
- 이제 머신러닝 데이터 분석을 시작해보자
- 본격적인 머신러닝을 하기 이전에 어떤식으로 프로세스가 작동되는지 내가 먼저 스스로 머신이 됐다고 생각하고 러닝을 해보자, 일명 "Human learning'
- 먼저 머신 러닝의 무조건적인 입문 자료 iris를 통해 시작했다.
- sklearn 모듈의 iris데이터를 불러왔다.
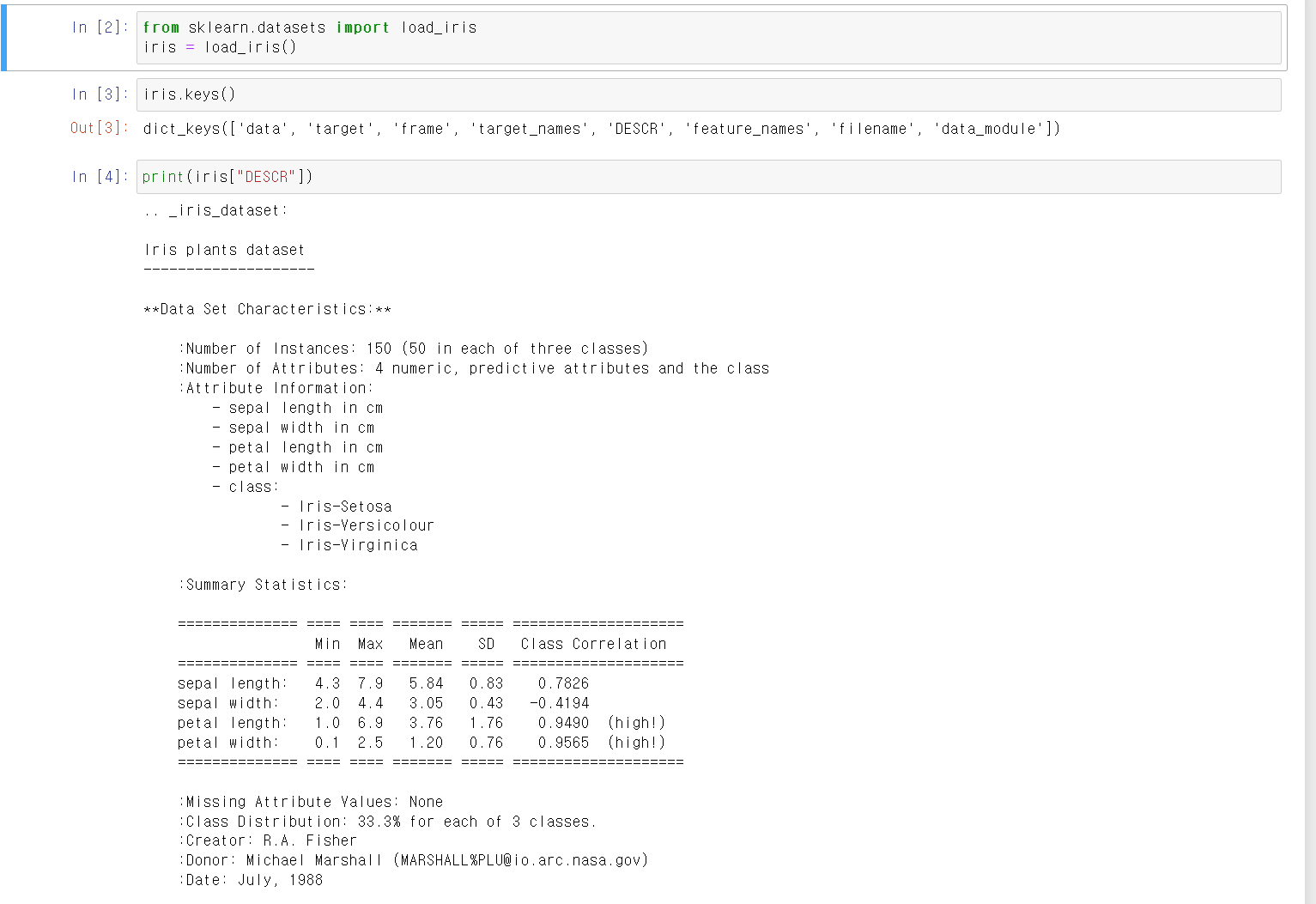
- 해당 데이터의 key값으로 data, target, frame, target_names, DESCR, feature_name 등이 있었다.
- 해당 데이터의 전체적인 정보를 확인했다.
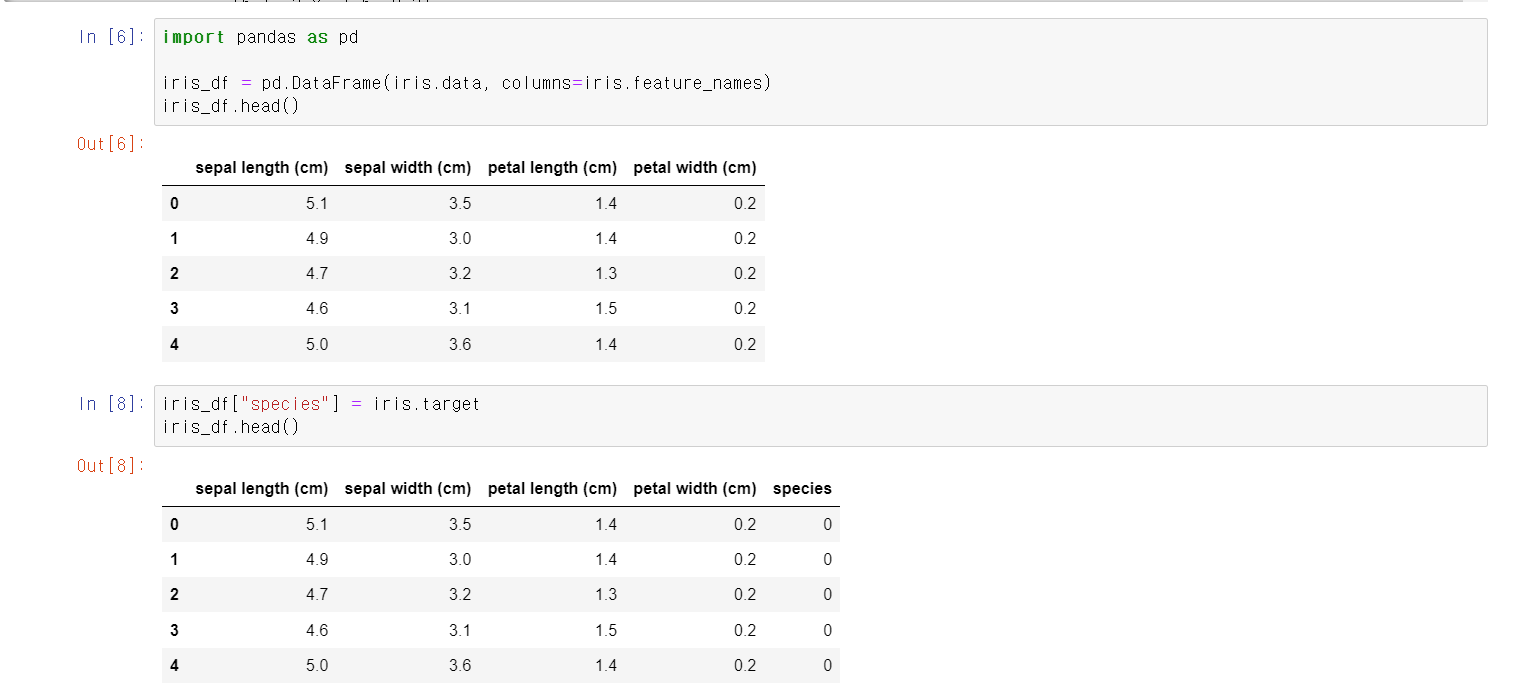
- 조금 더 보기 편하고 데이터를 가공하기 위해서 iris.data를 DataFrame으로 만든 후, target 0, 1, 2(setosa, versicolor, virginica)을 column에 추가했다.
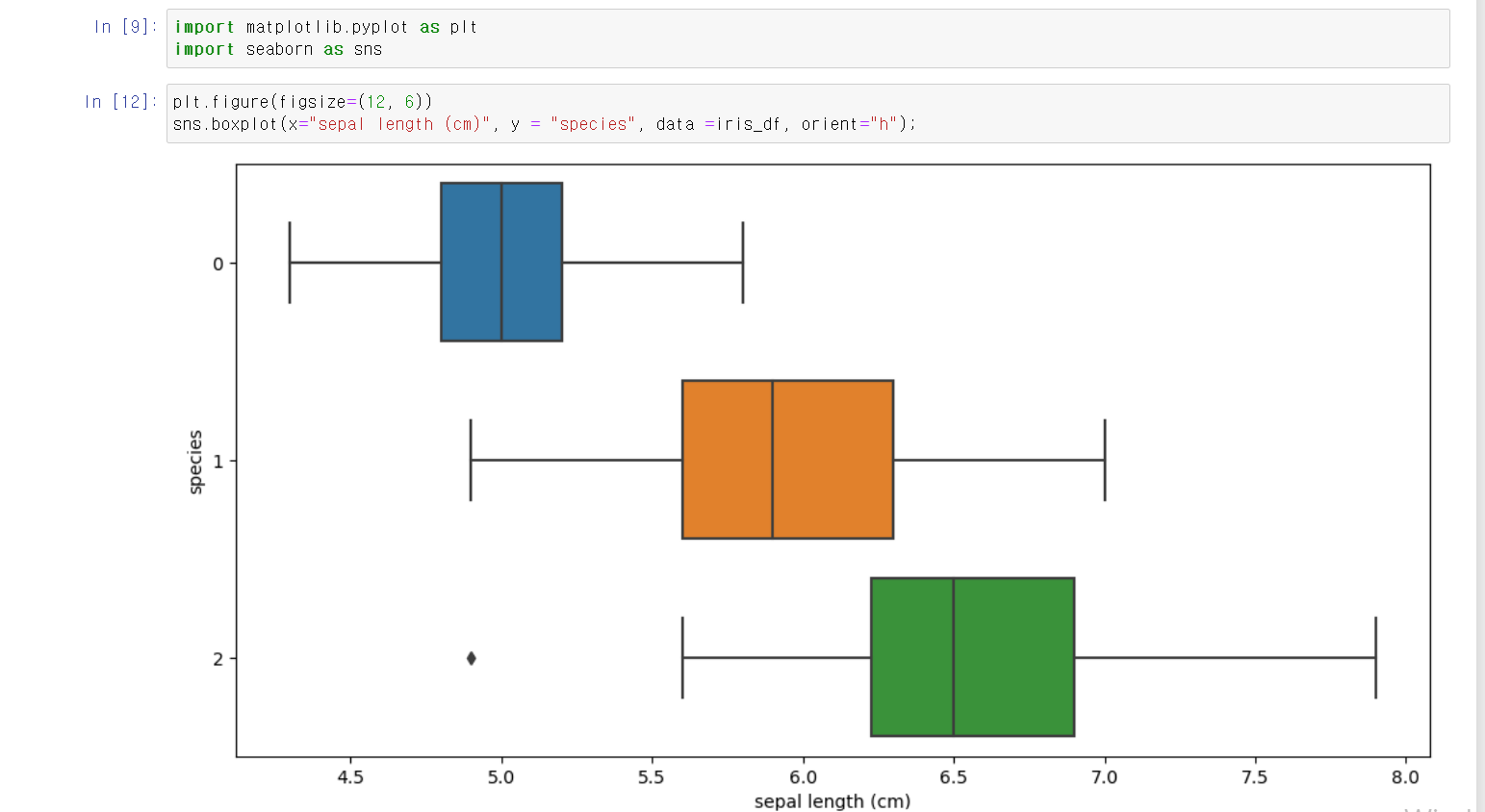
- 각 feature에 따라 개별적인 분석을 했다.
- 먼저 sepal length(cm)와 종에 따른 분석에서 명확한 차이를 구분할 수 없었다.
- setosa의 4분위, versicolor 2분위, virginica 1분위가 겹침으로서 명확한 구분이 어렵다.
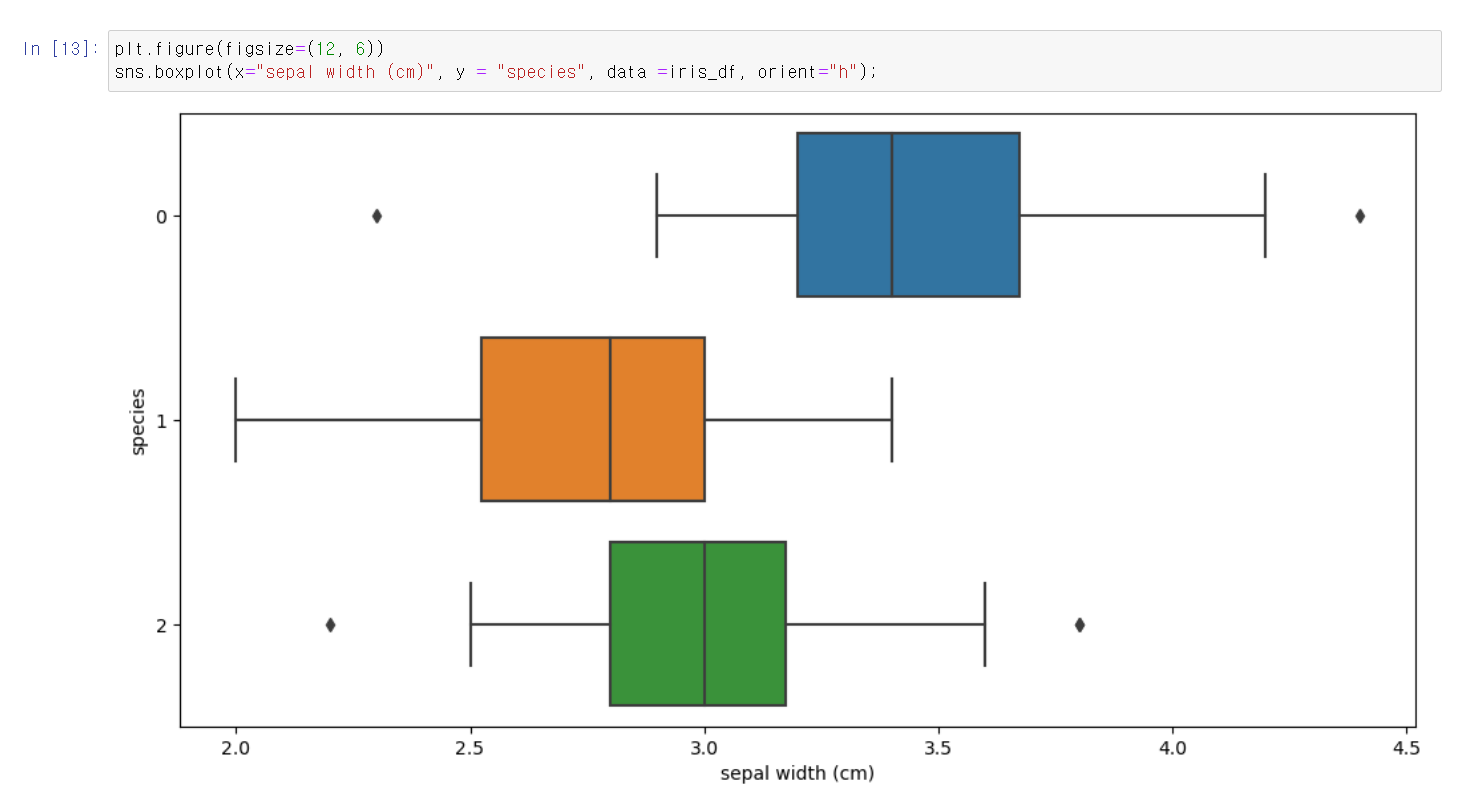
- sepal width를 변수에 넣어도 역시 서로 겹치는 부분이 존재한다.
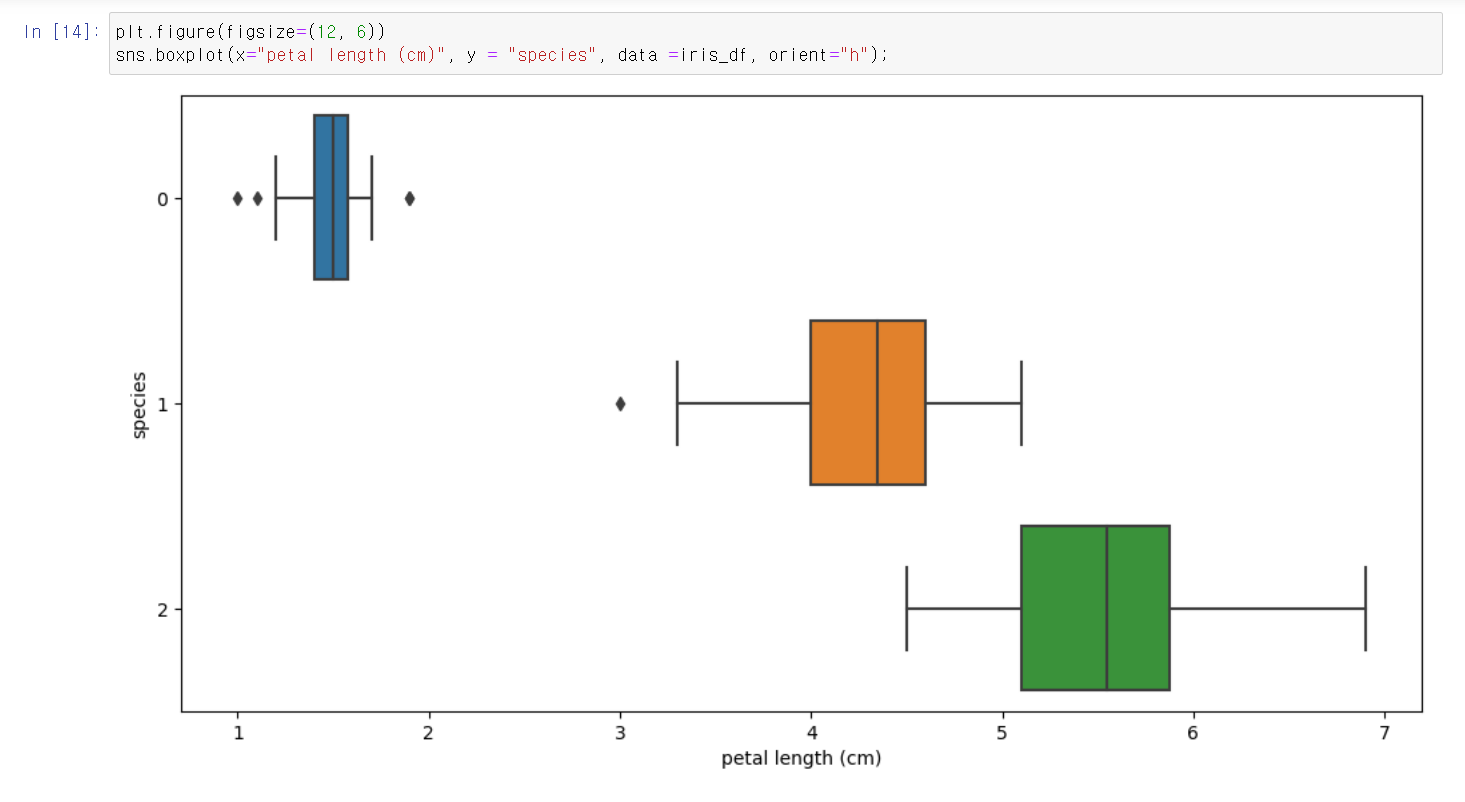
- petal length를 변수에 넣으니 versicolor와 virginica는 구분이 아직 어렵지만, setosa는 확실히 구분이 가능한 것을 알 수 있다.
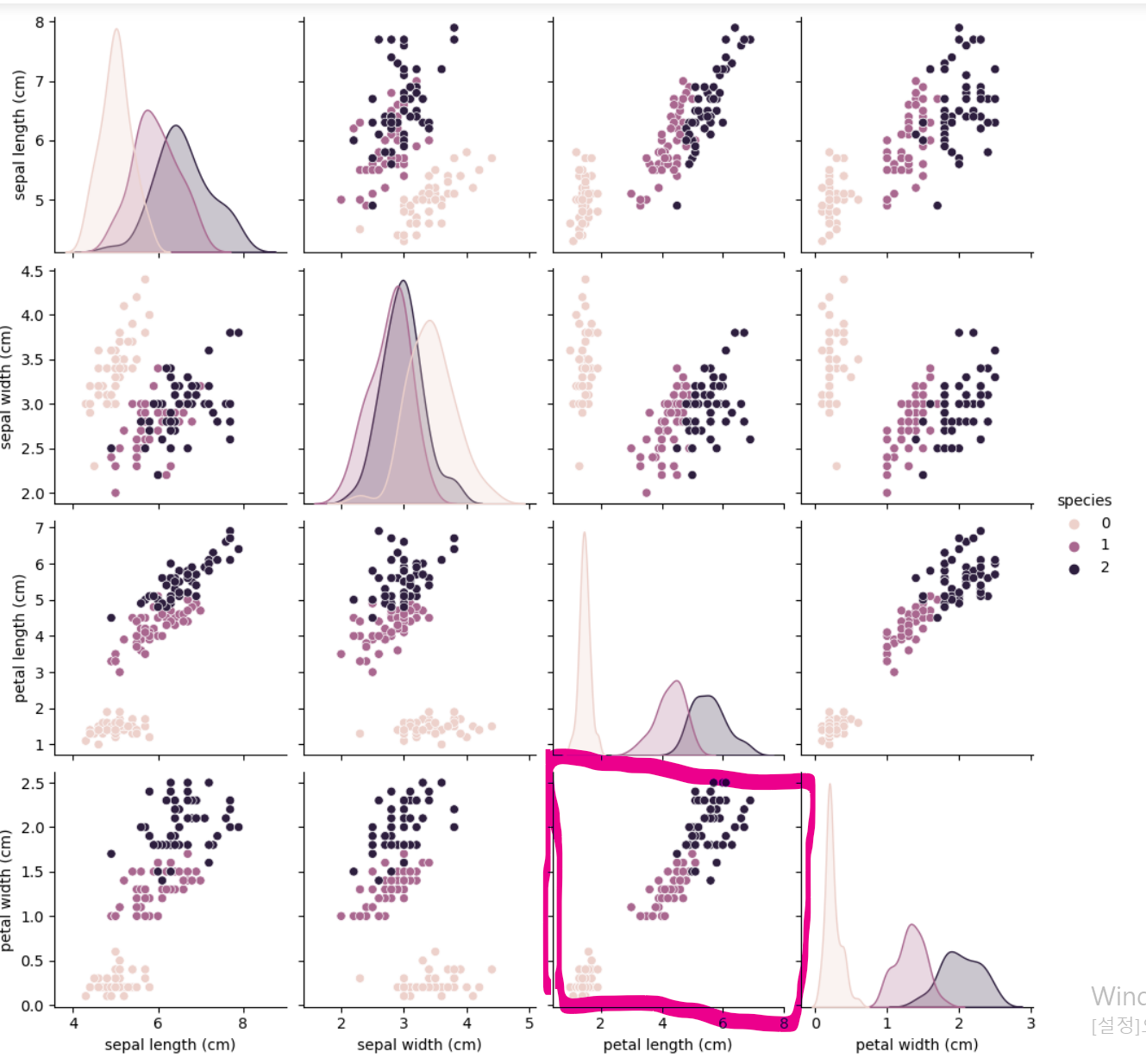
- 히트맵으로 확인한 결과 역시 petal length를 통한 구분이 가장 명확하다는 것을 알 수 있다.
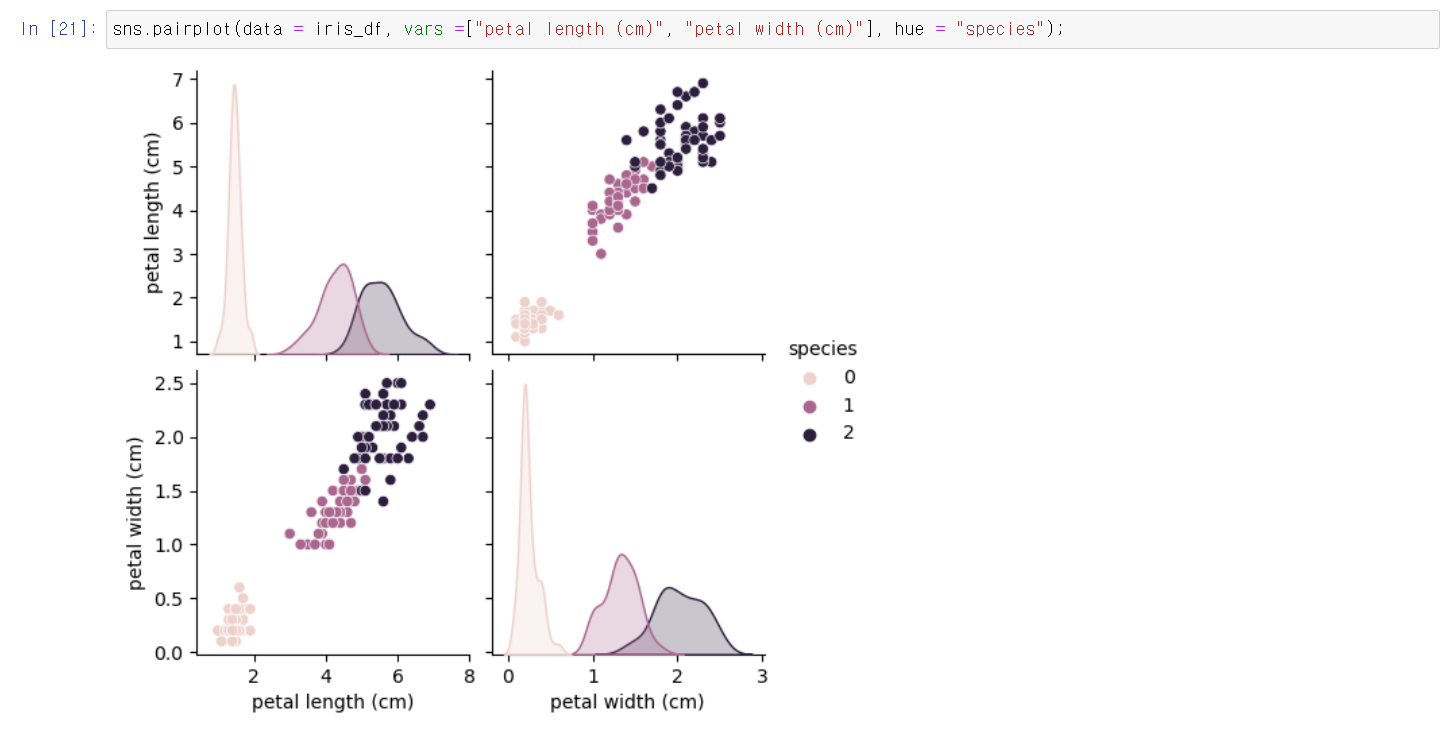
- 해당 데이터만을 히트맵으로 출력해서 보니 versicolor와 virginica의 경우 100% 명확하게 구분되는 것은 아니지만 어느정도 구분이 가능한 것을 볼 수 있다.
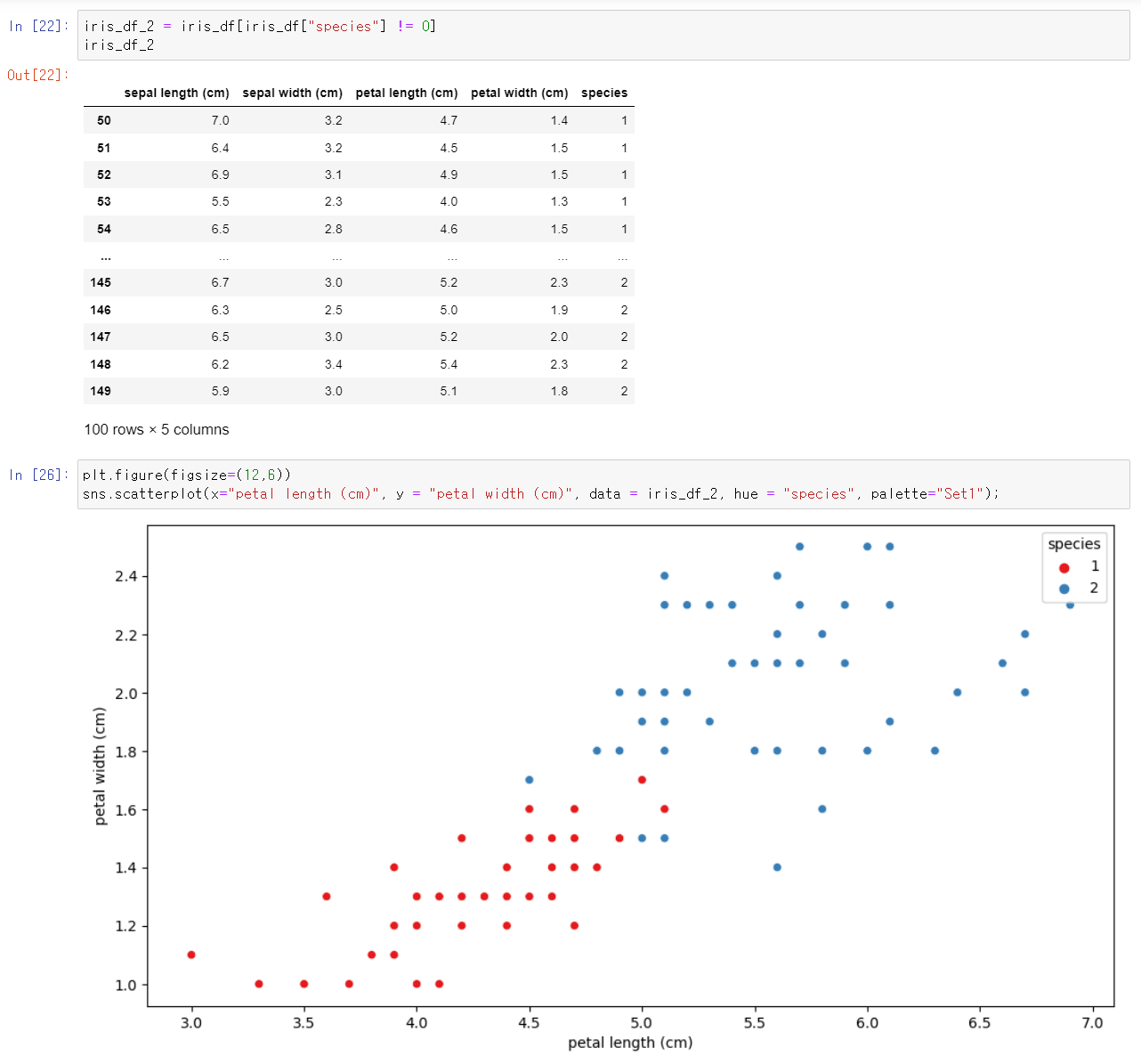
- DataFrame에서 setosa 데이터는 제외하고, versicolor와 virginica 데이터만을 iris_df_2로 저정한 후 산점도로 표현해서 보니 구분했다.
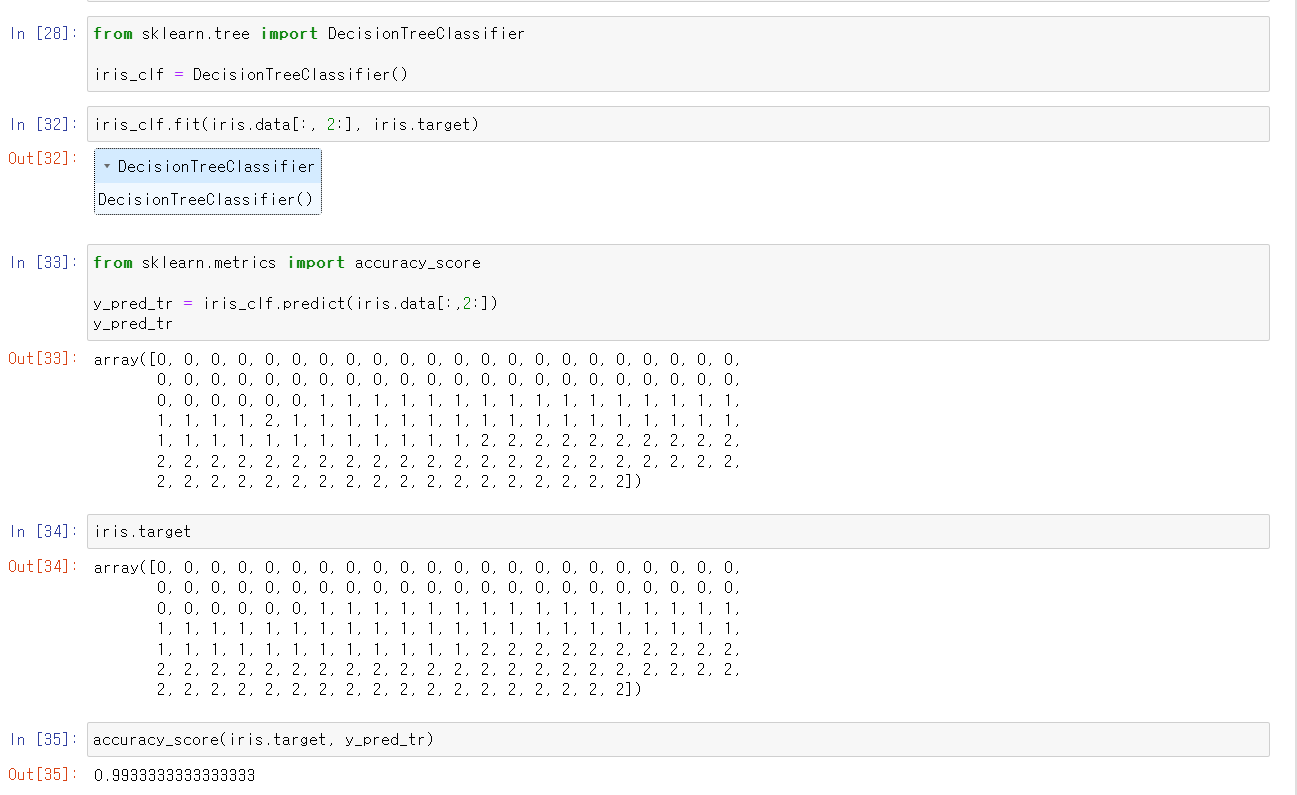
- sklearn 모듈에 DecisionTreeclassifier 기능을 사용해서 해당 데이터를 원본 iris 데이터의 target 즉 정답을 넣음으로써 지도 학습을 시켰다.
- 이후 학습시킨 모델링을 통해 얻은 데이터와 기존의 데이터를 비교한 결과 99% 성능을 보여주는 것을 확인했다.
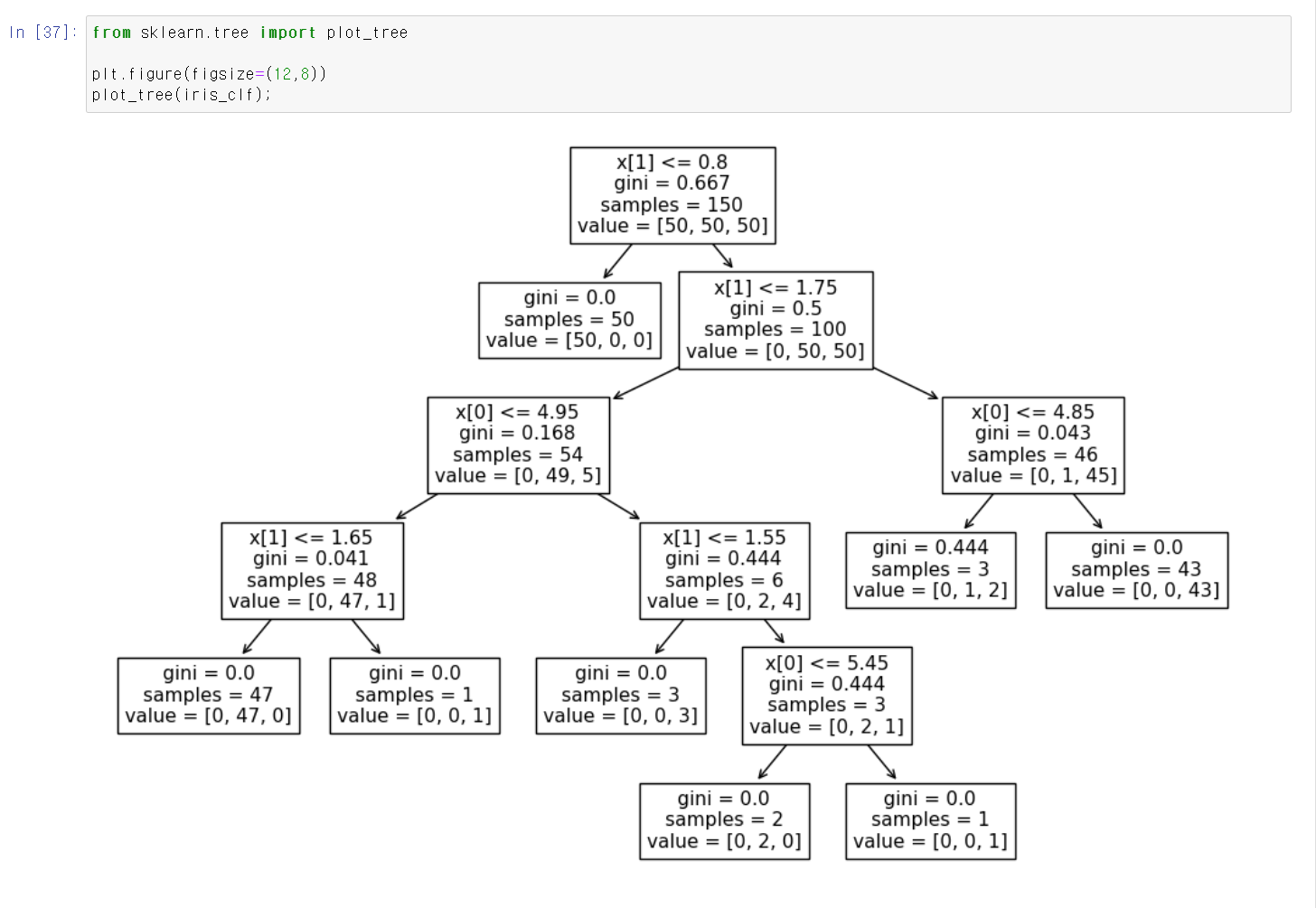
- 해당 DecisionTree를 시각적으로 표현했다.
- dapth가 상당히 깊은데, 깊은 dapth를 통해 모델링의 성능이 높을 수 있었다.
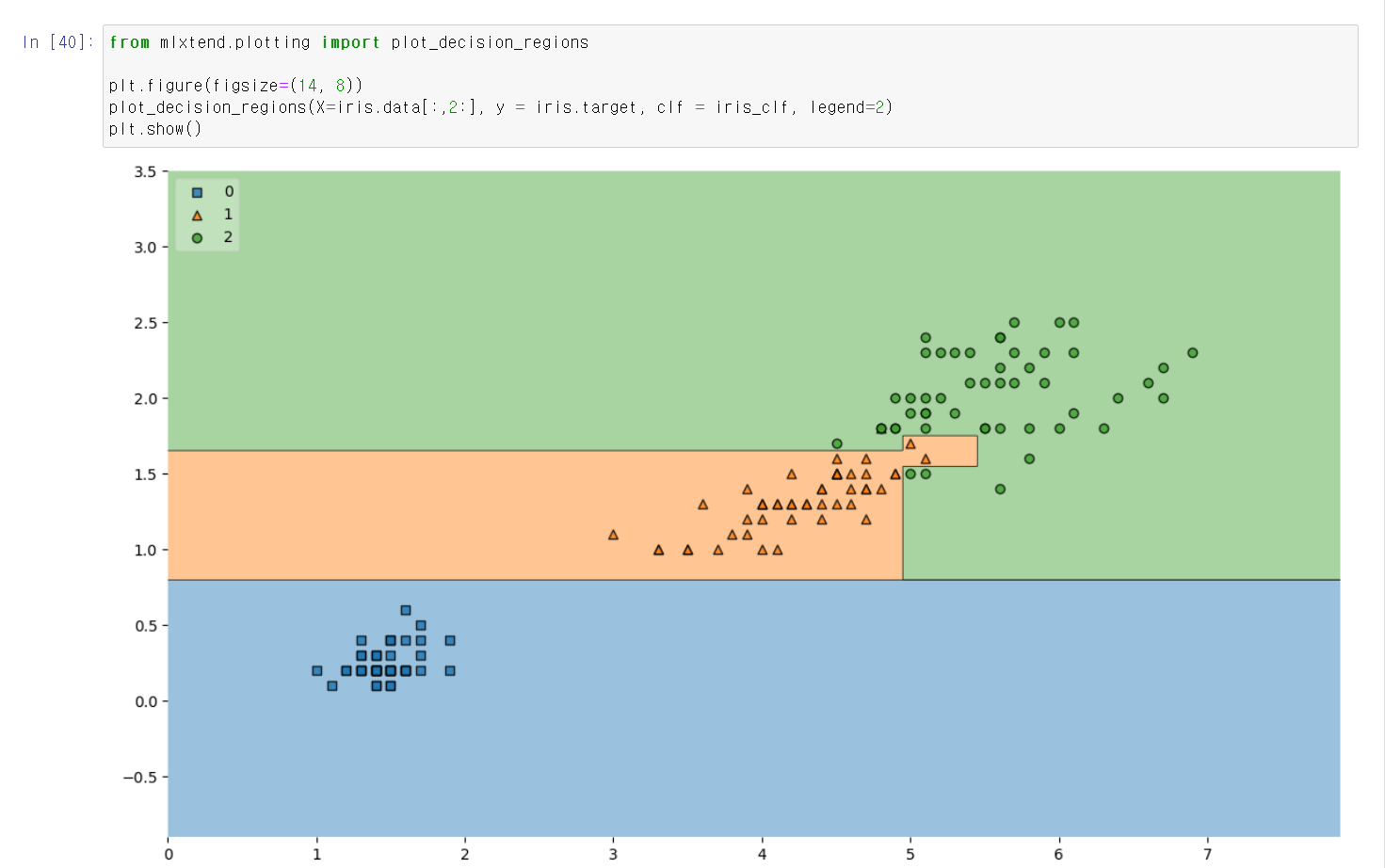
- 두 가지 변수를 통해 해당 모델링을 시각적으로 표현했을 때 versicolor와 virginica 만나는 부분에서 많은 조건문이 사용된 것을 알 수 있다.
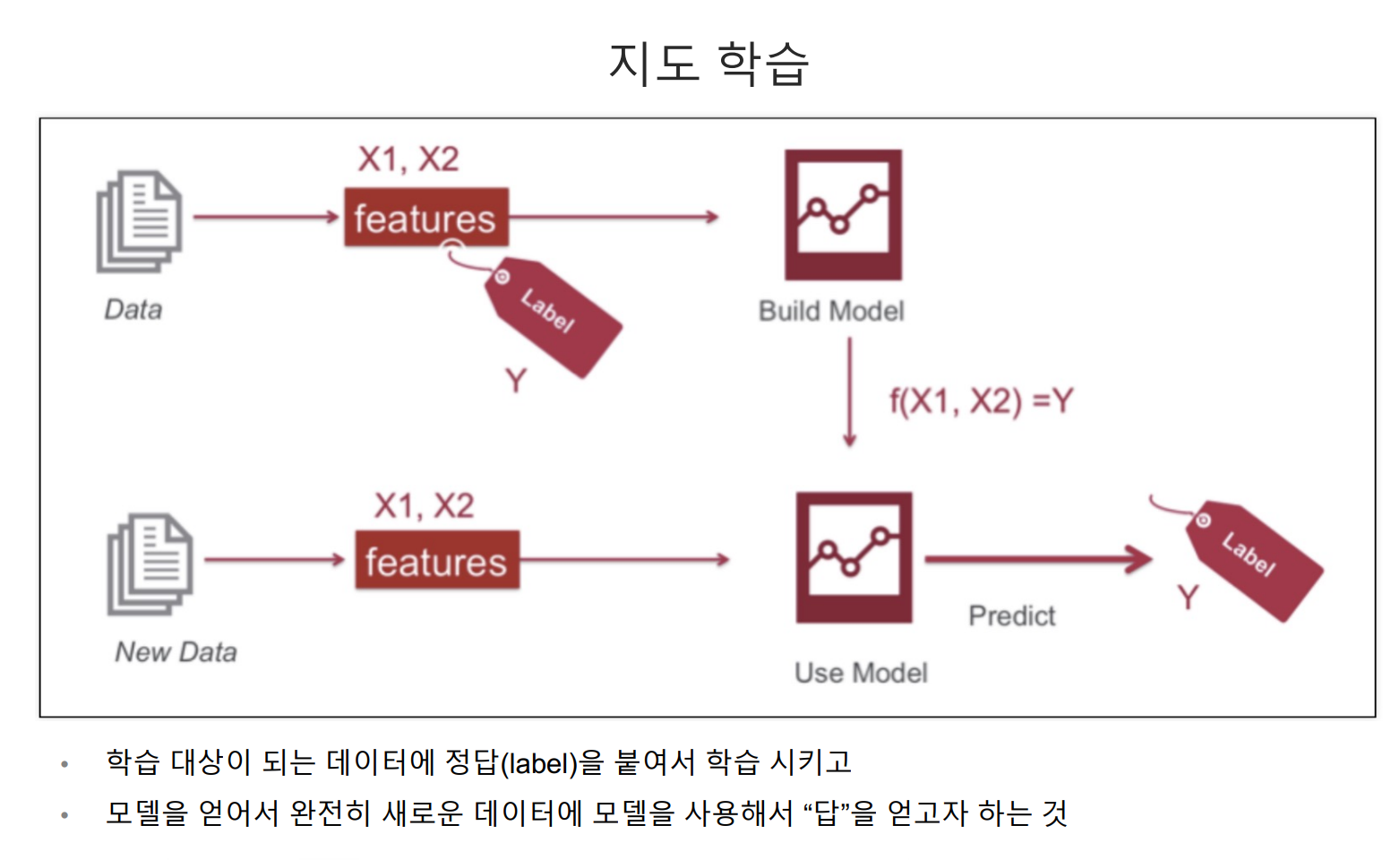
- 머신러닝의 과정은 먼저 data를 통해 모델링을 시키고, 해당 모델링에 새로운 data를 넣음으로써 모델링을 통한 예측값을 얻을 수 있다는 것이다.
- 다만, 위에 과정같이 성능만을 고집한다면 과적합이 발생해 해당 모델은 일반화가 어렵다는 단점이 사실 극단적인 단점으로 사용할 수도 없는 일이 발생한다.

상황을 바꿀 수 없다면, 나를 바꾸자