xswer19.log
로그인
xswer19.log
로그인
nltk
안선경
·
2023년 3월 22일
팔로우
0
ML_study
목록 보기
18/25
이제 정형화된 데이터가 아니라 자연어를 통해 머신러닝을 작동해보자
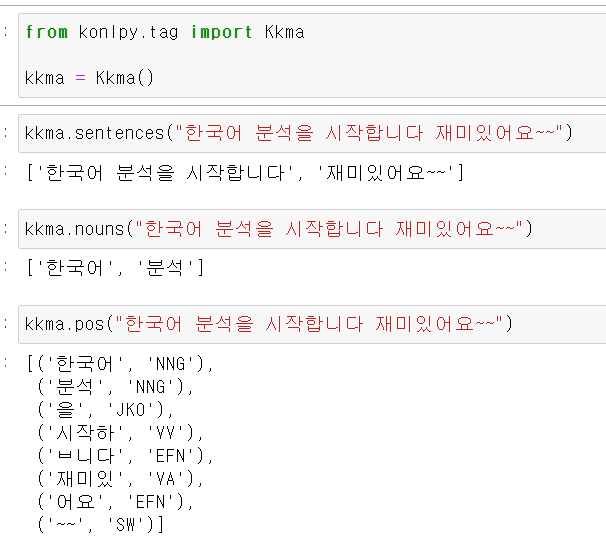
먼저 우리나라에서 만든 모듈인 konlpy의 kkma(꼬꼬마)를 사용해서 각 단위에 따라 단어를 구분할 수 있다.
다음은 한나눔 모듈로도 단어, 형태소를 구분할 수 있다.
제일 많이 사용하는 모듈로는 Okt가 있다.
안선경
상황을 바꿀 수 없다면, 나를 바꾸자
팔로우
이전 포스트
Credit_Card_Fraud_Detection
다음 포스트
WordCloud
0개의 댓글
댓글 작성