- 이전에 머신러닝에서 DecisionTree, 자료 변환 등 여러 과정을 가지지만, 한 번에 해결하는 PipeLine이라는 기능이 존재함
- 먼저 이전에 사용한 자료를 다시 변수에 저장 후
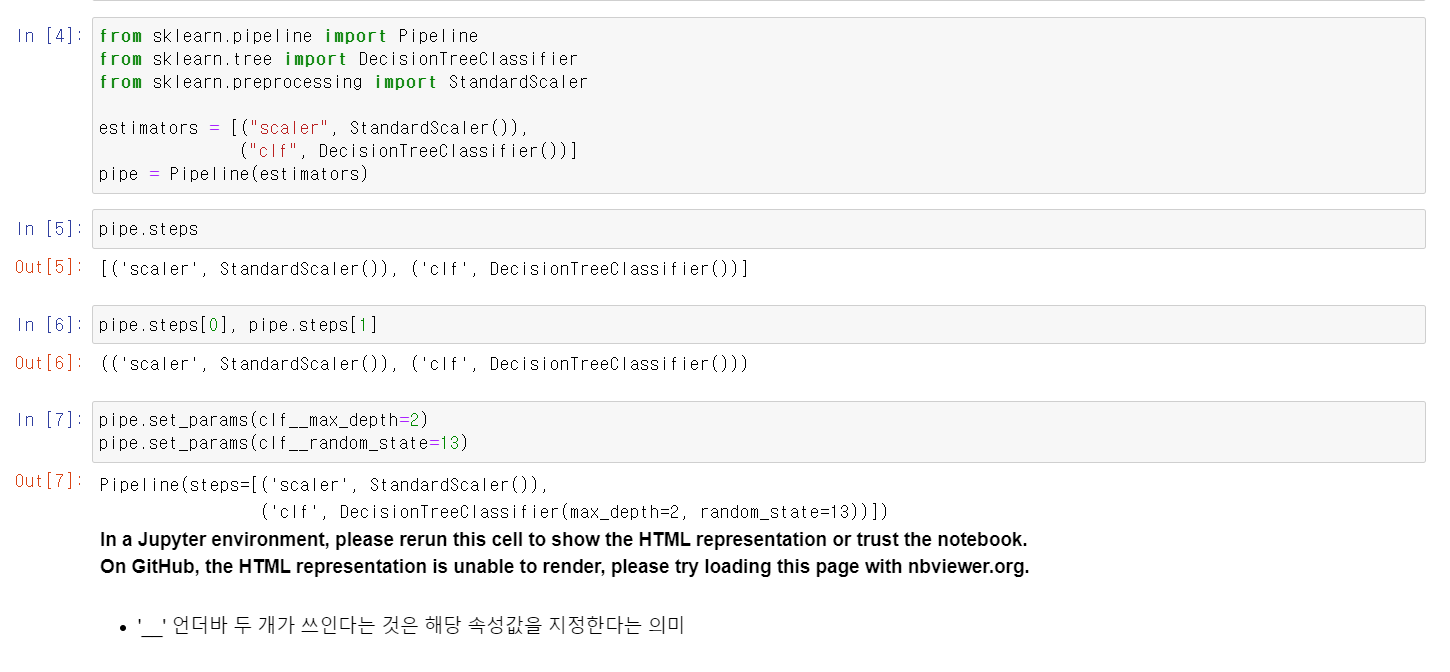
- 리스트 안에 튜플 형태로 스케일과 교육 방법을 지정 후 해당 변수를 Pipeline에 저장
- 해당 pipe변수에 max_depth값와 random_state 값을 저장
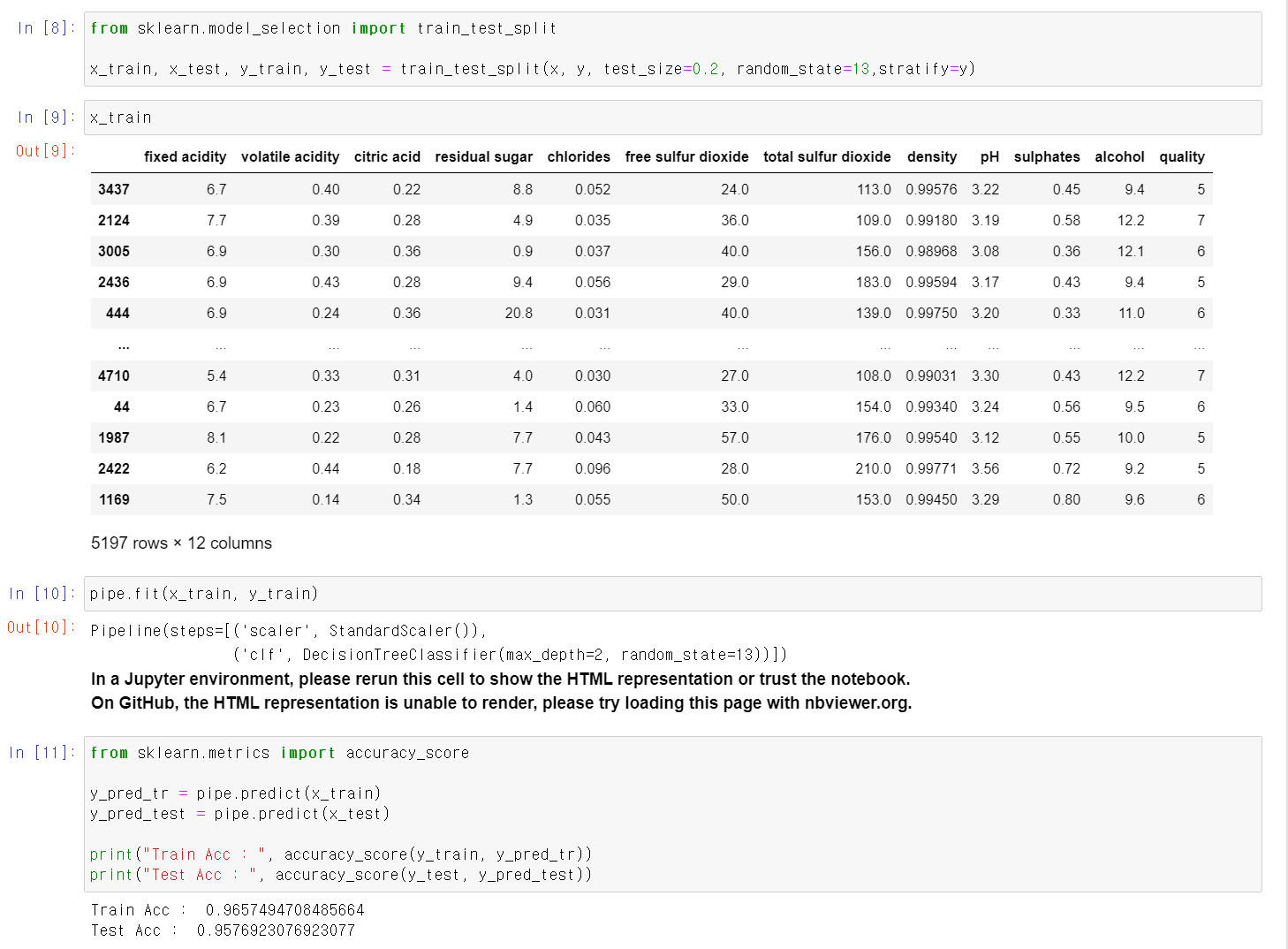
- 트레이닝 자료와 테스트 자료를 구분 후
- 트레이닝 자료와 정답을 교육 시킨 후 test자료에 분석 결과 비슷한 성능을 가진 값이 나옴

상황을 바꿀 수 없다면, 나를 바꾸자