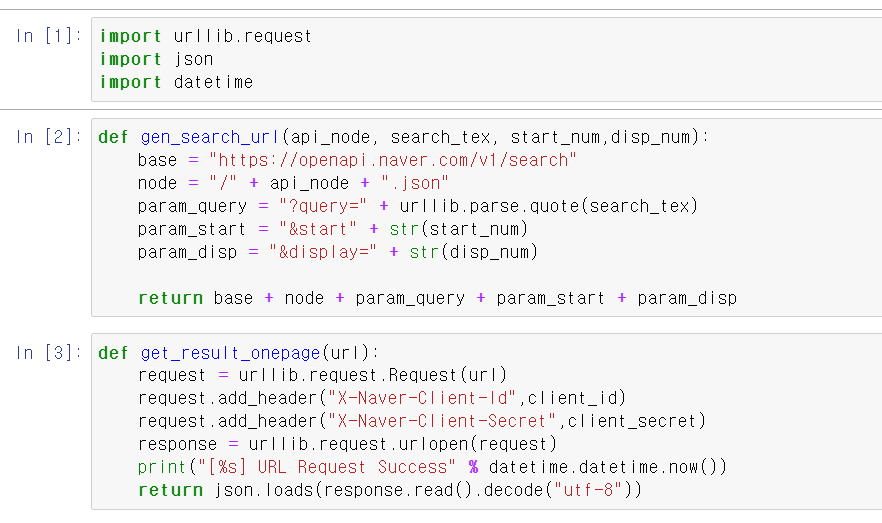
- 이제 네이버에서 Train데이터를 크롤링해서 불러온 후 자연어 모데링을 해보자
- 크롤링 과정을 예전 EDA할 때 사용한 함수를 불러와서 사용했다.
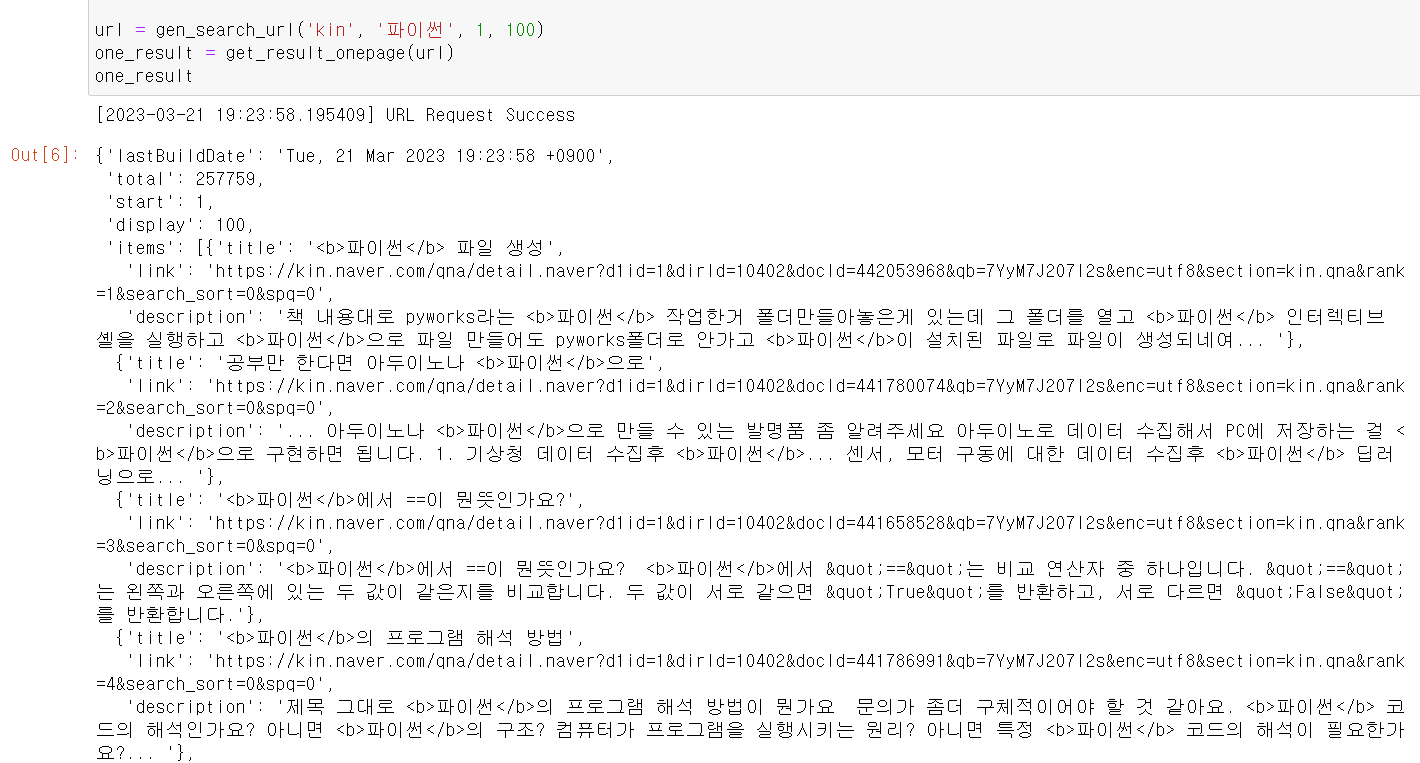
- 파이썬이 들어가는 검색을 한 후 100개의 문장을 추출하고,
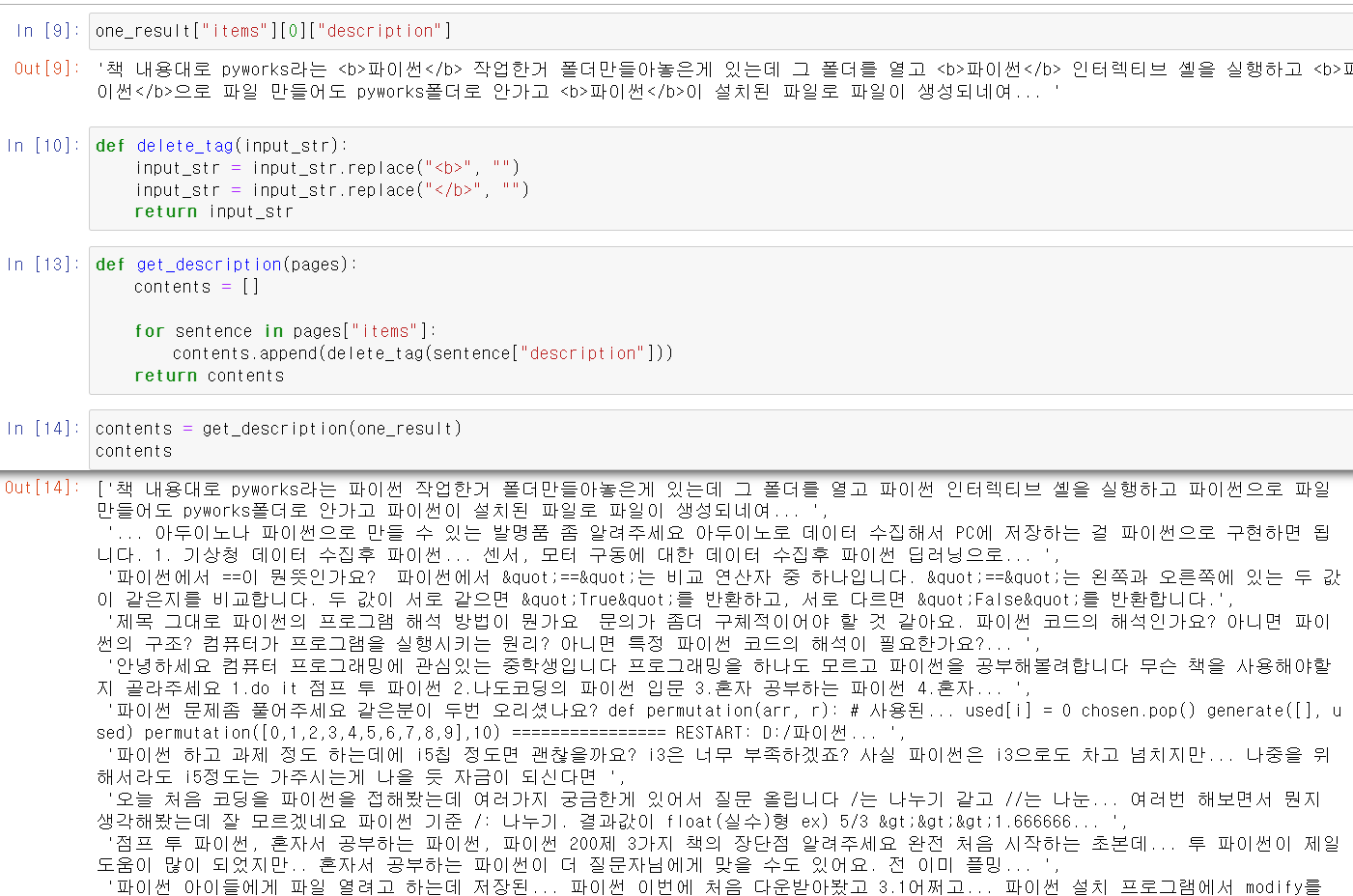
- 해당 문장에서 html기호를 빼고 리스트의 인덱스마다 하나의 문장씩 string형태로 저장했다.
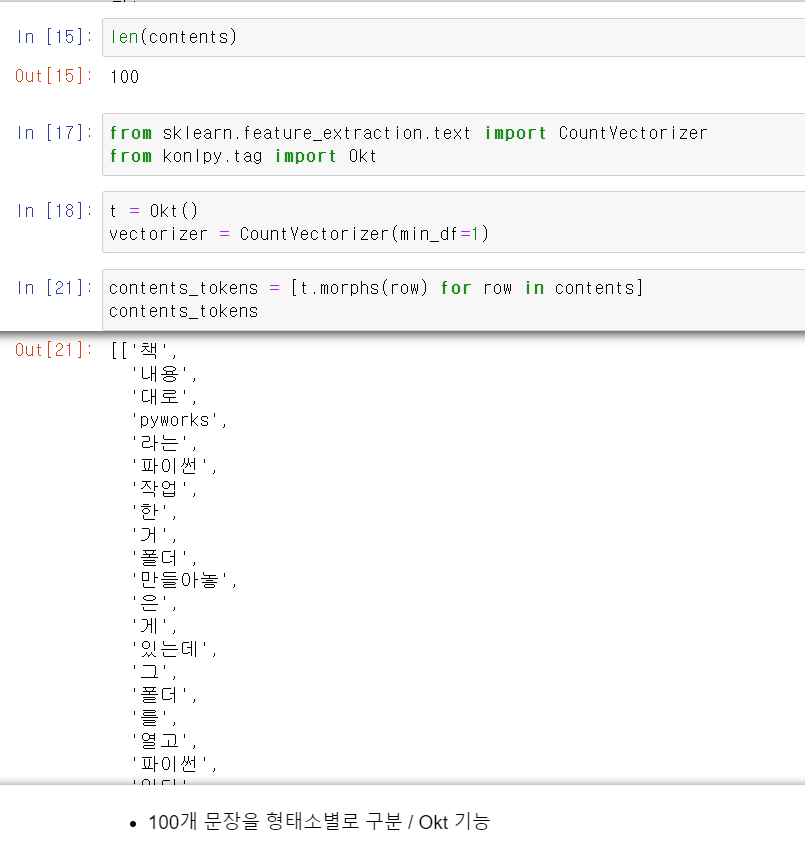
- 이제 100개 문장을 형태소별로 구분하고,
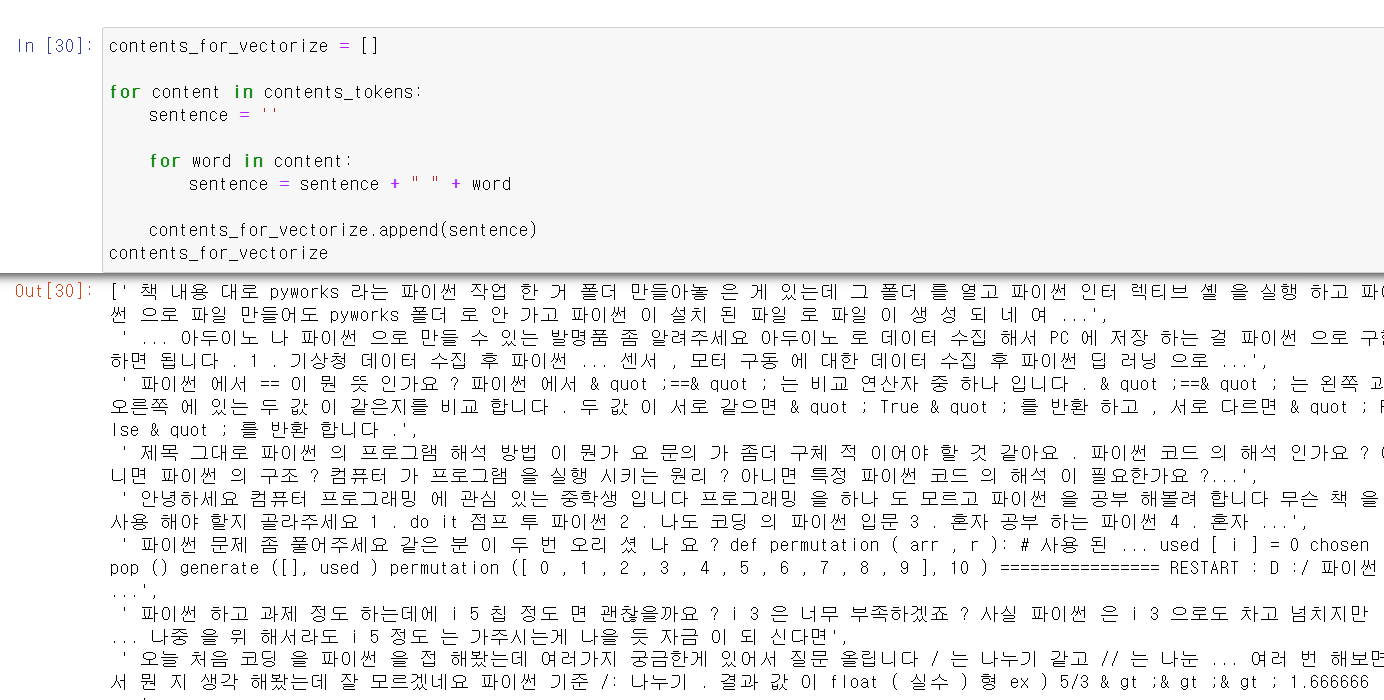
- 구분한 형태소 리스트를 문장하다 하나의 string인덱스로 리스트 형태에 담아서
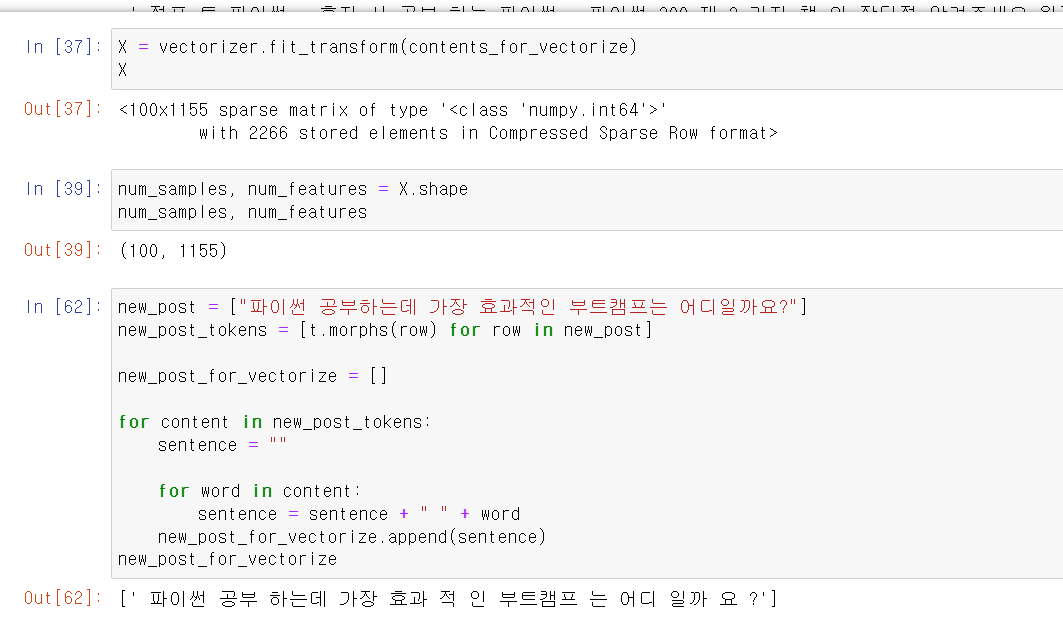
- 벡터화시켰다.
- 결과를 확인하니 100개의 문장이 1155개의 말뭉치로 이루어졌다.
- 이전 벨로그에서 어떤 형태로 저장되는지 간단히 적었는데, 100개 문장은...!
- 이제 테스트할 문장을 저장하고 형태소로 구분 후 다시 string형태로 저장했다.
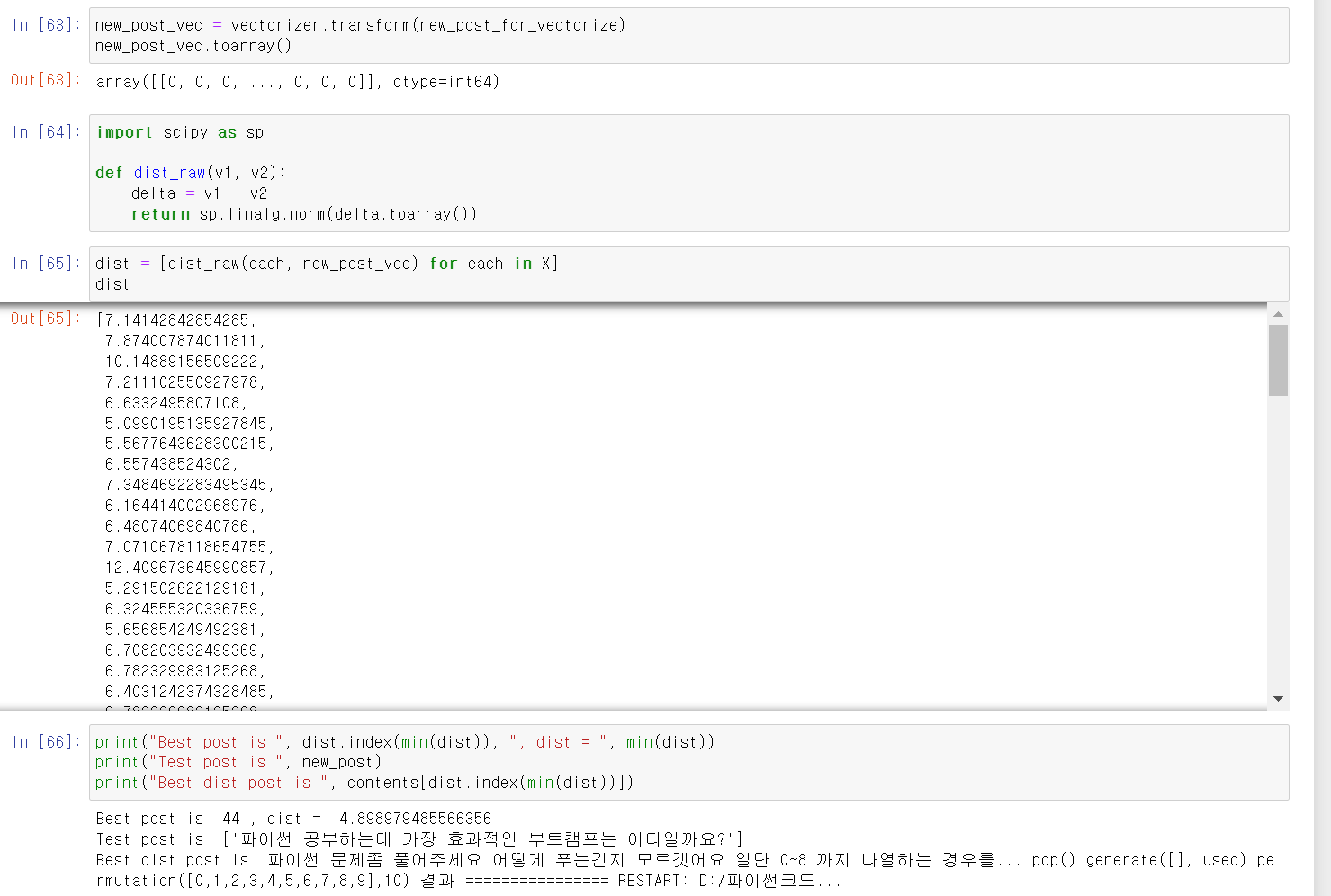
- 이제 해당 데이터를 벡터화 시키고, 100개 문장과 거리 차이를 계산하여 가장 적은 문장을 찾는다.
- 그 결과 44번째 문장이 제일 적은 거리 차이를 보이며 문장의 유사도가 높게 나왔다.

상황을 바꿀 수 없다면, 나를 바꾸자