
- Dacon에서 주최한 범죄 유형 AI 분류 대회를 참가했다.
- ID값을 제외한 19개의 컬럼으로 3개 범죄 유형을 예측하는 것이 대회의 목표였다.
- 사용한 모듈들이다.
- 기본적인 데이터 처리 모듈, 머신러닝 알고리즘 모듈, 데이터 군집 및 차원축소 등에 대한 모듈로 3개의 분류로 사용했다.
- 대회의 데이터를 git_hub에 올려서 데이터를 불러왔다.
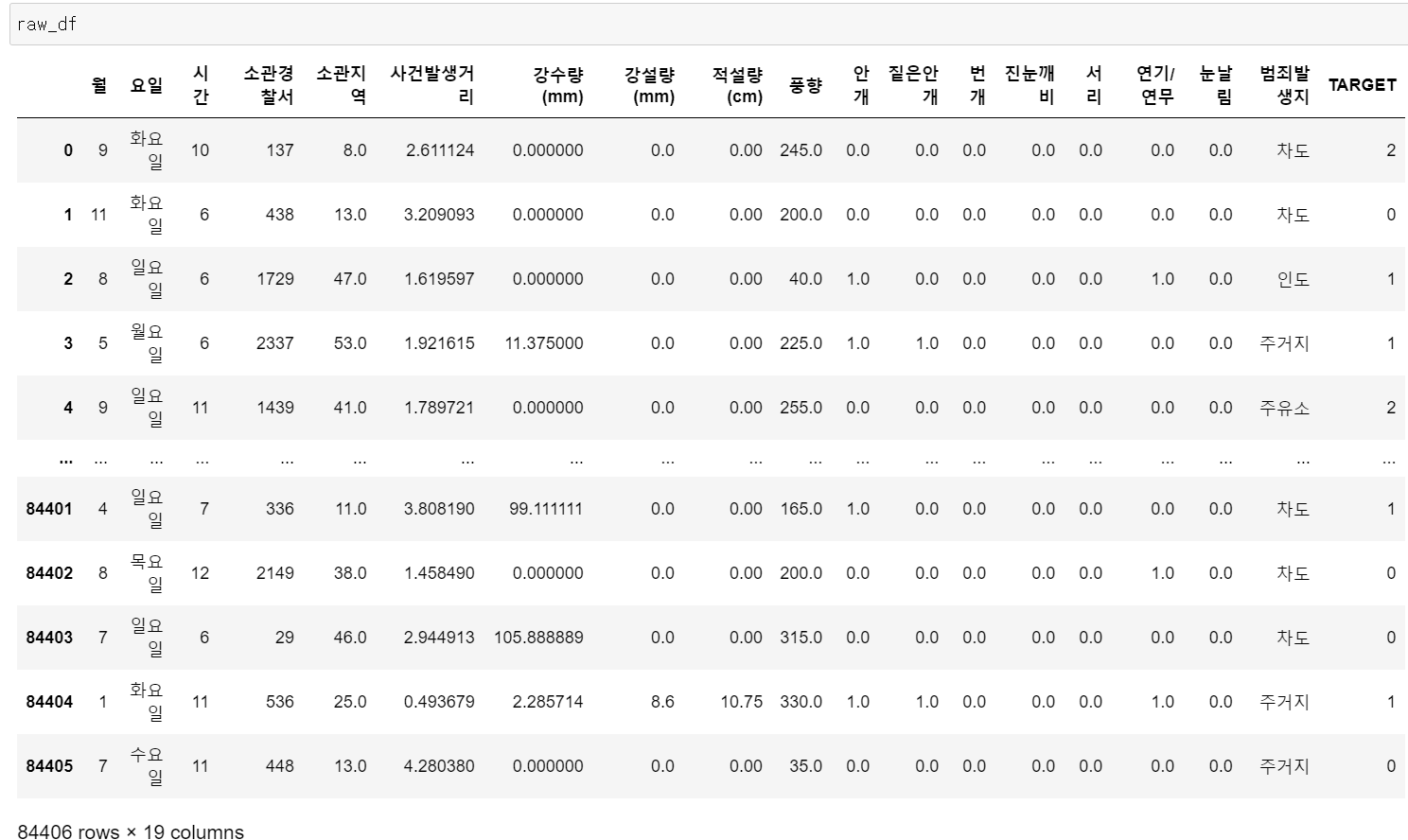
- 데이터의 shape은 84406개의 행과 19개의 컬럼을 구분됐다.
- 기본적인 시간 정보와 치안 관련 정보 그리고 기후 정보 등 3개의 카테고리 정보가 있었다.

- 데이터의 정보를 보니 float형태와 object로 구성되어 있고, Label은 강도, 절도, 상해 등 3개가 있었다.
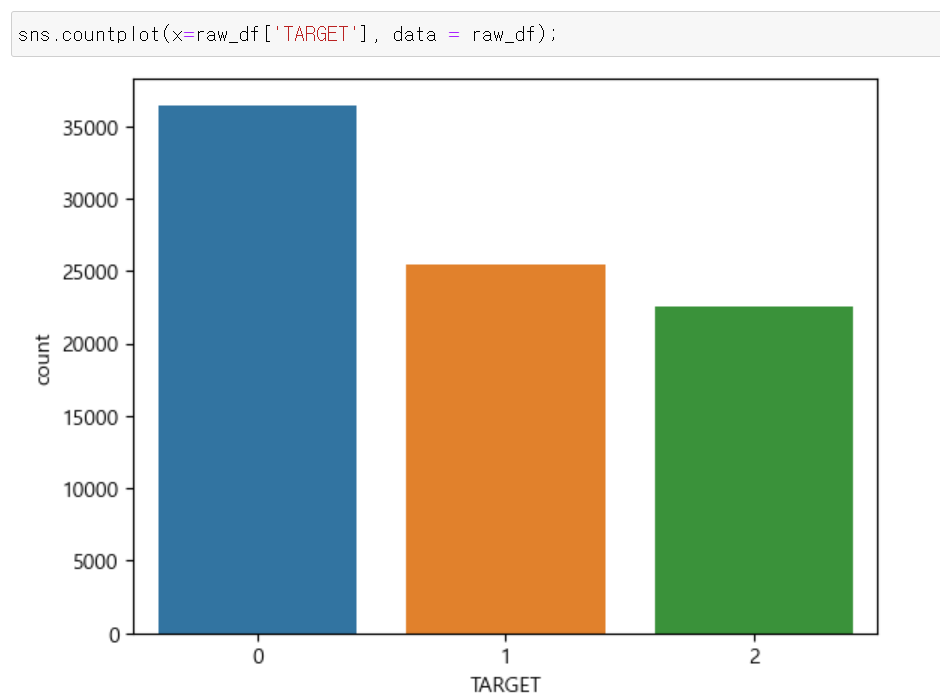
- Label값의 분포를 확인해보니 0이 가장 많으면 2가 가장 적었다.
- 하지만 2의 값이 극단적으로 작지 않기 때문에 일단 해당 데이터를 바탕으로 분석 및 AI 분류 작업을 진행했다.
- 먼저 데이터의 타입에 따라 카테고리 형태와 연속형 자료를 구분하고 두 개의 리스트에 담았다.
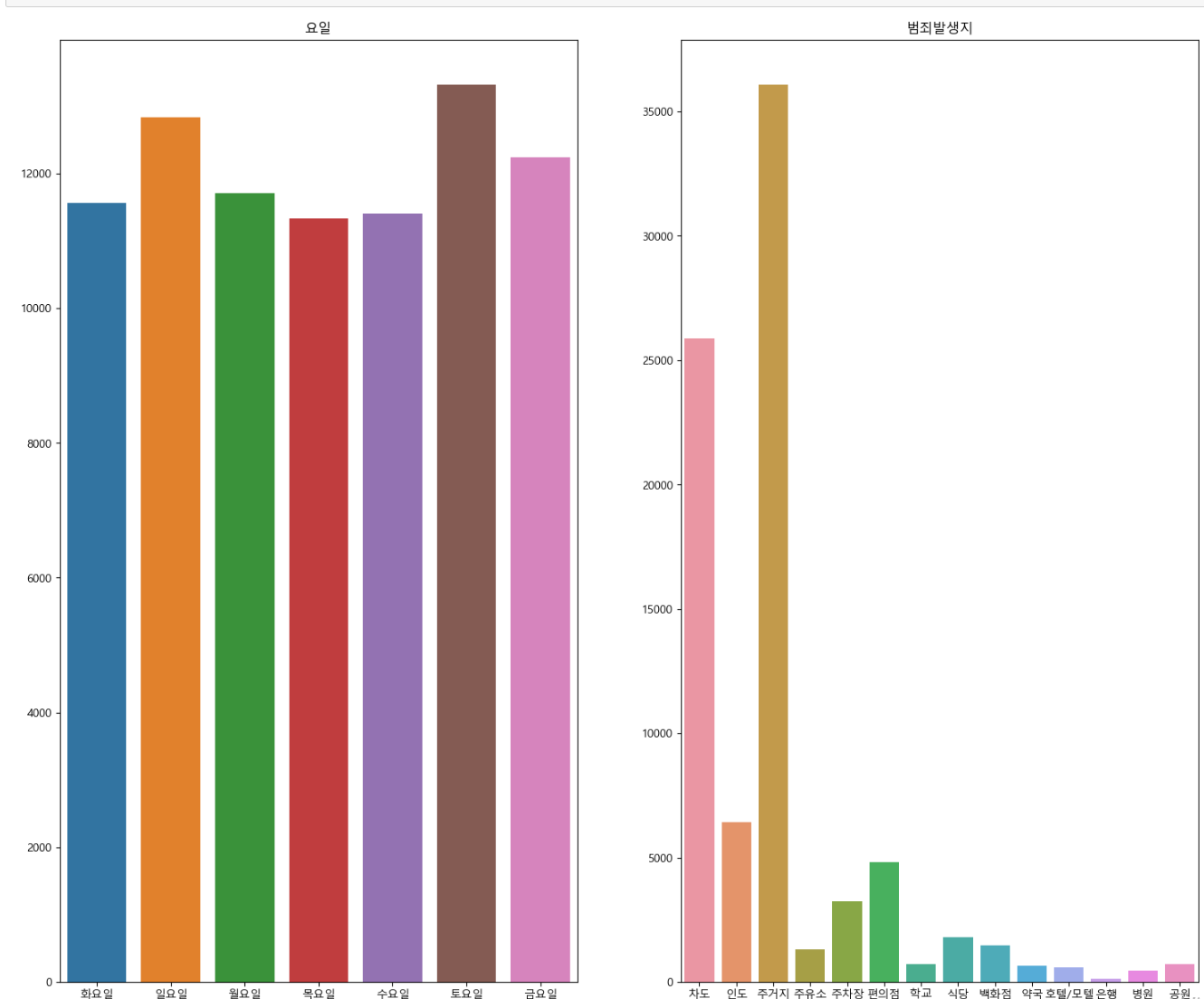
- 요일의 경우 토요일에 사건이 대체로 발생했으며, 발생지는 주거지 및 차도에서 자주 일어났다.
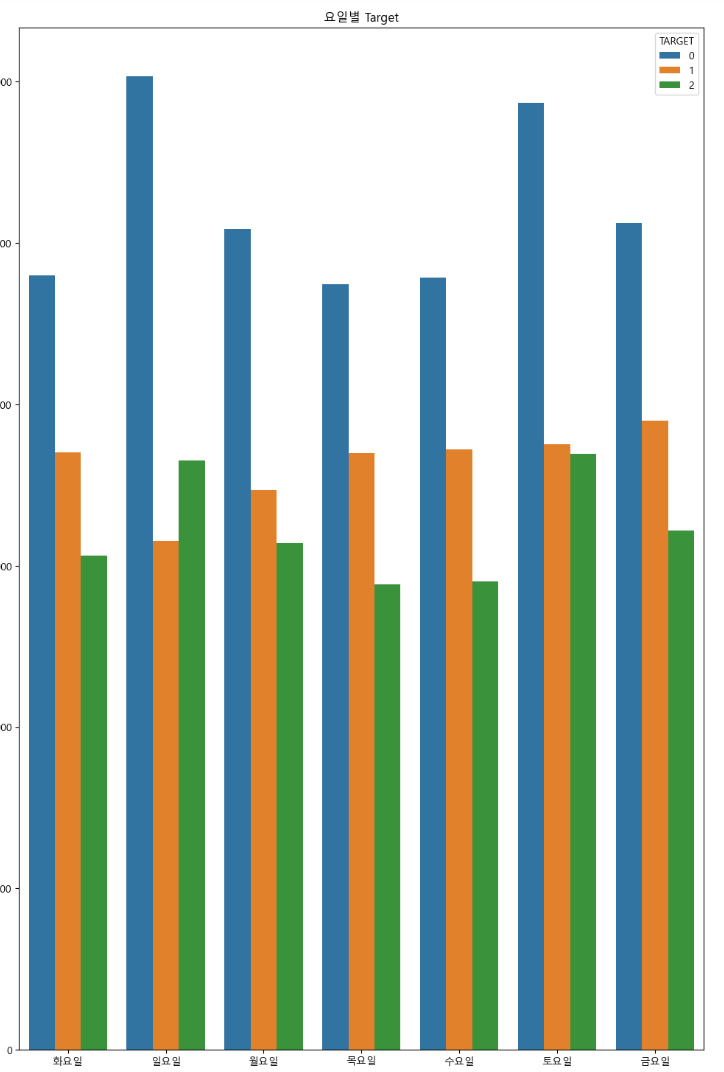
- 요일별 범죄 분류를 확인해보니 일요일을 제외하고 비슷한 양상을 보여줬다.
- 일요일의 경우 예외적으로 절도가 상해보다 많이 발생했다.
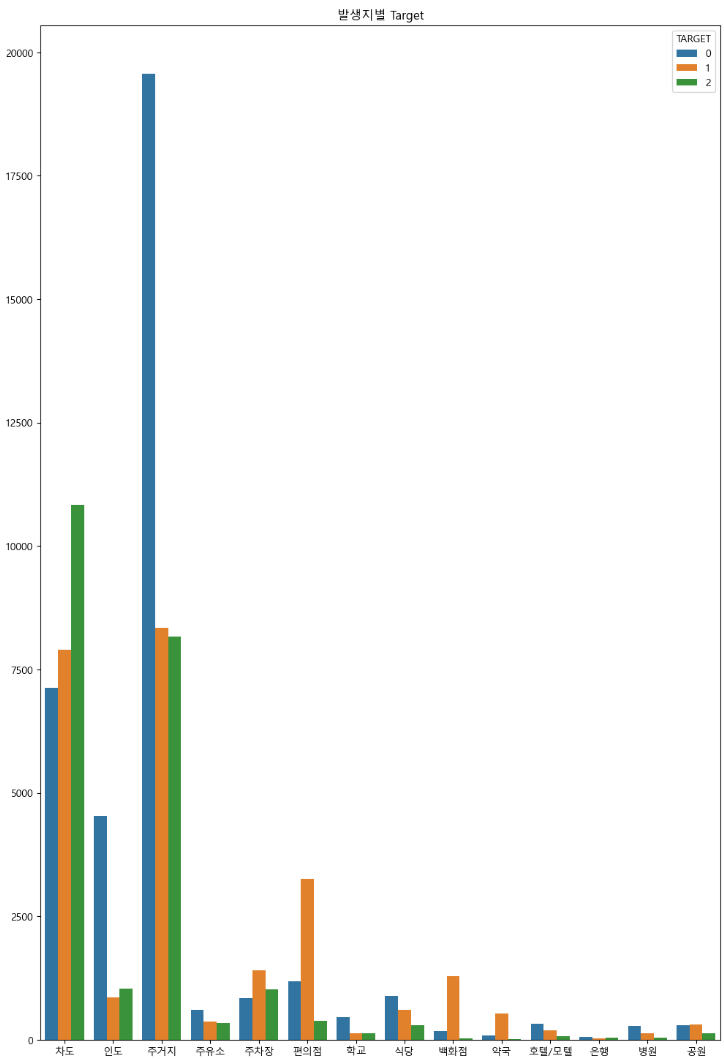
- 범죄발생지별 범죄 유형의 경우 차도에서는 상해가 많이 발생했으며, 주거지에서는 강도가 많이 발생했다.
- 차도에서는 음주운전으로 인한 상해 사건이 많지는 않을까?라는 가설을 세웠다.
- 그리고 주차장, 편의점, 백화점 등에서는 절도의 사건이 많이 발생했다.

- object형태의 요일과 범죄발생지 데이터의 타입을 바꾸고, Label값을 제외한 데이터를 x, 라벨데이터를 y에 저장하고 train, test데이터로 바꿨다.

- 그리고 cat_boost에 cat_feature에 넣기 위해 다른 데이터의 타입을 int로 바꿔줬다.
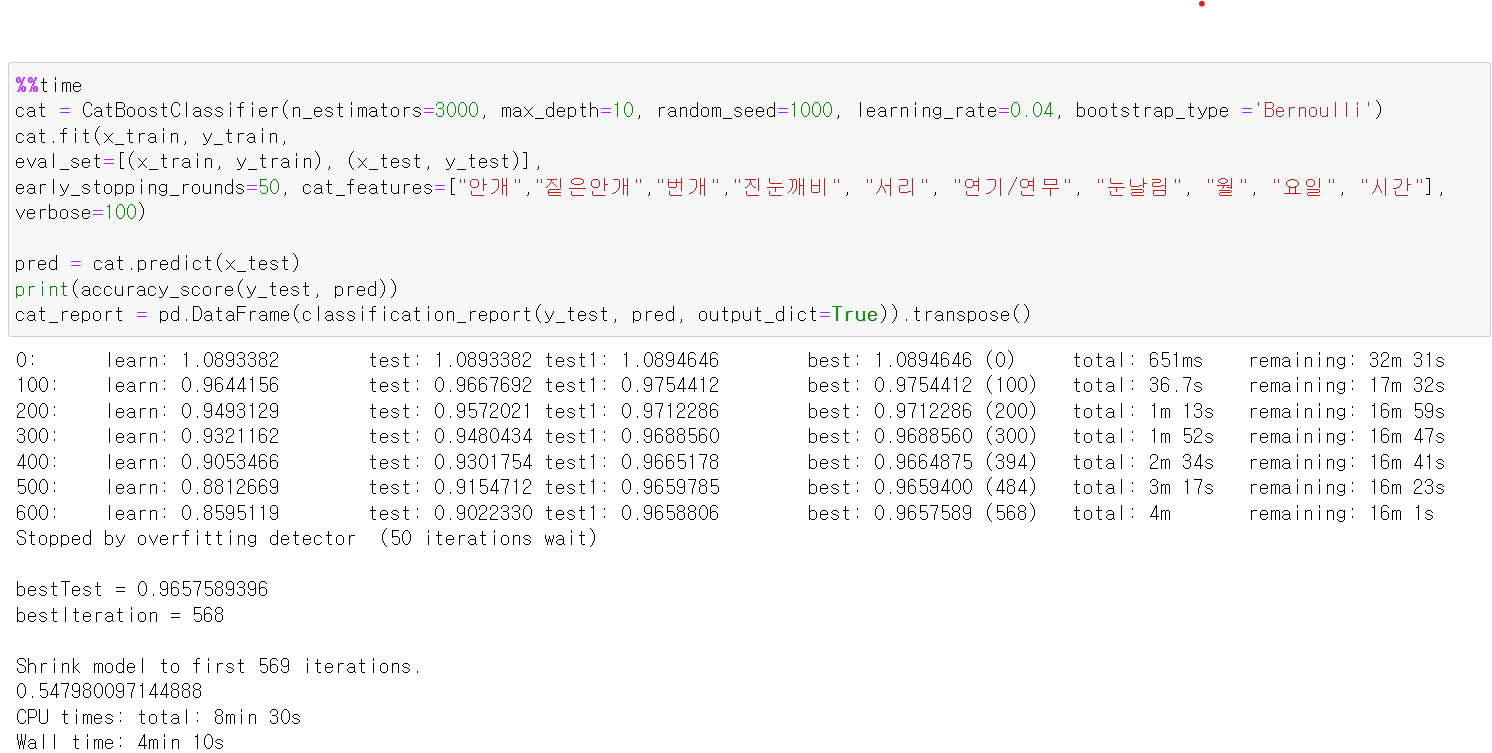
- 별다른 알고리즘 기법 없이 cat_boost에 넣고 돌려보니 54%의 정확도를 보인다.
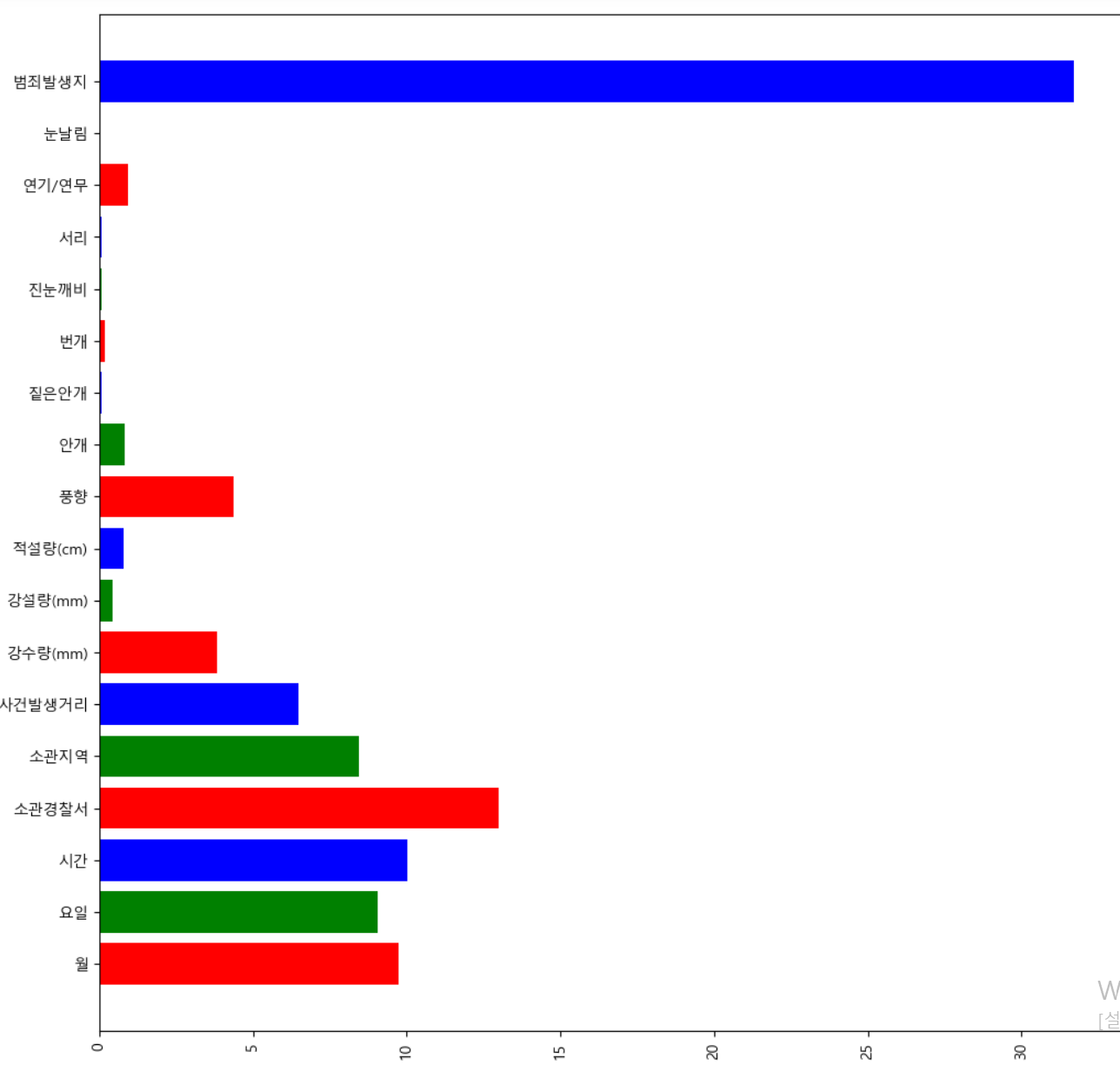
- 범죄발생지 외 몇몇 컬럼의 경우 높은 중요도를 보이나, 기후 데이터의 경우 큰 유의미한 차이를 만들지 못했다.
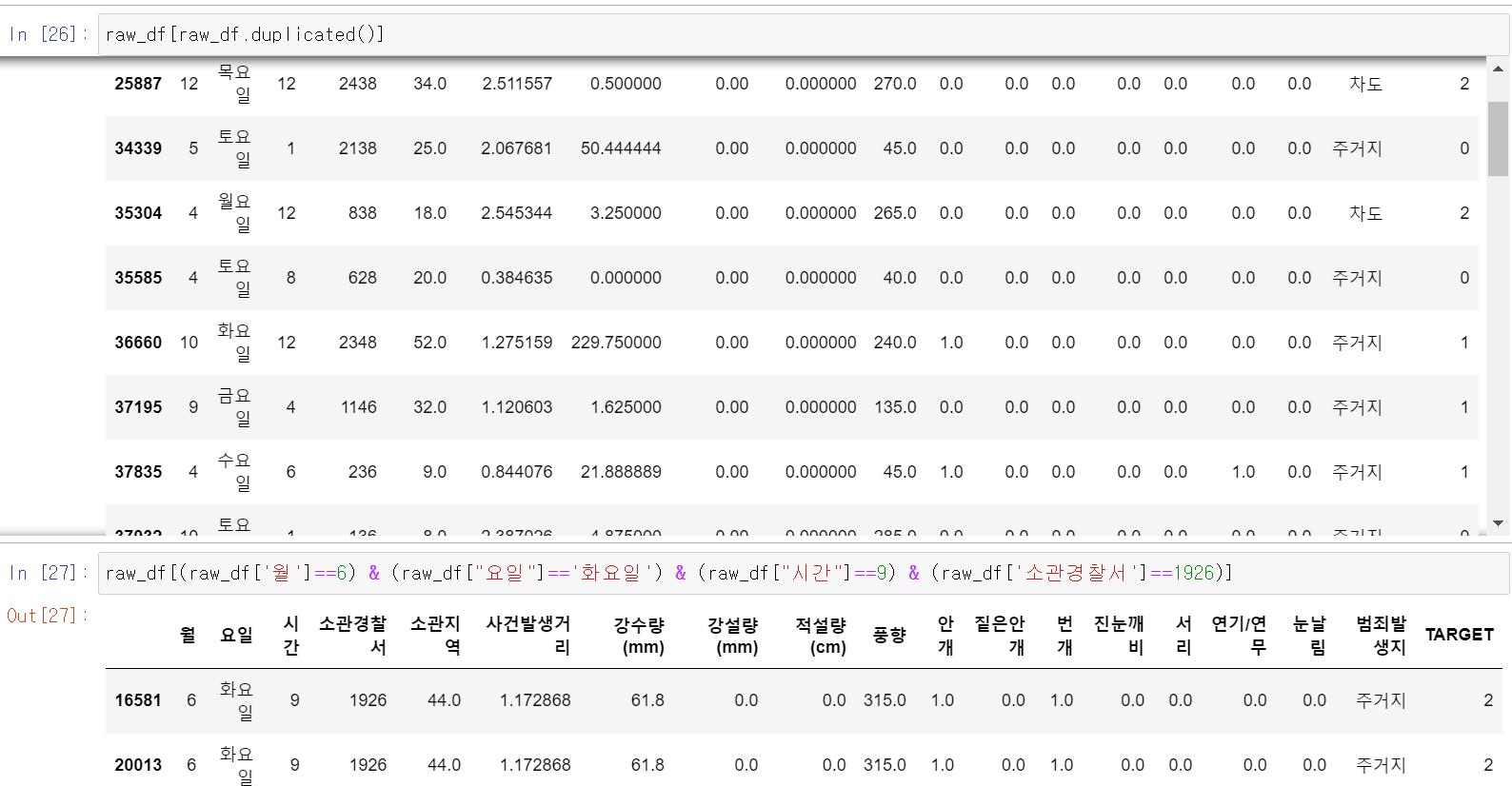
- 머신러닝 결과를 확인 후 데이터 분석 과정을 통해 데이터 상의 중복 데이터가 있는 확인했다.
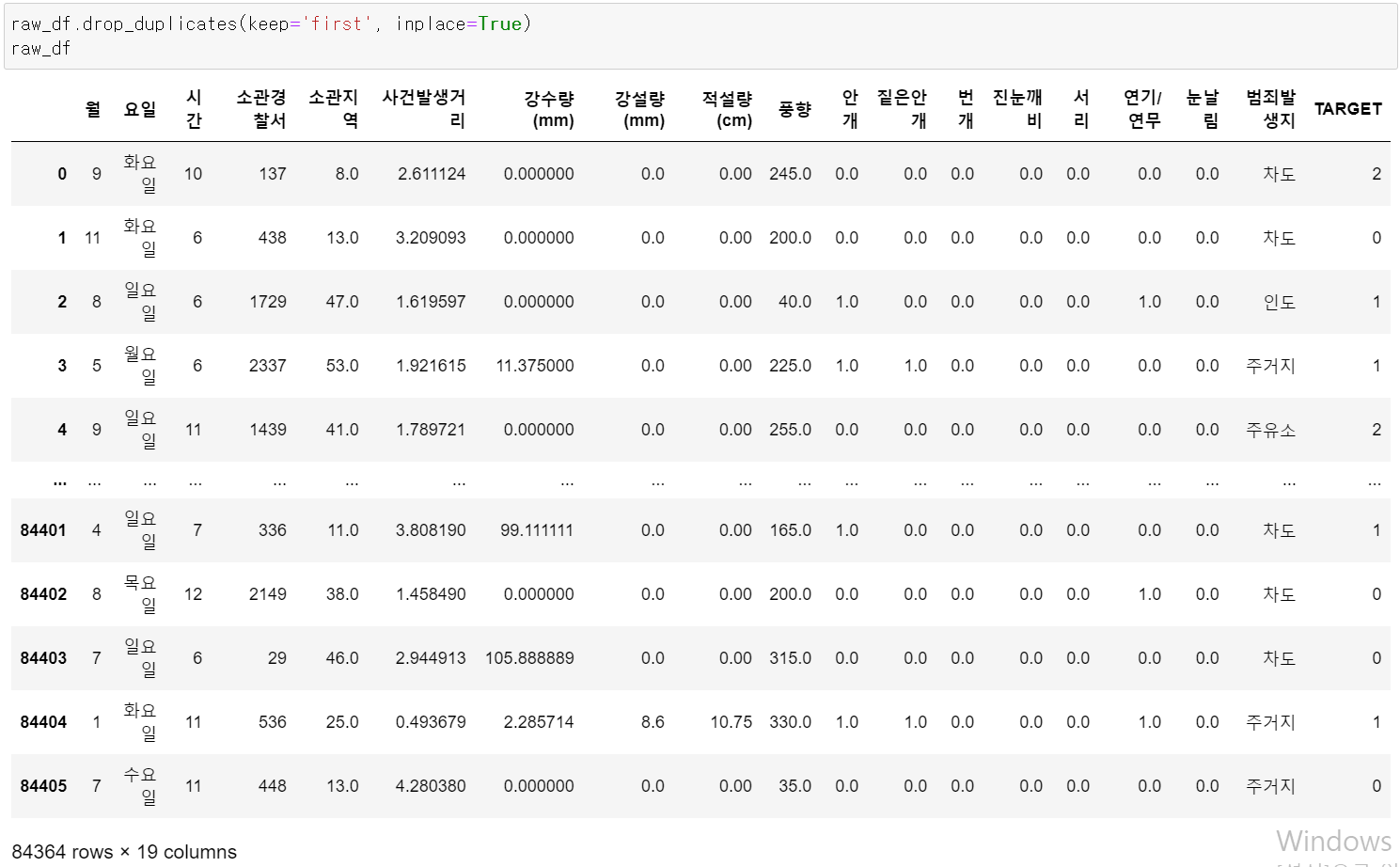
- 중복 데이터를 삭제 후 하나의 데이터만 남긴 후

- 기존의 중요도가 낮은 기후 데이터를 군집화 시키고, 치안 관련 정보인 소관경찰서, 소관지역을 군집화시켜 두 개의 컬럼을 추가했다.
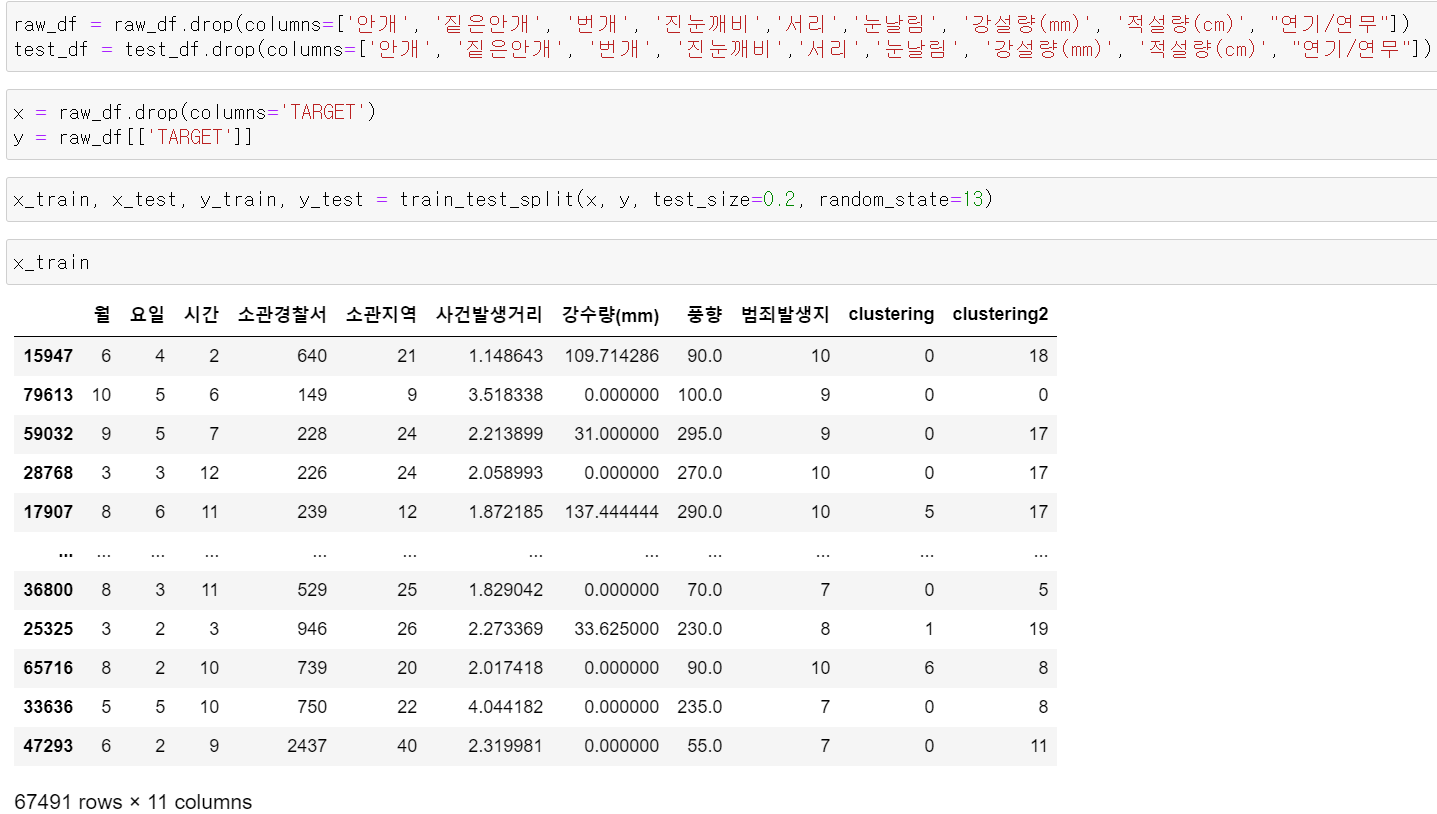
- 이후 군집화 시킨 기후 데이터는 빼고, train, test 데이터로 나눴다.
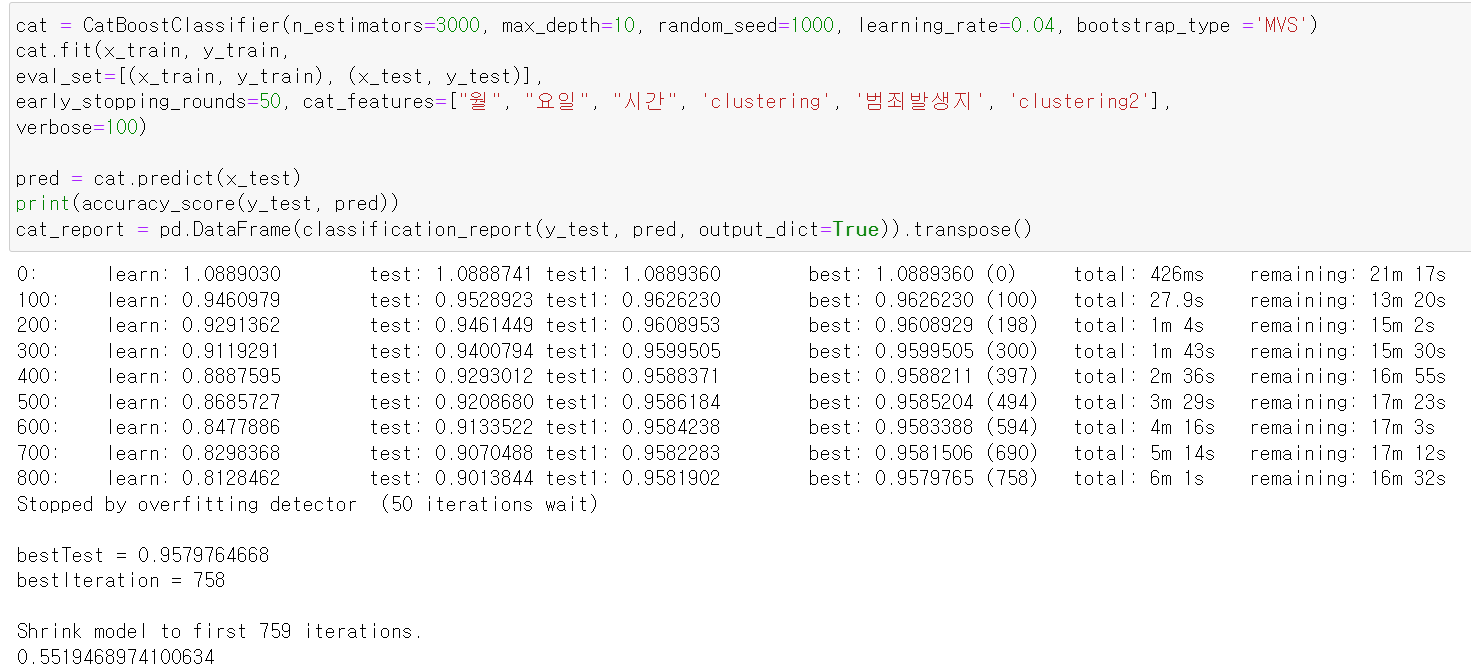
- 개선한 데이터를 바탕으로 머신러닝에 돌려보나 55%의 정확도를 보였다.

- 해당 모델을 통해 제출에 사용할 데이터를 예측하고 predict값을 파일을 csv로 만든 후

- 제출해보니 marco f1-score점수가 1등과 0.015차이가 났으며, 대회 기록상 0.51282가 나왔다.

상황을 바꿀 수 없다면, 나를 바꾸자