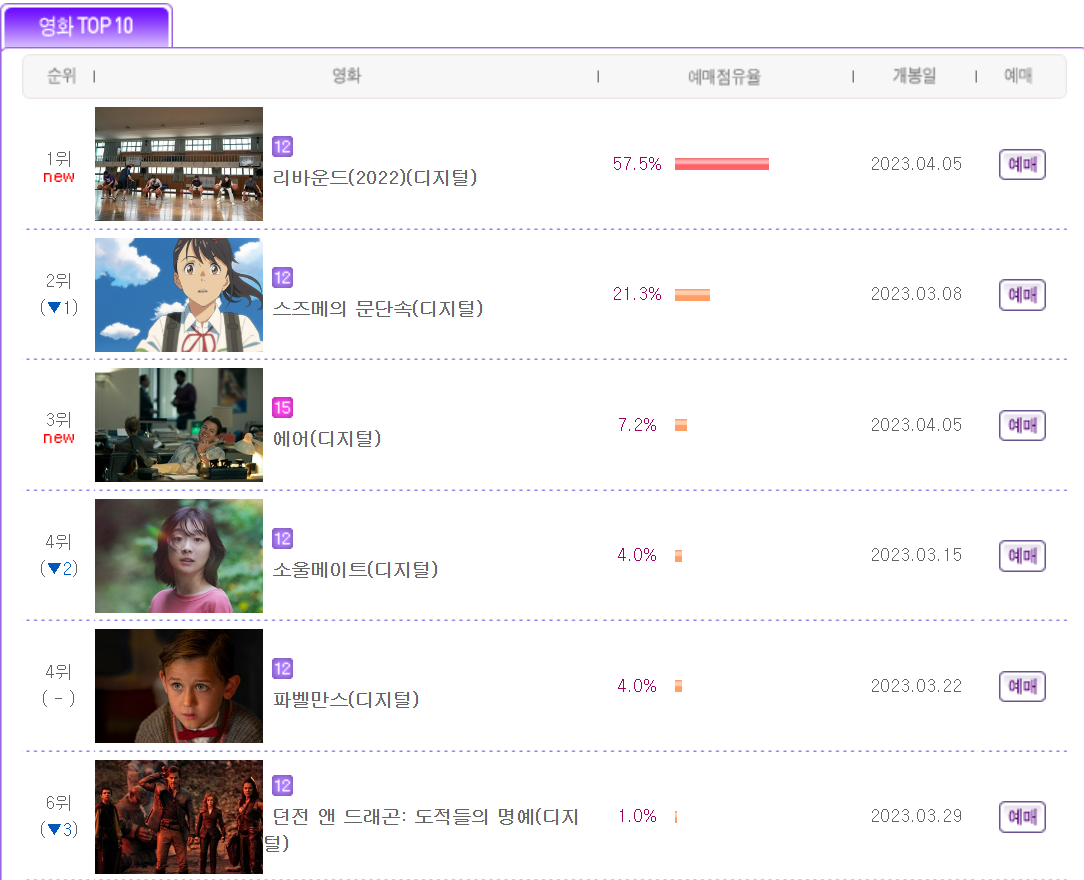
- 이번에는 인터파크의 영화 예매 순위(1~10위)를 Web_crolling을 통해 Data를 가공해보자
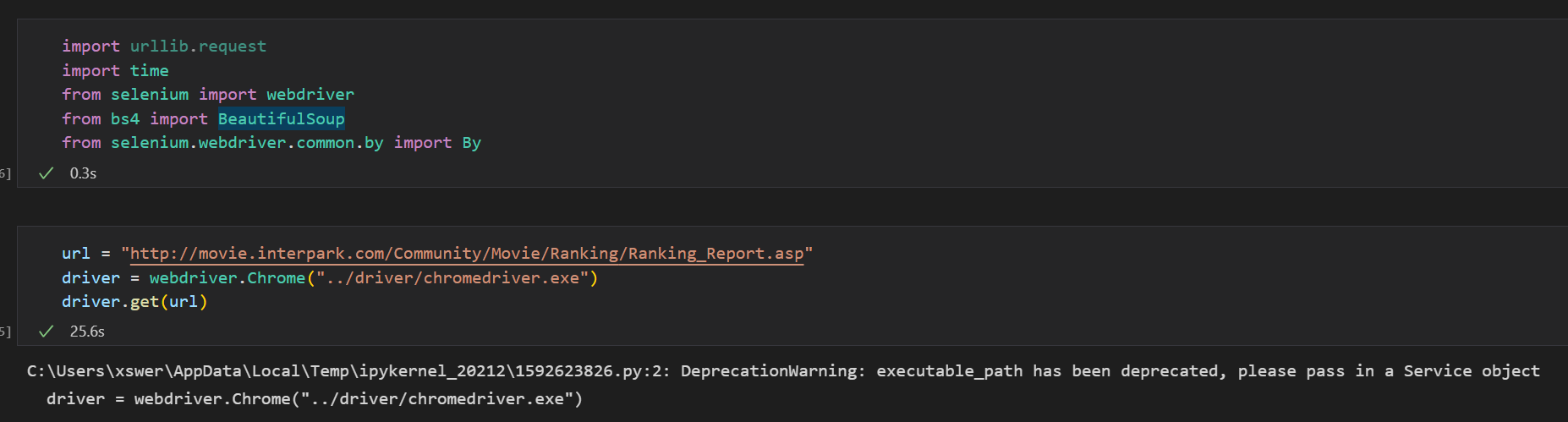
- 가장 먼저 크롤링을 하기 위해서 모듈과 해상 사이트의 url를 가지고 왔다.

- 그리고 특정 주간(목~일)의 데이터를 뽑기 위해 webdriver의 send_key를 통해 날짜를 입력하고, 해당 사이트의 페이지를 BeaufitulSoup으로 가져왔다.
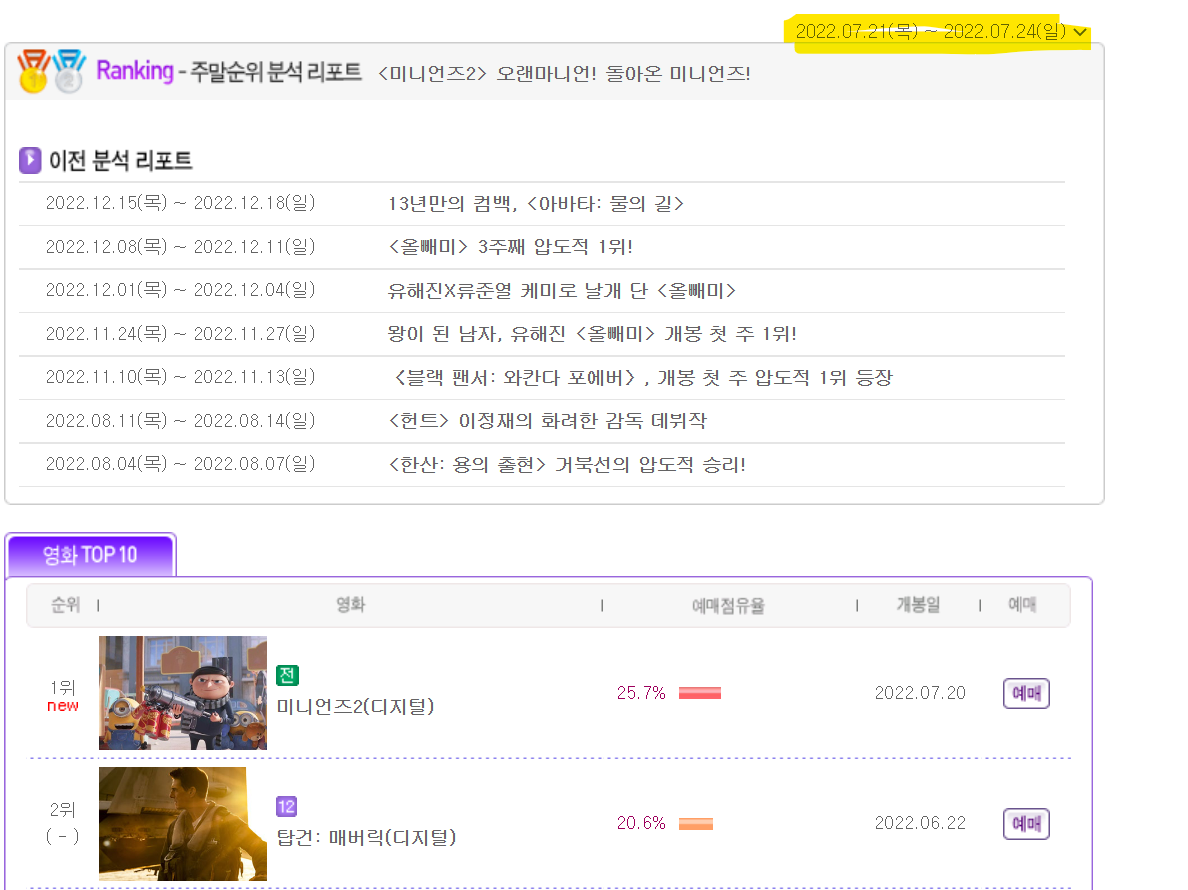
- 저기 노랗게 색칠한 부분에 날짜를 변경했다.
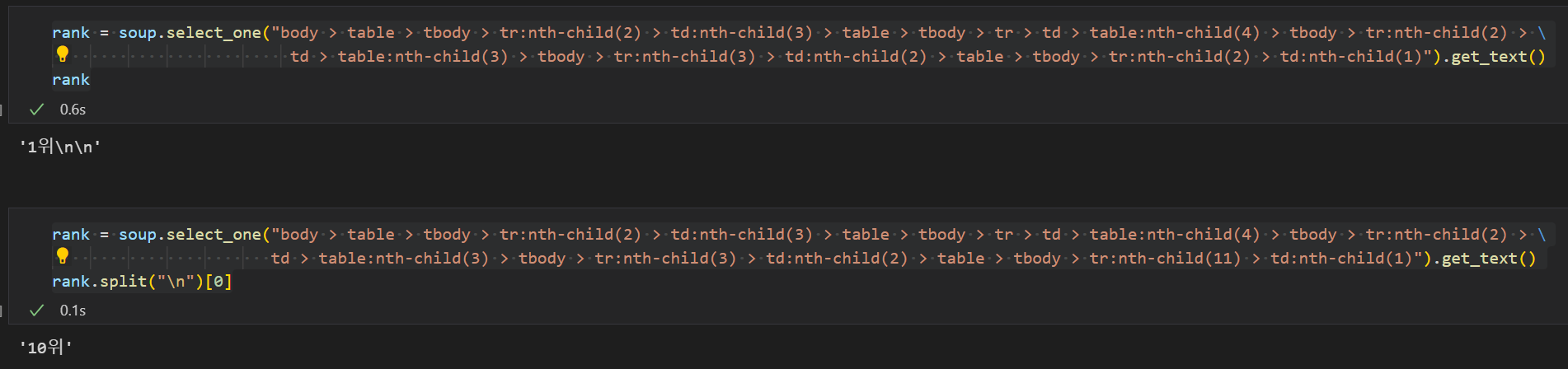
- 그리고 이제 필요한 데이터를 하나씩 뽑는데, 가장 먼저 순위를 뽑았다.
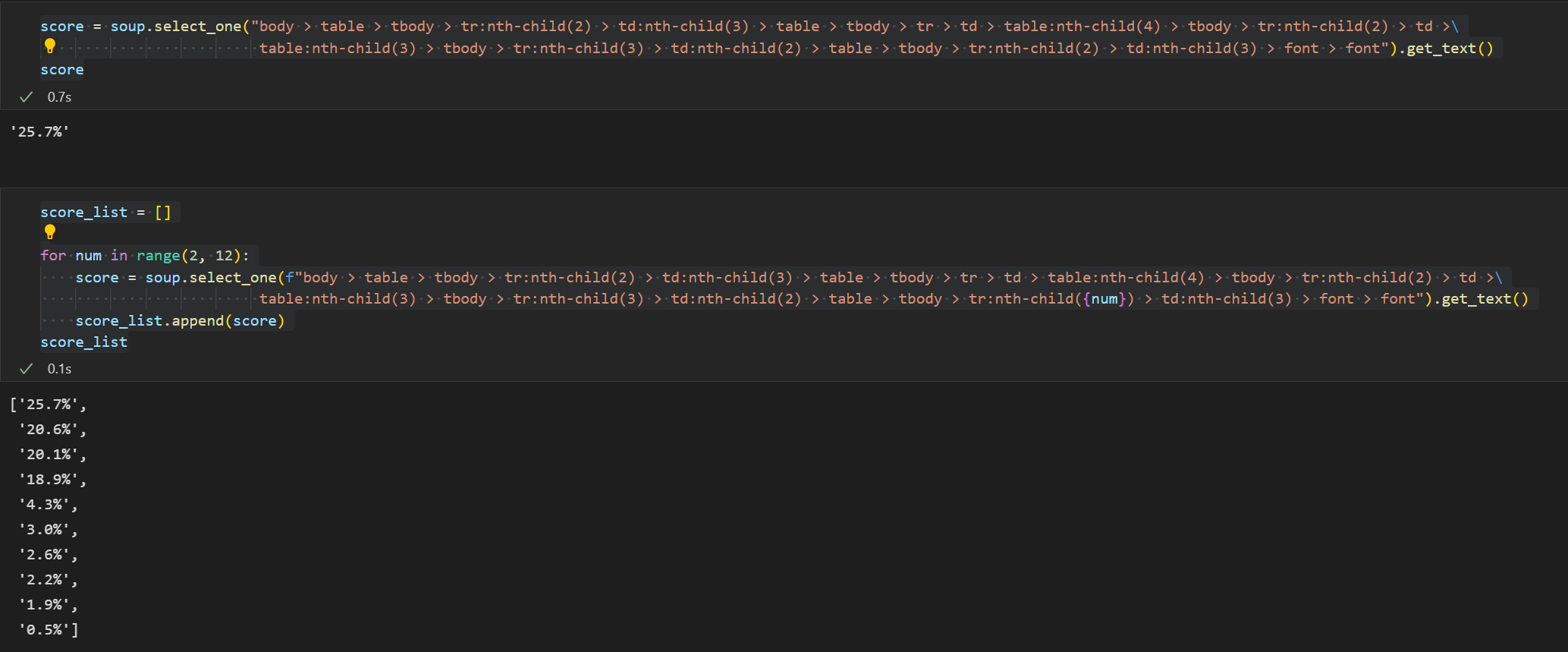
- 총 10개의 데이터를 뽑아야하는데 특정 html의 숫자를 2~12까지 넣음으로써 총 10개의 데이터가 뽑히는 것을 확인했다.

- 이제 for 반복문을 통해 데이터를 뽑고, split기능으로 필요없는 html 문자열을 날린 후 리스트로 저장했다.
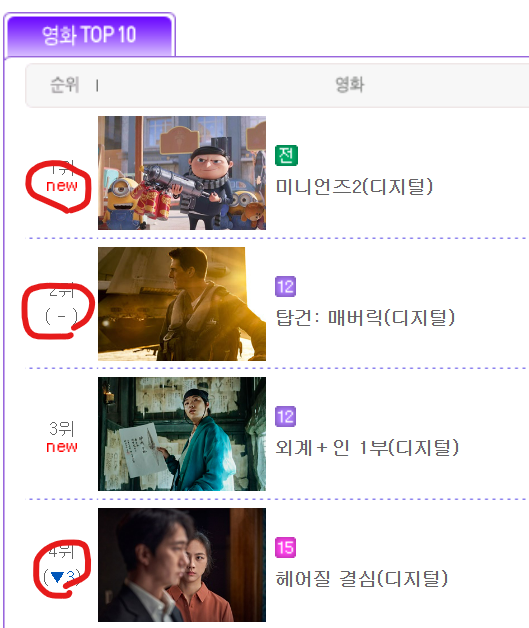
- 이번에는 저기 순위 밑에 예메증감 항목을 가져와보자
- 문제는 New문자의 경우 img 파일이라 text를 가져올 수 없고, '-'표시는 아예 html 데이터가 없으며, 순위변동 표시는 span 항목에 들어가있어서 각자 다른 html주소로 가져와야했고, html 주소가 다른 경우 에러가 발생했다.

- 그래서 에러 발생을 이용해서 첫번 째 Try문에는 img를 넣었을 때 에러가 발생하지 않으면 new 글자를 넣고, 에러가 발생하면 다시 두번 째 Try문을 사용했다.
- 두번 째 Try문에서 html의 마지막에 span를 넣어서 증감 표시를 나타내고, 만약 다시 에러가 뜨면 마지막으로 "-"를 넣어서 3개의 증감표시를 넣었다.
- 다음으로는 위와 같이 for반복문을 사용해서 title 항목을 넣었다.
- 그리고 개봉일자와 함께
- 예매율 컬럼에 넣을 예매율도 리스트로 만들었다.
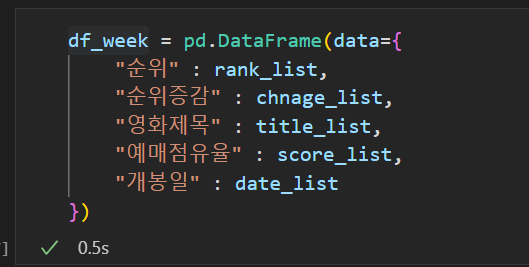
- 데이터를 뽑은 5개의 데이터를 DataFrame형태로 만들어서
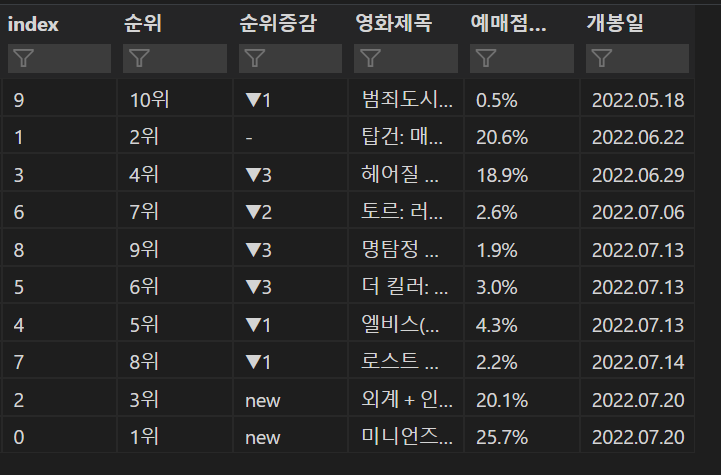
- 1~10위까지의 데이터 프레임을 만들었다.
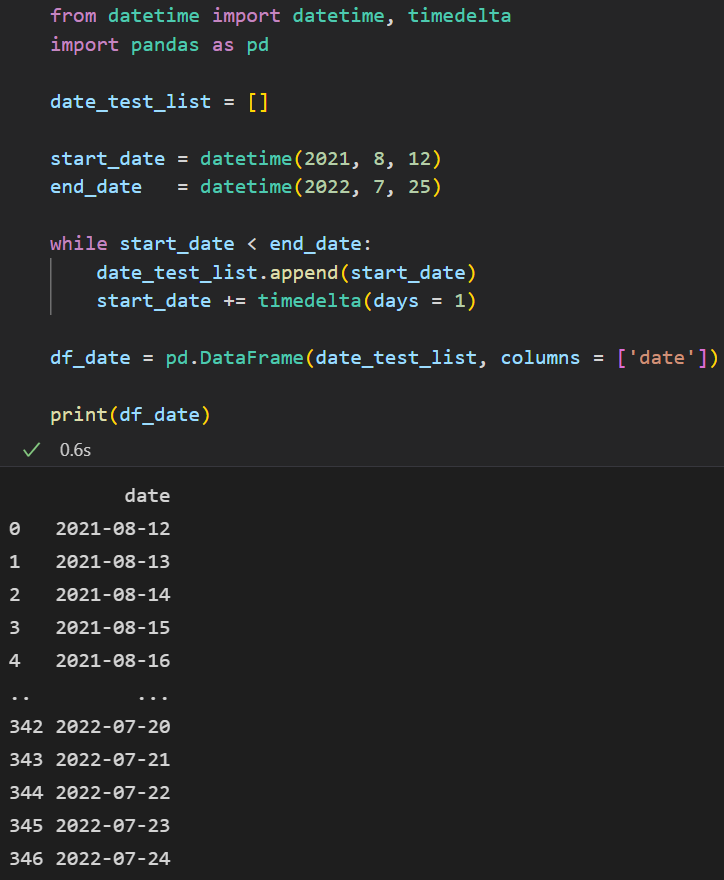
- 그리고 50주의 데이터를 뽑기 위해서 먼저 send_key에 넣을 날짜 데이터를 만들었다.
- 먼저 timedelta 모듈을 사용해서 시작 날짜 2021-8-12부터 하루씩 더해서 end_date 2022-7-25까지 하루씩 날짜를 뽑았다.
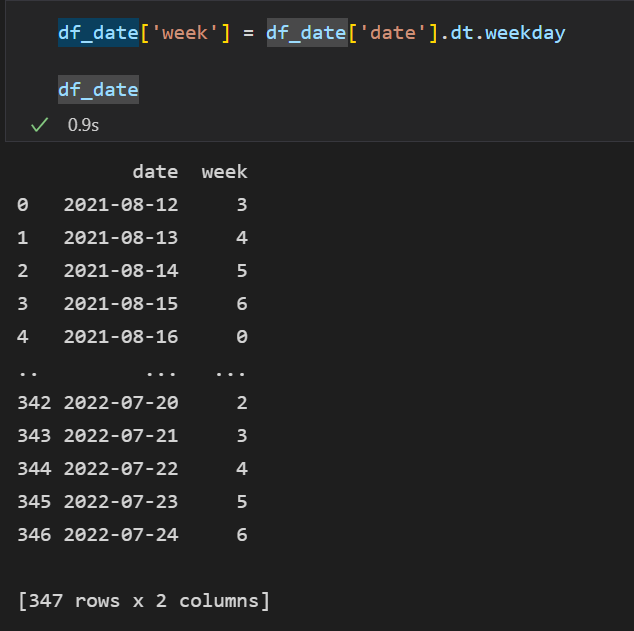
- 그리고 뽑은 데이터에서 해당 날짜의 요일을 int형태로 새로운 컬럼을 만들었다.
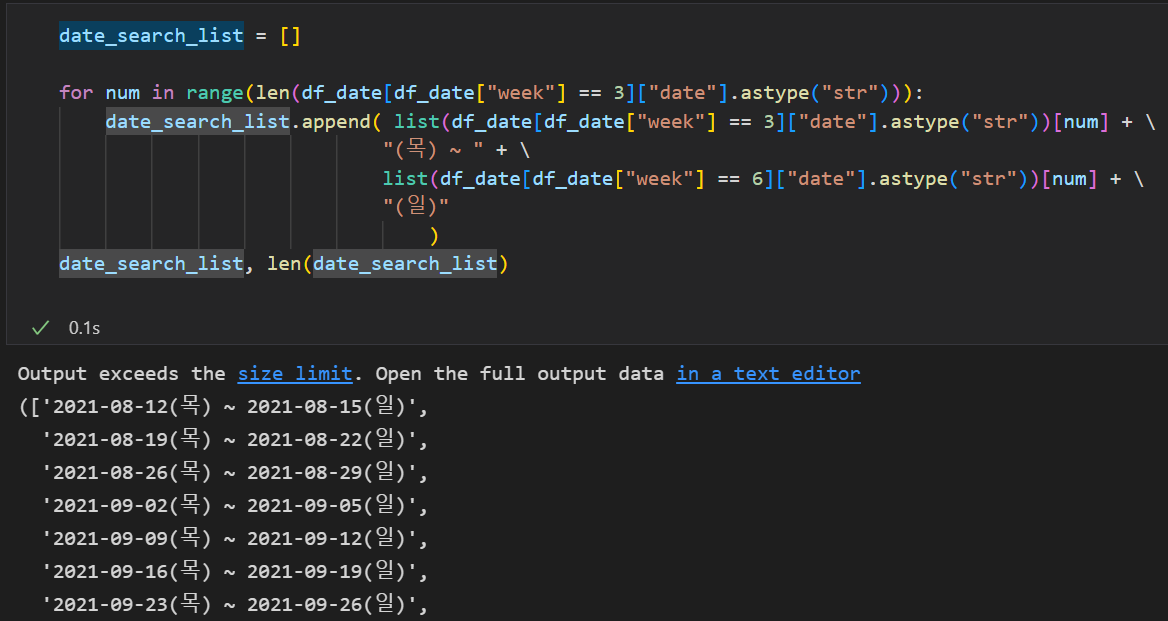
- 그리고 위 날짜 데이터프레임에서 목요일(3)과 일요일(6)에 해당하는 데이터를 for반복문을 통해서 send_key 보낼 리스트를 만들었다.
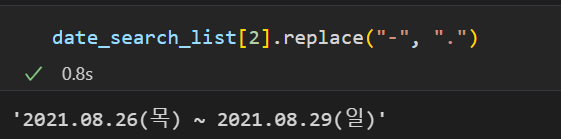
- 리스트를 뽑은 후 확인해보니 send_key에 보내는 형태는 -이 아니라 '.' 형태라 replace를 사용했다.

- 이제 send_key에 보낼 리스트를 뽑고, 위와 같이 작업을 매주 데이터에 적용해서 리스틀 뽑았다.
rank_list = []
chnage_list = []
title_list = []
score_list = []
date_list = []
for date in date_search_list:
date = date.replace("-", ".")
time.sleep(0.5)
driver.find_element(By.XPATH,'/html/body/table/tbody/tr[2]/td[3]/table/tbody/tr/td/table[3]/tbody/tr[2]/td/table[1]/tbody/tr[3]/td/form/select').send_keys(date)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
try:
for num in range(2, 12):
rank = soup.select_one(f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > \
td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({num}) > td:nth-child(1)").get_text()
rank = rank.split("\n")[0]
rank_list.append(rank)
for num in range(2, 12):
try:
change = soup.select_one(f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > \
table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({num}) > td:nth-child(1) > img").get_text()
chnage_list.append("new")
except:
try:
change = soup.select_one(f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > \
td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({num}) > td:nth-child(1) > span").get_text()
chnage_list.append(change)
except:
chnage_list.append("-")
for num in range(2, 12):
title = soup.select_one(f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > \
tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({num}) > td:nth-child(2) > table > tbody > tr > td:nth-child(2) > a > b").get_text()
title_list.append(title)
for num in range(2, 12):
score = soup.select_one(f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td >\
table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({num}) > td:nth-child(3) > font > font").get_text()
score_list.append(score)
for num in range(2, 12):
date_day = soup.select_one(f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > \
table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({num}) > td:nth-child(5)").get_text()
date_list.append(date_day.replace(".", ""))
except:
print(date)- 혹시나 에러가 발생할 경우 디버그를 하기 위해서 에러 발생한 날짜 리스트를 출력하게 만들었고, 아무 일도 없었다.
- 그리고 매주 날짜 리스트에서 검색 시작 날짜를 뽑기 위해서 10개씩 뽑아서 append했다.
- 자료의 리스트를 뽑아보니 500개씩 정상적으로 출력됐고, 해당 리스트 목록을 하나의 프레임 형태로 만들었다.
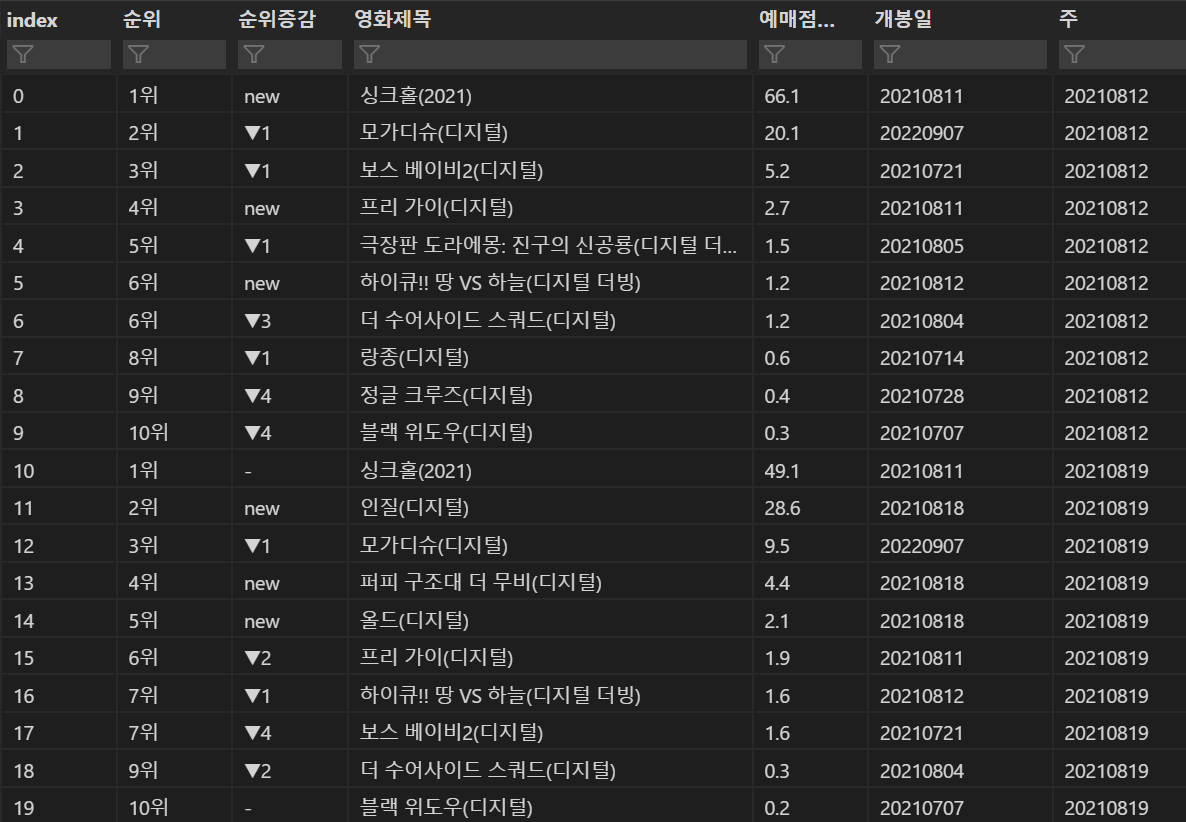
- 프레임을 확인해보니 정상적으로 출력된 것을 확인할 수 있다.

- 그리고 주간마다 Top10에 랭킹된 영화의 카운트를 세고, 6주 이상 집계된 데이터만 뽑기위해 groupby를 사용했다.
- 일단 groupby로 카운터를 세고, 순위를 빈도로 이름을 바꾼 후 정렬을 위해 index의 영화제목을 컬럼으로 새로 추가했다.
- 그리고 빈도가 6이상 데이터만 뽑은 뒤 빈도와 영화제목으로 정렬 후 영화제목 컬럼을 drop했다.
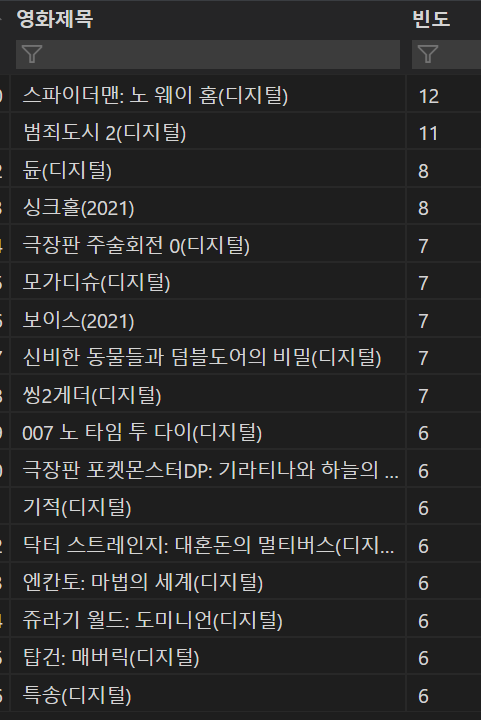
- 스파이더맨이 가장 오래 버텼고, 그 밑으로 범죄도시 등의 영화가 집계됐다.
- 이거 보고 심심할 때 영화를 다시 봐도 괜찮을 것 같기도 하고...?
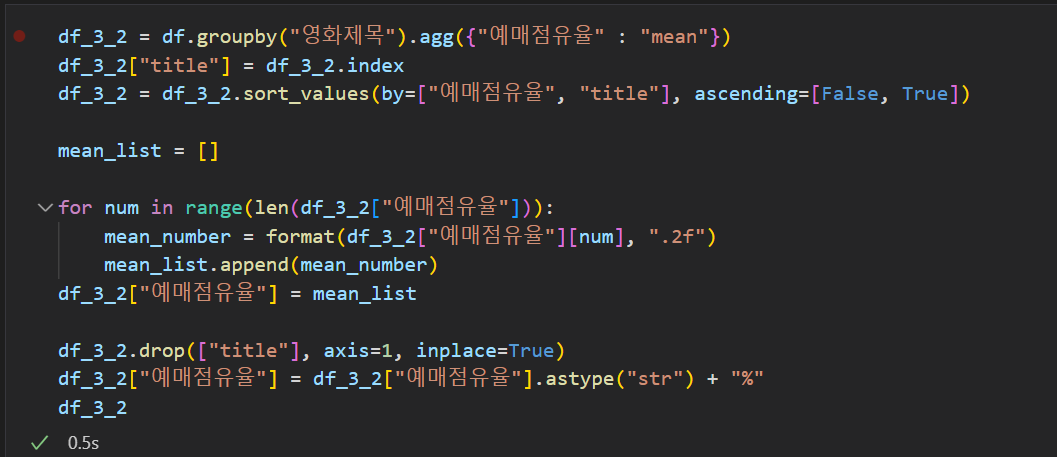
- 이번에는 영화별 예매점유율의 평균값을 구했다.
- 위에서는 string형태로 되어 있기 때문에 float형태로 변환해주고 format으로 반올림 후 참고로 0자리 개수를 맞추려고 round 대신에 사용했다.
- 그리고 마지막으로 string형태로 변환 후 퍼센트를 표시하기 위해 '%'를 붙였다.
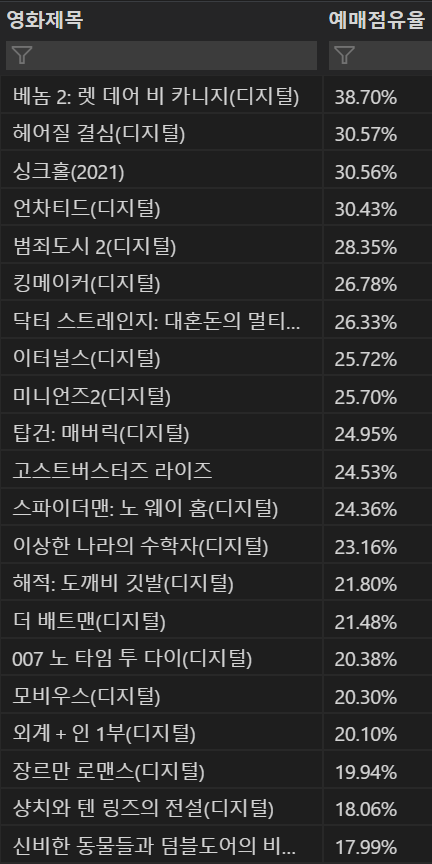
- 각 영화의 평균 예매율은 다음과 같이 나왔다.
끝

상황을 바꿀 수 없다면, 나를 바꾸자