- 이번에는 금융권 데이터를 가지고 데이터 분석과 머신러닝 알고리즘을 활용해보자
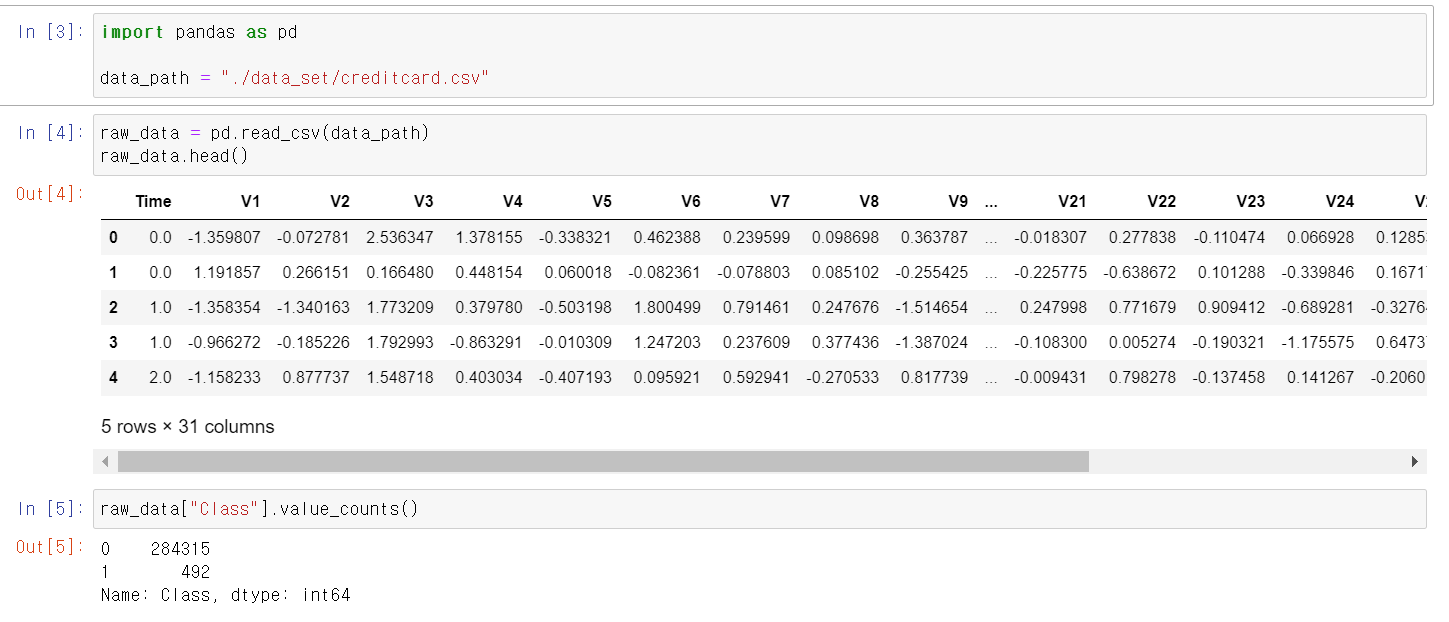
- 금융권 데이터는 개인정보가 많기 때문에 컬럼의 이름이 Vn으로 저장되어 있다.
- Class의 unique값은 0, 1이 있는데 0은 정상적인 신용카드 사용자, 1은 불법 신용카드 사용자다.
- Class를 제외하고 나머지 데이터를 교육시켜 input데이터를 통해 Class를 구별해보자
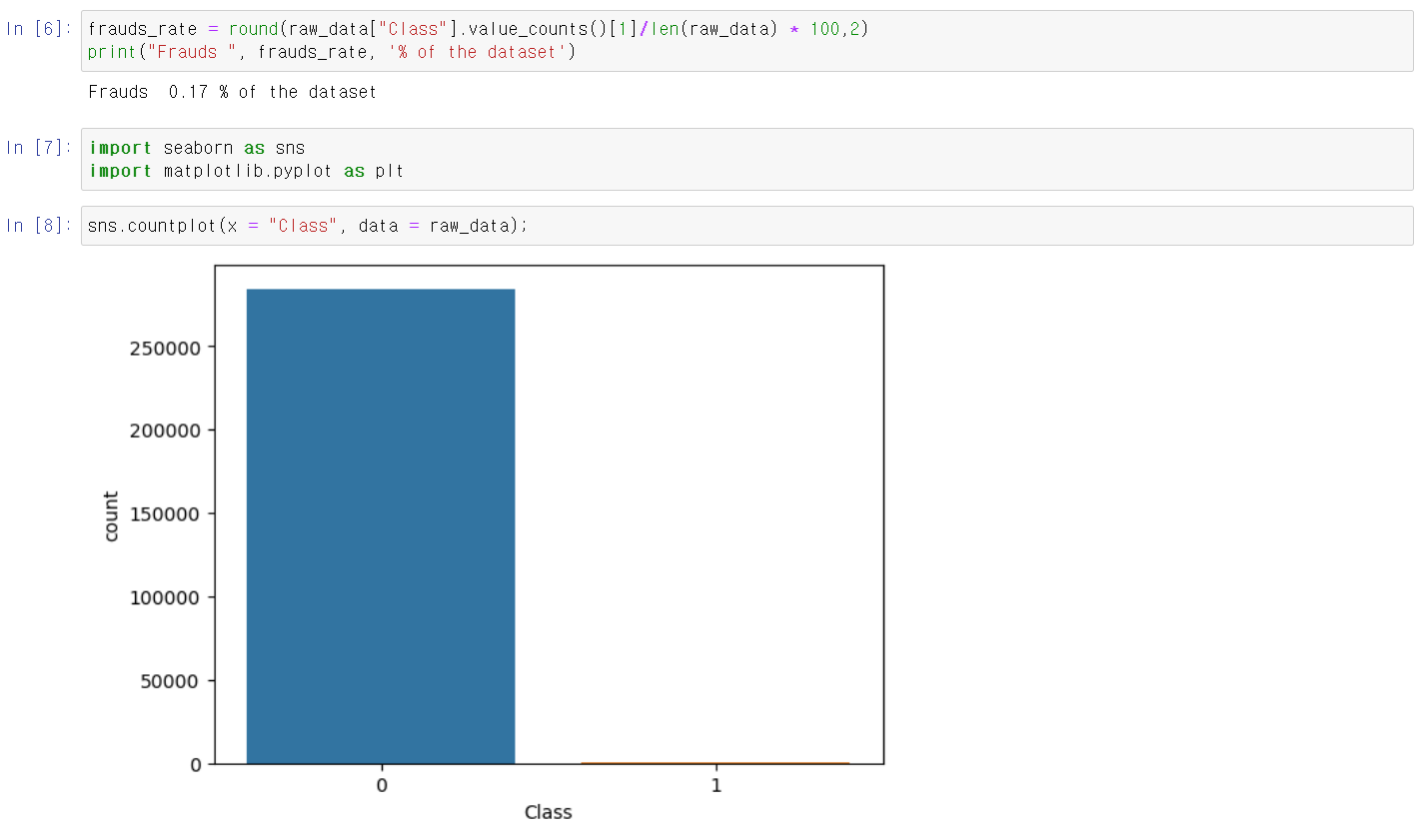
- 먼저 Class에서 1 count의 비뷸은 0.17%로 두 값의 편차가 매우 심하며, 해당 데이터를 시각화했다.
- 이제 x변수에 교육시킬 데이터를, y데이터에 정답인 label을 저장하고
- 두 데이터의 index값 또한 일치하기에 정상적이다.
- 이제 sklearn에 train_test_split 모듈을 사용해 데이터를 8:2로 train데이터와 test데이터로 구분하고
- y_train 데이터 안에서도 1, 0이 정상적으로 구분되어 있으며, 0.17%로 기존 데이터와 같은 비율을 보여준다.
- 위에 함수는 y_test(테스트 데이터의 라벨)와 교육시킨 모델링에 x_test데이터를 넣어 예측한 값을 넣으면 각 지표를 출력해주는 함수이며,
- 밑에 함수는 coufusion_metrix와 각 지표를 print해주는 함수이다.
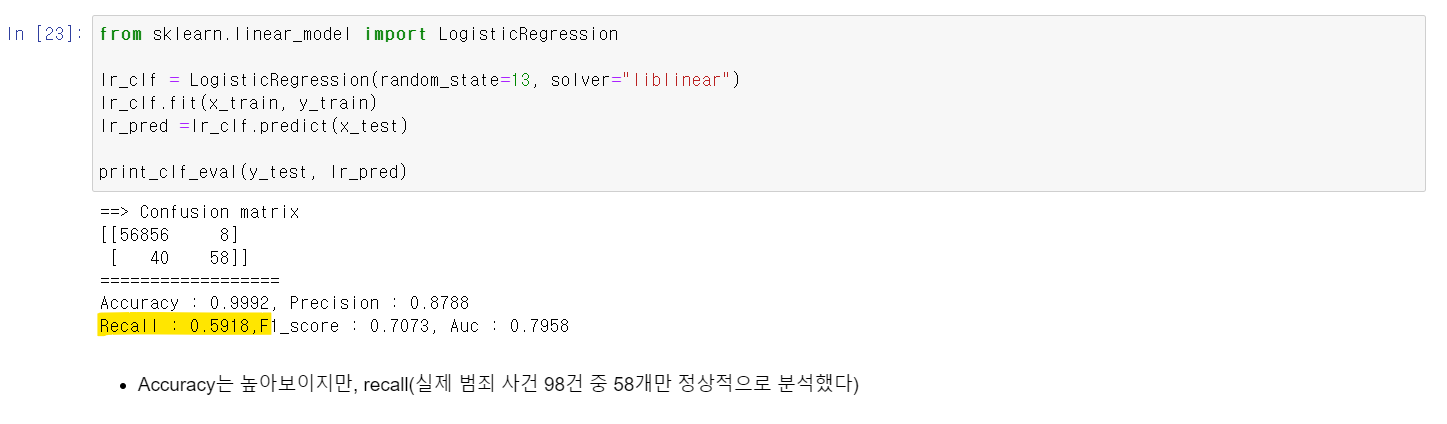
- 이제 가장 먼저 LogisticRegression으로 모델링을 시킨 결과 99%의 정확도를 보여준다.
- 하지만 Racall이 상당히 낮은데, 98개 불법 사용자 데이터 중 58개만 예측을 성공했다.
- 즉, 정확도는 높지만, Recall값이 너무 낮기에 좋은 모델성능을 보여줬다고 하기 어렵다.
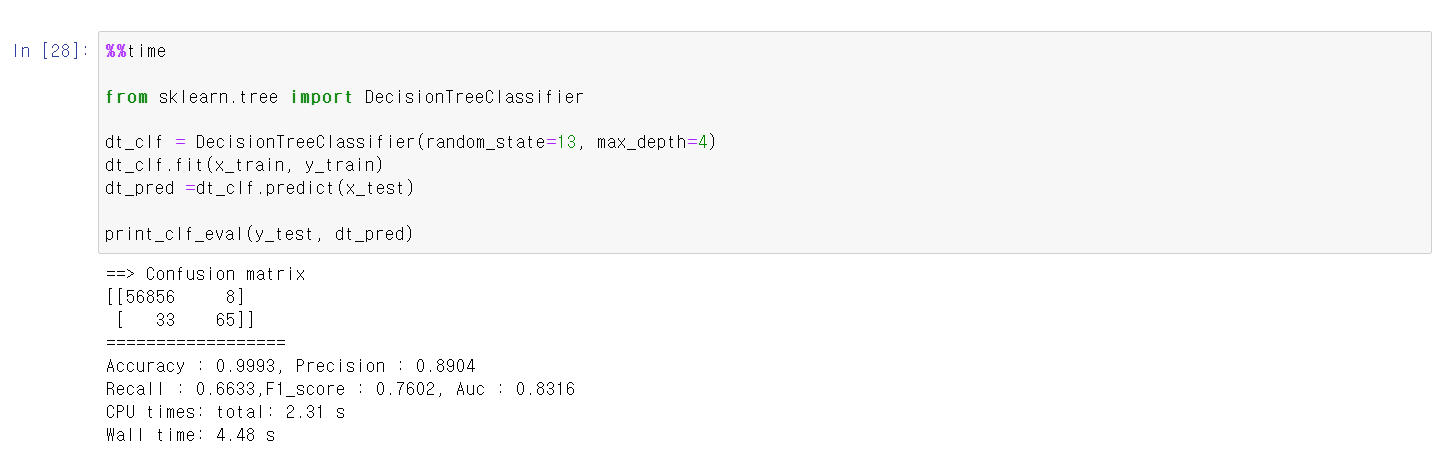
- 그래서 이번에는 DecisionTree를 통해 데이터 예측 모델을 만들었다.
- DecisionTree에 모델링을 시킨 후 데이터 예측값과 테스트 라벨값을 분석 결과 98개 중 65개를 맞히며 조금 더 좋은 성능을 보여준다.
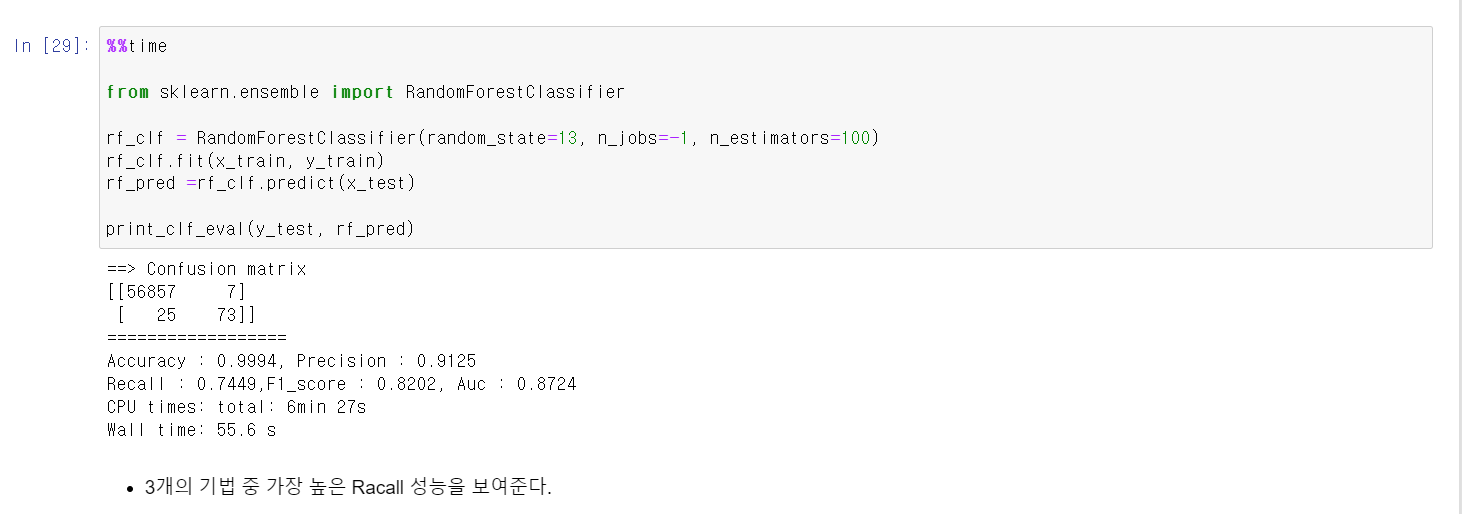
- 하지만, 여전히 성능이 만족할만하지 않기에 가장 무난하게 좋은 RandomForest를 사용해서 모델링을 시켜봤다.
- 이번에는 Recall값이 74%까지 올라가면 98개 중 73개를 정확히 예측했다.
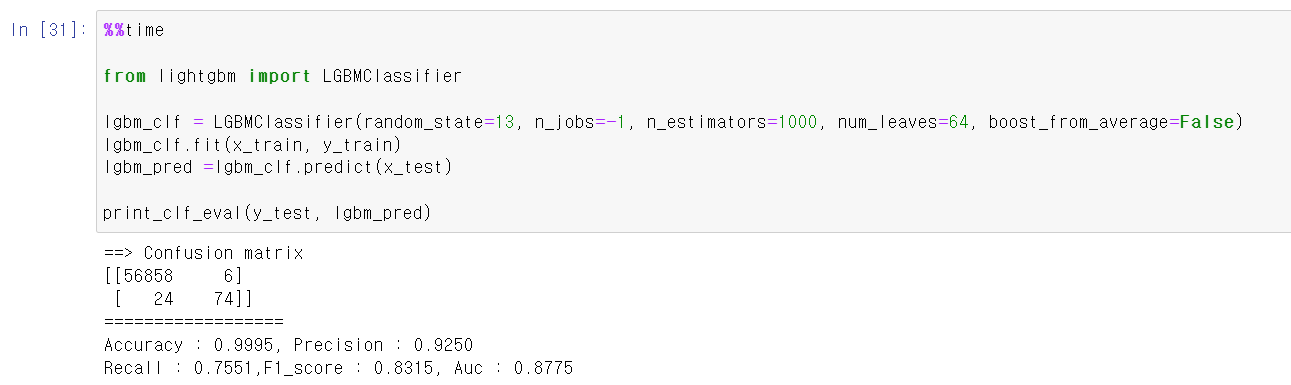
- 마지막으로 lgbmclassifier 모델기법을 사용했다.
- Recall값이 큰 차이는 없지만, lgbmclassifier기법이 확실히 빠르다는 장점이 있었다.

- 이제 각 기법에 따른 값을 보기 좋게 하기 위해 DataFrame으로 만드는 함수를 만들고,
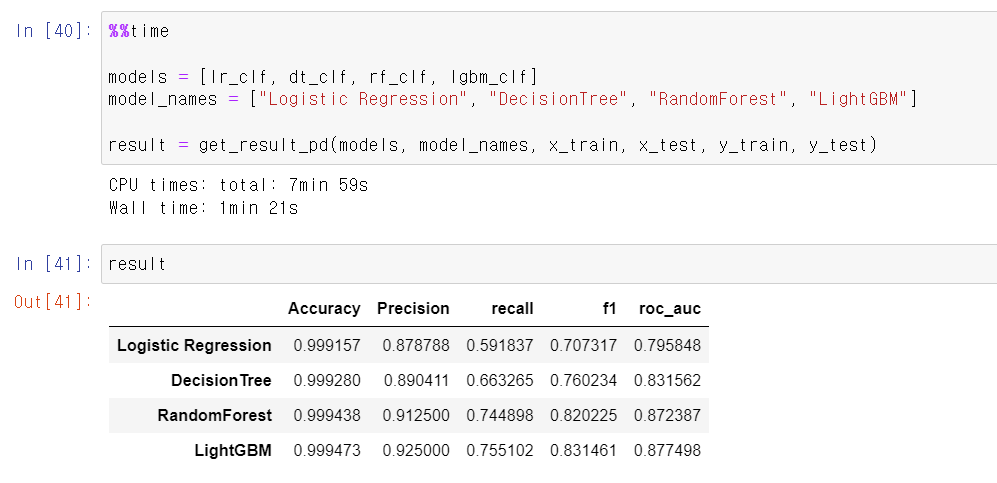
- 각 기법을 넣은 리스트를 넣어 위에 만든 함수를 불러서 결과값을 만들고, 해당 값을 데이터프레임으로 만들었다.
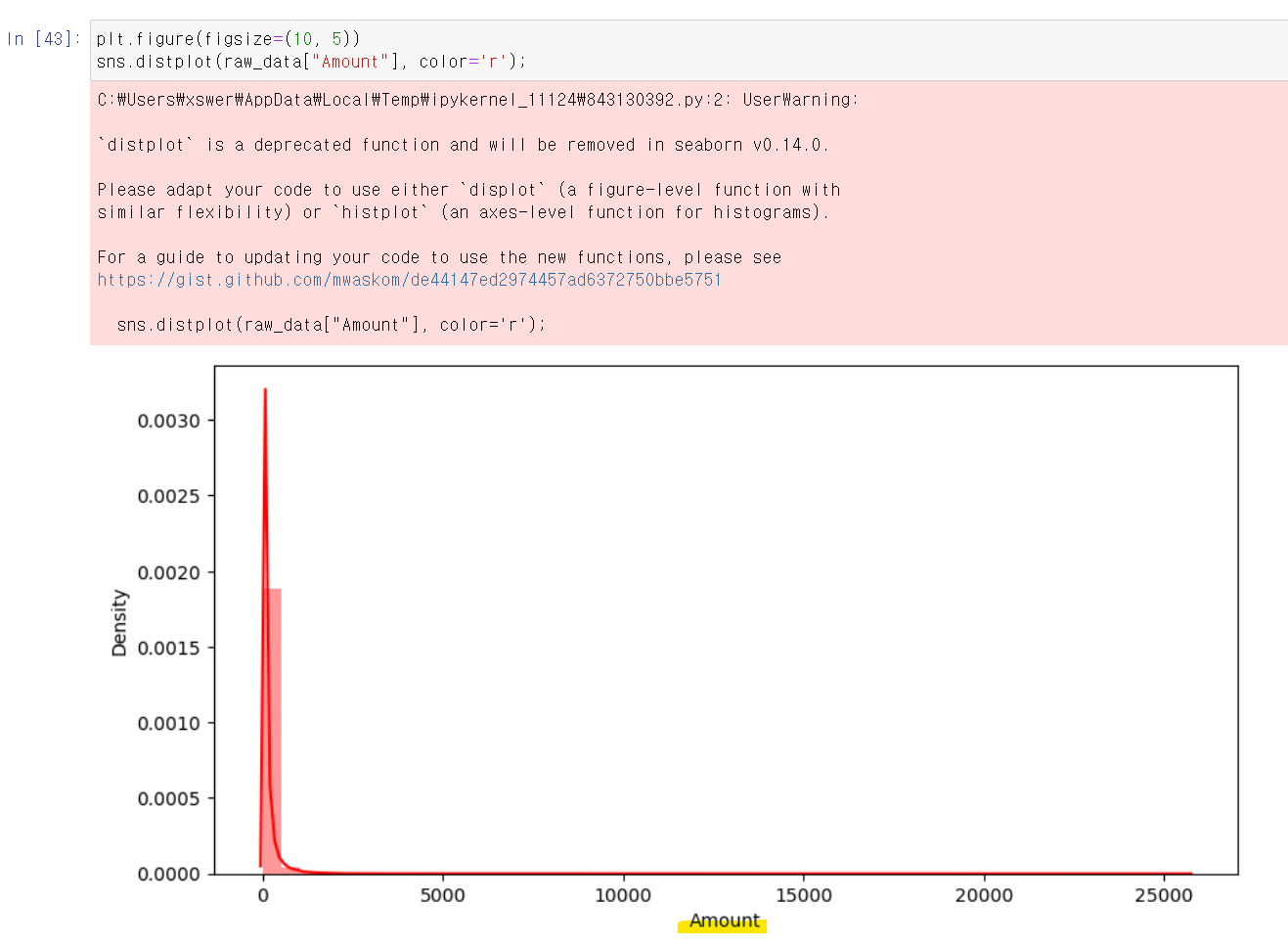
- 하지만 분석 과정에서 가장 큰 문제는 Amount컬럼의 값이 편차가 심하다는 것이었다.
- 그래서 해당 문제를 해결하고 다시 모델링을 시도했다.
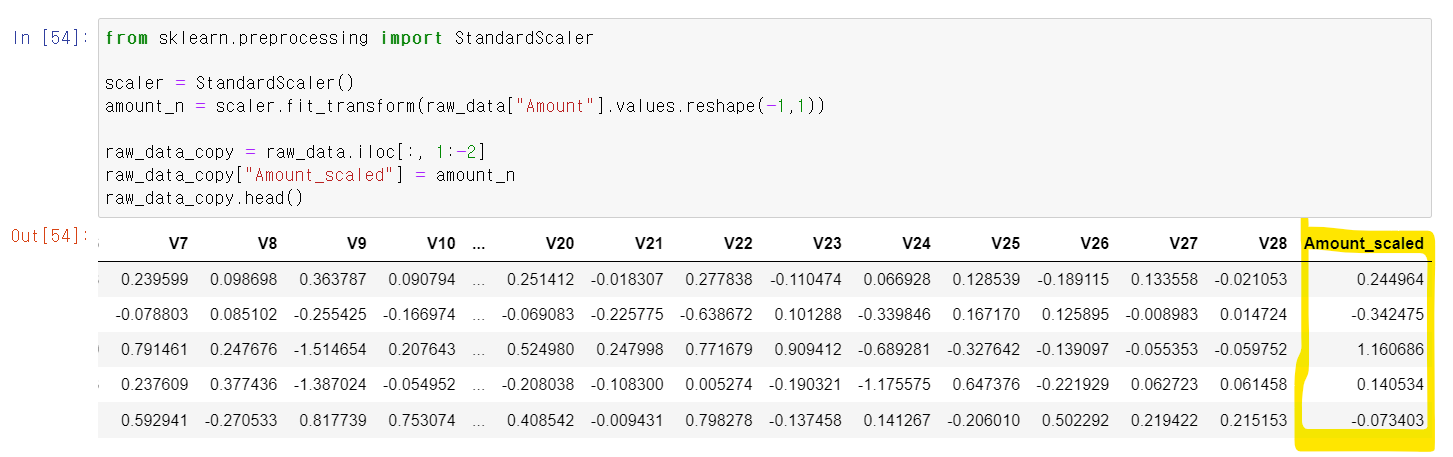
- Amount컬럼의 값을 StandardScaler로 바꾸고 해당 값을 DataFrame에 추가했다.
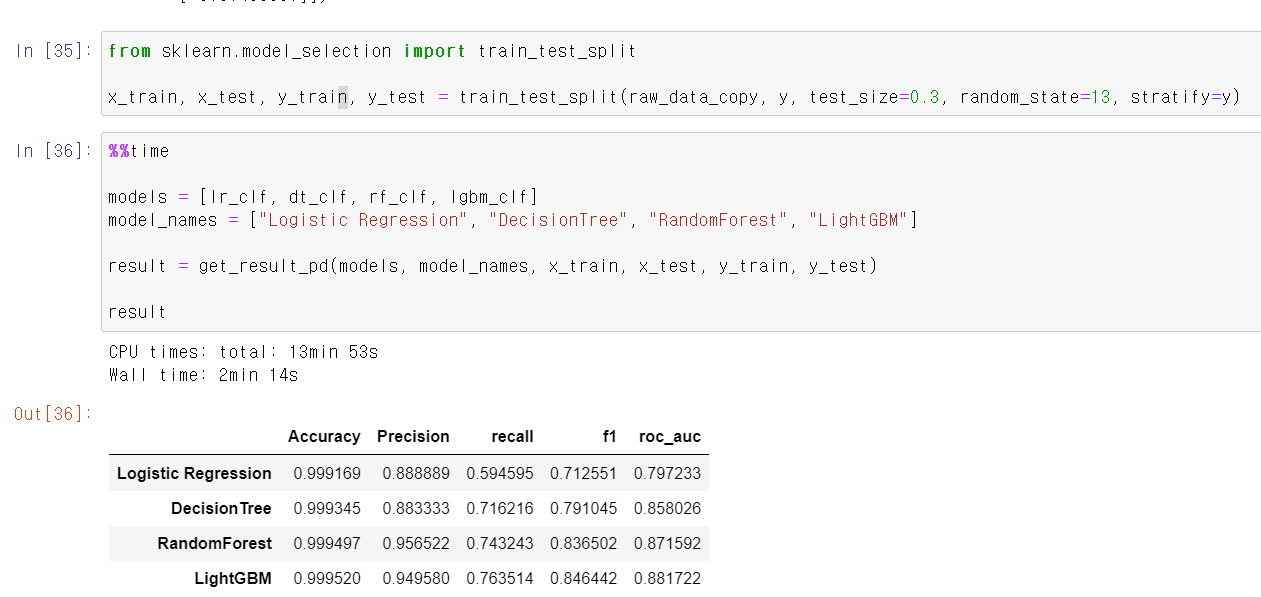
- 위와 같은 방법으로 각 모델링 방법으로 교육을 시켰다.
- 조금 미세하기 전체적으로 올라갔지만 크게 차이는 없는 것 같다.
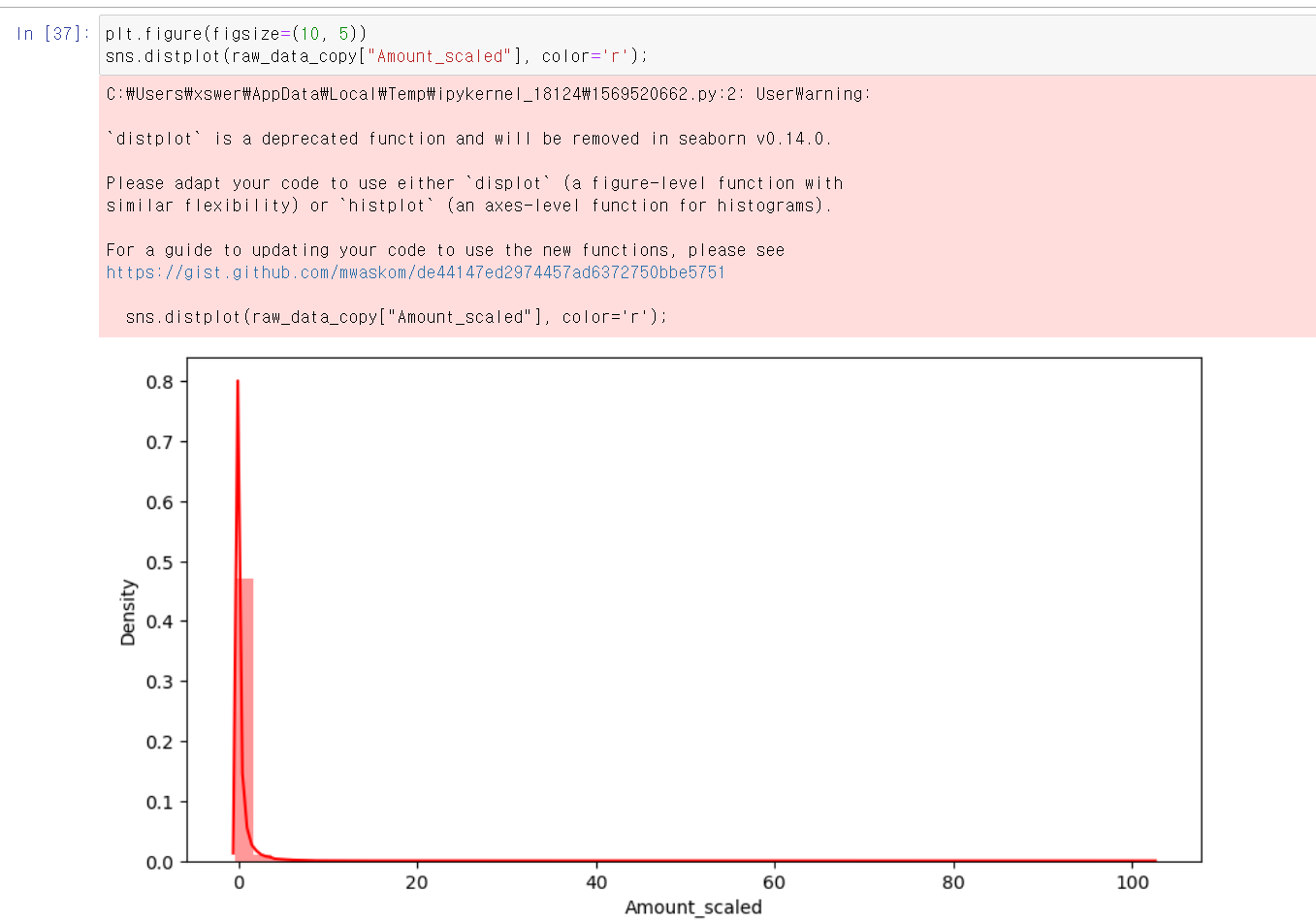
- 시각화를 통해 보니 분포의 차이가 크게 달라진 게 없는 것 같다.

- 이제 ROC 커브를 그리는 함수를 만들어 결과를 확인해보자
- fpr(False Positive), tpr(True Positive) 값을 받고 각 값을 x, y축으로 선을 그린 다음, [0,1]직선 선을 그어서 보자
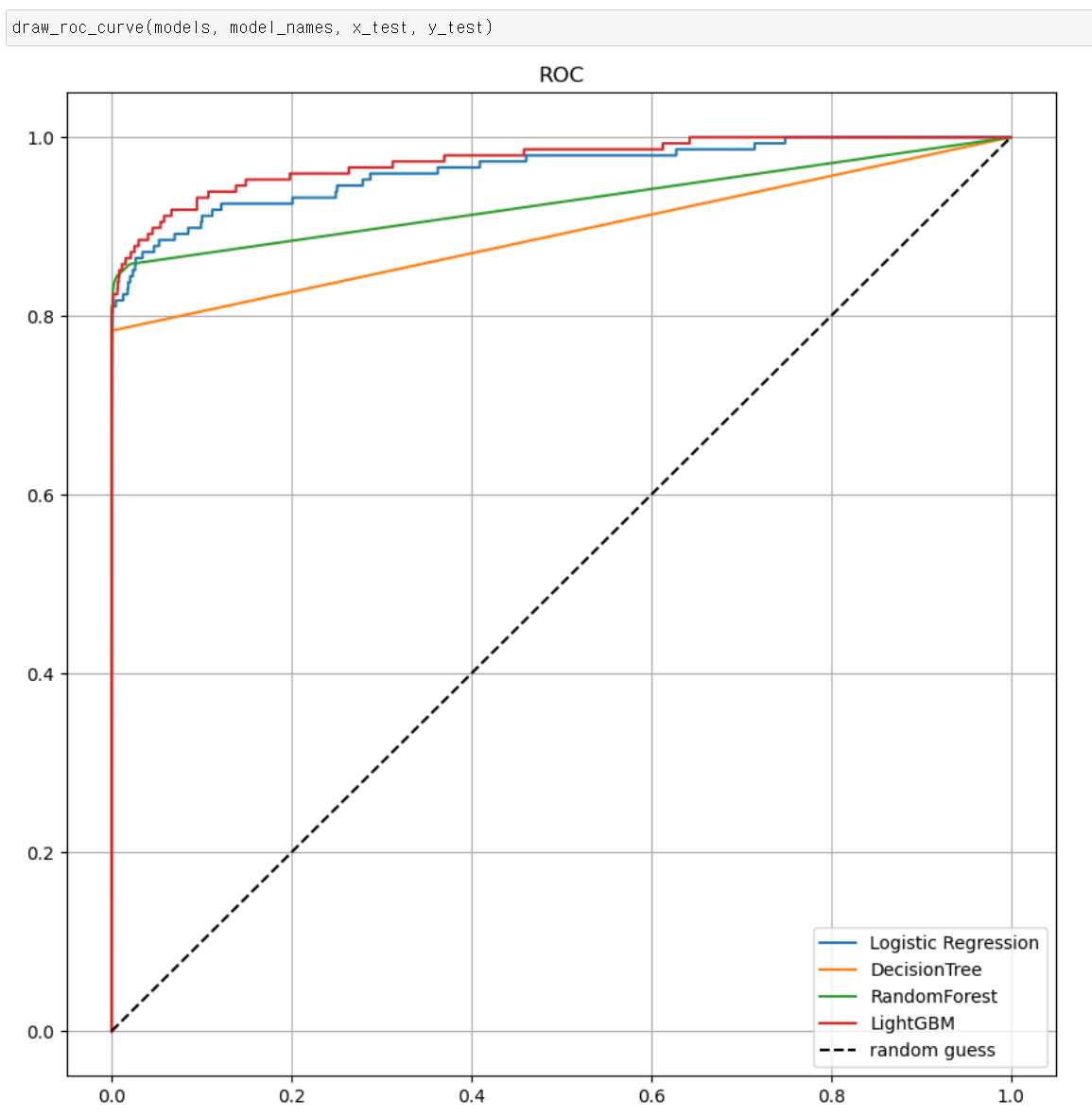
- roc커브 시각화를 통해 보니 ligthGBM기법이 제일 좋아 보이고, DecisionTree가 제일 낮은 결과를 보인다.
- 이번에는 더욱 정규분포에 가까운 값으로 바꾸기 위개 log값을 통해 값의 Scaler을 바꿨다.
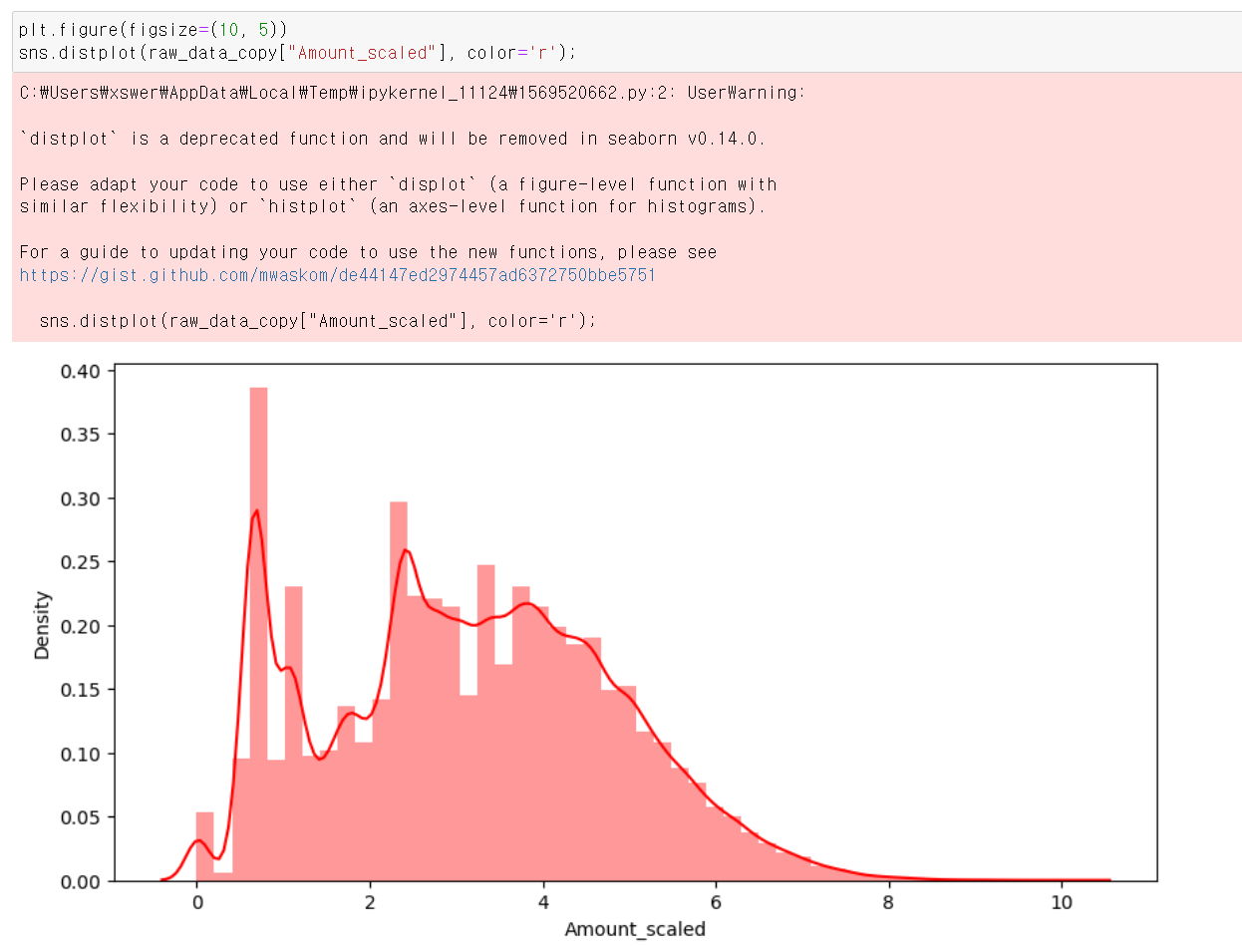
- 그래도 3개의 Scaler중에 제일 고른 분포를 보여준다.
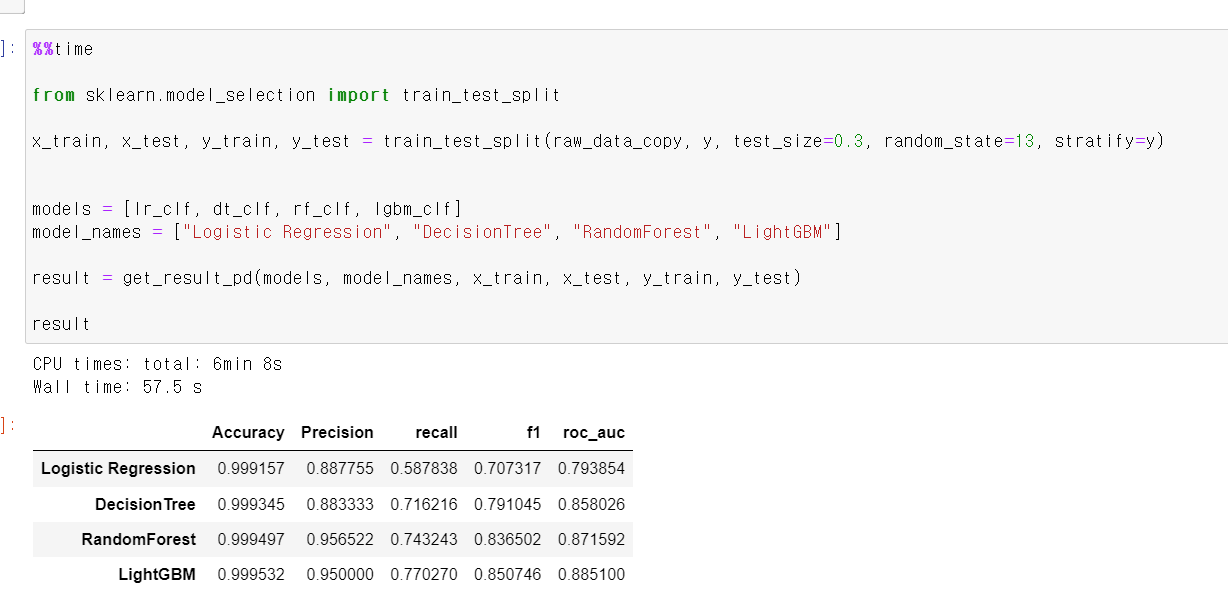
- 이제 해당 Scaler값으로 분석 결과 이번에도 미세하게 전체적으로 Recall의 값이 올라갔다.
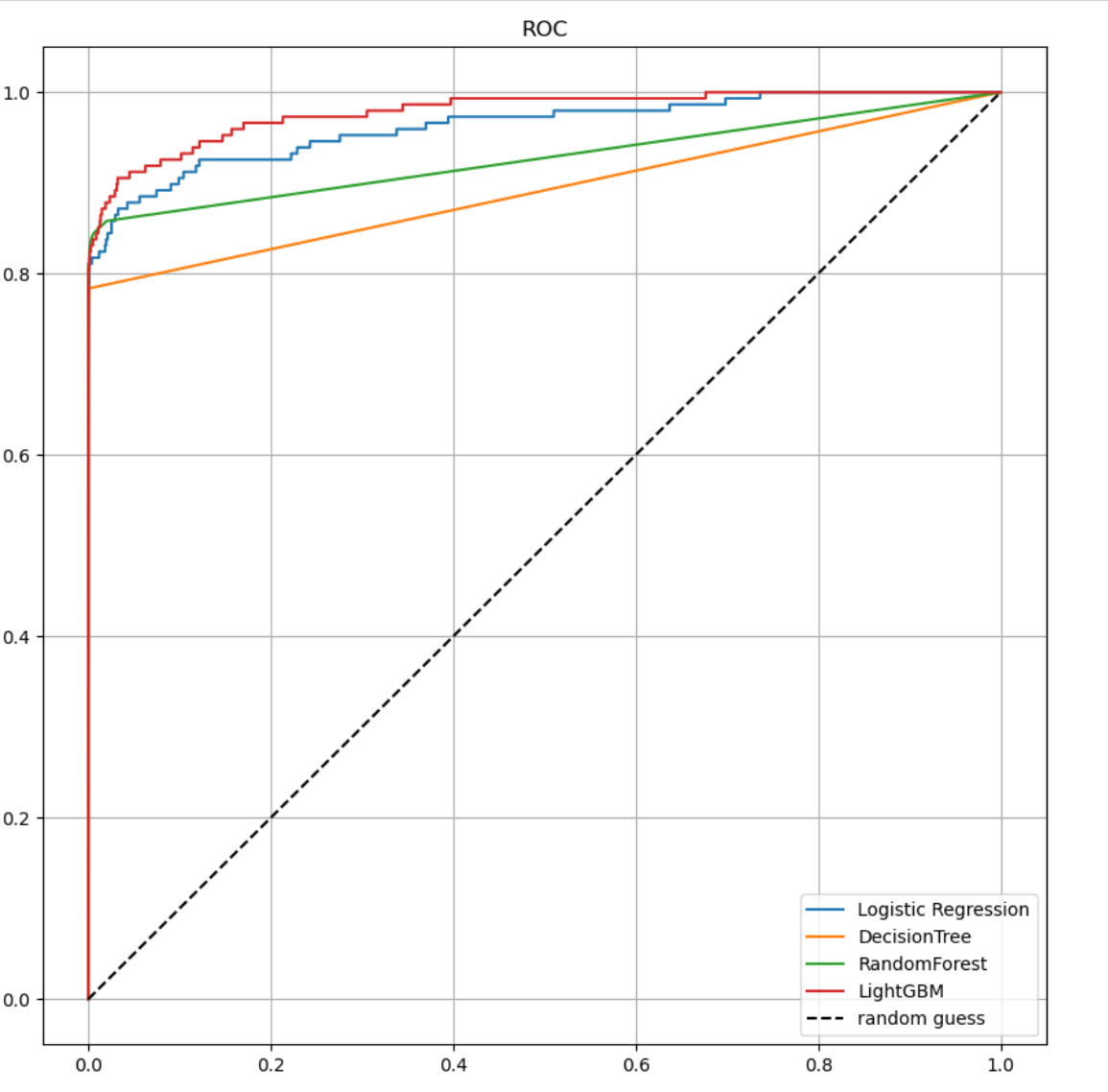
- roc커브를 시각화를 해서 보니...음...큰 차이가 없는 것 같다.
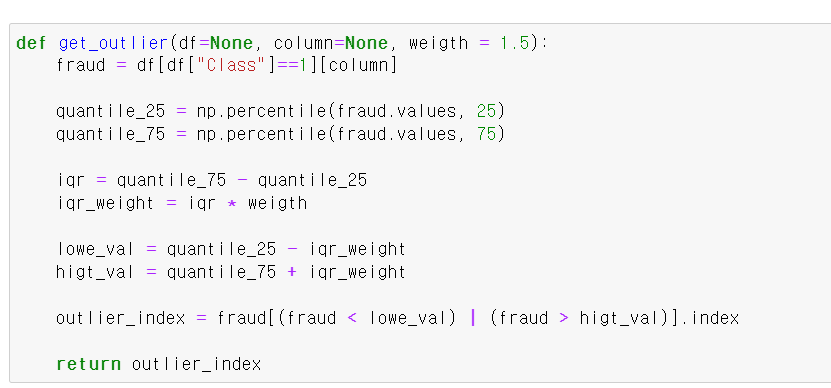
- 이번에는 아웃라이너 값을 제거하고 분석을 해보자
- 아웃라이너는 4분위수를 알아야 이해할 수 있는데, Q3-Q1 값을 iqr이라고 하며, 해당 값의 1.5배를 해서 Q3 + (iqr1.5) 그리고 Q1-(iqr1.5) 두 값을 기준으로 밖에 있으면 아웃라이너 값이다.
- 정확히 해당 함수는 아웃라이너가 있는 인덱스 값을 찾는 함수다.
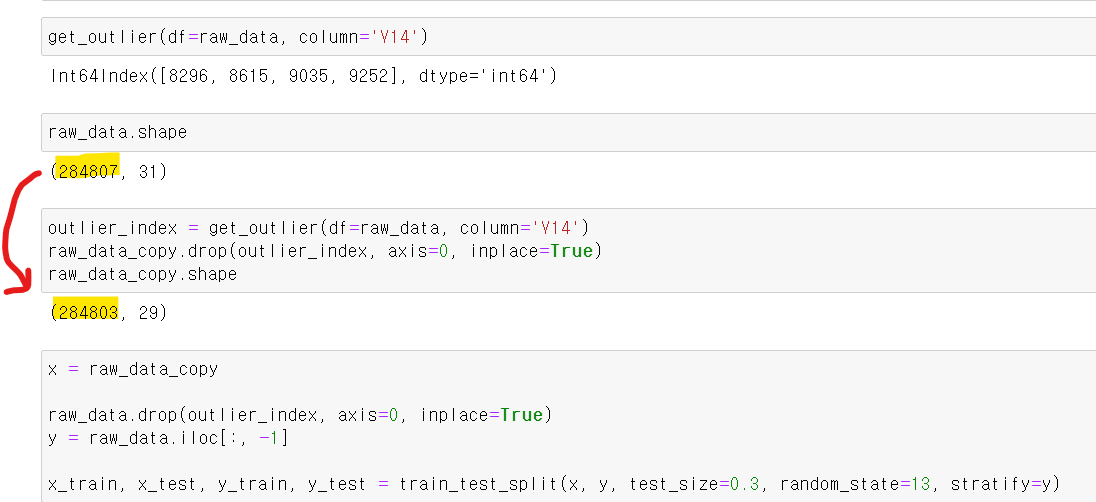
- V14컬럼의 아웃라이너 값을 찾고, 제외한 결과 3개의 인덱스 값이 삭제됐다.
- 이제 해당 데이터셋을 통해 분석을 해보니
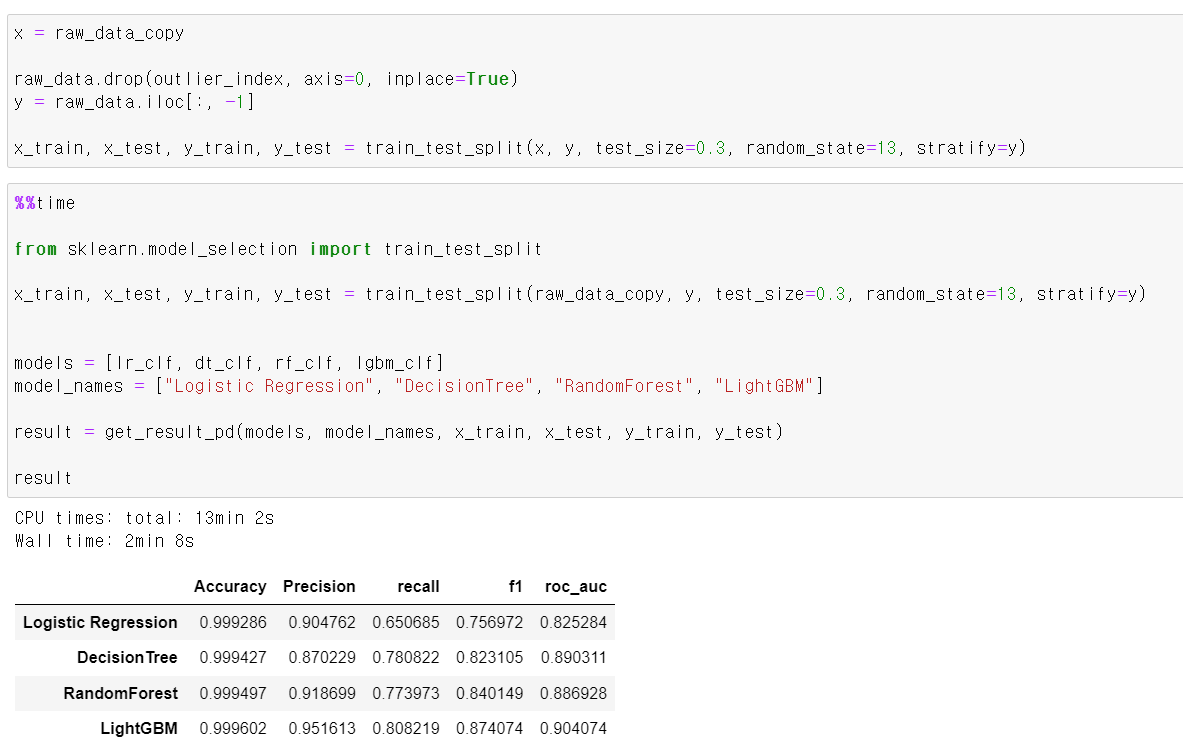
- 이번에는 Recall의 값이 눈에 뛰게 좋아졌다.
- 해당 모델링의 목적은 결국 불법 신용카드 사용자를 구분하는 머신러닝을 만드는 것이기에 Recall값이 중요하다 -> 전체 불법 사용자 중 진짜로 예측이 맞는 값
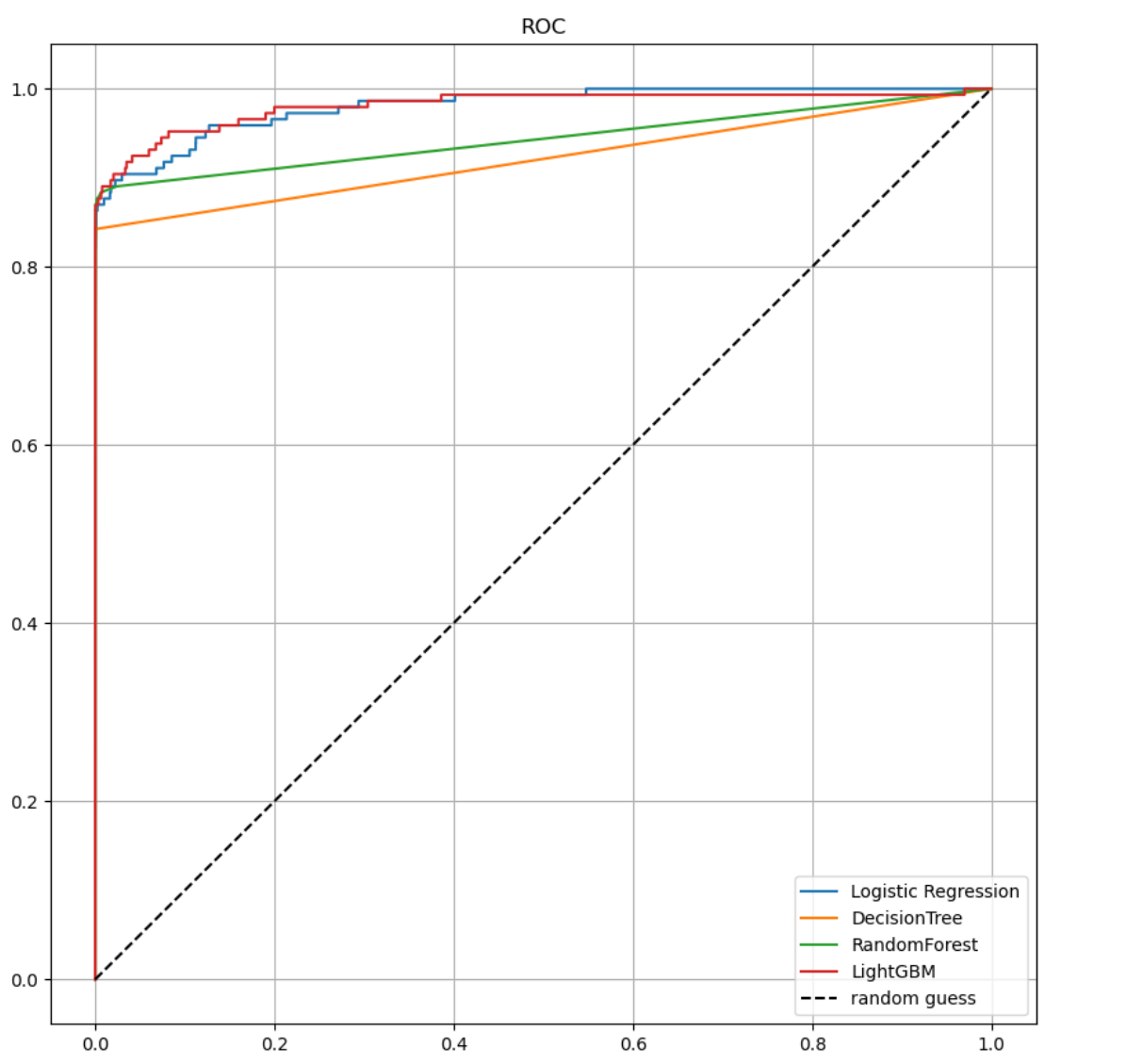
- ROC커브 시각화도 전체적으로 왼쪽 위 상단에 더 가까워지는 게 보인다.
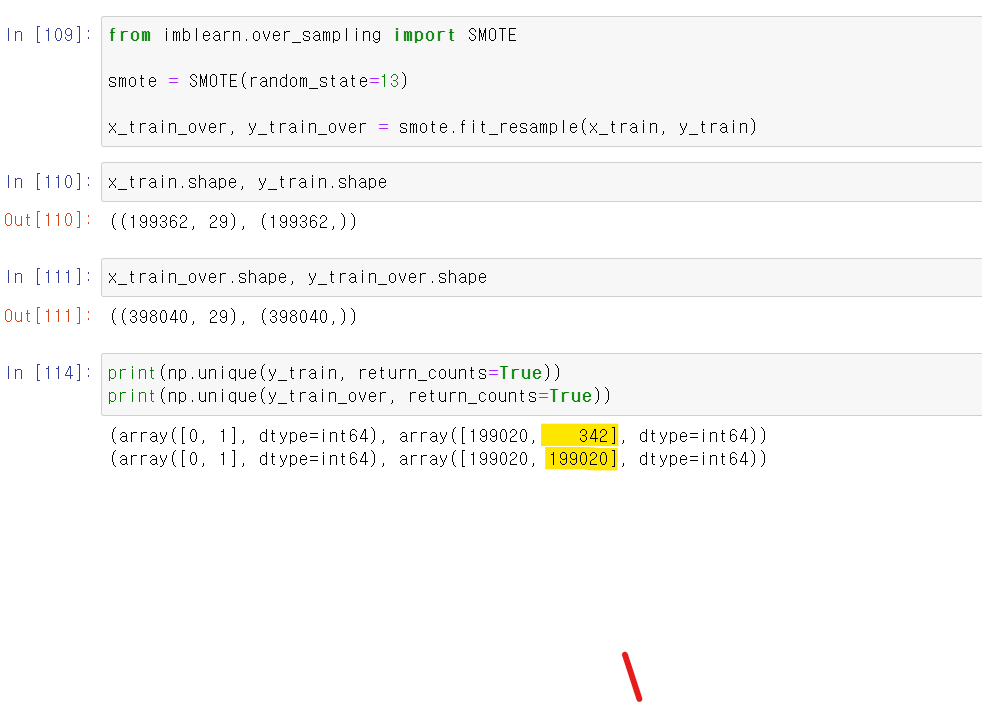
- 이제 마지막으로 데이터 양의 수준을 맞춰서 분석해보자
- 원래는 0이 압도적으로 많고 1이 적은데, SMOTE 모듈을 통해 두 값의 비중을 똑같이 만들었다.
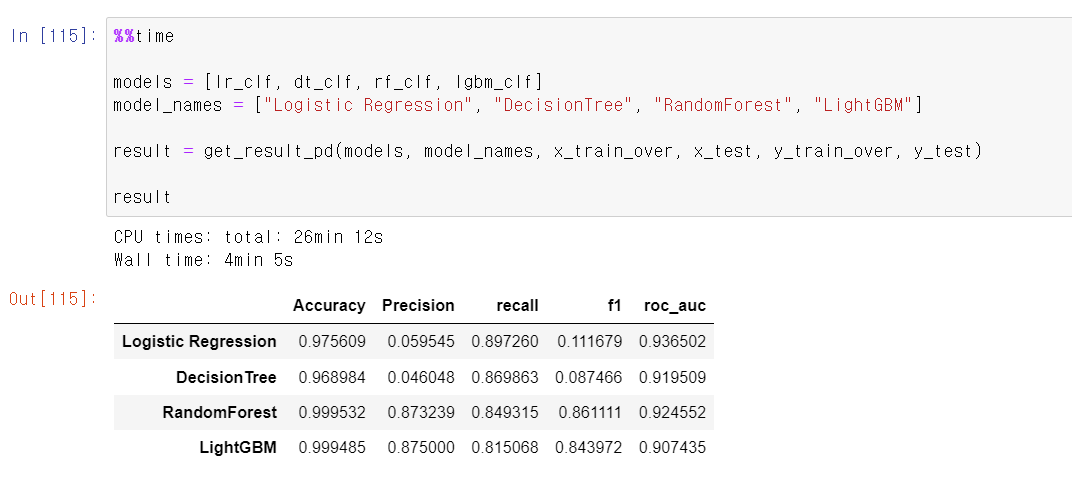
- 이번에는 큰 차이는 없지만, 그대로 미세하게 Recall의 값이 높아졌다.
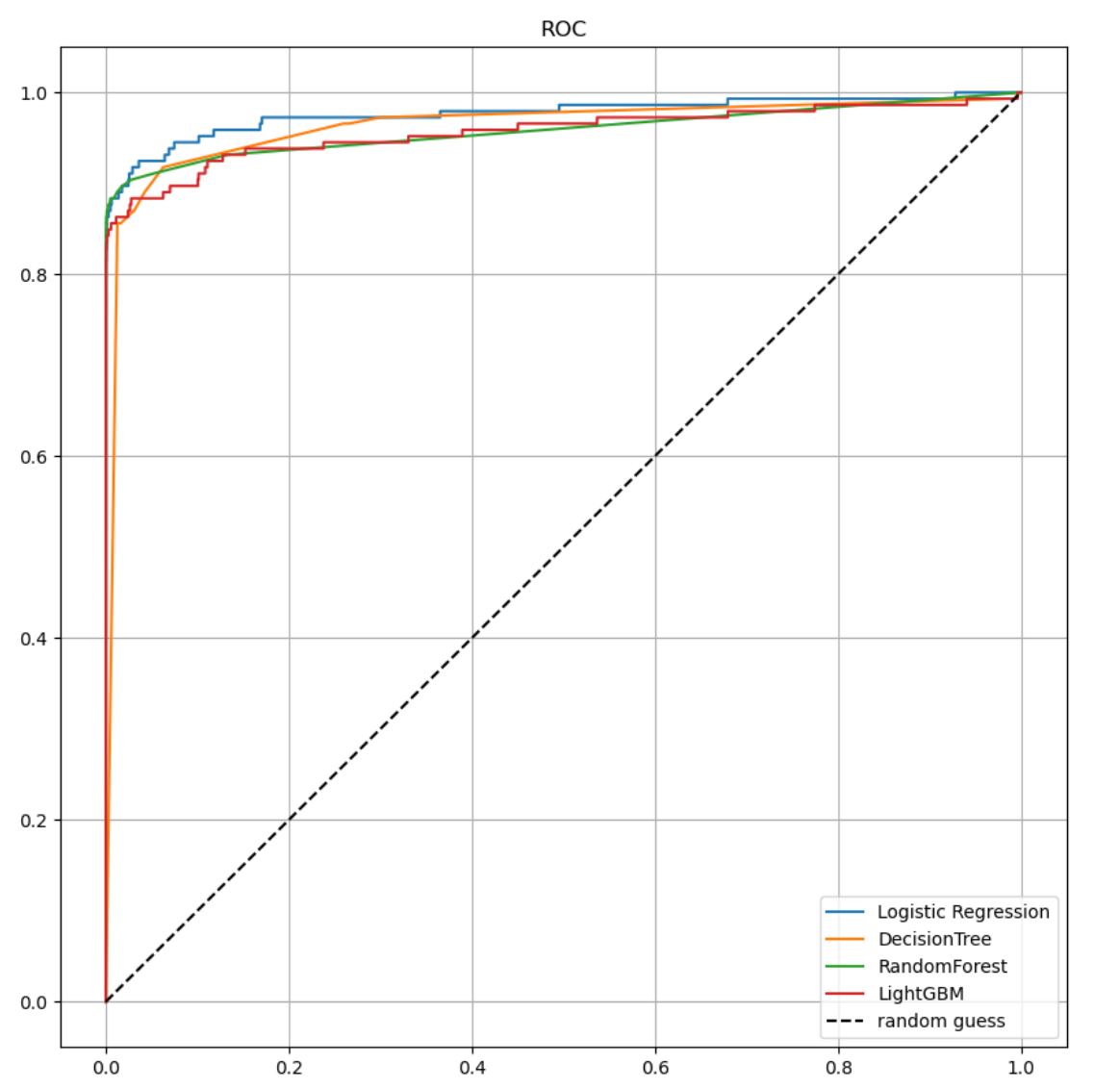
- 음...시각화를 통해 보니 눈에 뛰는 변화는 없는 것 같다.
- 그래도 마지막 단계에서 가장 높은 Recall성능을 보여주며 약 81% Recall성능을 보여준다.

상황을 바꿀 수 없다면, 나를 바꾸자