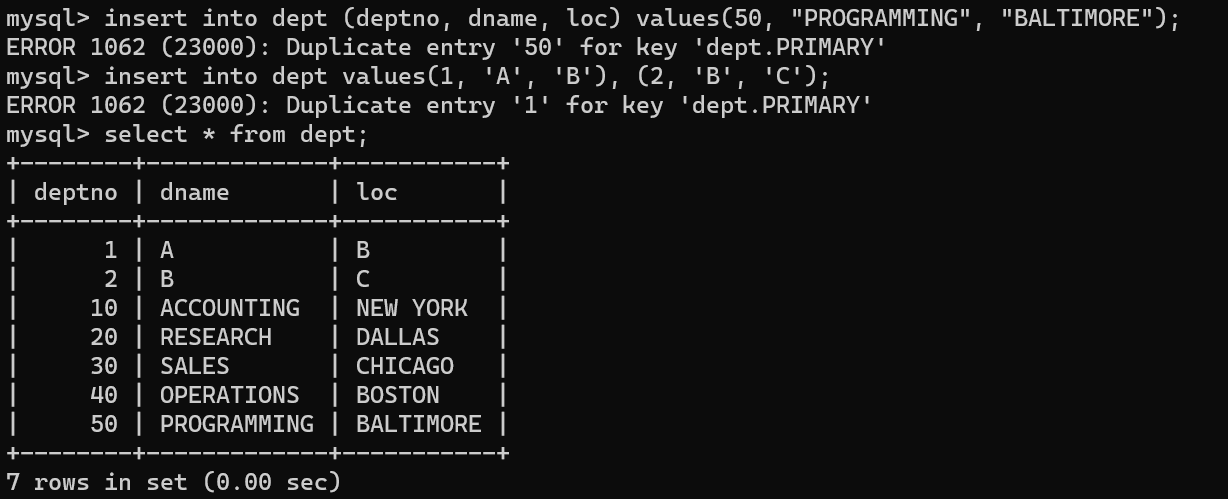
- 테이블에 데이터를 넣을 때 처음 문법 처럼
insert into <tablename> (<column1, column2>) values(<data>)
혹은
insert into <tablename> (<column1, column2>) values (dataset1), (dataset2)- 처음 코드는 하나의 데이터 셋을 넣는 방식이고, 두번 째는 여러 데이터를 넣을 때 튜플 형태로 여러 데이터를 넣을 수 있다. 또한, column부분의 경우 테이블의 column의 수와 동일한 데이터셋을 넣는다면 넣지 않아도 괜찮다.
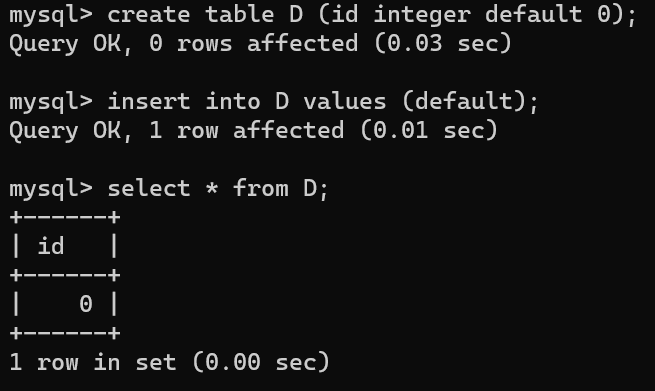
- 테이블 생성 시 default 값을 줌으로써 insert 시 기본값으로 설정한 데이터를 자동적으로 넣을 수 있다.
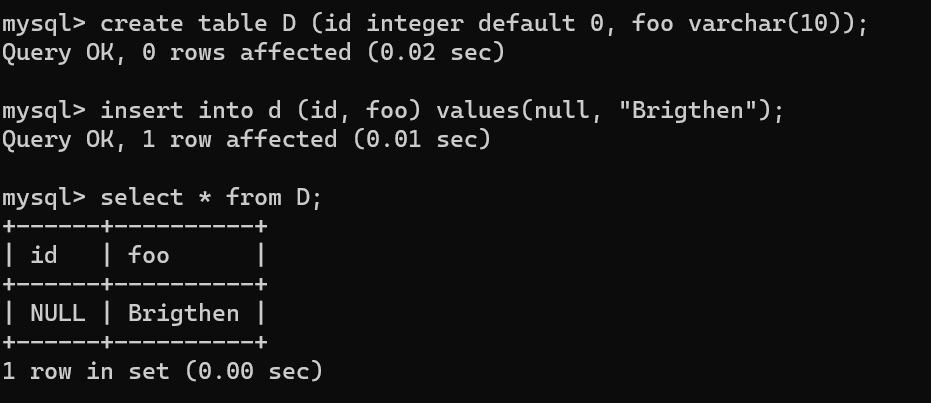
- 만약 default값을 설정했어도 insert 구문에 null값을 넣음으로써 빈값으로도 만들 수 있다.
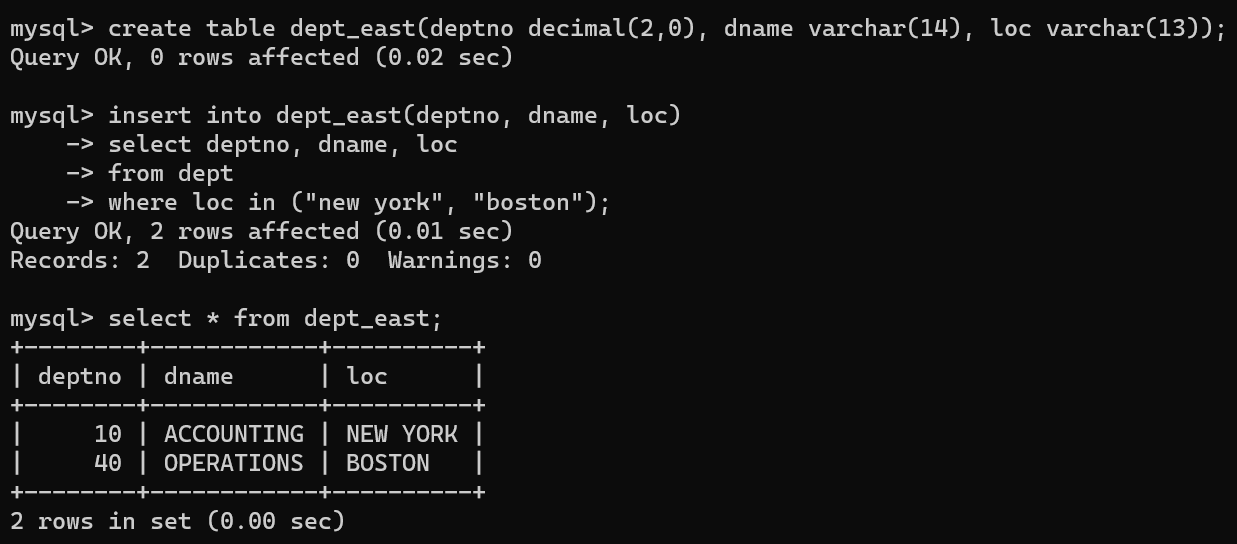
- 테이블에 데이터를 넣을 때 단순히 데이터를 입력하는 것이 아니라, 다른 테이블에서 select 구문으로 where절에 조건을 걸어 원하는 데이터만 뽑아올 수 있다.
- 위 코드의 경우 장소가 뉴욕, 보스톤인 데이터만 뽑아서 dept_east 테이블에 데이터를 넣었다.
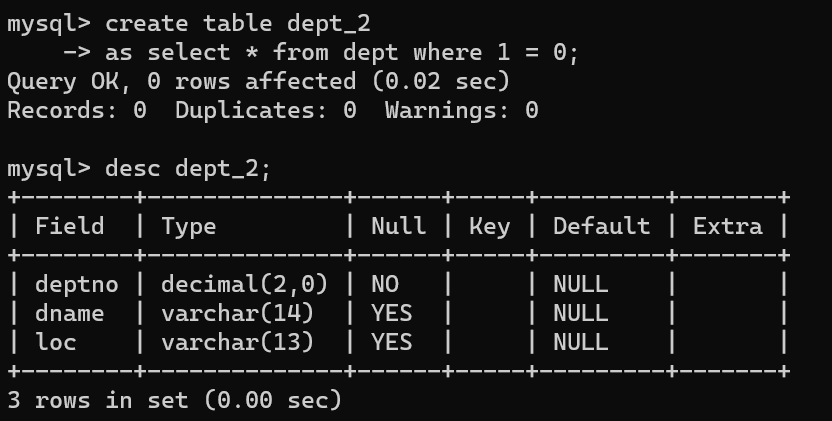
- 이번엔 데이터를 복사해서 테이블에 넣는 것이 아니라, 테이블의 형태(컬럼 속성)를 복사해서 새로운 테이블을 만드는 방법이다.
create table <tablename> as select * from dept where 1=0- where 1=0 부분이 중요한데 조건을 걸어주지 않을 시 데이터도 같이 복사된다.
- dept_2 확인 결과 정상적으로 dept의 테이블 속성이 복사됐다.
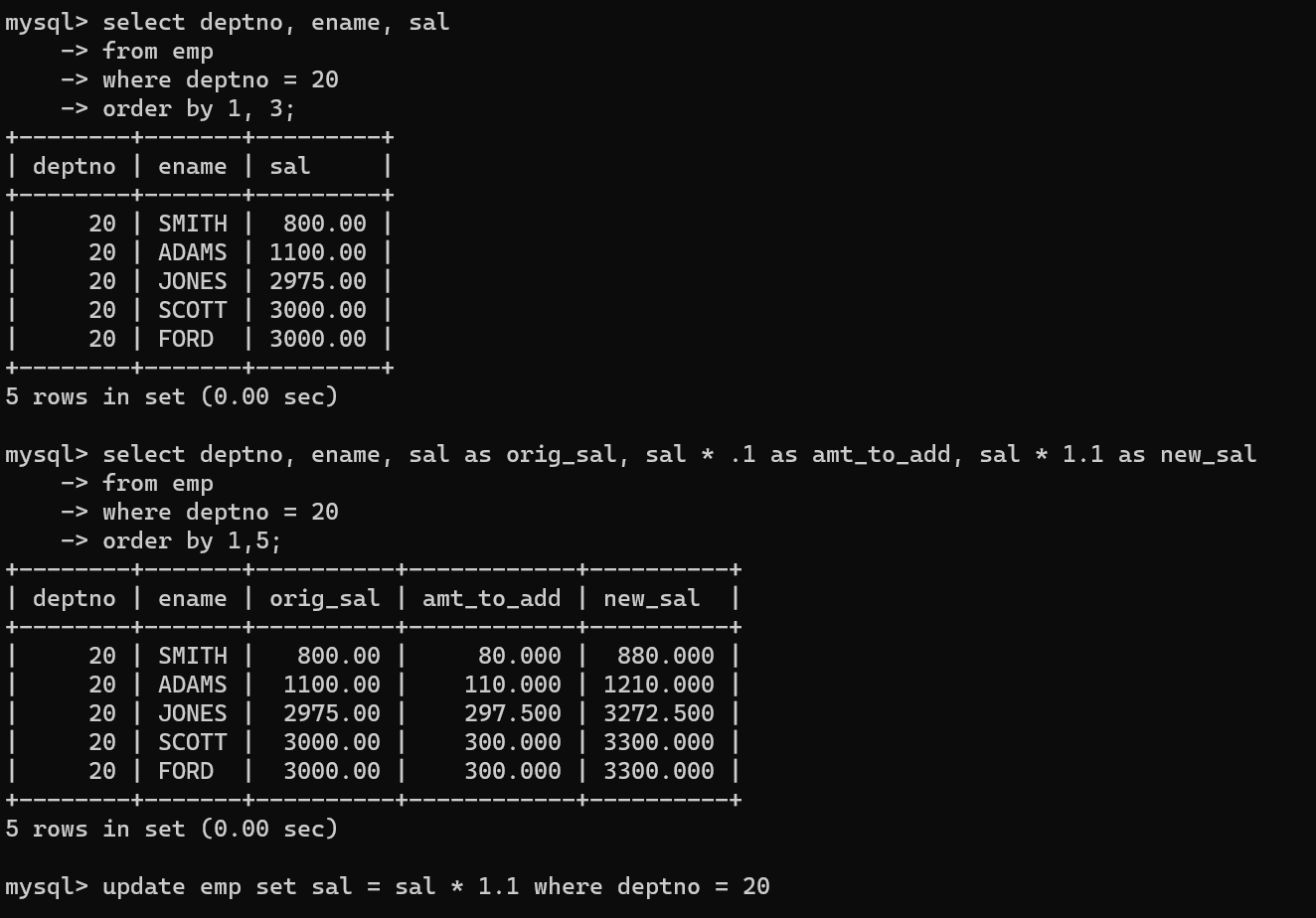
- 테이블의 자료를 일괄적으로 수정하는 방법도 있다.
update <tablename> set <update내용> where condition- update내용에 원하는 컬럼의 수정사항을 넣으면 일괄적으로 수정된다.
- 수정 전 먼저 내용을 확인하고 싶다면 select 구문을 통해 먼저 확인하고 수정할 수 있다.
- 두번 째 코드를 보면 사무실 번호가 20이라는 조건을 통해 월급, 월급의 인상 폭, 인상된 월급 3개의 컬럼을 통해 데이터 업데이트와 관련된 내용을 미리 select 구문을 통해 볼 수 있다.

- where절에 다른 테이블의 쿼리를 불러와서 조건으로 사용해서 조건에 따른 update 또한 가능하다.
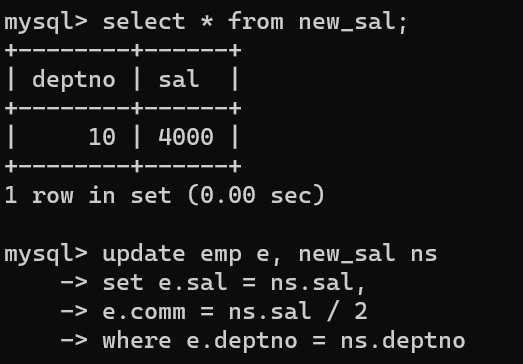
- new_sal이라는 새로운 테이블을 만들고,
- emp테이블의 deptno의 데이터와 new_sal deptno의 번호가 같을 경우 emp의 sal을 new_sal의 데이터로 바꾸고, emp comm의 값은 new_sal의 반의 값으로 저장할 수 있다.
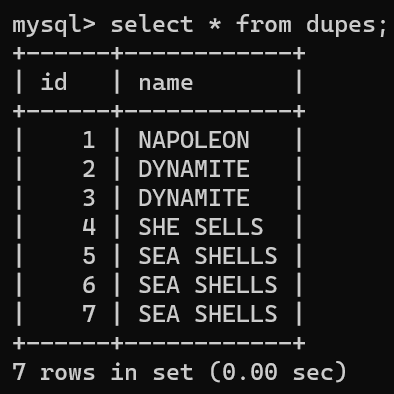
- 다음은 중복 레코드 삭제이다.
- 먼저 dupes라는 중복 데이터 존재하는 테이블을 만든다.
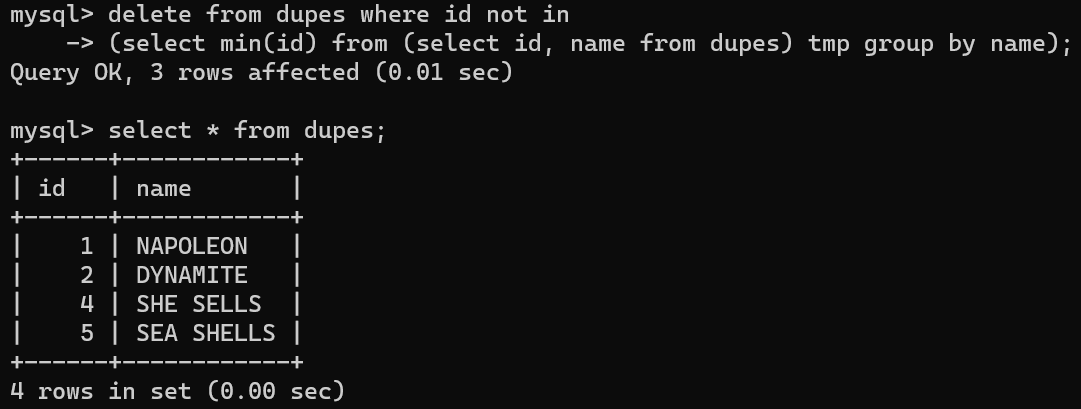
- 이후 where 조건문에 서브쿼리를 사용해서 중복값이 있을 경우 삭제하는 코드를 입력한다.
- 해당 코드만 볼 경우 이해하기 힘들 수 있는데,
select min(id) from (select im name from dupes) tmp group by name 코드 결과는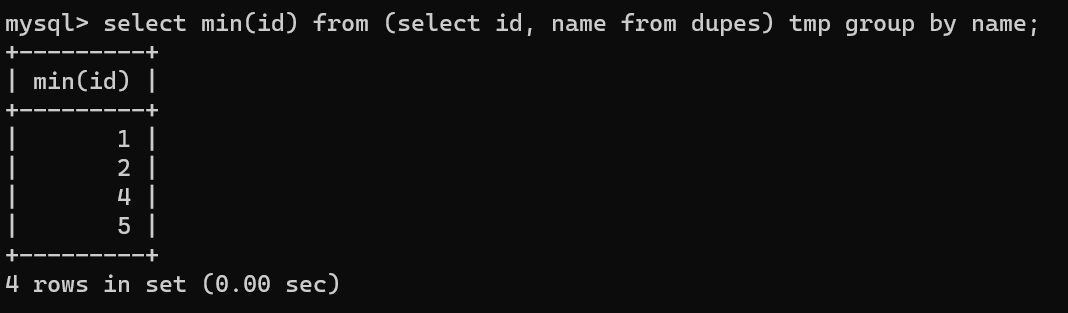
-
id의 최저값을 name별로 그룹으로 데이터를 뽑아서 name이 중복되지 않는 id의 고유값이 나온다
-
그렇기 때문에 해당 데이터에 존재하지 않는 경우 삭제를 하고 중복값을 없앨 수 있다.
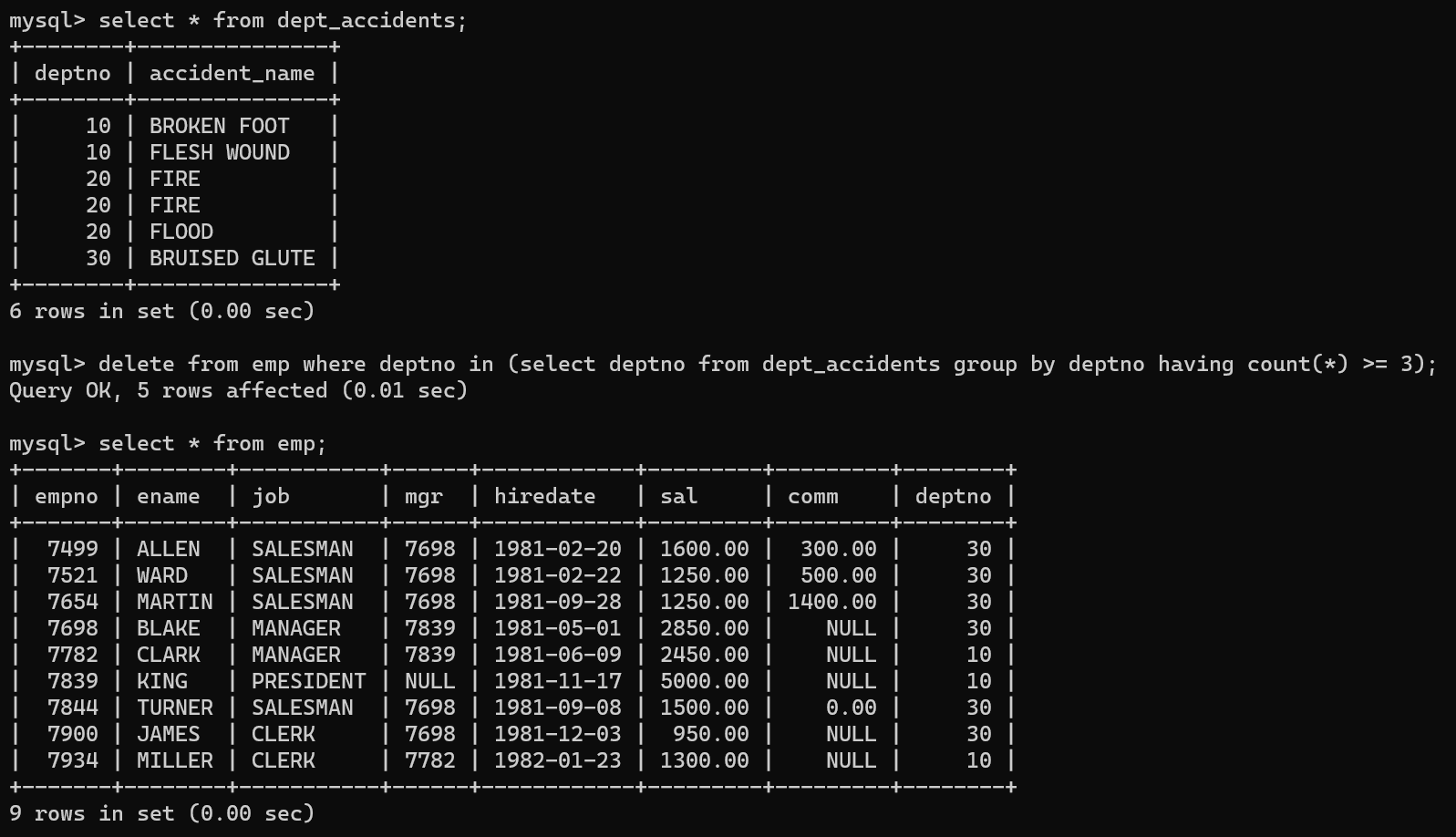
-
이번에는 dept_accidents라는 테이블을 만들고,
-
사무실 번호별로 카운터를 만든 후 카운터의 횟수가 3회 이상일 경우의 데이터셋을 뽑아 해당 데이터셋에 사무실 번호에 해당하는 정보를 삭제하는 코드를 입력했다.
-
그 결과로 emp테이블에 deptno번호가 20인 데이터 모두가 삭제됐다.
-
레코드의 입력, 업데이트, 삭제는 간단하지만 가장 기본적인 문법으로 정말 중요하다. 그렇기 때문에 기초를 튼튼하게 기억하자.

상황을 바꿀 수 없다면, 나를 바꾸자