- 이번에는 기존의 데이터를 차원축소해서 분석하는 Principal_component를 사용해서 iris데이터와 wine데이터를 분석해보자
- 먼저 정말 친숙한 iris 데이터를 불러온다.
- 그리고 iris데이터를 StandardScaler로 변환 후 4개의 차원(column)을 PCA(Principal_Component)로 2개의 차원으로 축소 후 Standard형태로 변환한 데이터를 교육시킨다.
- 결과를 확인해보니 150개 index와 2개의 차원을 가지고 있다.
- 데이터 형태는 다음과 같다.
- 이제 보기 쉽게 DataFrame형태로 변환하는 함수를 만들어주고,
- 만든 PAC데이터를 DataFrame으로 만든 후 Label값인 species를 추가해준다.
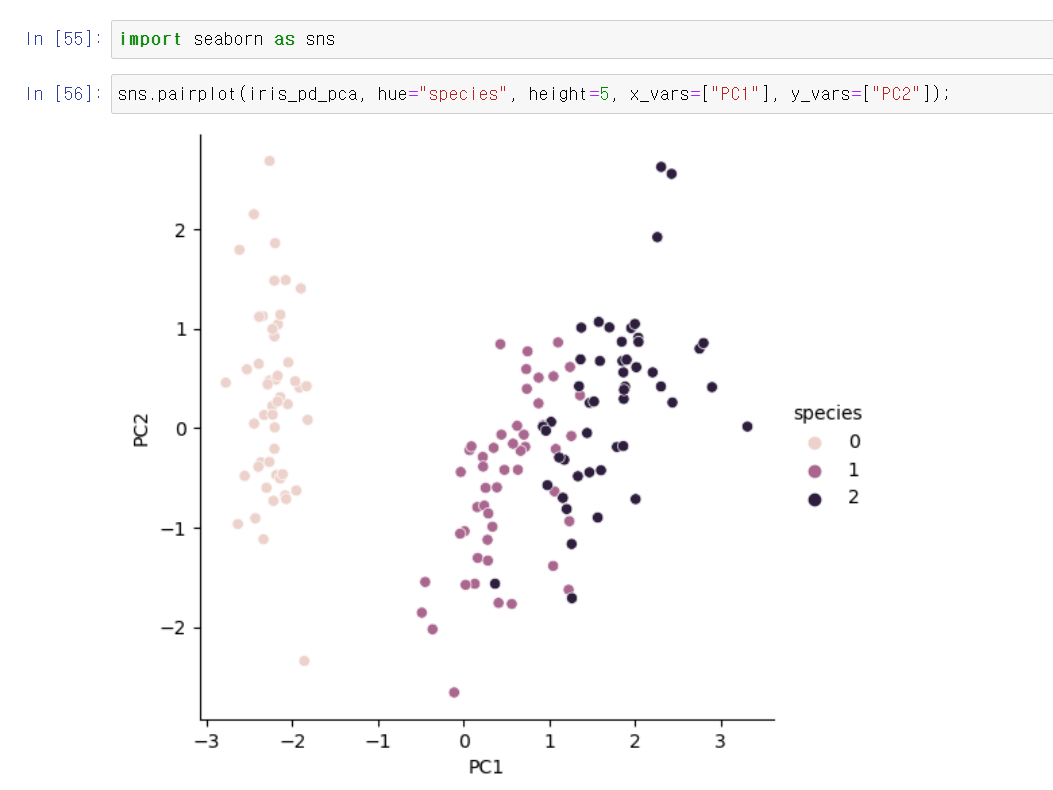
- 이제 seaborn으로 3개의 품종을 구분해서 산점도를 그려보니 생각보다 잘 구분이 된다.
- 특히 0번 품종은 확실히 구분되며, 1번과 2번은 겹치는 부분이 있지만 어느정도 구분이 가능하다.

- 이제 PCA의 설명력을 보니 72%, 22%로 보여준다.
- 이제 해당 PCA데이터를 가지고 모델링을 시켜보자
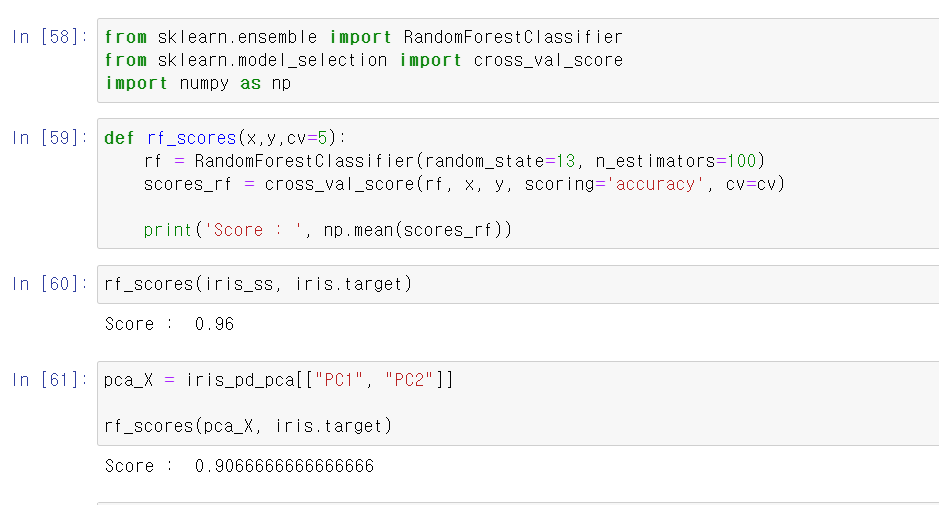
- 일단 기존의 4개의 차원을 가진 iris_ss(standard_Scaler)데이터를 가지고 교차검증을 확인해보니 96%성능을 보여준다.
- 그리고 PCA데이터를 가지고 교차검증을 해보니 90%에 성능을 보여준다.
- 성능을 확연히 떨어지지만, 2개의 차원으로 축소했는데도 어느정도의 예측력을 가지고 있다.
- 이제 와인 데이터를 통해 다시 확인해보자
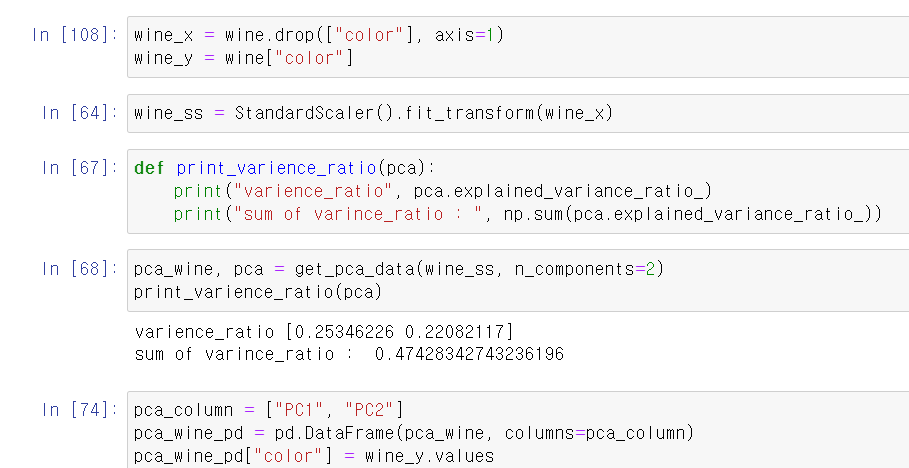
- 먼저 color(레드, 화이트)를 라벨로 사용하고, 나머지를 교육시킬 데이터로 사용한다.
- 그리고 pca설명력과 설명력 합계를 출력하는 함수를 만든다.
- 이제 차원을 2개로 설정하고 PCA데이터를 만든 후 데이터프레임에 label과 함께 저장한다.
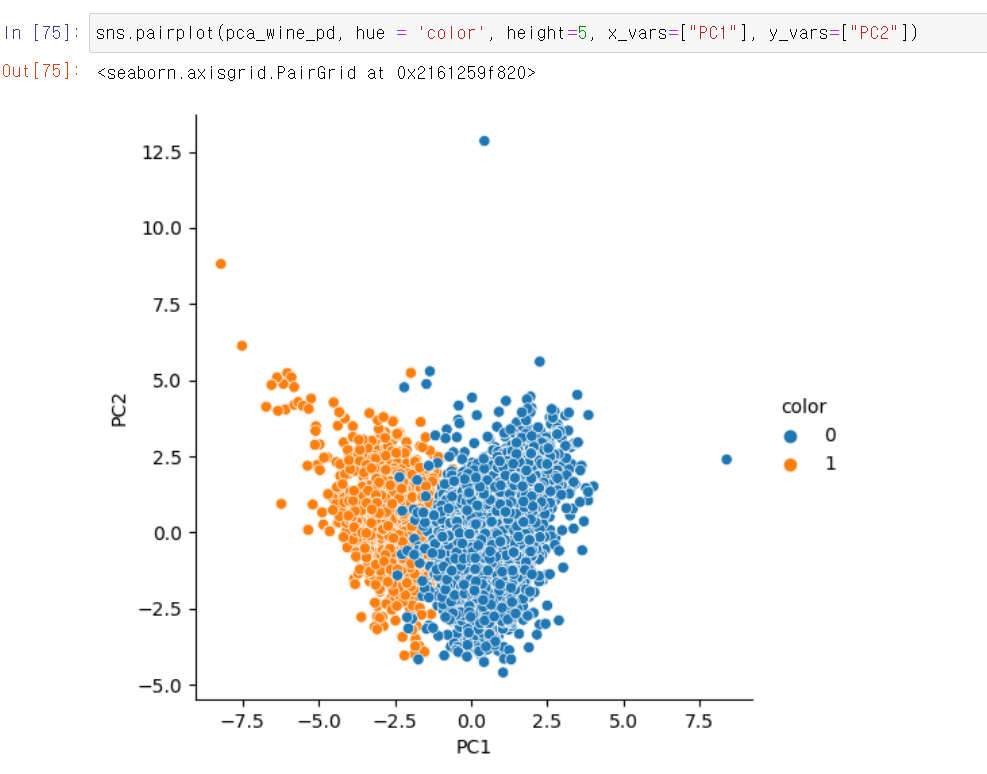
- 만든 데이터프레임의 결과를 시각화를 통해 확인해보니
- 하트모양이 됐네...?아 이게 아니라 0.0을 기준으로 겹치는 부분이 존재하지만, 중간을 기준으로 확실한 구분이 가능하다.
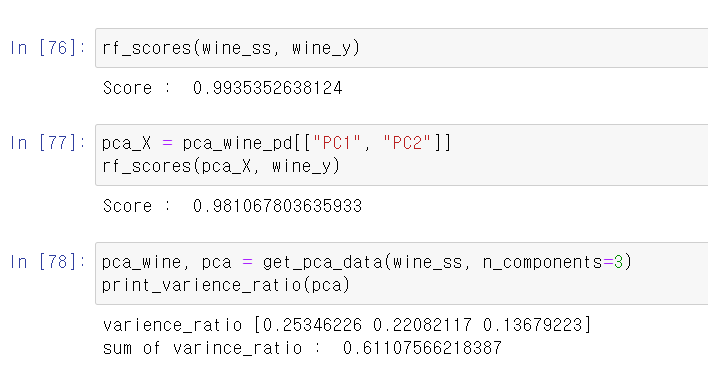
- 이제 기존의 데이터와 PCA데이터의 교차검증 성능을 확인해보니 비슷한 결과를 보여주고, 설명력 또한 출력해서 확인했다.
- 3개의 차원으로 늘려 설명력을 보니 합계설명력은 어느정도 올라갔다.
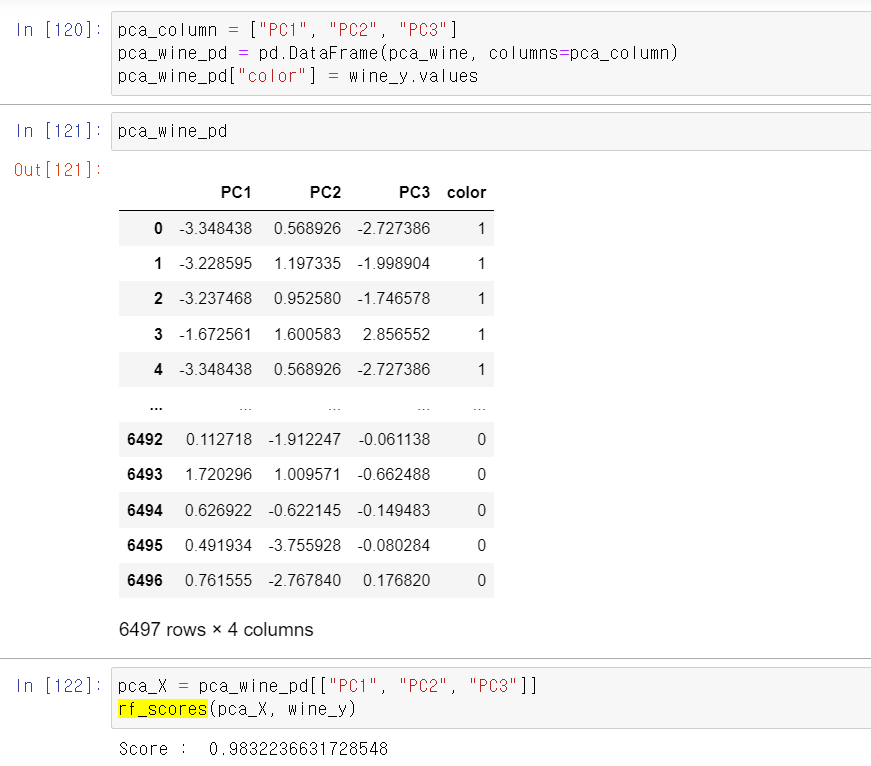
- 이제 3개의 차원으로 교차검증을 해보니 음...비슷하다.
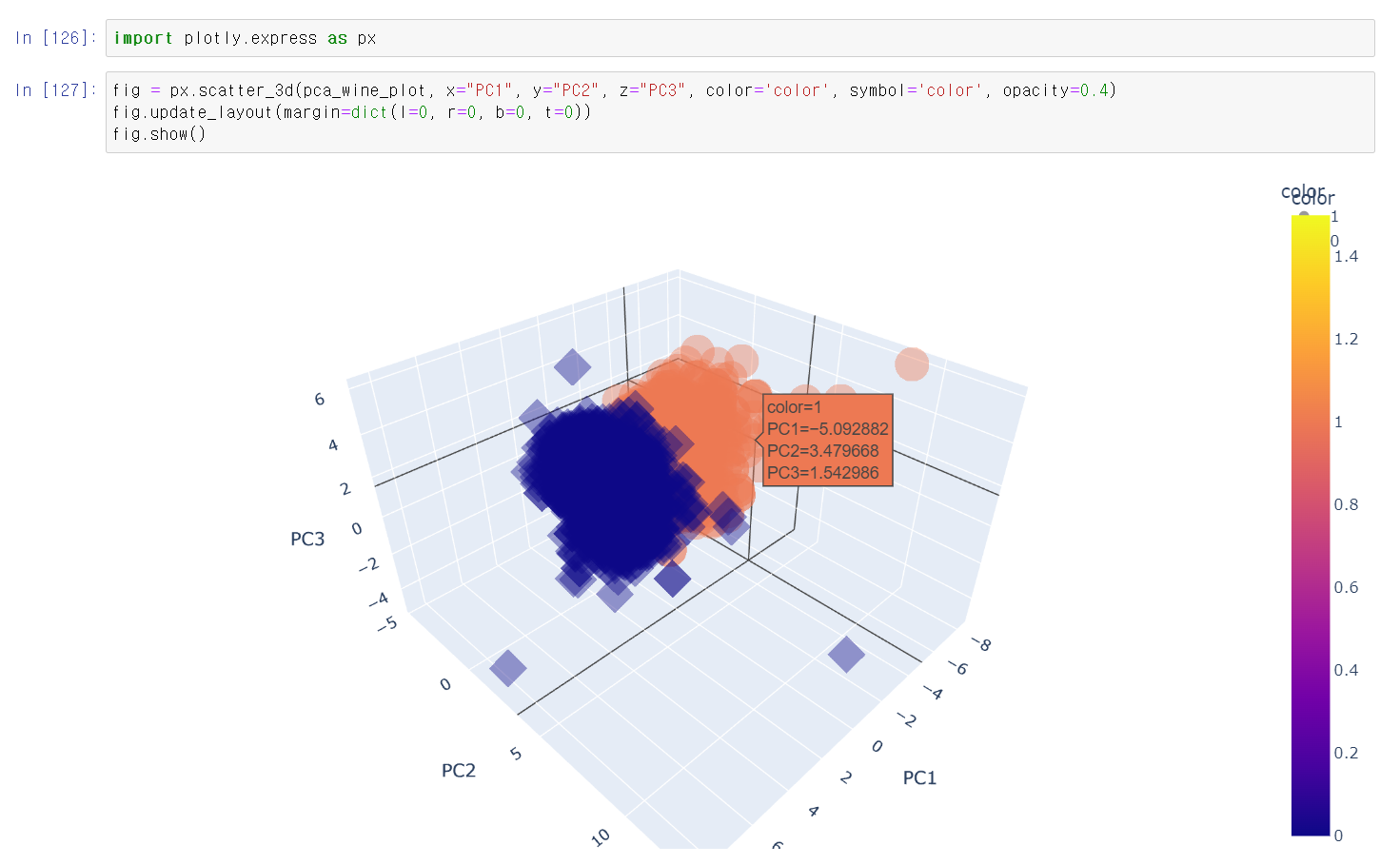
- 마지막으로 3차원 데이터가 어떤 형태인지 plotly를 통해 시각화를 해봤다.

상황을 바꿀 수 없다면, 나를 바꾸자