My_Toy_Project
1.Cafe Marketing

낭설에 이디야 브랜드가 스타벅스 브랜드 근처에 매장을 연다는 소문이 돔실제 이디야 브랜드가 해당 마케팅 전략을 사용하는지 서울시를 기준으로 조사를 진행프로젝트 목적 및 사용 모듈을 실행스타벅스 사이트에서 정보를 웹 크롤링하기 위해 selenium 모듈을 사용먼저 사이트
2.Oil Price Analysis
서울시 전체(구별 구분) 일반주유소, 셀프주유소의 데이터 전처리, 가공 및 분석분석을 통해 일반주유소와 셀프주유소의 가격 차이에 의미가 있는지 분석jupyter notebook에서 필요한 모듈 import해당 사이트에서 Data를 추출하기 전에 웹 페이지 클릭, 입력
3.Baseball_salary
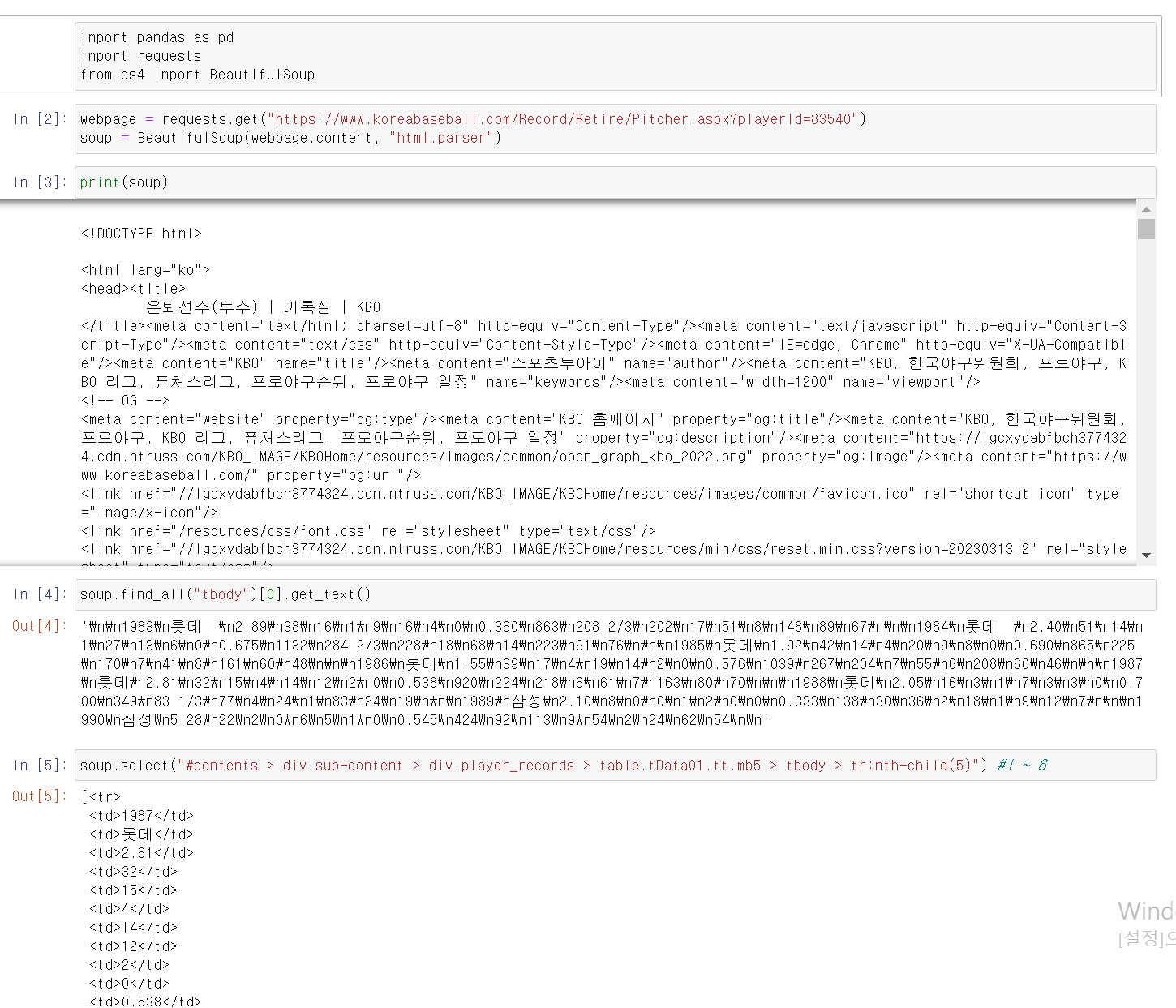
이번 Toy_project는 故 최동원 선수가 현재 KBO리그에서 활동한다면 얼마의 연봉을 받을 수 있을지 머신러닝을 통한 예측을 해보자먼저, 故 최동원 선수의 투수로서 데이터를 추출하고, 최근 선수들의 기량 데이터와 비교 및 분석 후 최근 선수들의 연봉을 Label값
4.Internet_Use_Data
이번에는 인구수, 인터넷 사용량, 지역 등 3개의 데이터를 통해 인터넷 사용 정도에 대한 데이터를 가공 및 전처리를 해보자먼저 1인당 소득, 1인당 인터넷 사용량, 요금에 대한 데이터를 불러온다.데이터의 정보를 보니 국가는 string, 나머지는 float형태로 저장되
5.Museum_Data

이번에는 대한민국의 박물과 및 미술관의 데이터를 전처리해보자 가격, 사용 시간, 요금 등 다양한 측면에서 분석하기 쉽도록 데이터를 가공할 예정이다. 가장 먼저 json파일을 변수에 저장했다. 제이슨 파일의 형태를 보니, fields 키값에 데이터의 컬럼이 저장되어
6.Seoul_Smoking

이번에는 서울시 흡연 자료를 바탕으로 데이터 전처리 과정을 가져보자기본 데이터 프레임의 위와 같으며, 구분1과 구분2에 따라 데이터의 수치가 집계되어 있다.일단 보기 편하게 데이터프레임의 이름을 바꾸고, 시 단위의 경우 서울시밖에 없기 때문에 '시'로 바꿔주고 구분1에
7.Movie_rank
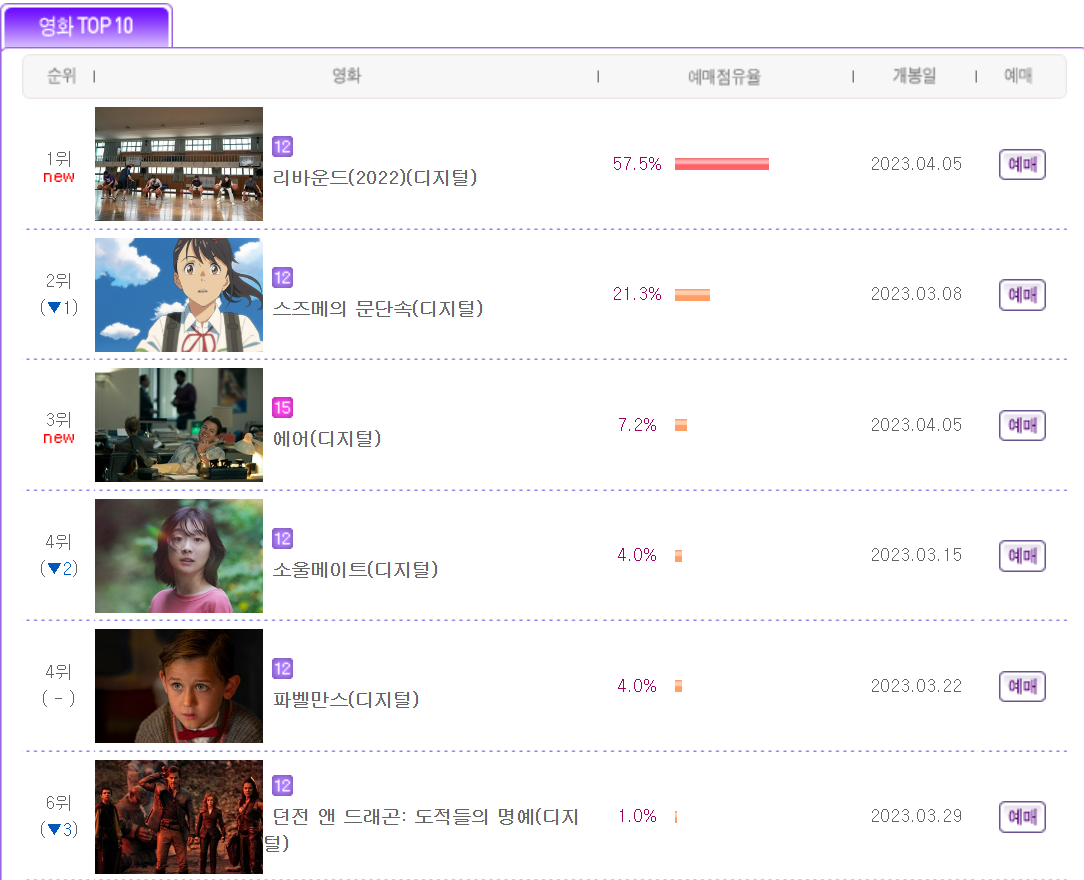
이번에는 인터파크의 영화 예매 순위(1~10위)를 Web_crolling을 통해 Data를 가공해보자가장 먼저 크롤링을 하기 위해서 모듈과 해상 사이트의 url를 가지고 왔다.그리고 특정 주간(목~일)의 데이터를 뽑기 위해 webdriver의 send_key를 통해 날
8.Seoul_Station

이번에는 서울 지하철의 유동인구에 대한 데이터를 전처리 및 분석하는 시간을 가졌다.먼저 필요한 데이터를 프레임 형태로 불러왔다.먼저 중복 데이터를 확인하기 위해 작업일자를 제외한 column들을 기준으로 중복값을 지웠다.이후 사용월, 호선과 지하철역이 동일할 경우 하나
9.Olympic

이번에는 올림픽 메달 기록을 통해 데이터 전처리 및 분석 작업을 수행했다.먼저 분석을 위한 데이터를 불러왔다데이터의 정보로는 주최도시, 연도, 종목, 성별, 국가, 메달의 종류 등이 있다.데이터의 info를 확인해보니 대체로 데이터의 타입이 오브젝트 형태로 존재하며,
10.Terror

이번에는 테러 데이터를 바탕으로 분석 및 민간인에 대한 테러를 멈춰야한다는 주장을 했다.먼저 데이터를 불러왔는데, 135개의 컬럼이 존재한다.해당 데이터를 캐글의 데이터를 바탕으로 분석을 했다.먼저 필요한 컬럼을 불러왔다.연도, 달, 일, 국가, 사망자, 부상자 등의