
프로젝트 시작
- 프로젝트 목표
- 이번에는 Zero_base의 Final프로젝트로서 손동작의 움직임을 감지하고 학습된 모델의 출력값을 통해 유튜브의 영상을 조작하는 프로젝트를 시작했다.
- 해당 모델을 통해 손을 사용할 수 없는 상황, 전자 기기가 멀리 있는 상황 등에서 손 체스처를 통해 영상을 조작하고자 프로젝트를 진행했다.
- 프로젝트 진행 방향
- 01 | 데이터 수집 : 다양한 환경에서 Noise를 가정하고 10가지의 손동작 영상 데이터를 수집
- 02 | 전처리 : OpenCV와 구글의 미디어파이프라인을 통해 영상의 프레임을 조정하고, 손동작의 각 관절 21개의 좌표값을 전처리
- 03 | 모델 학습 : CNN 2, RNN 2, Yolo 1 등 5개의 모델(팀원 당 1개의 모델) 모델에 고정한 프레임을 기준으로 3차원 array데이터를 학습 진행
- 04 | 모델 평가 : 학습한 모델의 정확도 및 성능 테스트
- 05 | 실제 사용 : 실제 셀레니움, 커맨드 입력 등 다양한 파이썬의 모듈을 사용해 User가 일상 생활에서 사용가능한 환경 구축 및 성능 테스트
Data수집 및 전처리
- 데이터 수집
- 5명의 팀원이 10가지 손동작 데이터를 다양한 상황을 가정하고 데이터를 수집
- 프레임 조정(openCV)
- 각 영상마다 프레임이 다르기 때문에 openCV를 사용해 30의 고정 프레임을 설정한 각 영상의 프레임을 조정

먼저 라이브러리를 불러오고, cap에 원본 파일을 불러온다. 그리고 원본 파일의 프레임을 가져오고 출력할 동영상의 파일을 변수에 저장한다. 이후 출력할 영상의 해상도와 파일 객체를 설정하고 out변수에 저정한다. 이후 해당 파일을 저장하면 된다.
이렇게 원본 파일의 프레임이 변환된 것을 볼 수 있다.
- 각 영상마다 프레임이 다르기 때문에 openCV를 사용해 30의 고정 프레임을 설정한 각 영상의 프레임을 조정
- 그리고 구글의 미디어파이프라인의 구현하는 코드의 성능을 확인했다.

- 이렇게 손을 인식하고, 화면의 좌측 상단을 0, 우측 하단을 1을 표준화해서 각 관절의 값 21개의 위치값을 출력한다.
- 현재 엄지와 중지의 손가락 위치를 실시간으로 OpenCV화면 상단에 출력하면서 미디어파이프라인의 출력 프레임 단위를 확인했다.
- 이후 수집한 영상 데이터를 코드에 넣어 하나의 Label을 기준으로 21개의 관절값 좌표 array를 출력했다. 여기서 (프레임, 관절, 3차원)으로 데이터를 정리하는데 시간이 다소 필요했다.
import cv2
import mediapipe as mp
import numpy as np
video_path = "./data/7/WIN_20230619_17_08_21_Pro.mp4"
mp_hands = mp.solutions.hands.Hands(
max_num_hands=1,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
cap = cv2.VideoCapture(video_path)
frame_count = 0
frames_array = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = mp_hands.process(image)
if results.multi_hand_landmarks:
for land in results.multi_hand_landmarks:
one_hand = []
for num in range(21):
hand = np.array([land.landmark[num].x,land.landmark[num].y, land.landmark[num].z])
one_hand.append(hand)
frames_array.append(one_hand)
frame_count += 1
if frame_count == 60:
break
mp_hands.close()
cap.release()
# 결과 출력
print(len(frames_array))- 출력 결과
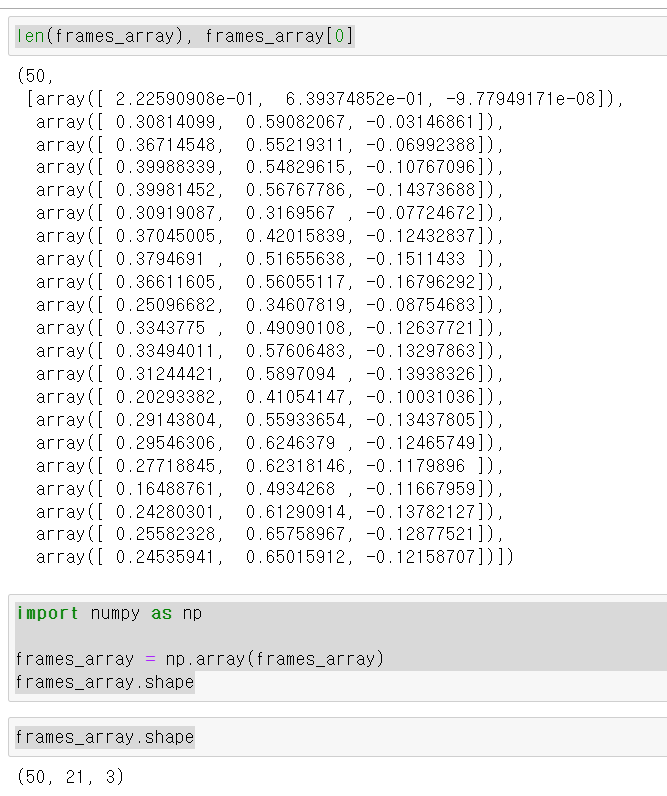
Problem1
- 정상적으로 50프레임, 21개 관절 위치, 3차원 데이터가 나왔으나, 문제는 84프레임의 영상을 구글의 미디어파이프라인에 넣으니 50개의 프레임이 나왔다. 문제의 원인은 하나의 영상에서 손이 없거나, 프레임 사이 손의 위치 변화가 적을 경우 미디어파이프라인에서 출력을 하지 않기 때문이다
Solution1
- 해당 문제를 해결하기 위해 영상의 중간값 즉 손의 중간 동작을 기준으로 만약 프레임 50이라면 20~40까지 중간 행동을 모델에 학습해 각 동작의 프레임을 맞추고 Model의 input_shape를 통일했다.
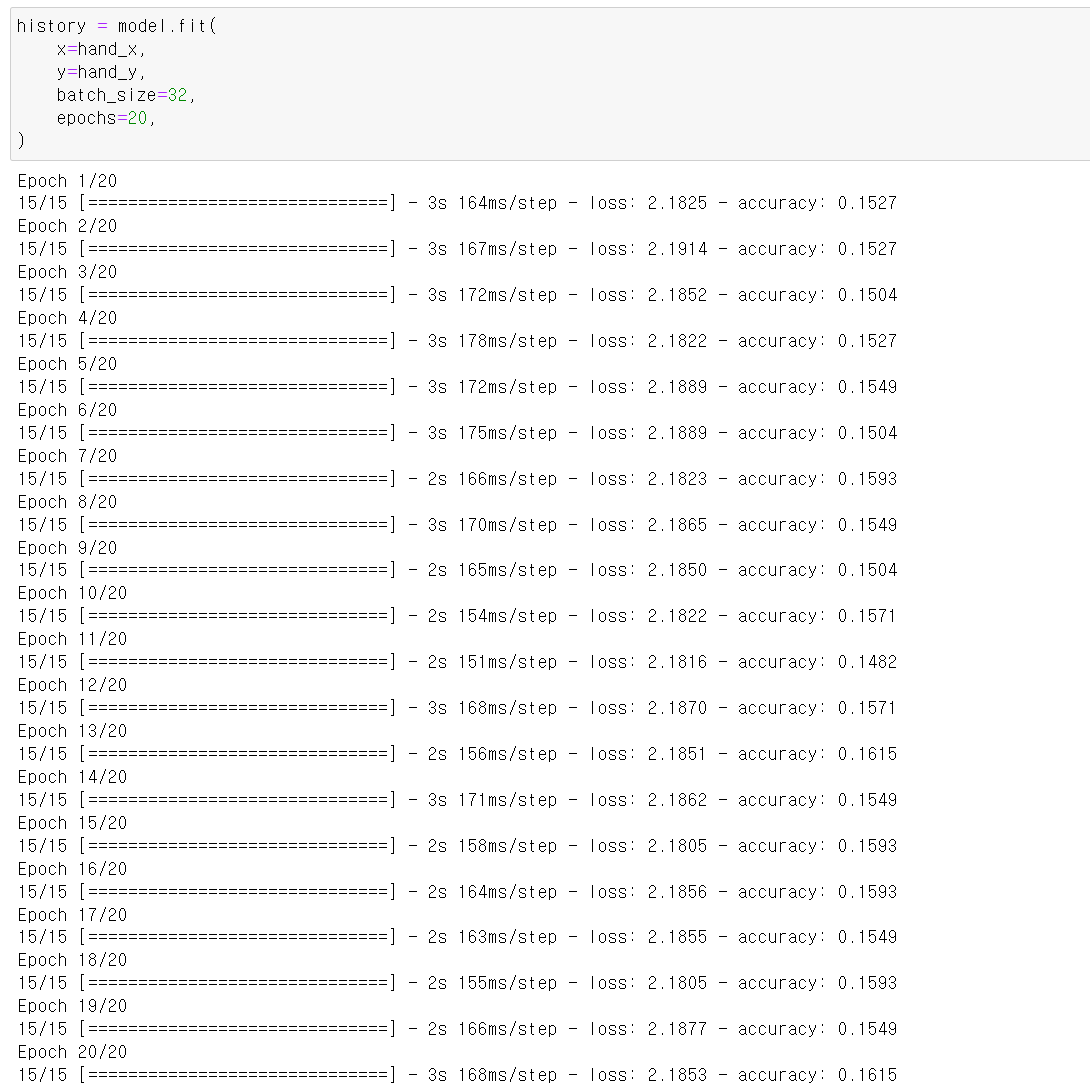
Model_Train
- 이제 모델을 구축하고, 학습할 모듈을 불러오고 각 팀원들이 수집한 영상의 좌표값 데이터를 모은 list_pickle파일을 불러왔다.
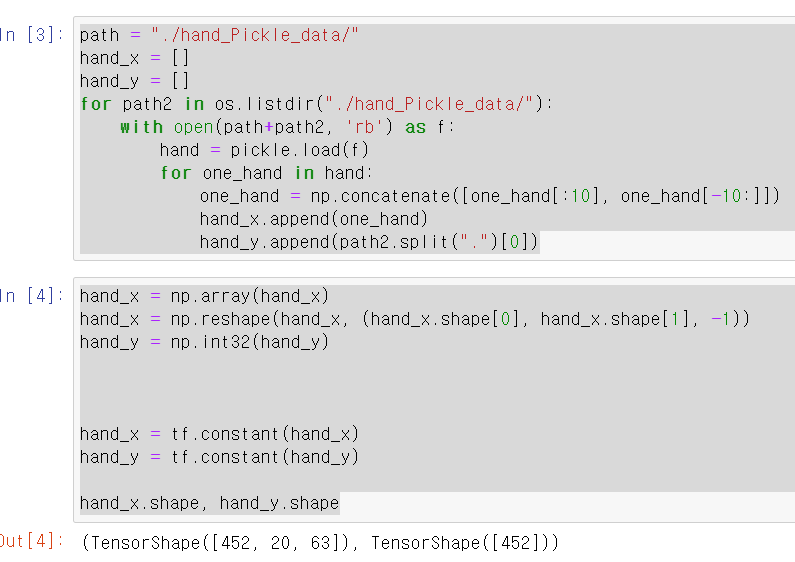
- 각 list데이터를 하나의 데이터씩 풀어서 총 452개 데이터를 (20, 21, 3)의 데이터를 출력 후 LSTM모델에 학습하기 위해 21과 3의 차원 데이터를 합쳐 452개의 (20[프레임], 63[좌표 * 21개 관절])tensor타입의 데이터를 변수에 저장했다.
- 그리고 각 손의 Label값을 저장했다. 여기서 정말 고생한 게 split으로 데이터를 뽑아서 string으로 뽑혔는데 모델 학습 과정에서 이를 알지 못하고 데이터 타입의 에러를 찾느라 정말 고생했다. 난 바보였다
- 모델의 코드는
LSTM
def create_lstm_model(input_shape, num_classes, dropout_rate):
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=input_shape))
model.add(Dropout(dropout_rate))
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(dropout_rate))
model.add(LSTM(256, return_sequences=True))
model.add(Dropout(dropout_rate))
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(dropout_rate))
model.add(LSTM(64, return_sequences=True))
model.add(Dropout(dropout_rate))
model.add(LSTM(32))
model.add(Dropout(dropout_rate))
model.add(Dense(num_classes, activation='softmax'))
return model- 위 함수를 통해 모델을 구축했으며
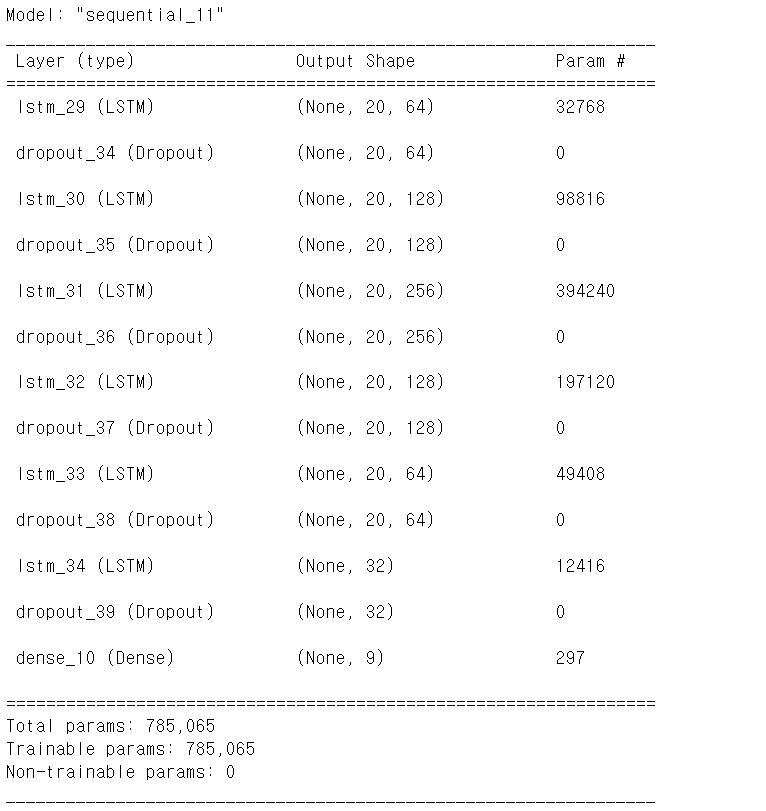
- 위와 같은 형태로 요약된다.
- 하지만 관절의 개수 21개와 xyz좌표값을 하나의 차원으로 축소한 결과 제대로 된 학습이 이루어지지 않아서 다른 모델을 서치했다.
ConvLSTM1D

def build_convlstm1d(input_shape, num_class, dropout_rate):
model = Sequential()
model.add(ConvLSTM1D(filters=64, kernel_size=3, activation='tanh', input_shape=input_shape, return_sequences=True))
model.add(BatchNormalization())
model.add(Dropout(dropout_rate))
model.add(ConvLSTM1D(filters=128, kernel_size=3, activation='tanh', return_sequences=True))
model.add(BatchNormalization())
model.add(Dropout(dropout_rate))
model.add(ConvLSTM1D(filters=256, kernel_size=3, activation='tanh', return_sequences=True))
model.add(BatchNormalization())
model.add(Dropout(dropout_rate))
model.add(Flatten())
model.add(Dense(64, activation='elu'))
model.add(BatchNormalization())
model.add(Dropout(dropout_rate))
model.add(Dense(num_class, activation='softmax'))
return model- 사용한 모델은 ConvLSTM1D모델이다. 해당 모델은 시계열 구조와 공간적 데이터의 특징을 모두 사용할 수 있는 모델이다.
- 1D 합성곱 레이어와 LSTM의 레이어를 합쳐 입력 시퀀스의 공간적인 패턴과 시간적인 의존성을 모두 학습할 수 있다.
- input_shape의 차원은 3차원이며 각 차원은 (시퀸스의 길이, 공간적 차원, 채널수)이다. 여기서 시퀸시는 프레임이며, 공간적 차원은 각 관절의 21개, 채널수 xyz로 대입된다.
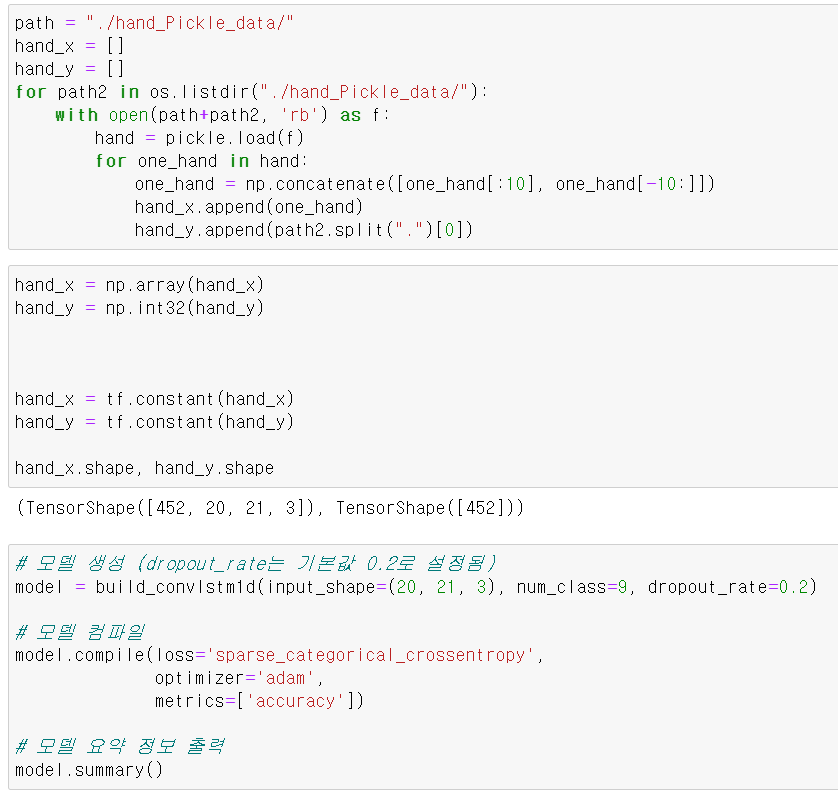
- 그리고 기존의 (20, 63)을 쓸 수 없기에 다시 데이터를 불러와 x 데이터는 (20, 21, 3)으로 만들었다.
- 그리고 loss는 oneHotEncorder로 변환하기 위해 sparse 계열의 loss를 사용했으며, opimizer는 역시 adam그리고 측정지표는 accuracy를 사용했다.
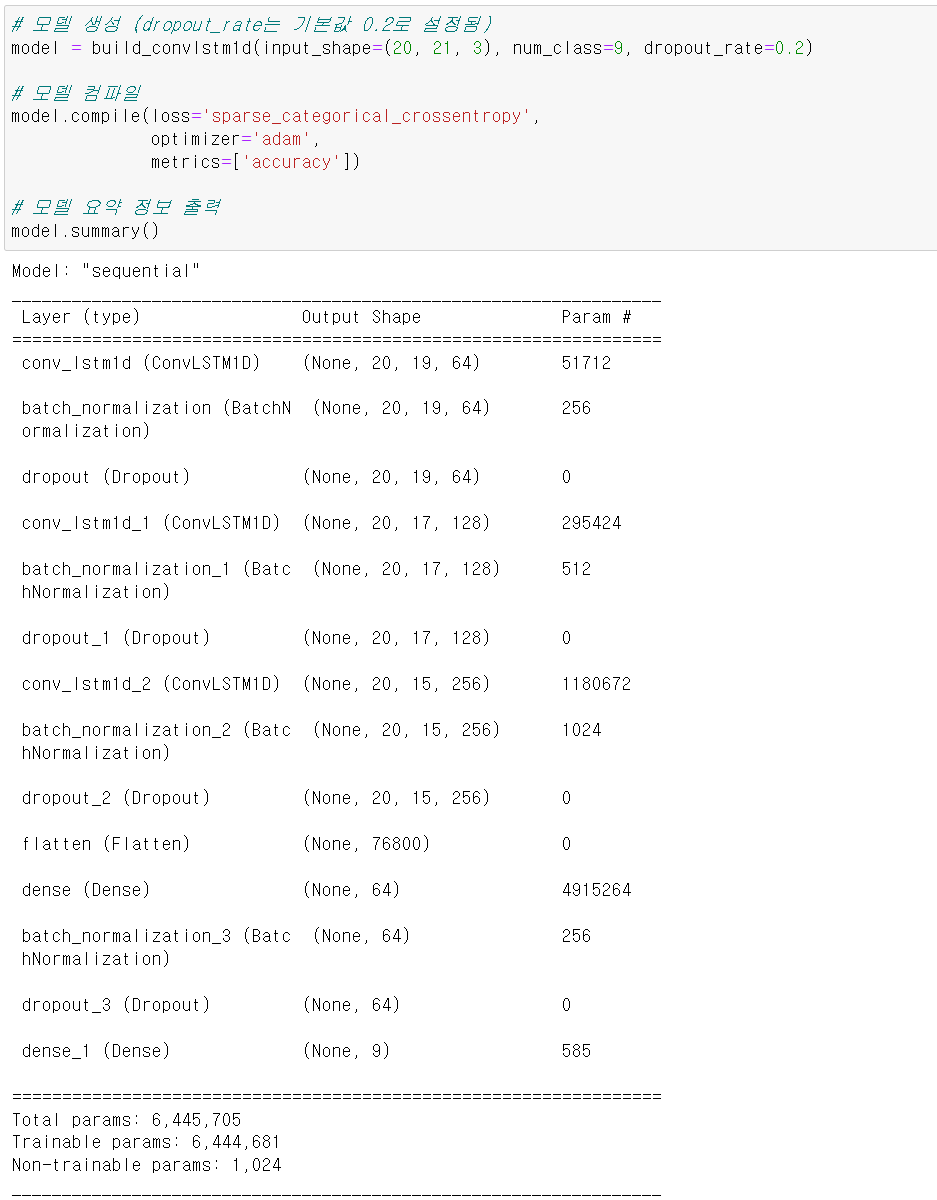
- 모델의 층은 이렇게 구성됐으며
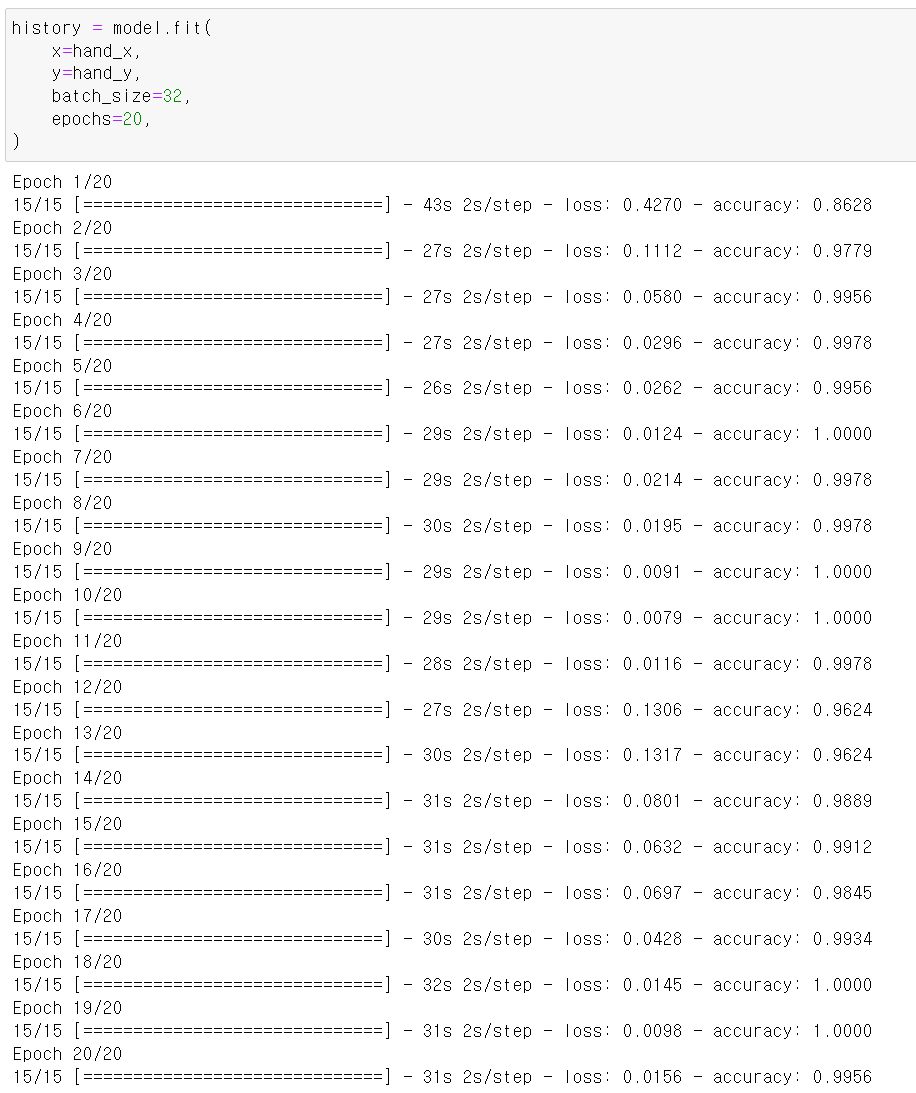
- 모델의 학습 train확인한 결과 매우 좋다.
- 다만 너무 높은 accuracy로 인해 과적합이 의심되기 때문에 Test데이터에 성능을 테스트해봐야겠다.

상황을 바꿀 수 없다면, 나를 바꾸자