
-
이번에는 서울 지하철의 유동인구에 대한 데이터를 전처리 및 분석하는 시간을 가졌다.
-
먼저 필요한 데이터를 프레임 형태로 불러왔다.
-
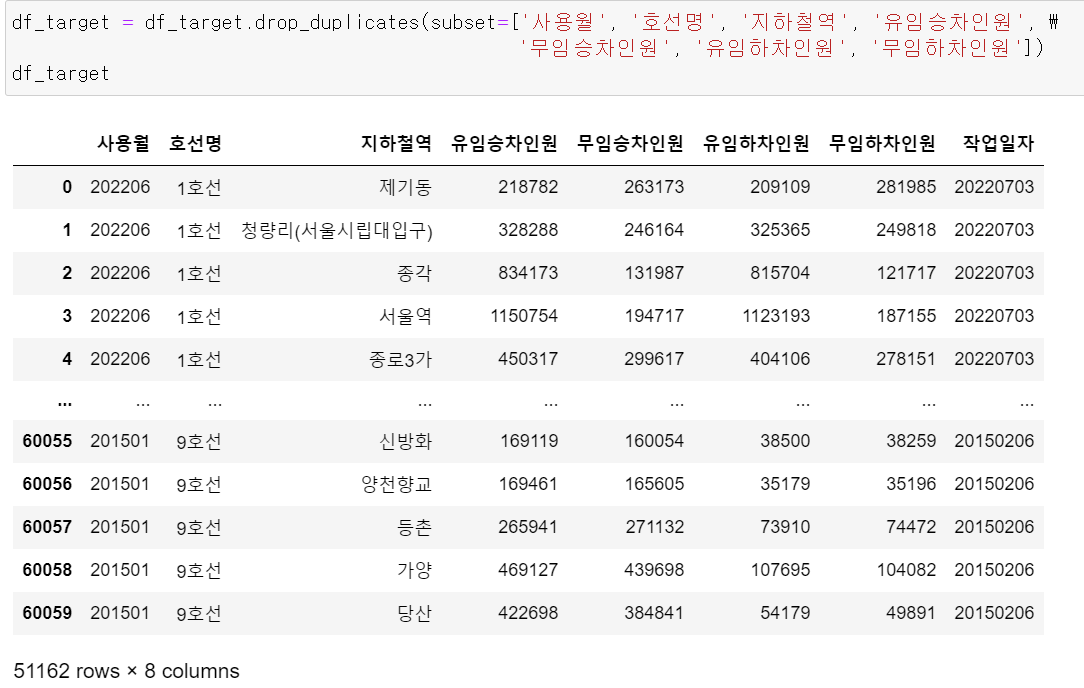
먼저 중복 데이터를 확인하기 위해 작업일자를 제외한 column들을 기준으로 중복값을 지웠다.
-
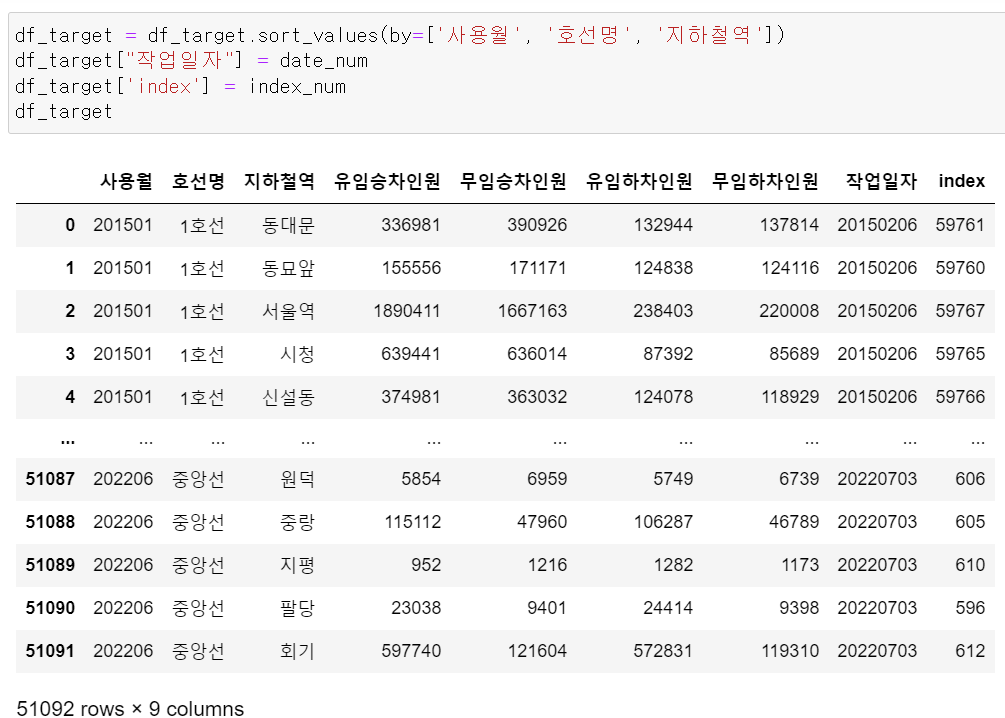
이후 사용월, 호선과 지하철역이 동일할 경우 하나로 합치는 작업을 했는데,
-
인덱스 번호와 작업일자는 유지하기 위해

-
사용월, 호선명, 지하철역을 기준으로 정렬을 하고, 중복되지 않은 첫번째 값의 index번호와 작업일자에 대한 변수를 저장했다.
-
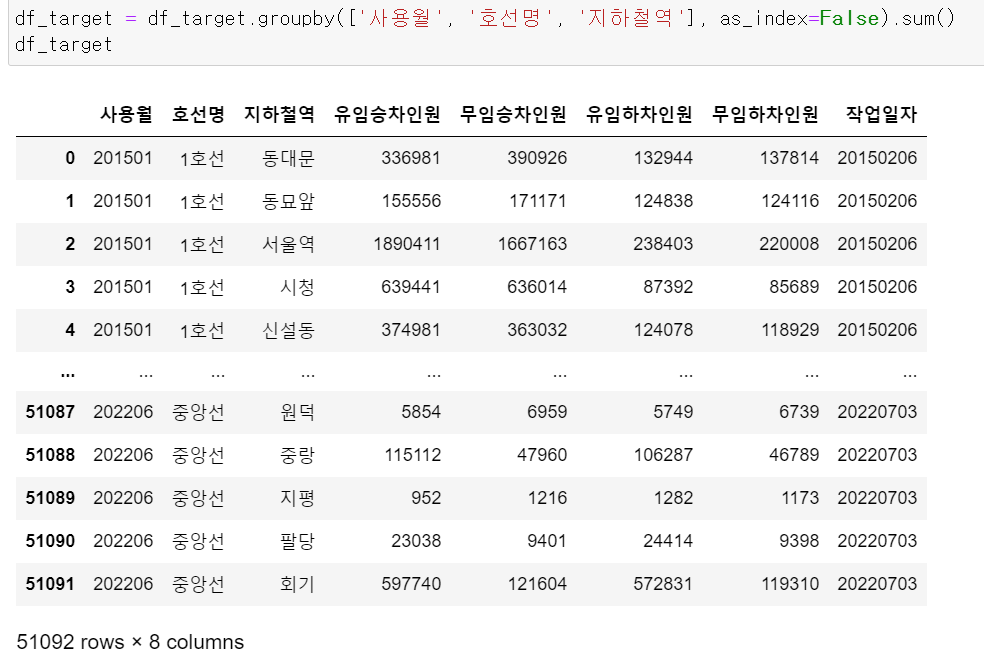
그리고 사용월, 호선명, 지하철역이 중복된 행들에 대해서 groupby로 승하차인원을 더해주고
-
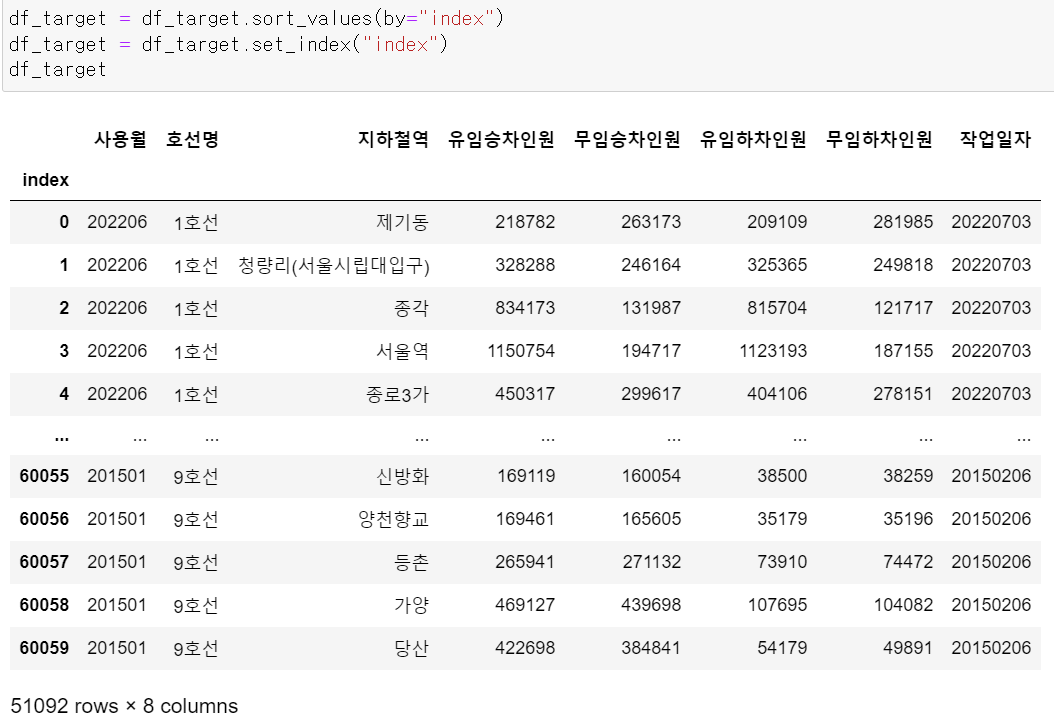
작업일자와 index번호를 새로운 컬럼으로 추가 및 수정해줬다.
-
그리고 추가한 index컬럼을 기준index로 바꿔주고, 인덱스로 정렬을 시켜줬다.

-
이번에는 호선명 및 지하철역의 데이터를 수정해줬다.
-
먼저 9호선 2~3단계 및 9호선 2단계는 9호선으로 바꿔주고, 괄호가 있는 경우 모든 괄호와 안에 문자를 삭제했고, 신천역은 잠실새내역으로 바꿔줬다.
-
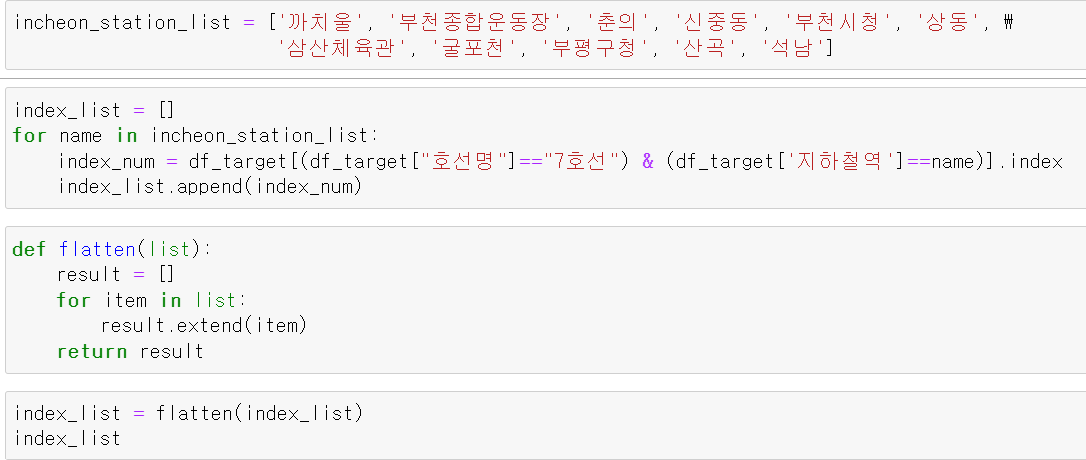
이번에는 인천 지하철에 속하는 지하철역은 데이터가 정확하지 않기 때문에 구분하기 위해 따로 인천 지하철에 속하는 지하철역의 index번호 변수를 저장했다.
-
list가 2차원 구조로 저장되어서 1차원 형태로 나열했다.
-
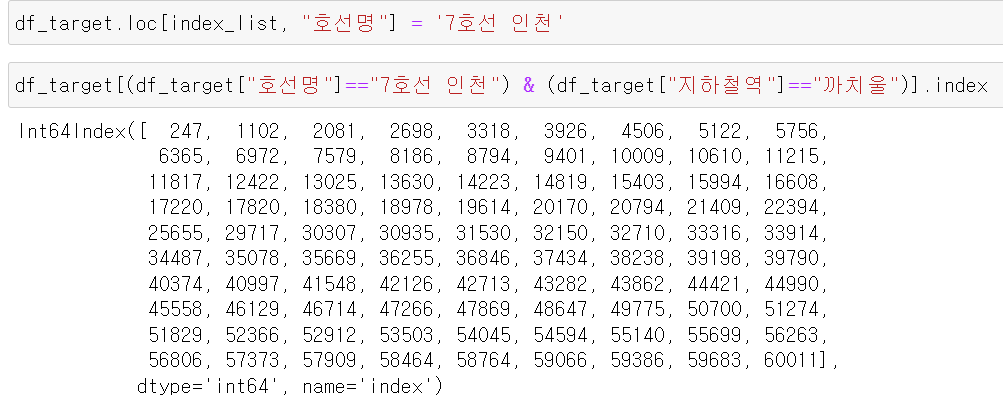
해당 인덱스 번호에 호선명은 7호선 인천으로 바꿔주고, 정상적으로 변경됐다.
-
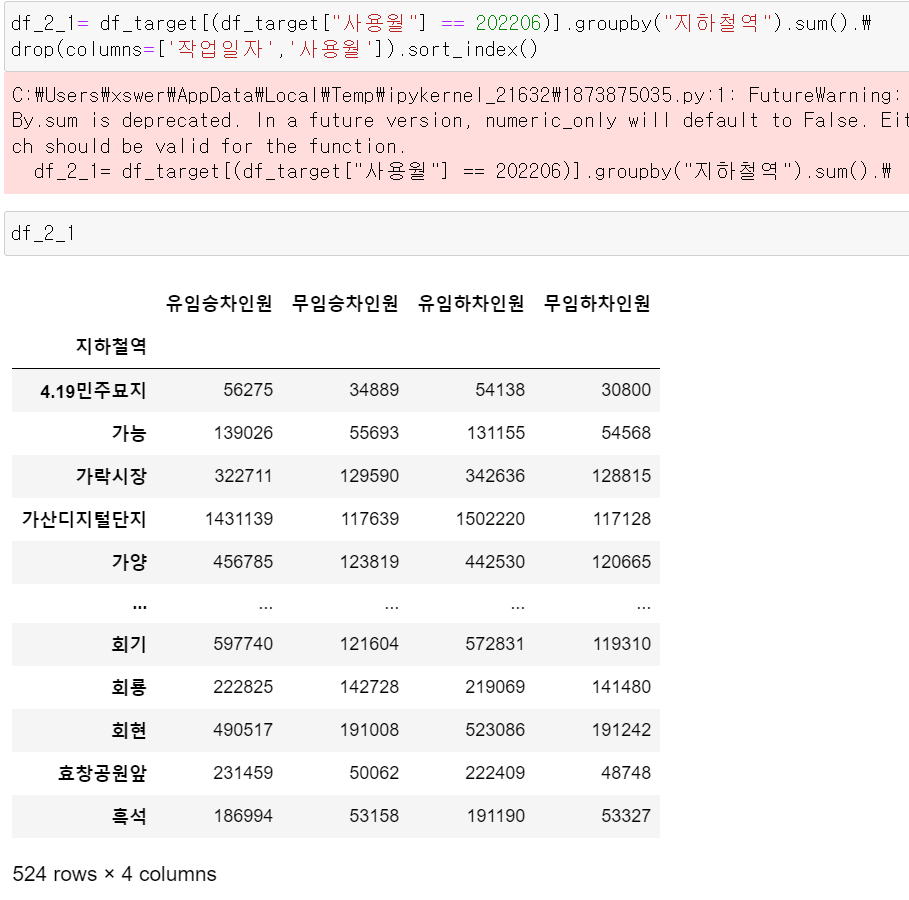
그리고 2022년 6월 기준 지하철역별 승하차인원을 groupby로 묶어줬다.
-
다음으로 각 지하철역별 묶인 호선명을 알아봤다.
-
먼저 고유 지하철역 이름을 변수에 저정하고, 해당 지하철역에 해당하는 호선명의 고유값을 리스트 형태로 저장했다.
-
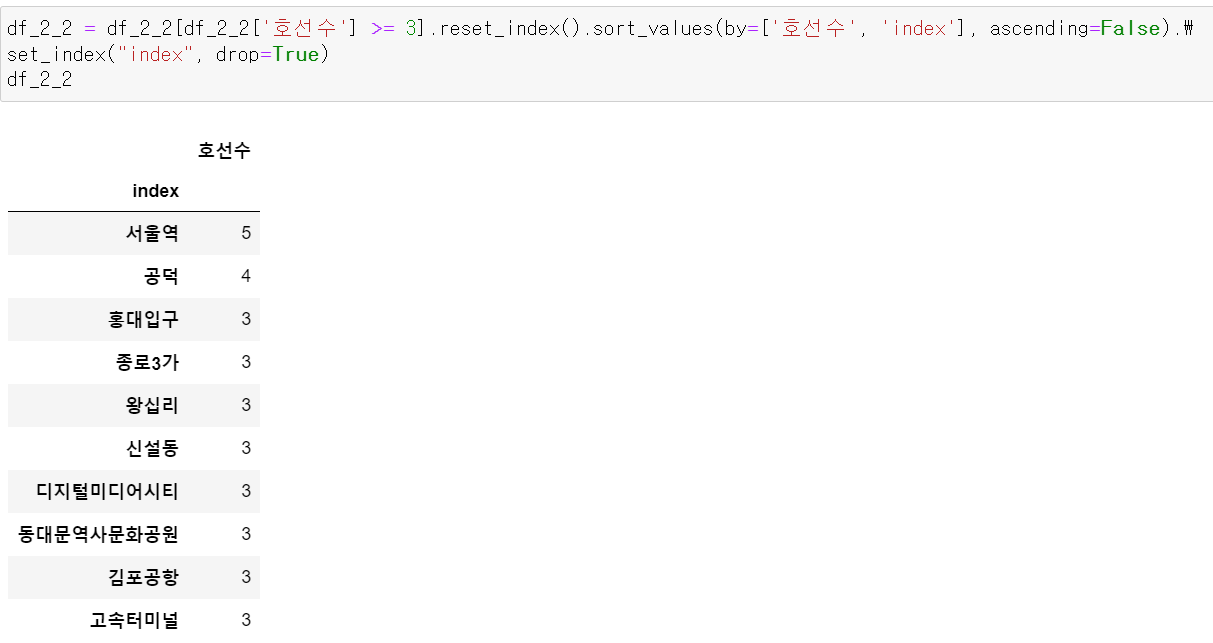
그리고 만든 리스트를 통해 역을 인덱스로 저장하고, 호선수를 column으로 데이터프레임을 만들고 3개 이상의 역들만 출력했다.
-
이번에는 지하철역별 어떤 호선이 있는지 확인하기 위해 3개의 빈 리스트를 만들고
-
for반복문을 통해 각 역의 이름, 호선수, 호선명을 저장했다.
-
호선명은 join을 통해 ", "(콤마와 띄어쓰기)를 기준으로 저장했다.

-
3개의 리스트로 호선수가 3개 이상인 데이터를 프레임으로 만들어줬다.
-
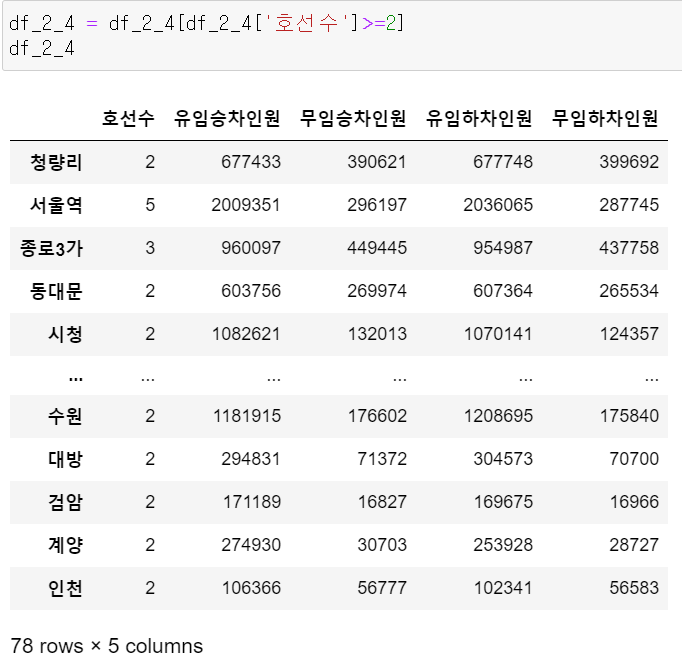
이번에는 지하철역별 승하차인원의 합을 구하기 위해 4개의 빈 리스트를 만들고, for반복문을 통해 2022년 6월에 해당하는 지하철역별 승하차인원을 구했다.
-
그리고 호선수가 2개 이상인 지하철역의 승하차원 인원의 합을 구한 데이터프레임을 만들었다
-
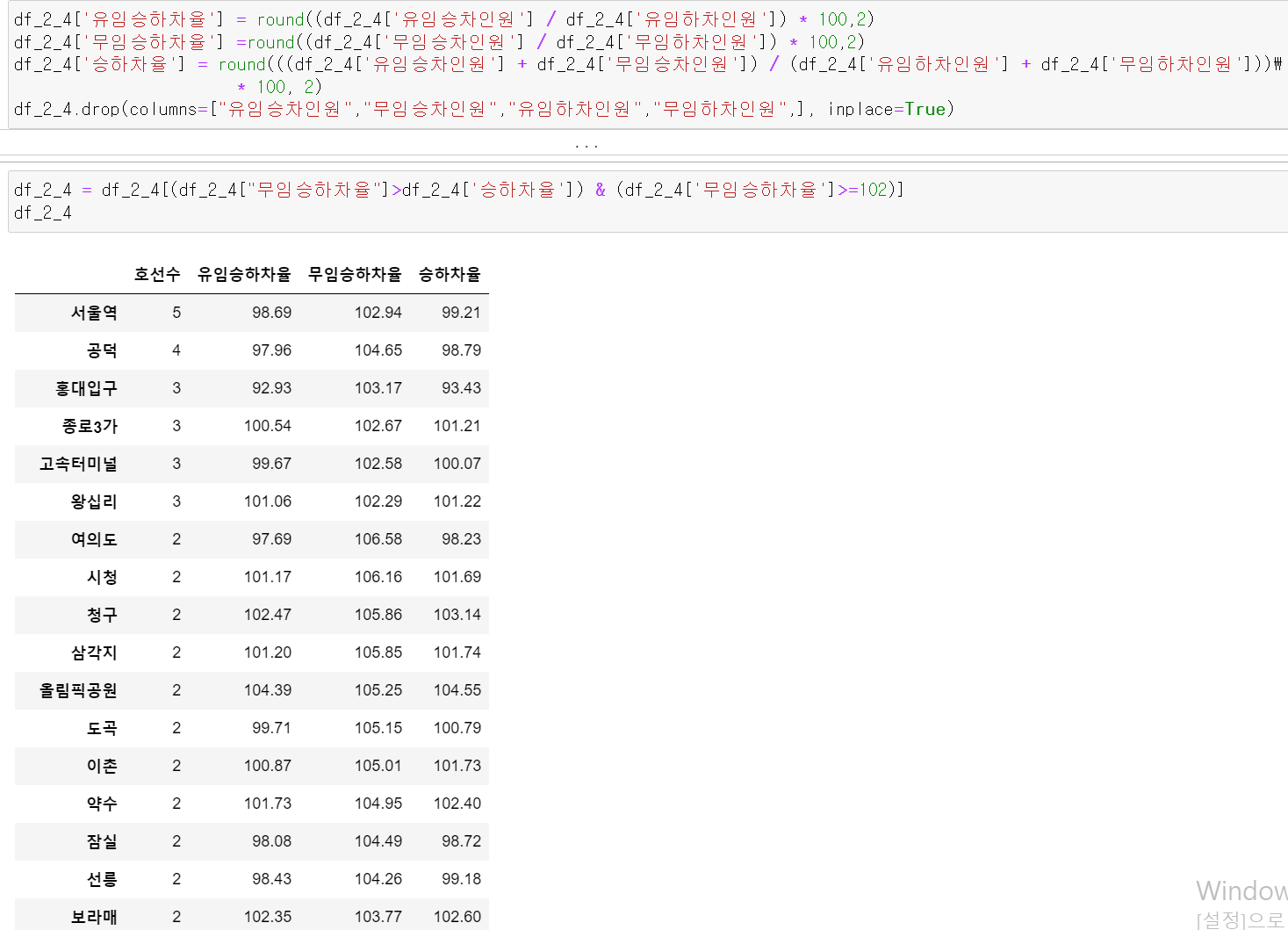
구한 프레임을 바탕으로
2.
-
3개의 값을 구하고, 승하차율보다 무임승하차비율이 높으며 무임승하차율이 102이상인 값들의 프레임을 구했다.
-
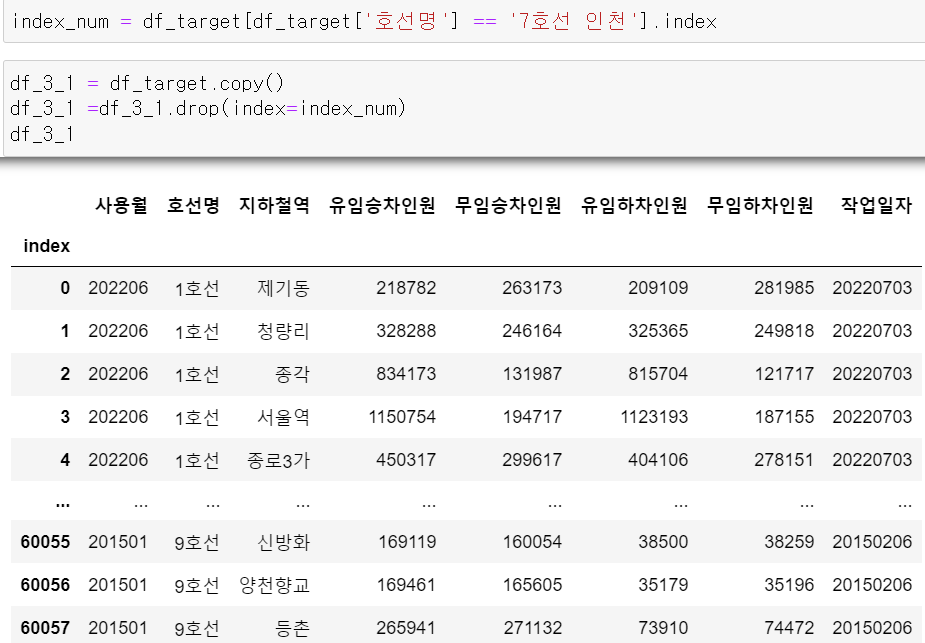
다음 작업을 하기 전에 7호선 인천지하철역의 경우 데이터가 정확하지 않기에 제거한 새로윤 프레임을 만들고
-
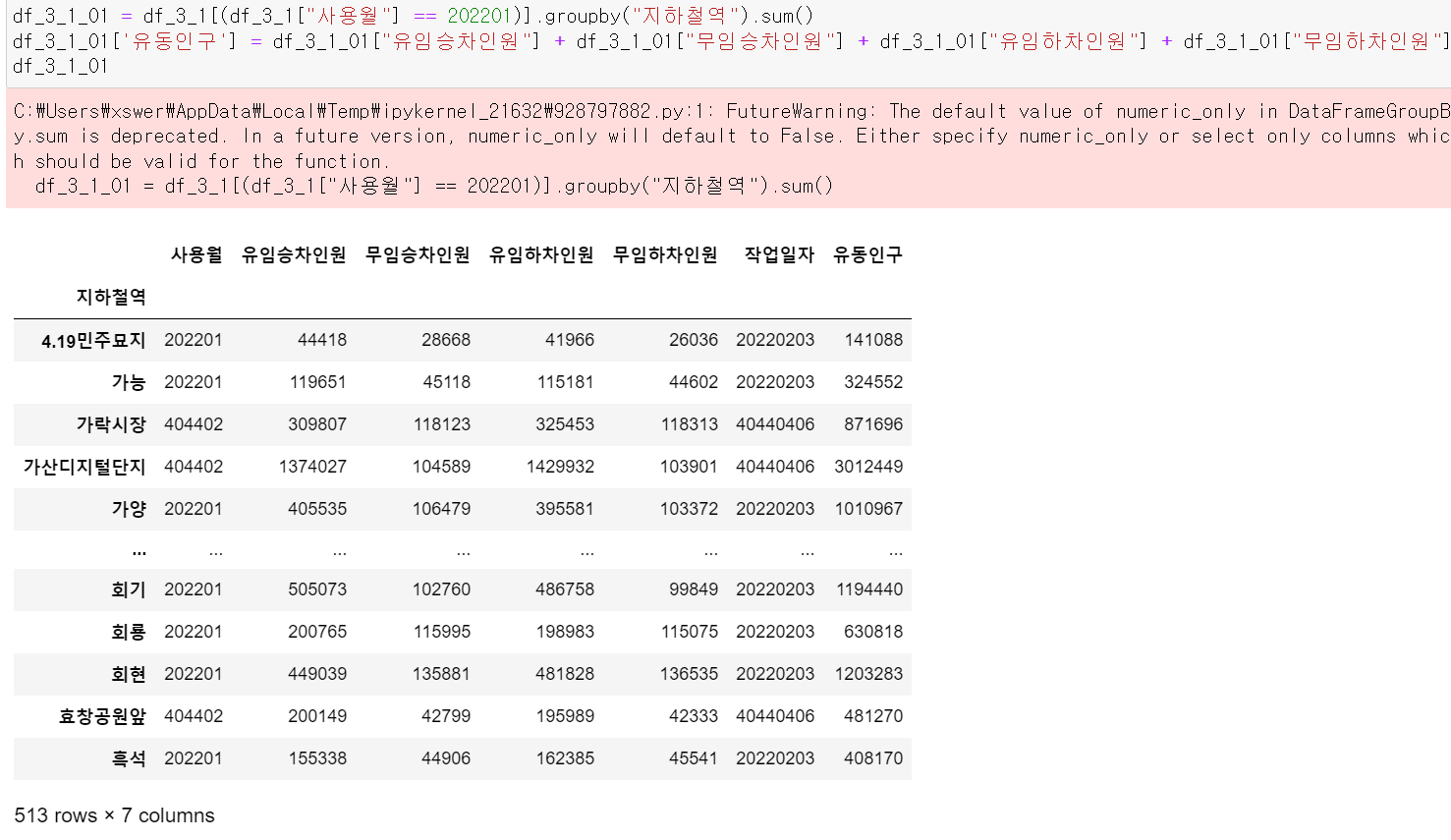
이번에는 2022년 1월 대비 2022년 6월의 유동인구증감률을 구하기 위해 2022년 1월의 지하철역별 유동인구 프레임을 만들고
-
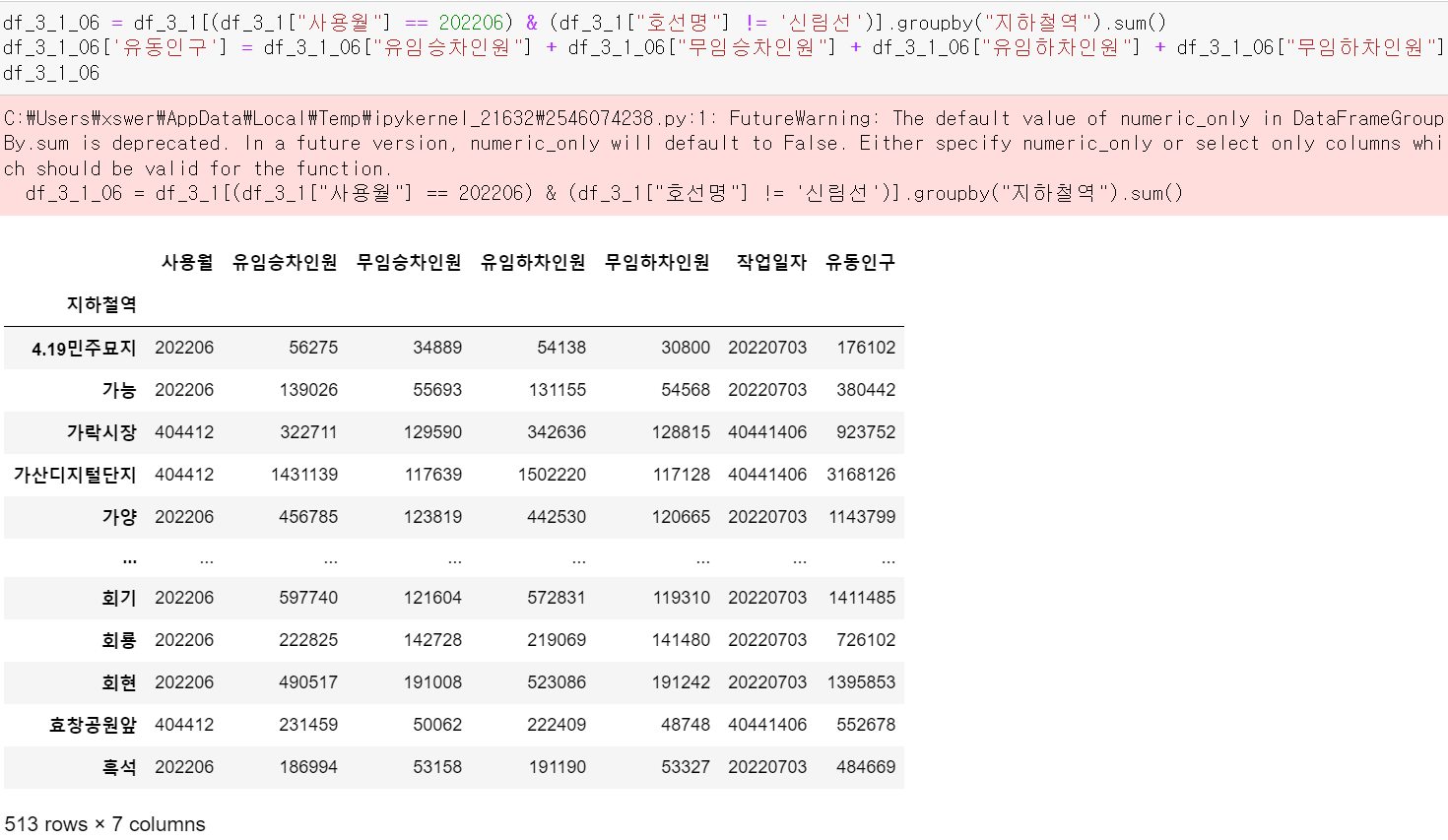
2022년 6월 기준 신림선을 제외한 지하철역별 유동인구 데이터프레임을 만들었다.
-
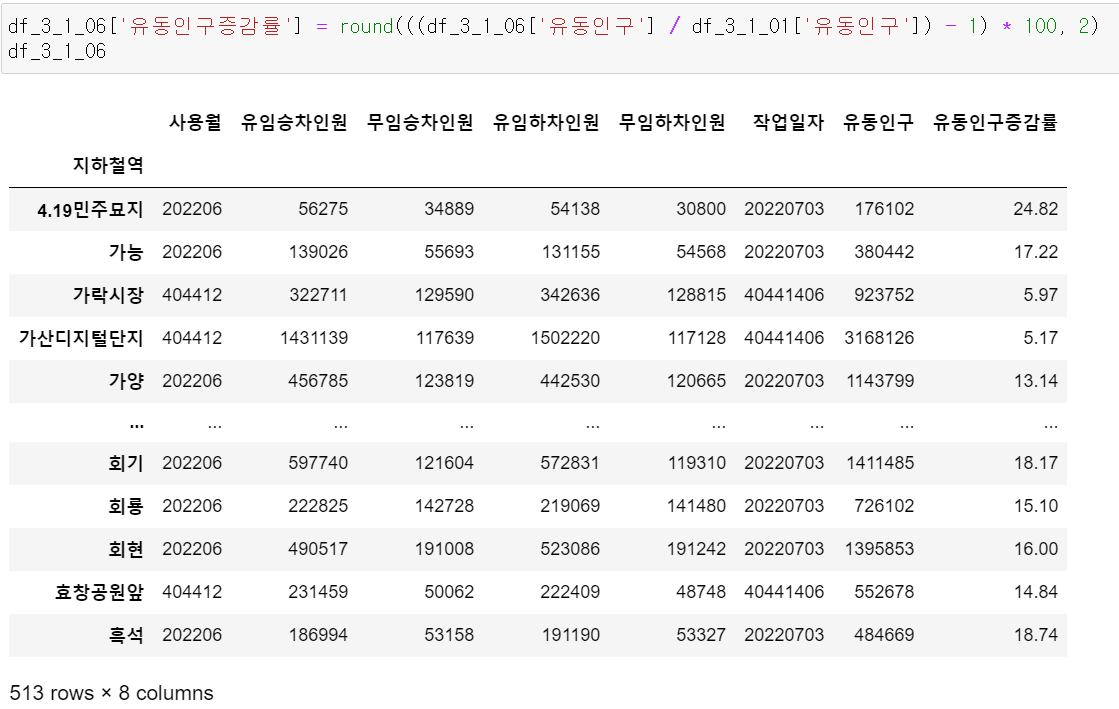
이제 지하철역별 유동인구증감률을
-
해당 공식을 통해 구했다.
-
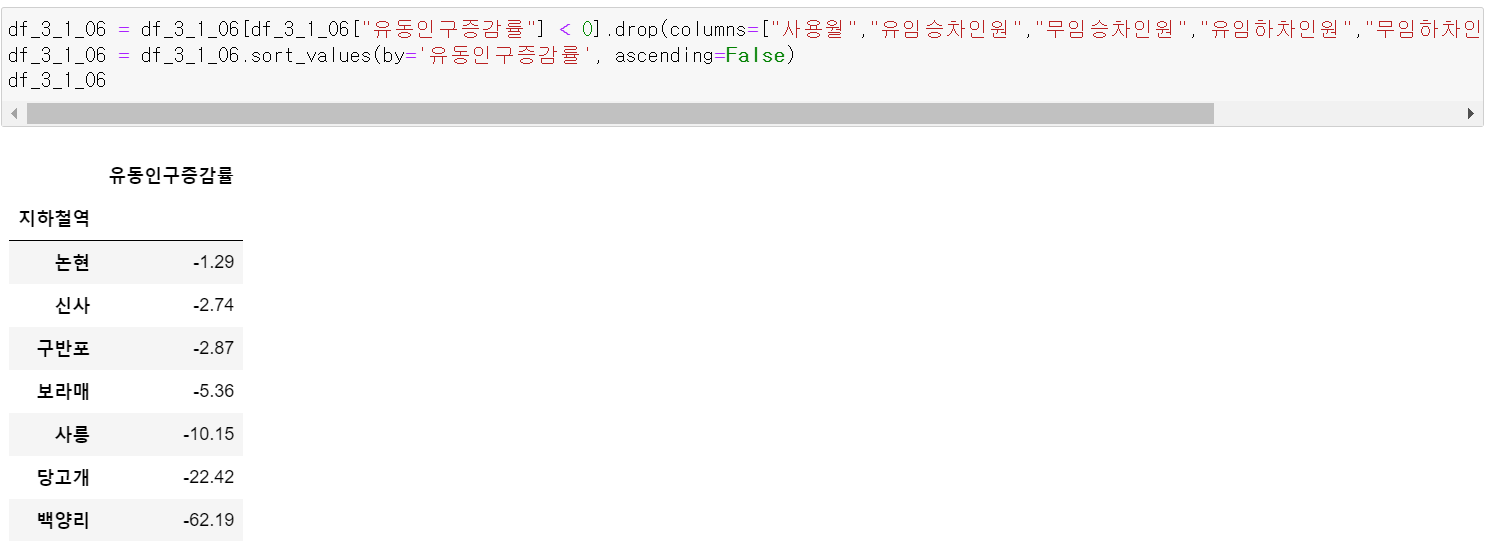
그리고 필요없는 컬럼을 제거하고, 유동인구가 감소한 지하철역에 대한 데이터프레임을 만들었다.
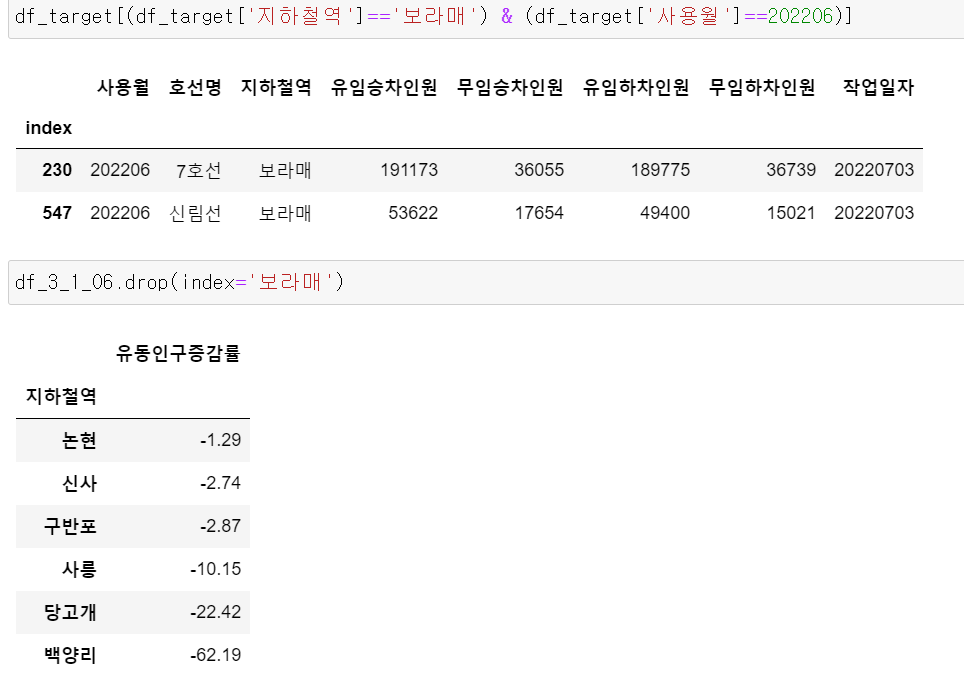
-
하지만, 보라매역의 경우 신림선이 포함되어 있기 때문에 보라매역을 제외한 6개의 지하철역이 유동인구가 감소했다.
-
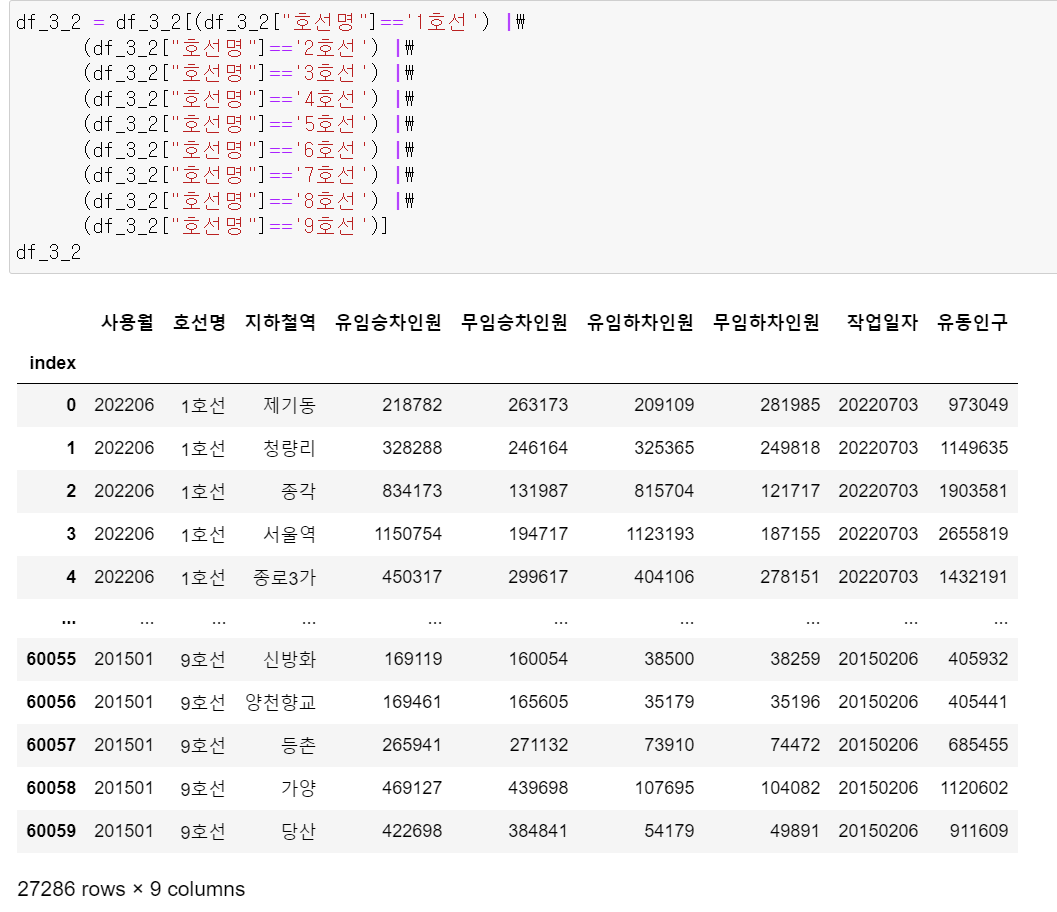
이번에는 1~9호선 중 2015년 1월 이후 신설된 역에 대한 데이터프레임을 만들었다.
-
먼저 호선이 1~9호선에 해당하는 데이터프레임만 만들고
-
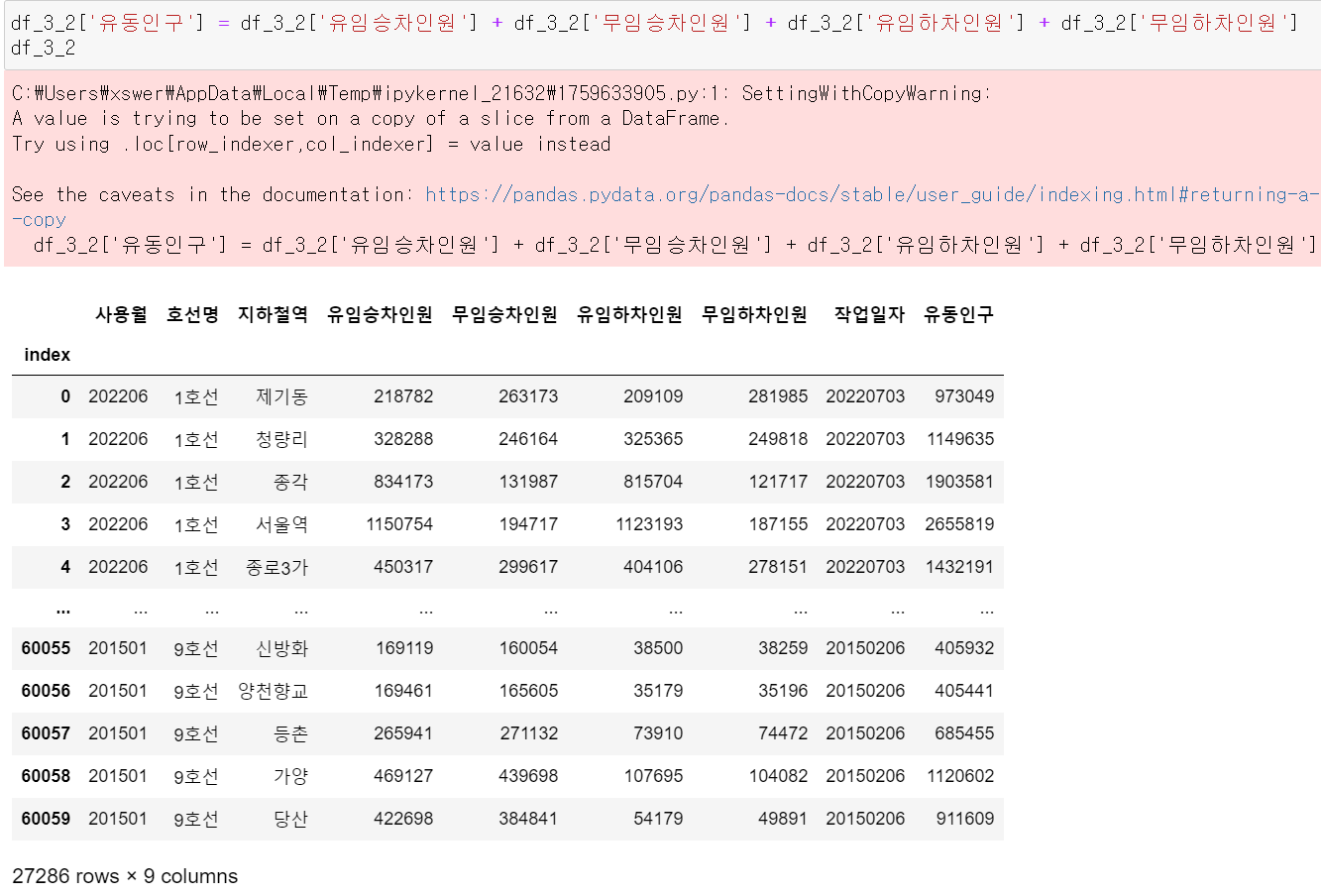
승하차인원을 합쳐 유동인구 컬럼을 만들었다.
-
만약 2015년 1월 유동인구 데이터가 없다가 2018년 5월에 생겼다면 2018년 5월에 역이 신설됐다고 판단했다.
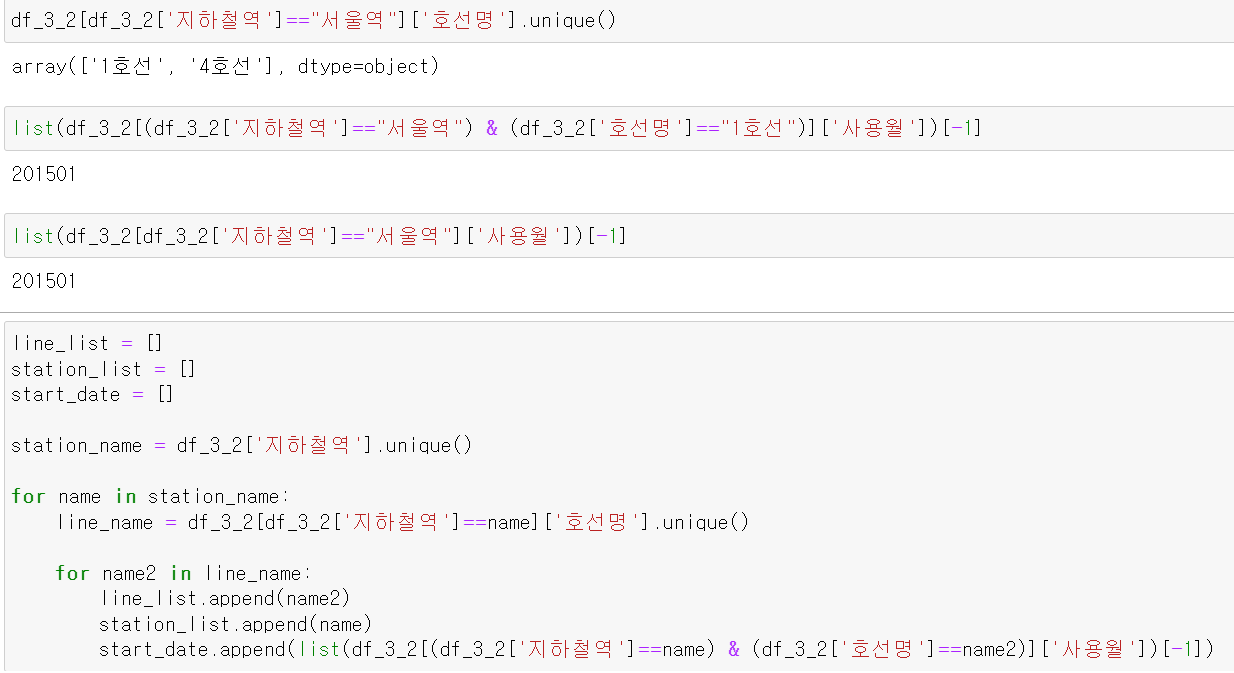
-
이제 각 지하철역의 호선, 지하철역명, 사용월의 제일 빠른 날짜를 3개의 데이터로 저장하고

-
3개의 리스트로 하나의 데이터프레임을 만들었다.

-
총 20개의 신설역 프레임이 만들어졌는데

-
3개의 지하철역 종합운동자, 올림픽공원, 석촌의 경우 다른 호선에서 이미 존재했기 때문에 3개의 역을 삭제했다.
-
해당 역을 삭제하고 17개의 신설월 데이터프레임을 만들었다.
-
서울 지하철 승하차인원을 바탕으로 데이터 전처리 및 분석하는 시간을 가져봤다.
