- 와인 성분 데이터를 통해 머신러닝을 조금 더 연습해보자
- 준비한 자료를 변수에 저장 후 화이트 와인은 0, 레드 와인은 1로 컬럼을 추가 후, pd.concat으로 두 자료를 합친다.
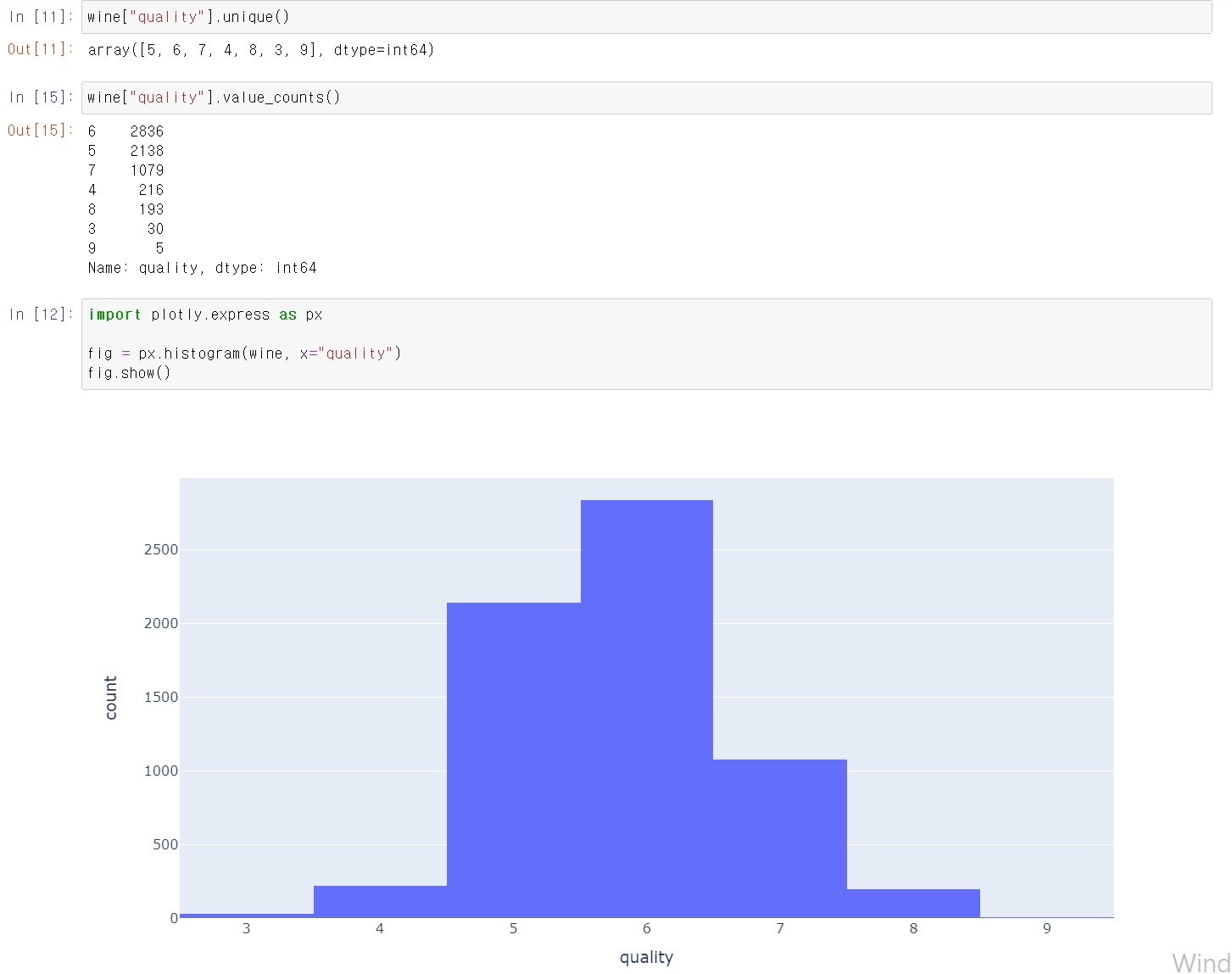
- quality 변수를 각 값의 count를 분석 결과 3과 9가 가장 낮음
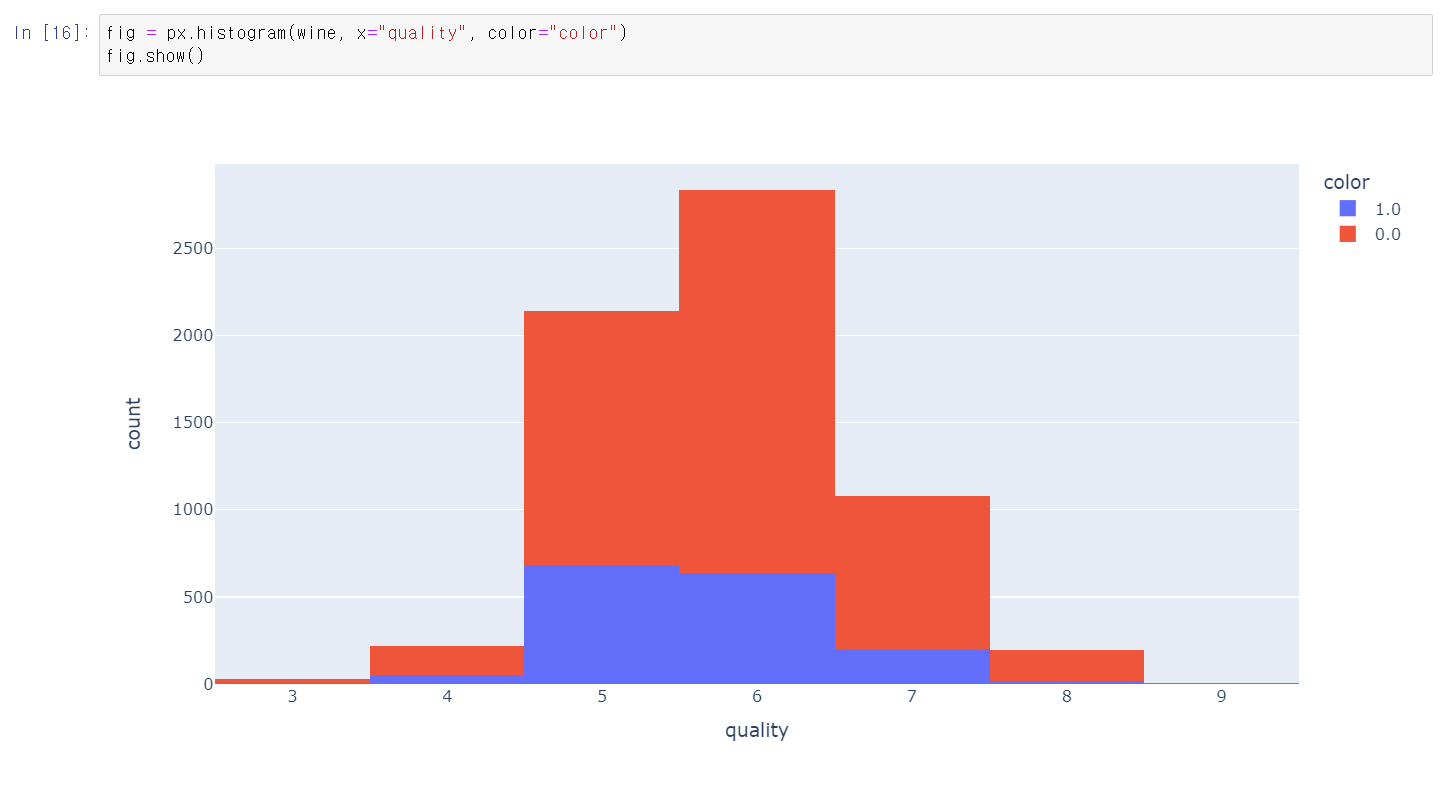
- 레드 와인과 화이트 와인을 구분해서 quality를 다시 분석해보니 레드와인의 수가 더 많으며 비슷한 분포를 가진다.

- 이제 주어진 자료를 통해 레드 와인인지 화이트 와인인지 구분하는 머신러닝을 교육하기 위해 x에는 color(와이 구분 변수)를 제외한 값을, y에는 color변수를 저장
- train_test_split을 통해 8:2로 자료를 구분 후,
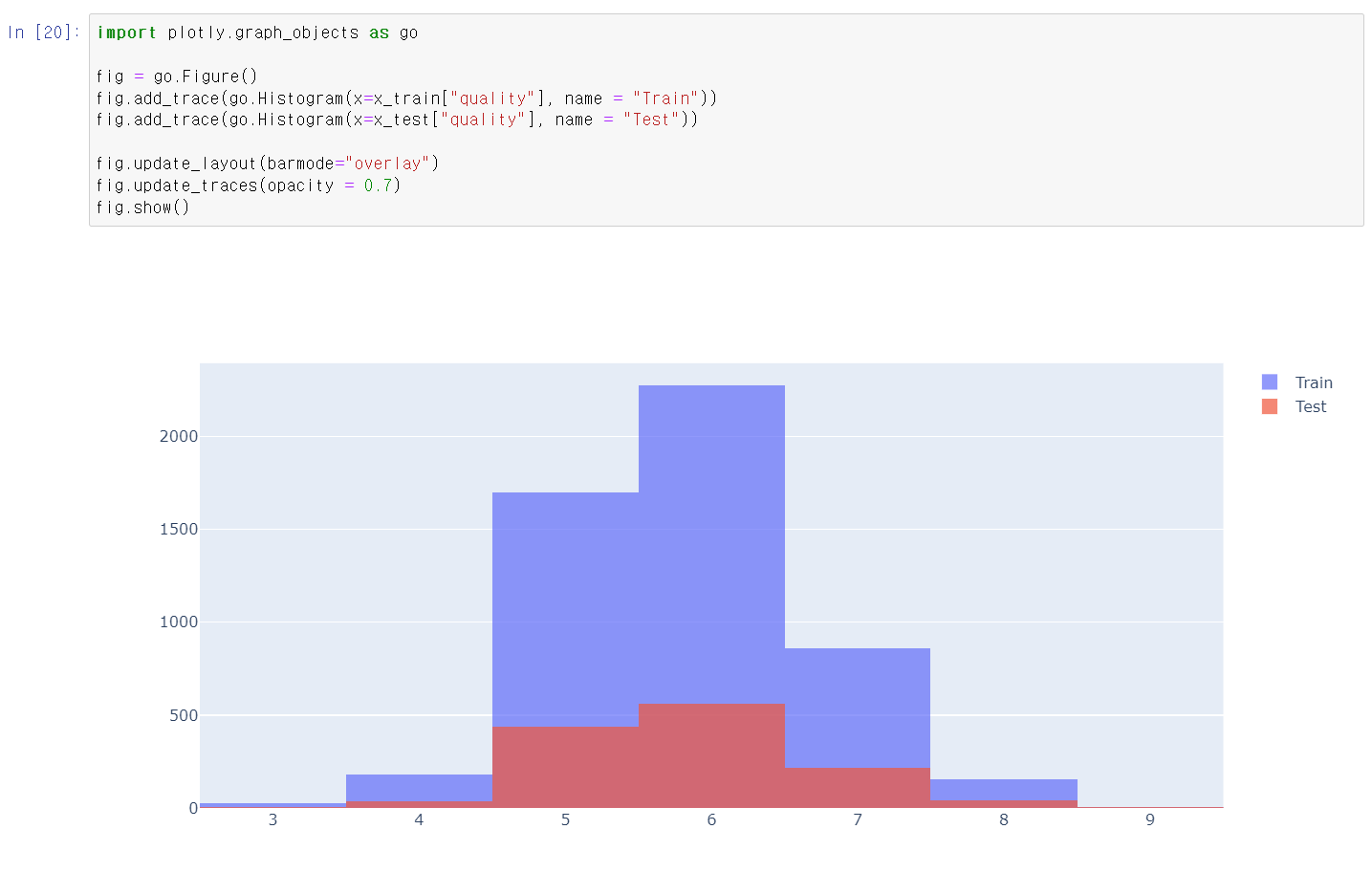
- 교육시킬 데이터와 테스트할 데이터의 숫자와 분포를 시각화로 확인
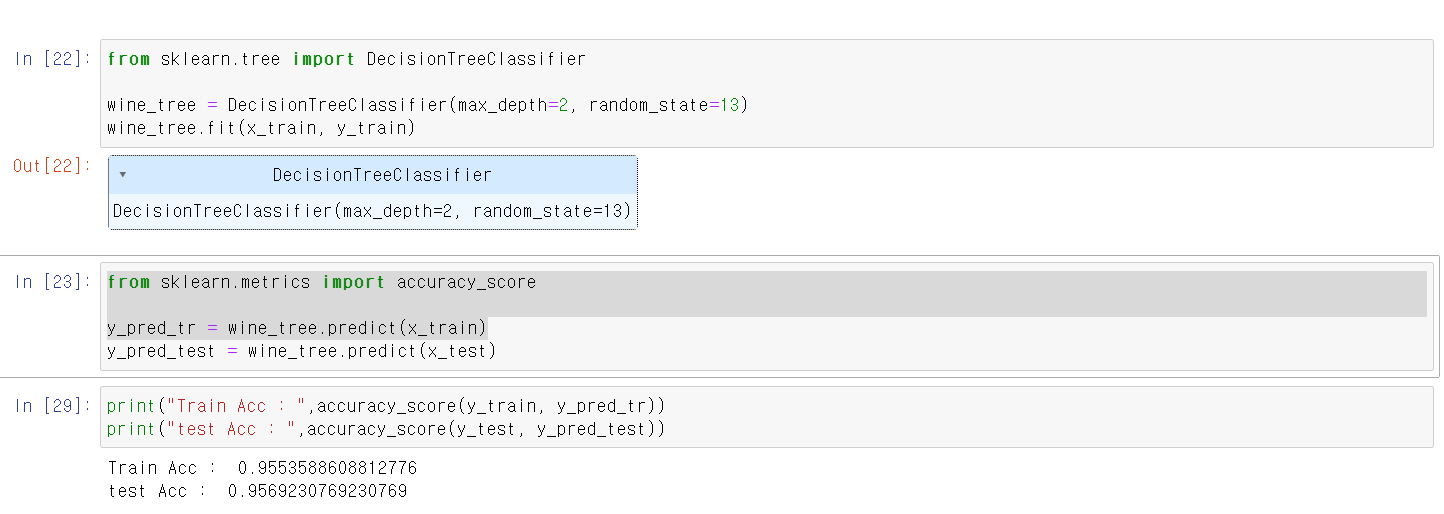
- max_depth를 2로, random_state를 13으로 교육시킨 결과 성능이 95%로 나왔으며, test데이터에 분석 결과 비슷한 성능을 가짐
- 하지만, 이것으로 결론을 내리는 것이 아니라 주어진 자료를 다양한 형태로 분석 시도
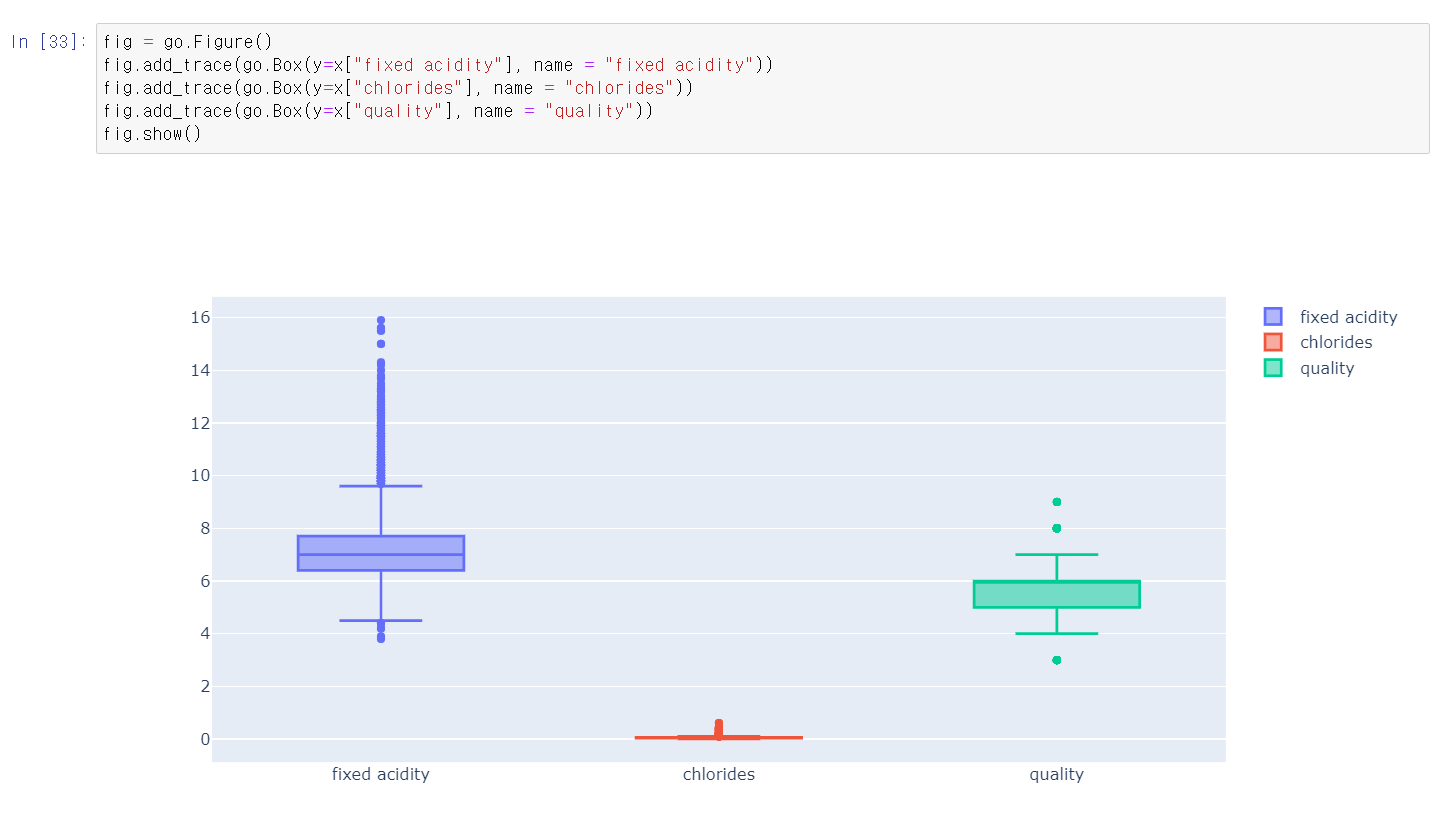
- 그전에 내가 먼저 스스로 자료를 분석함
- 각 값을 시각화를 통해 레드 와인과 화이트 와인을 구분할 변수값을 분석
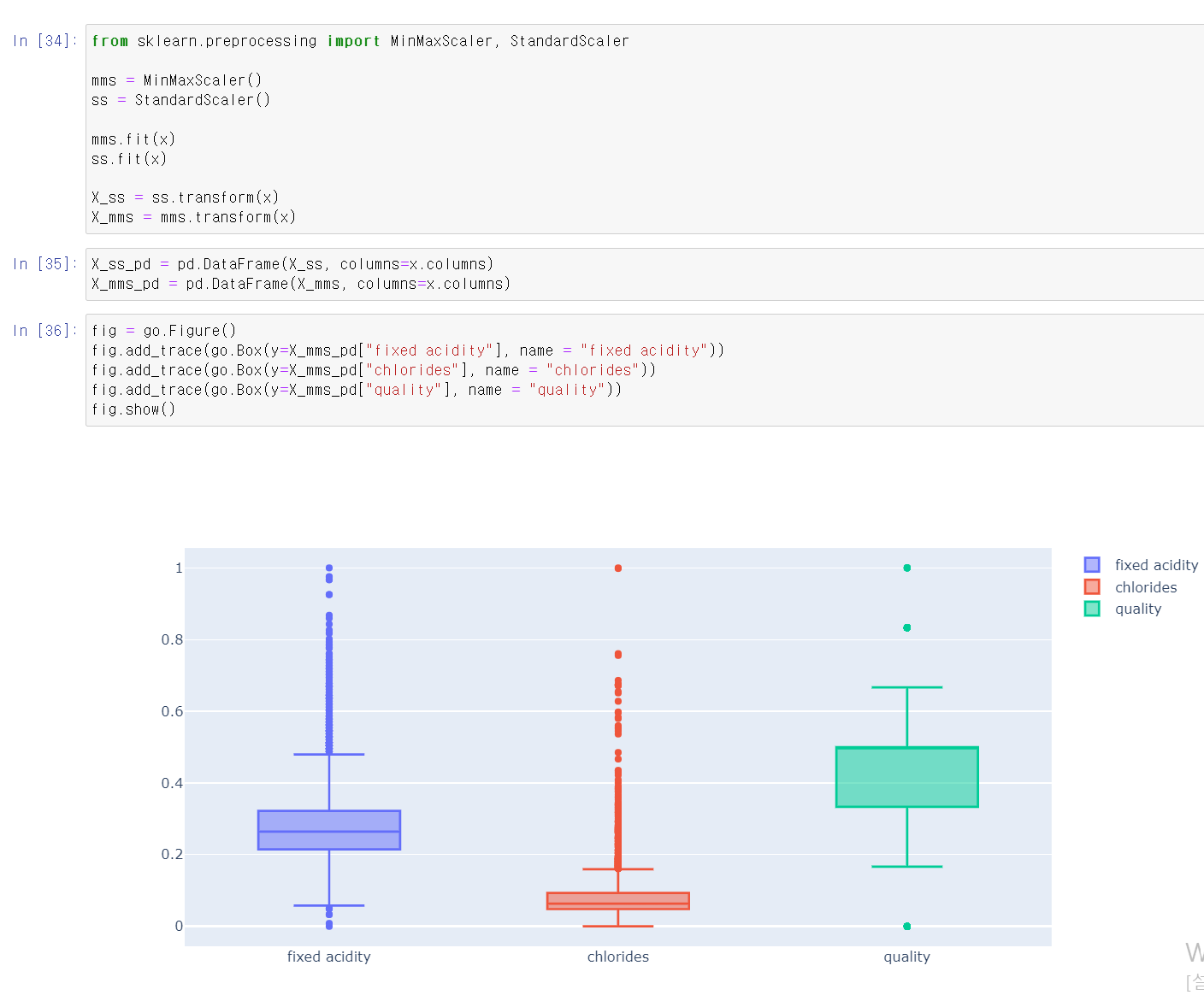
- 주어진 자료를 MinMax, Standard로 변환 후 각 자료를 시각화로 자료를 분석
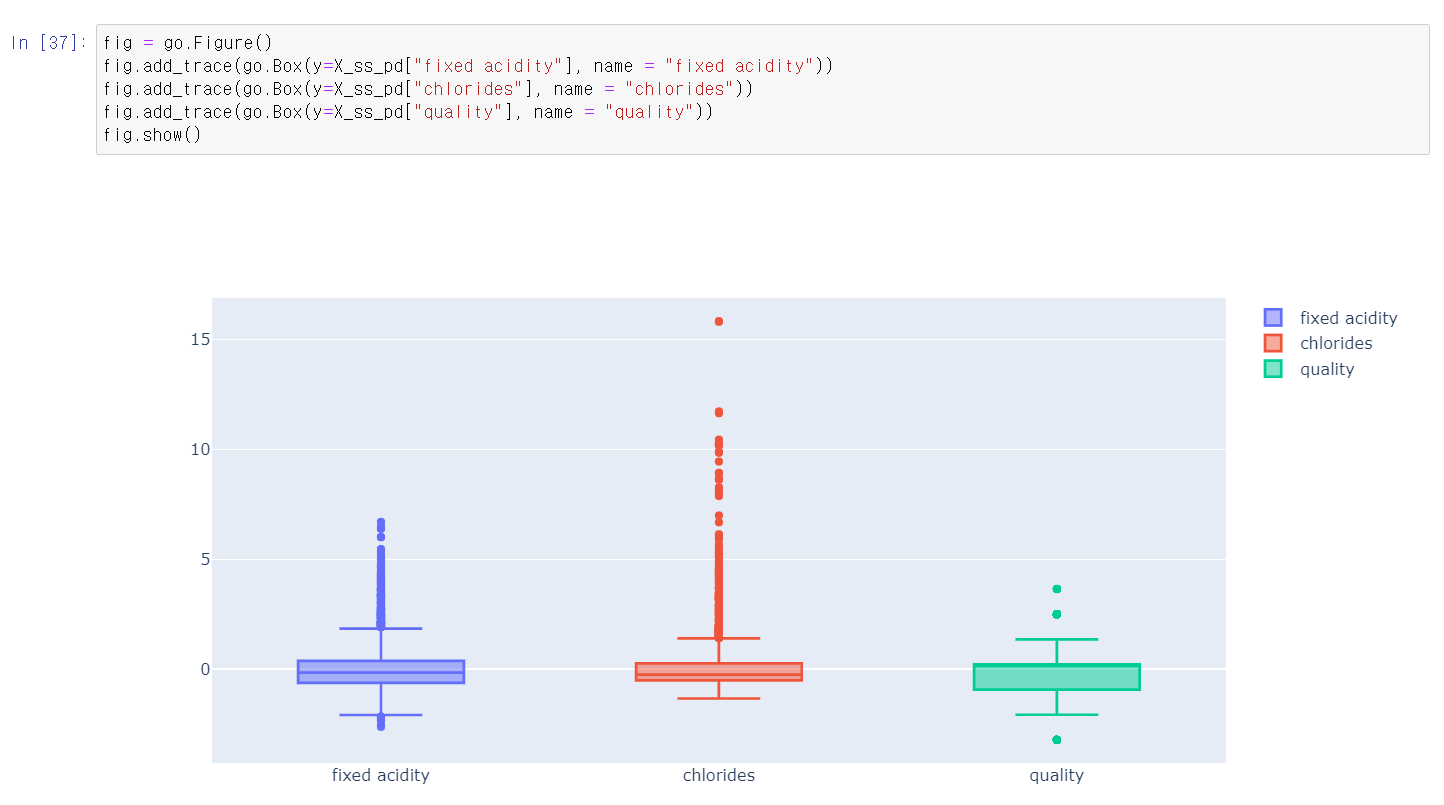
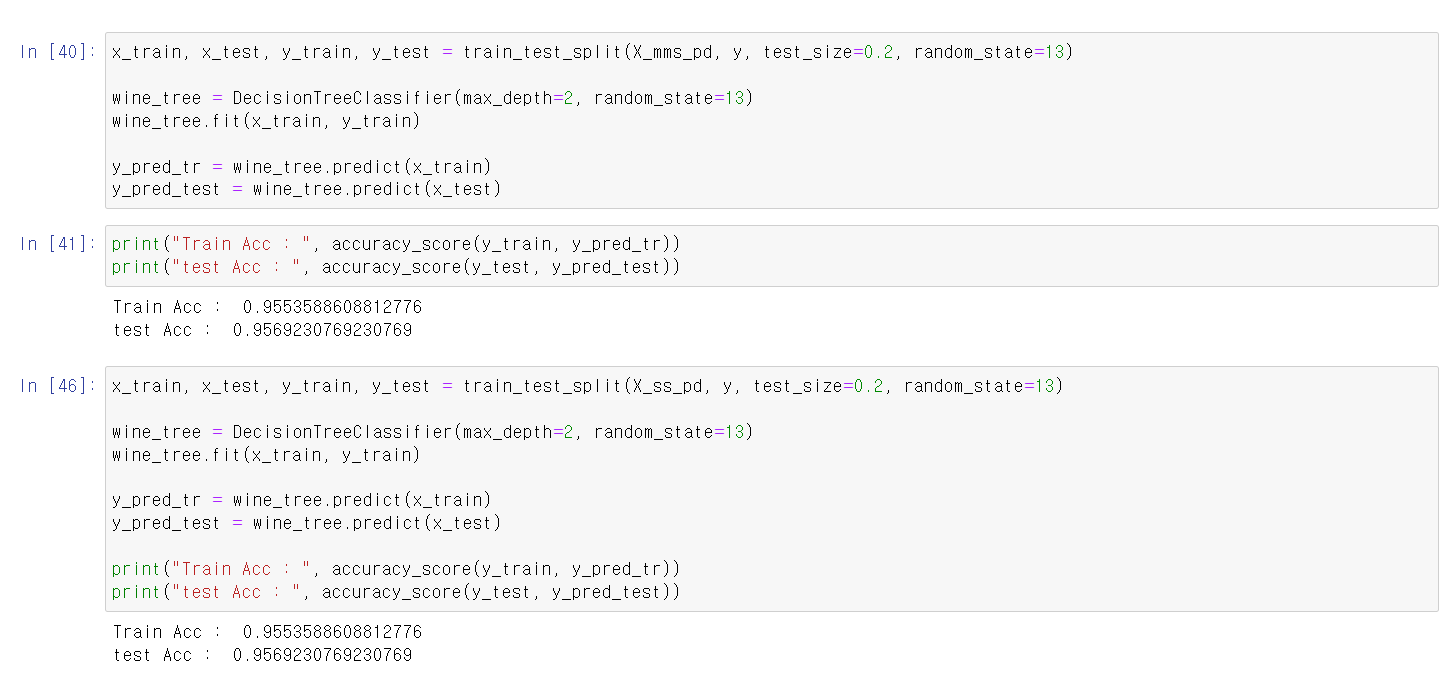
- MinMax, Standard 두 자료값을 통해 분석 결과 비슷한 성능을 가짐
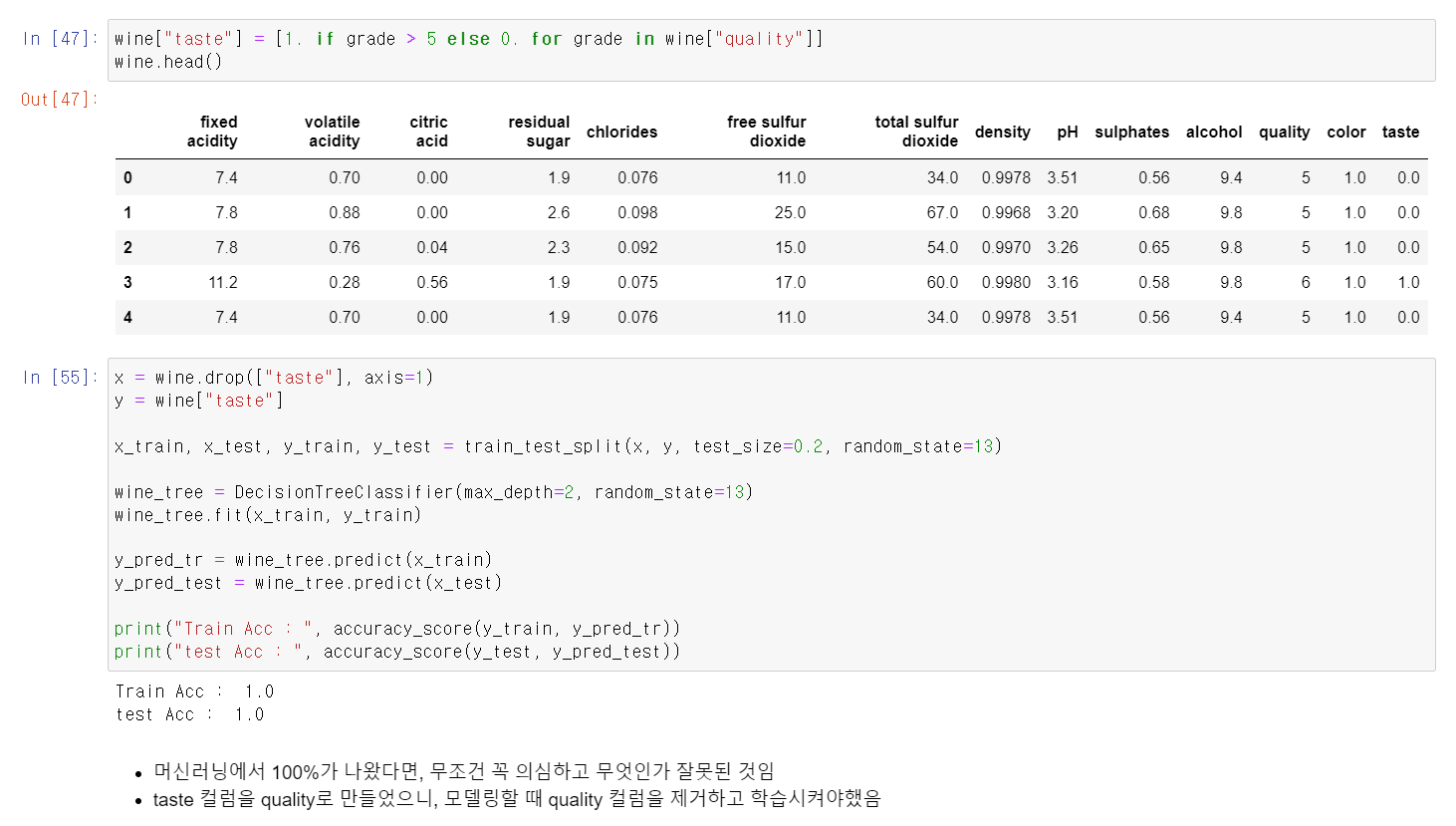
- 이번에는 quality가 4이상이면 1, 5이하면 0의 값을 가지는 column을 추가
- 해당 자료를 통해 머신러닝으로 분석 시도
- 100% 성능이 나옴...100%?
- 머신러닝에서 100% 성능이 나온다는 것은 분명히 무엇인가 잘못된 것인데 quality 변수를 통해 만든 taste를 통해 교육시켰기 때문에 100%가 나옴

- 머신러닝 과정을 시각화 결과 quality이 기준으로 교육함
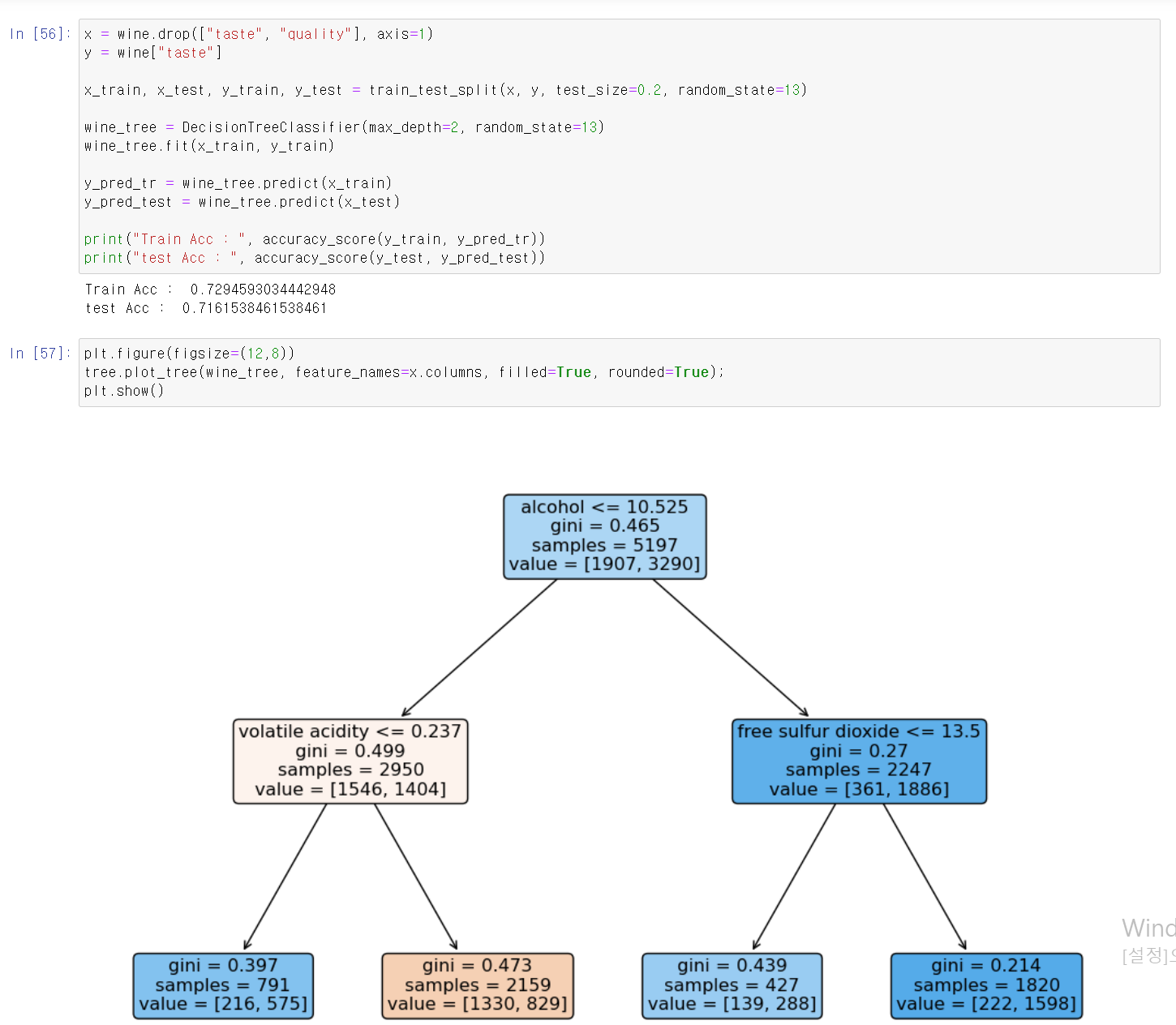
- quality, taste 변수를 제거한 자료를 taste를 정답으로 교육시킨 결과 정상적으로 성능이 나옴
- 또한, 밑에 머신러닝 과정을 보니, 알코올을 기준으로 먼저 구분 후 여러 변수로 교육을 함
- 결국 알코올이 높으면 맛있는 와인인가...?

상황을 바꿀 수 없다면, 나를 바꾸자