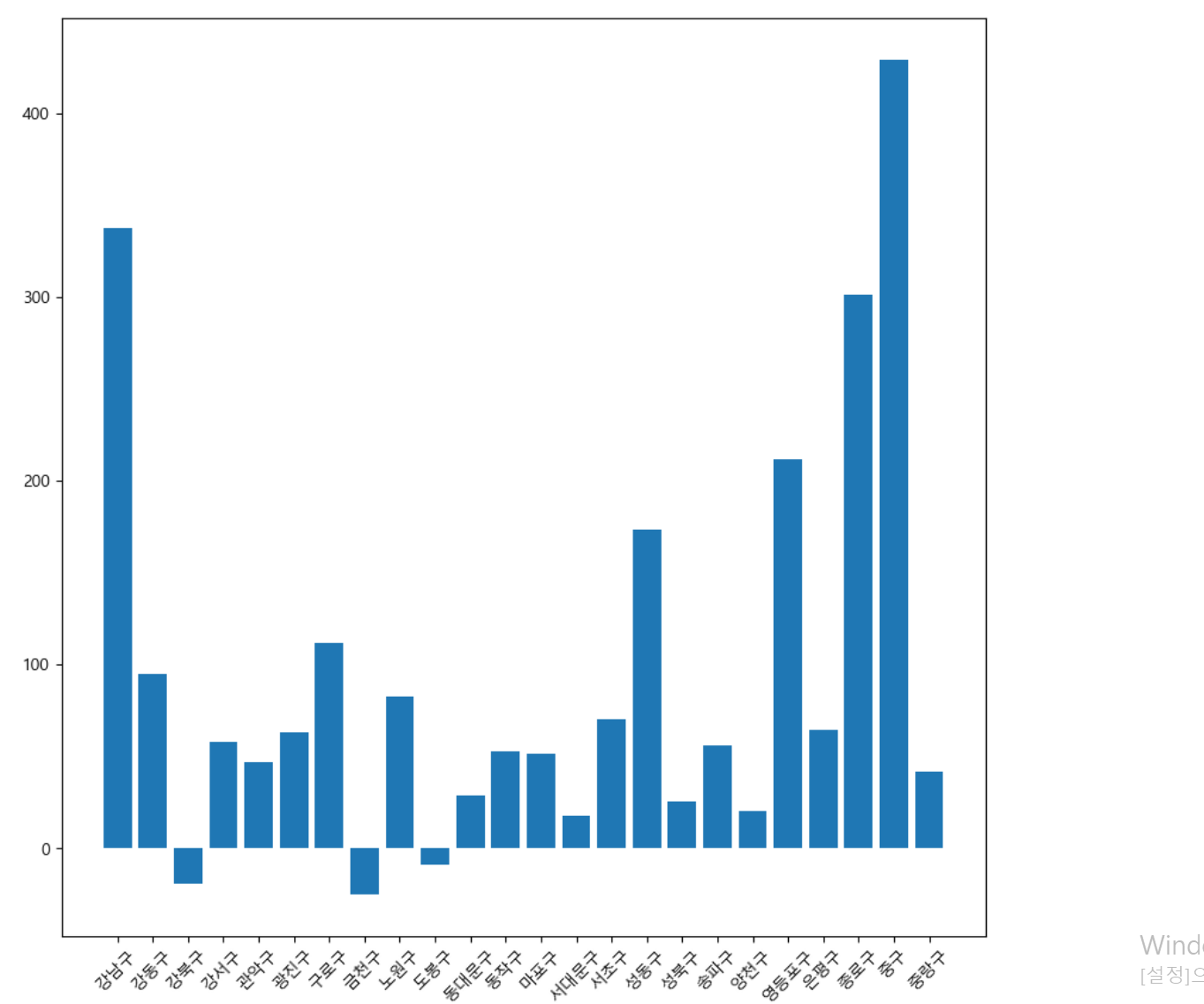
- 다만, 해당 사이트는 매일 업데이트 되기에 당시 분석 결과와 보는 시점의 결과가 다를 수는 있음
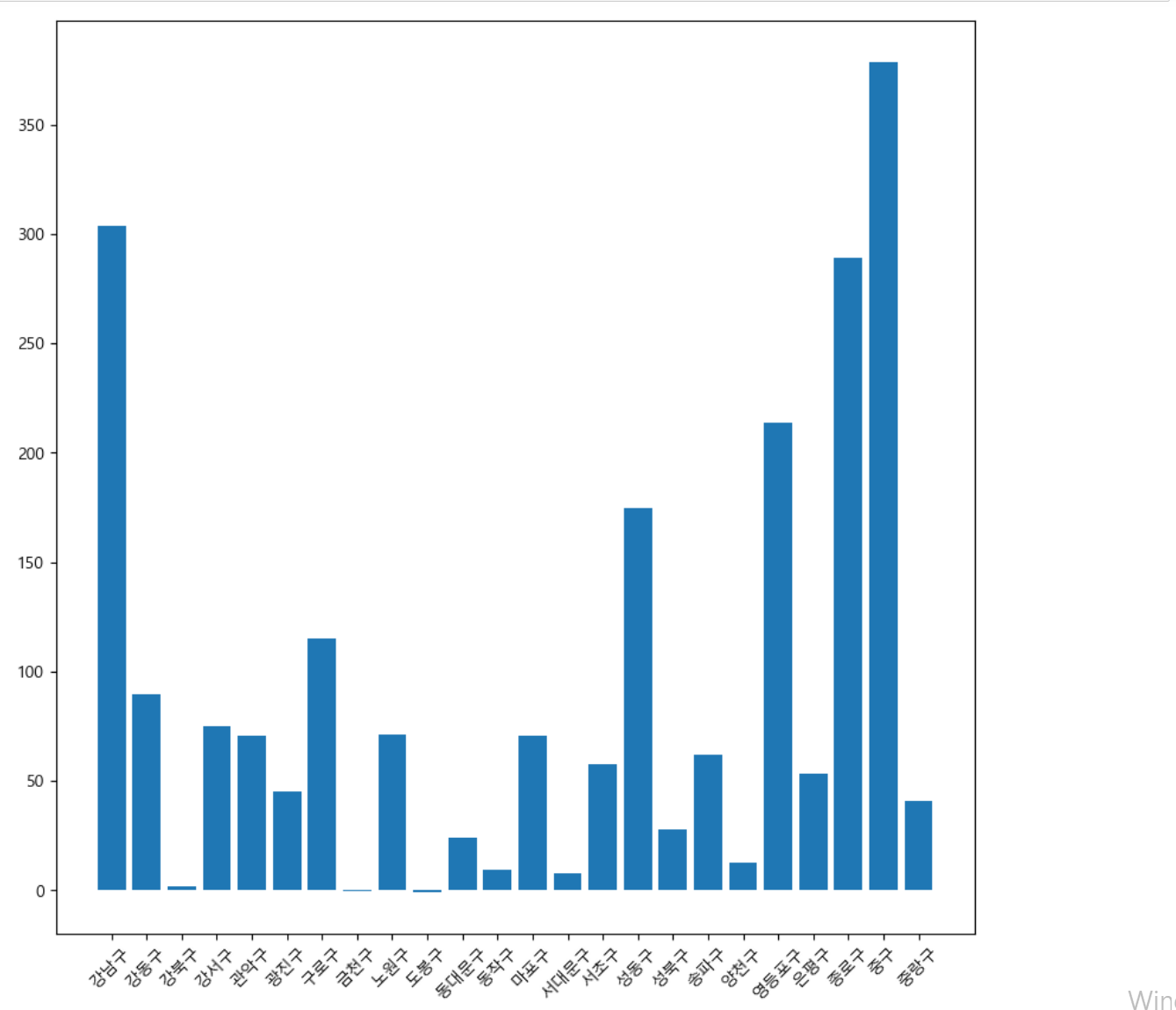
- 결과를 적은 당시와 velog 기록을 위해 다시 작업을 했을 때 가격차이가 발생하여 분석결과와 데이터의 결과가 다소 다름

- 경유에 대한 bar그래프 생성


상황을 바꿀 수 없다면, 나를 바꾸자