- iris 데이터를 통해 다시 한 번 머신러닝의 과정을 이해해보자
- 해당 과정에서 중요한 것은 데이터의 분리이다.
- 현실적인 문제로 머신러닝 작업 시 분석 객체의 모든 데이터를 수집하는 것은 어렵다.
- 그렇기에 수집한 데이터를 7:3 혹은 8:2로 분류 후 큰 데이터를 traning 데이터로, 작은 데이터는 모델링을 사용하는 데이터로 활용한다.
- 여기서 150개 irir데이터를 8:2로 구분한 후 numpy를 통해 값을 확인한 결과 0, 1, 2(sotosa, versicolor와 virginica)가 유니크값으로 나오고, 비율은 9, 8, 13으로 나왔다
- 조건에 따라 다르지만 이번에는 각 값들의 비중을 동일하게 하기 위해서 train_test_split의 매소드 중 stratify를 Labels 즉 iris의 target을 넣어 동일한 비중으로 만들었다.

- 여기서 중요한 것은 모델링 과정에서 dapth의 조건으로 2를 넣어서 과도한 적합을 막았다.
- 그러면 성능은 떨어질지 모르지만, 모델링의 일반화가 조금 더 용이해진다.
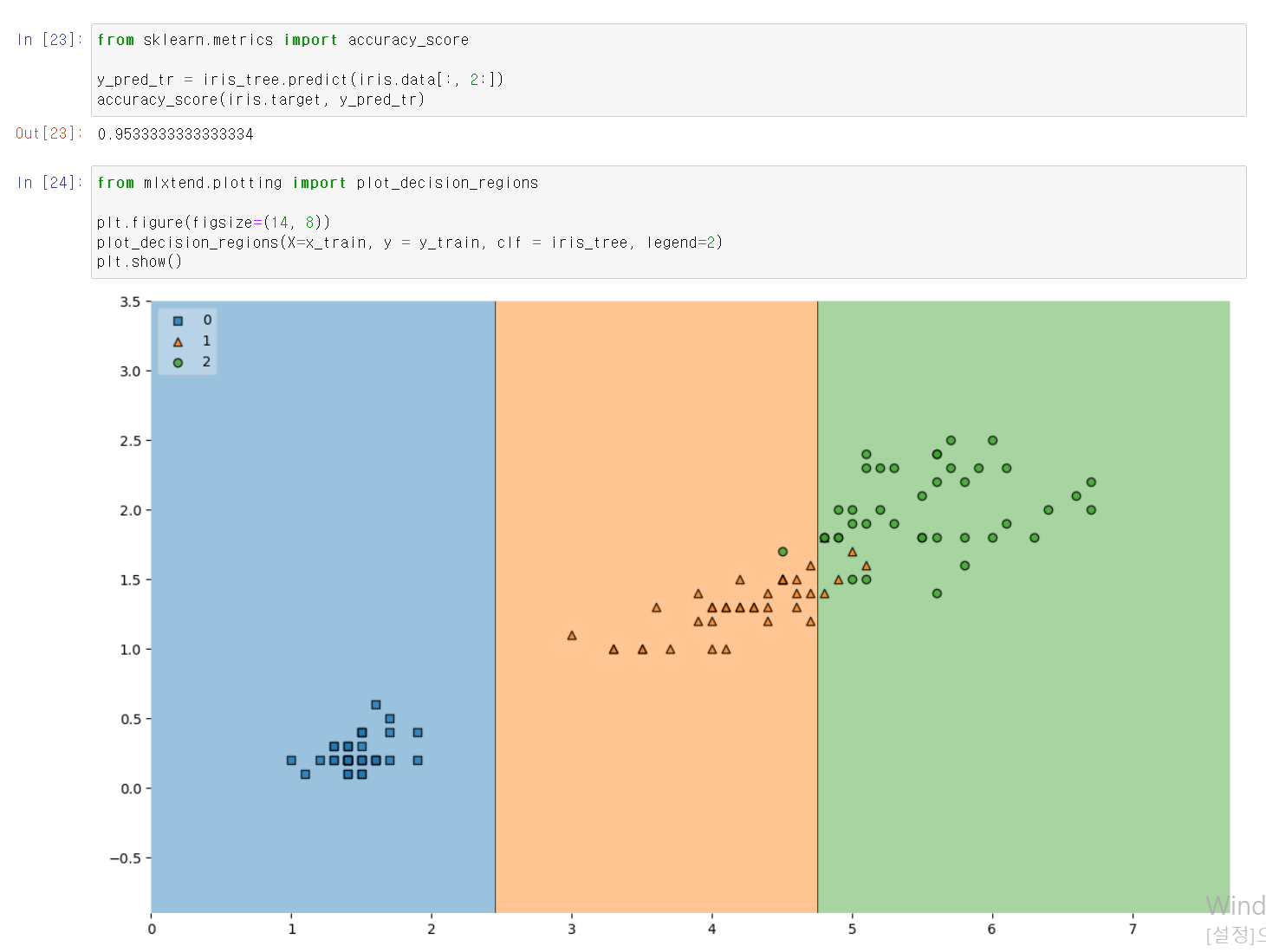
- 성능은 이전 결과보다 조금 더 낮아졌지만,
- 이전 모델링 시각화가 비교했을 때 훨씬 단순하면서 깔끔한 결과가 보인다.
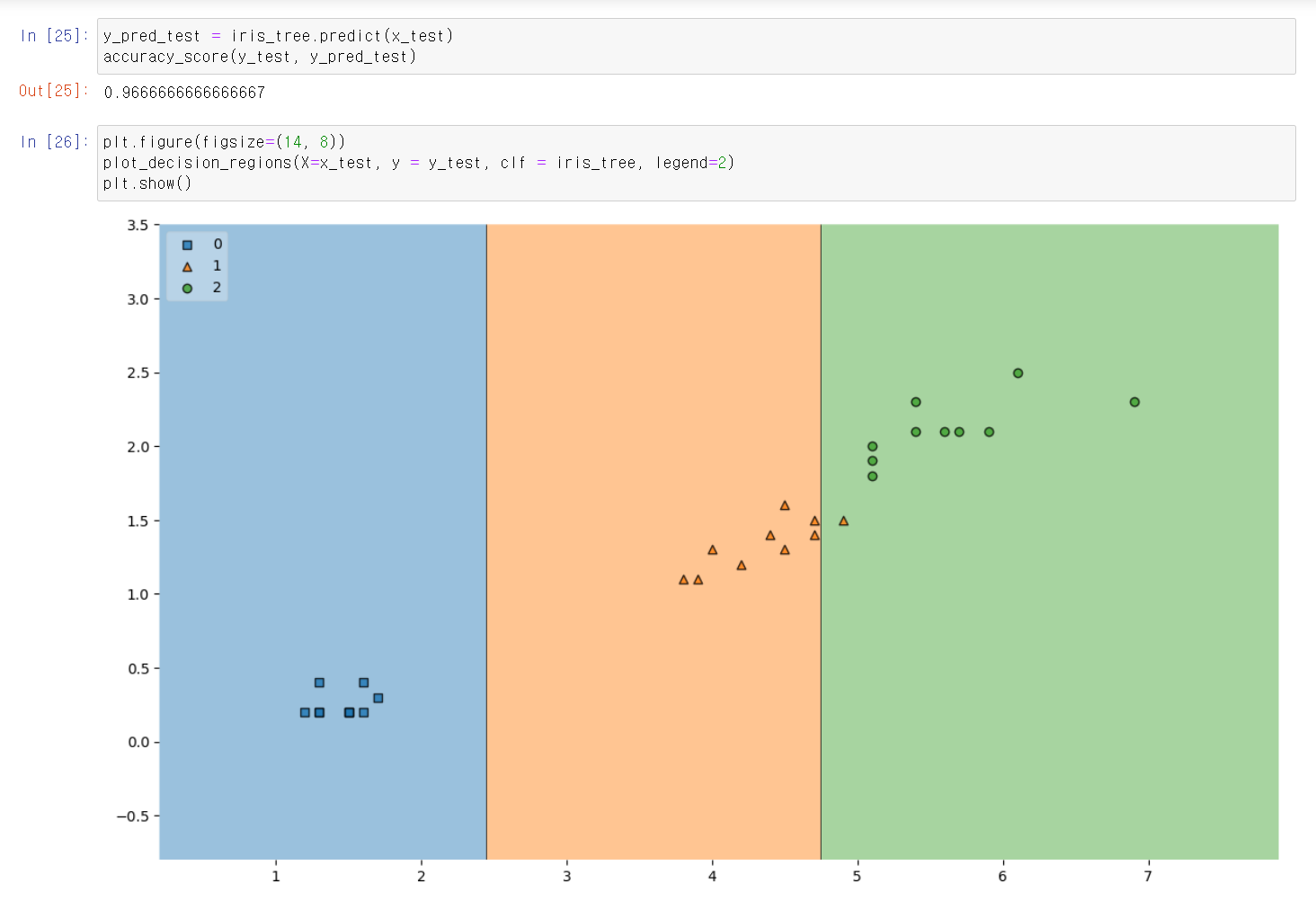
- test 데이터에 대한 성능을 확인한 결과 비슷한 값을 보이며 시각적으로도 비슷하다.
- 트레이닝 데이터의 성능값과 테스트 데이터의 성능이 비슷한 값을 보여준다.
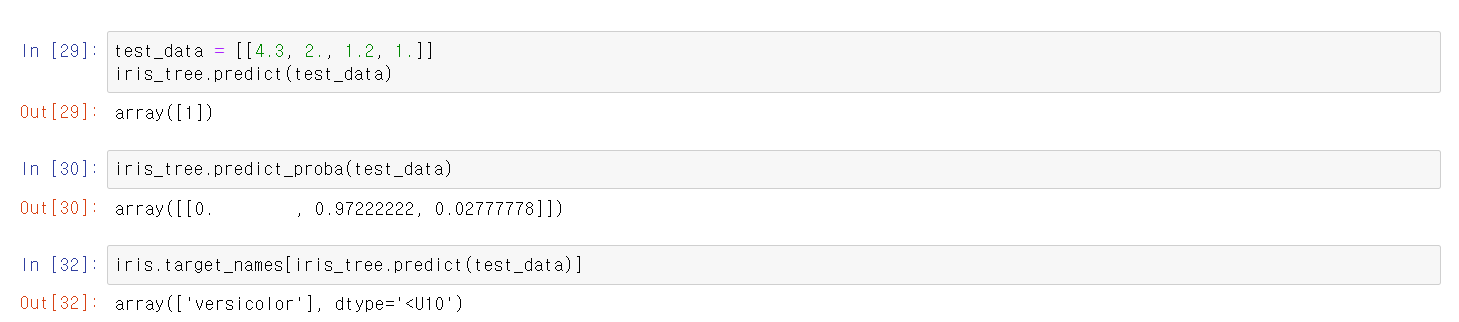
- 임의로 iris 데이터를 만들어 모델에 넣은 결과 해당 데이터는 1 즉, versicolor에 해당하며,
- setosa에 속할 확률은 0%, versicolor에 속할 확률은 97%, virginica에 속할 확률은 0.3% 정도이다.

상황을 바꿀 수 없다면, 나를 바꾸자