- 이번에는 HAR(human activity recognition)에 차원을 축소해서 데이터를 분석해보자
- 먼저 train, test 데이터를 가져오고, 정상적인 형태로 불러온 것을 확인했다.
- 이제 기존의 x_train 데이터의 561개 차원을 PCA를 통해 2개로 축소하고,
- pca.components_.shape은 2개의 index가 561개의 column을 가진 것을 말한다. 기존이 561개의 컬럼이 2개 다 담겨있다고 생각하면 될 것 같다.
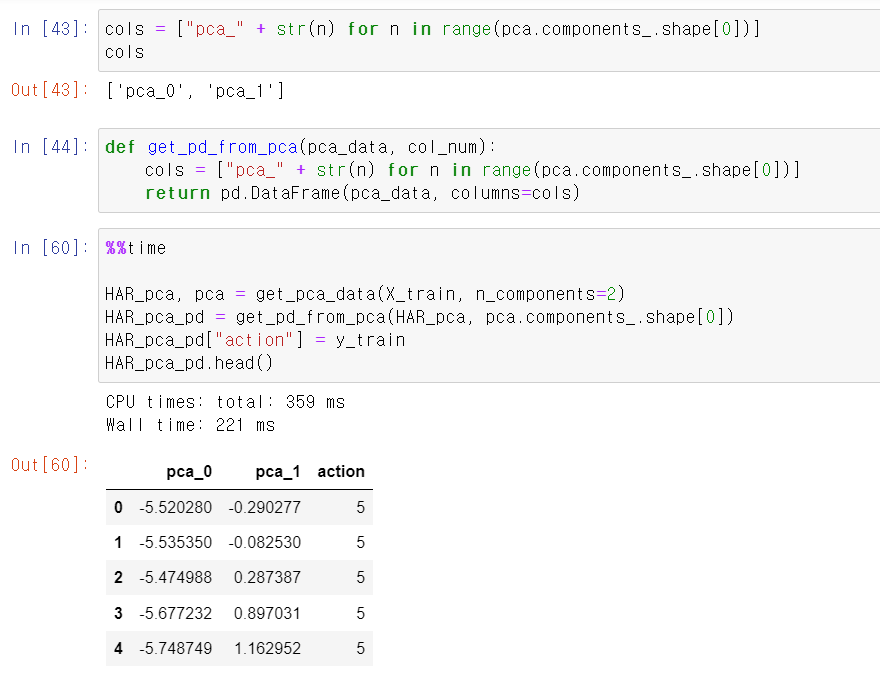
- 이제 컬럼 이름을 cols에 담고, pca 결과를 DataFrame으로 만드는 함수를 저장한 뒤, x_train데이터를 pca 2차원으로 교육시킨 뒤 라벨을 column으로 추가한다.
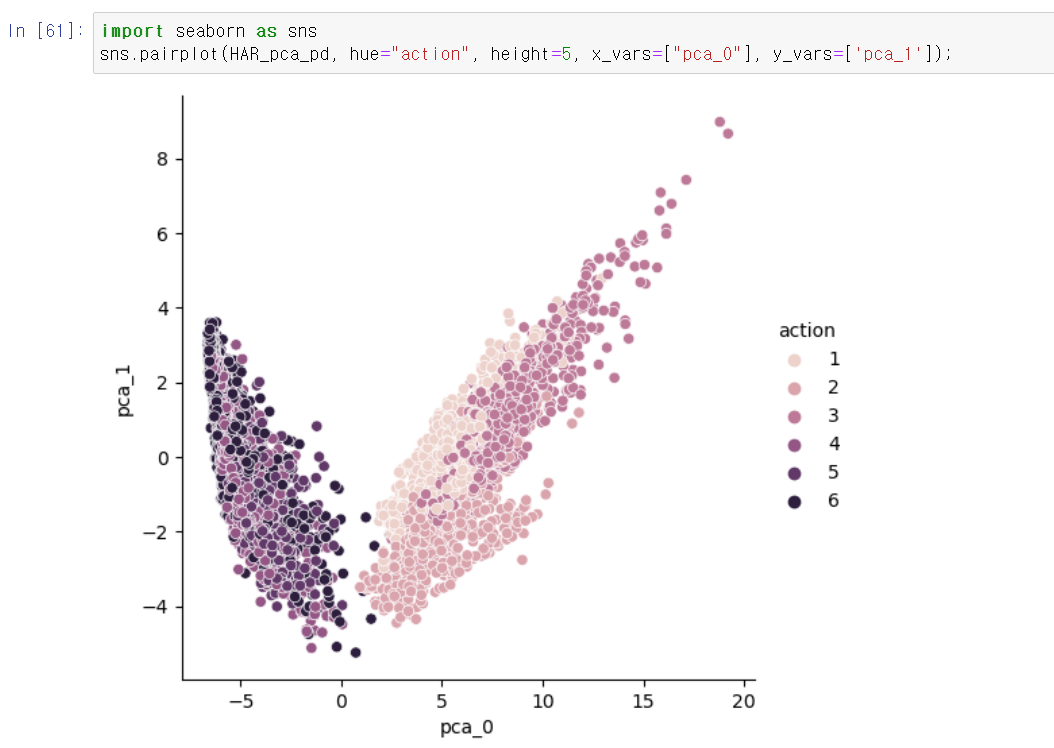
- 해당 DataFrame을 시각화해보니 아무래도 561개의 컬럼을 2개의 차원으로 축소하다보니 겹치는 부분이 많이 존재한다.
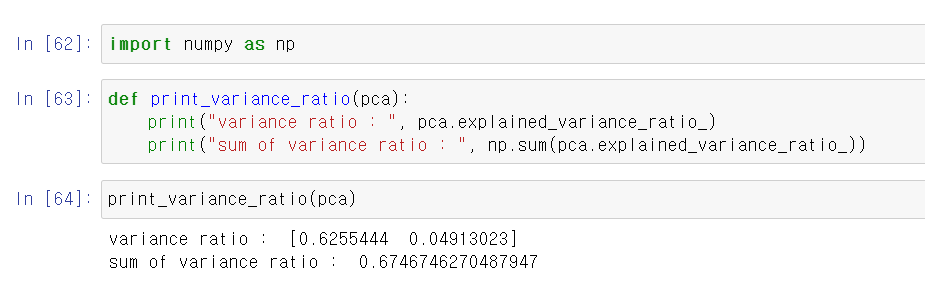
- 이제 pca의 설명력과 설명력의 합계를 보여주는 함수를 만들고, 확인해보니까 67%정도 기존의 데이터를 설명할 수 있다는 것을 볼 수 있다.
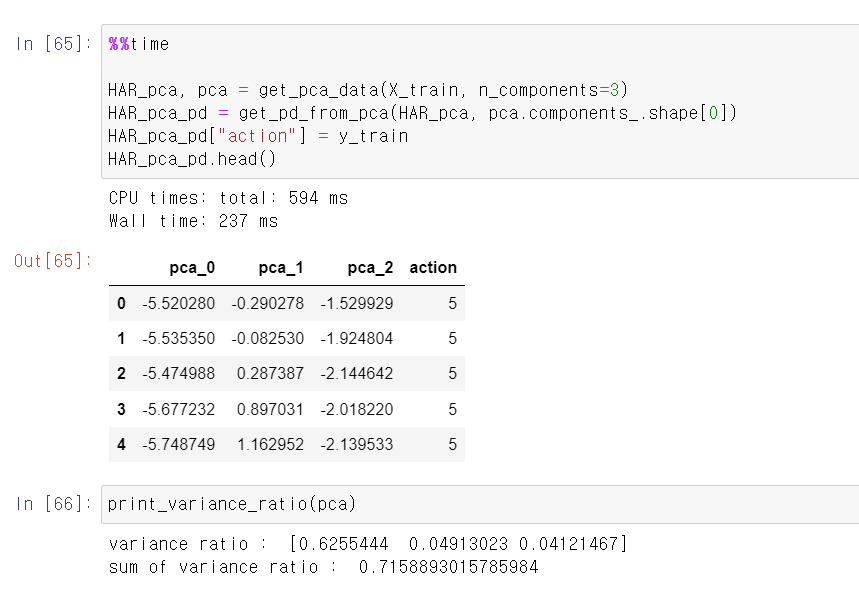
- 이번에는 설명력을 높이기 위해서 3개의 차원으로 확장하고, 해당 결과를 확인해보니 71%정도의 설명력을 보여준다.
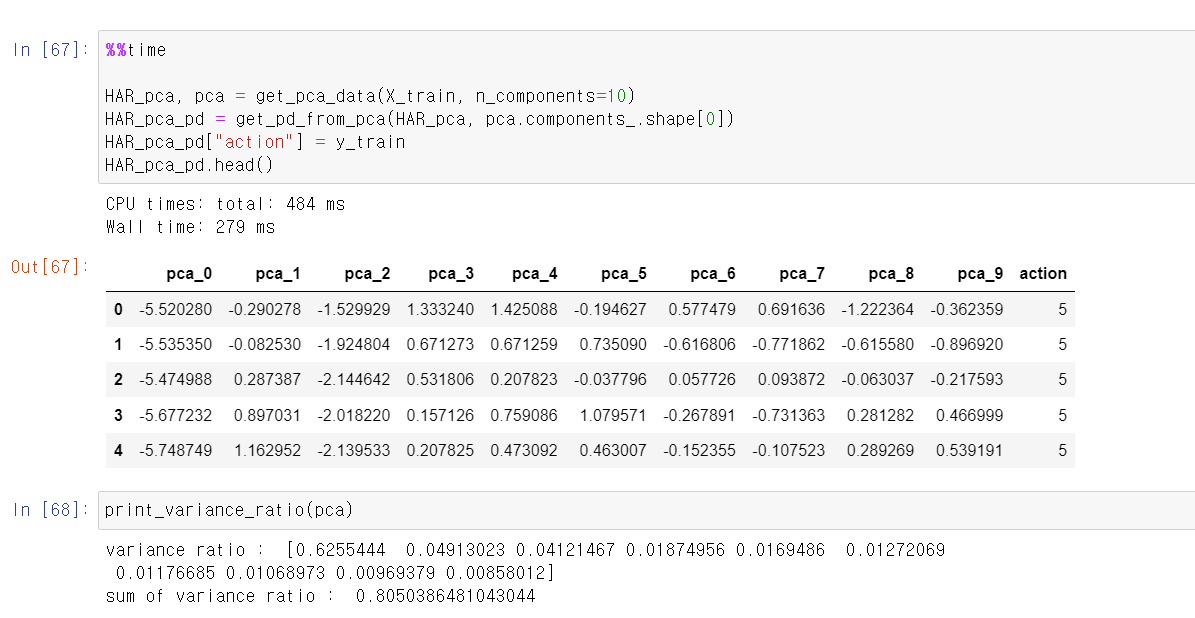
- 10개의 차원으로 확장하니 아무래도 기존의 데이터를 설명할 수 있는 설명력이 더 높아진다.

- 이제 text데이터와 비교를 해보자
- 먼저 RandomForest기법을 사용하고, GridSearchCV를 사용해서 2단계에서 교차검증을 한다.
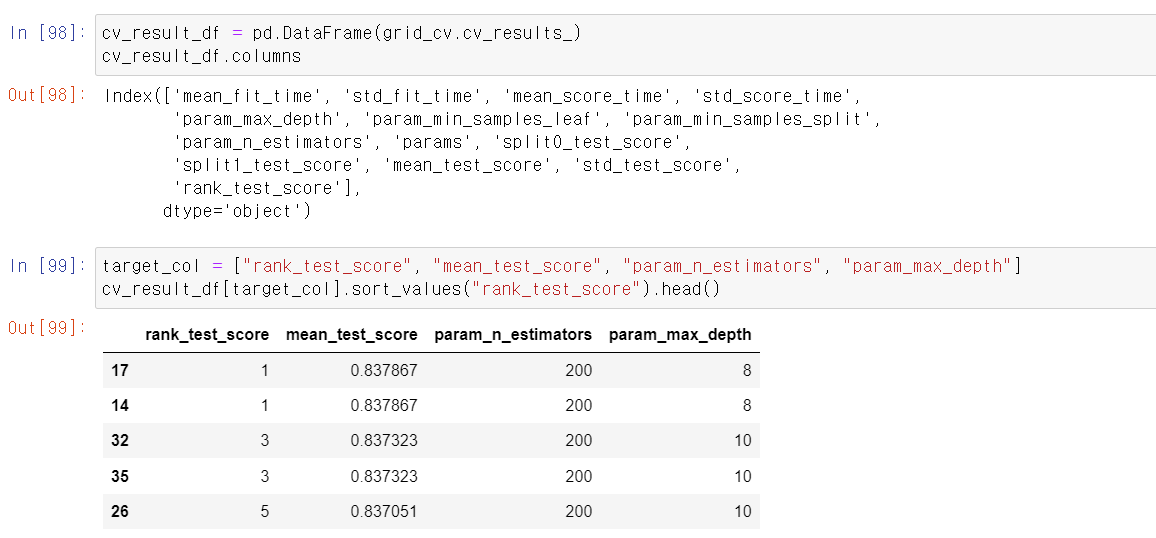
- n_esitimators 200개 및 8 max_depth에서 가장 높은 성능을 보인다.

- 이제 해당 모델링으로 x_train의 pca데이터와 y_train 라벨링을 교육시킨 뒤 x_test 데이터에 예측한 결과와 y_test결과를 비교해보니 85%의 성능을 보여준다.

상황을 바꿀 수 없다면, 나를 바꾸자