크롤링한 데이터를 분석하여 인사이트 도출
크롤링이 되지 않는 경우
[문제상황]
- vscode 상에서 정상적으로 진행되고, 에러 없이 완료됨
- 그러나, 아무런 결과값도 담겨있지 않음 (내용을 제대로 크롤링하지 못함)
[원인]
- url = request.get( )으로 이마트몰 접근 시, <Response [429]>
- 400번대 출력 시, 페이지 없음 등의 에러 발생
- 429 : 사용자가 서버에 대해 일정 기간 내에 너무 많은 요청을 보냈음을 의미
- https://developer.mozilla.org/ko/docs/Web/HTTP/Reference/Status/429
- Retry-After : 사용자가 다시 요청을 보내기 전에 얼마나 대기해야 하는지에 대한 정보
- 날짜: 재시도 할 날짜
- 숫자: 응답을 받은 후 지연 시간(초)
- 그러나 서버에서 현재 헤더를 반환할지 말지는 서버 구현에 따라 달라지므로, 경우에 따라 429 에러가 발생하더라도 정확히 얼마나 대기해야 하는지 모름
Retry-After: <http-date>
Retry-After: <delay-seconds>
# 예시
Retry-After: Wed, 21 Oct 2015 07:28:00 GMT
Retry-After: 120"어떻게 Block이 된 걸까"
1. requests : 요청을 보내는 단계로, 클라이언트(나의 컴퓨터)가 서버로 보냄
2. response : 요청을 받은 서버가 데이터를 가져와 클라이언트에게 보내는 것
3. 크롤링 시, 이 requests를 아주 짧은 시간에 과도하게 보냄 (약 80개 상품에 10페이지 => 800 + @)*
4. 서버에서는 이러한 반복적이고 잦은 요청을 공격으로 인식 (서버 개발자가 설정한 기준에 의해)
5. 서버와 페이지, 데이터를 보호하기 위해 해당 클라이언트(=나)를 Block
[해결]
- API Key 사용
- 예외처리 수행 (현재 수행 방법)
- Requests의 Response가 400번대일 경우
- selenium의 driver로 크롤링 수행
Requests vs Selenium
- Requests : html, find_all(클래스명 등)
- Selenium : 동적 크롤링, XPATH, 주소값 이용
1. 동작 방식
| 구분 | requests | selenium |
|---|---|---|
| 작동 방식 | 서버에 HTTP 요청만 보내고 응답을 받아옴 (HTML 코드만 가져옴) | 실제 브라우저를 제어함 (Chrome/Firefox 등 실행) |
| 렌더링 | ❌ 없음 (JavaScript는 실행되지 않음) | ✅ 있음 (브라우저가 JS를 렌더링) |
| 사용 대상 | 정적 페이지 (HTML에 정보가 있는 경우) | 동적 페이지 (JS로 데이터가 나중에 로딩되는 경우) |
2. 성능 차이
| 항목 | requests | selenium |
|---|---|---|
| 속도 | 🚀 빠름 (단순 요청/응답만 함) | 🐢 느림 (브라우저 실행 + JS 처리 필요) |
| 리소스 사용 | 🧠 적음 (CPU/메모리 부담 적음) | 💥 큼 (브라우저 여러 개 뜨면 리소스 폭증) |
| 병렬성 | ✔ 다중 스레딩/비동기화 쉬움 | ✘ 브라우저 인스턴스 관리가 까다로움 |
3. 사용 용도
| 상황 | 적합한 도구 |
|---|---|
| 뉴스 기사 HTML 긁기 | ✅ requests |
| 쇼핑몰에서 스크롤해야 상품 전체가 보이는 경우 | ✅ selenium |
| API 엔드포인트나 URL 분석해서 바로 JSON 가져올 수 있는 경우 | ✅ requests |
| 버튼 클릭 → AJAX로 데이터 갱신되는 웹 페이지 | ✅ selenium |
4. 안정성과 유지보수
| requests | selenium |
|---|---|
| 간단하고 안정적 웹 페이지 구조 바뀌어도 적응이 쉬움 | 웹 요소 위치 지정이 불안정할 수 있음 (클래스 이름이 바뀌거나, DOM 구조 변화 시) 브라우저 업데이트, 드라이버 버전 등 외부 요인에 영향을 많이 받음 |
5. 적절한 사용상황
| 상황 | 추천 도구 |
|---|---|
| 빠르고 단순하게 HTML만 긁어오고 싶다 | requests |
| 동적으로 생성된 데이터를 수집해야 한다 | selenium |
| 대량으로 빠르게 크롤링하고 싶다 | requests + BeautifulSoup |
| 사용자처럼 직접 버튼 누르고 데이터를 얻어야 한다 | selenium |
EDA
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
import time
import random
import pyautogui
import pyperclip
import pandas as pd
import numpy as np
import re1. requests와 bs4 라이브러리를 이용하여, 이마트 '우유/유제품' 카테고리에 있는 제품의 이름/금액/별점 및 리뷰수를 30페이지까지만 수집해, emart_product.csv 파일로 저장하시오.
driver = webdriver.Chrome()
# 크롤링
product_name_list = []
product_price_list = []
score_list = []
count_list = []
for i in tqdm(range(1, 10)):
sleep_time = random.uniform(3,5) # 3~5
time.sleep(sleep_time) # 3~5초 동안 쉼
page = 'https://emart.ssg.com/disp/category.ssg?dispCtgId=6000213534&page=' + str(i)
url = requests.get(page)
html = BeautifulSoup(url.text)
# '<Response [429]>'
if int(str(url).split(' ')[1][1:4]) >= 400: # 블락된 경우, 크롬 드라이버로 html 정보 받아옴
driver.get(page)
driver.implicitly_wait(10)
scr = driver.page_source
html = BeautifulSoup(scr)
# 상품명
product_name = html.find_all('div', attrs = {'class' : 'mnemitem_tit'})
for x in product_name:
x1 = x.get_text()
product_name_list.append(x1)
# 상품 가격
product_price = html.find_all('div', attrs = {'class' : 'new_price'})
for x in product_price:
x1 = x.get_text()
product_price_list.append(x1)
# 리뷰가 없는 상품 체크
products = html.find_all('li', attrs = {'class' : 'mnemitem_grid_item'})
for y in range(len(products)):
check = products[y].find_all('div', attrs = {'class' : 'mnemitem_review_info'})
if str(check) == '[]':
score_list.append(np.nan)
count_list.append(np.nan)
else: # 리뷰가 있는 경우
score = products[y].find_all('div', attrs = {'class':'mnemitem_review_info'})[0]\
.find_all('span', class_ = 'review_text')[0].get_text()
count = products[y].find_all('div', attrs = {'class':'mnemitem_review_info'})[0]\
.find_all('span', class_ = 'review_text')[1].get_text()
score_list.append(score)
count_list.append(count)
df1 = pd.DataFrame( {'상품명' : product_name_list, '상품가격' : product_price_list,
'리뷰점수' : score_list, '리뷰개수' : count_list})
df1.head()- 추출한 데이터 전처리/가공
# 상품명
def func1(x):
return x.replace('\n', '')
df1['상품명'] = df1['상품명'].apply(func1)
# 상품가격
def func2(x):
x1 = x.split('\n')
return int(x1[2].replace(',', '')[:-1])
df1['상품가격'] = df1['상품가격'].apply(func2)
df1.head()
# 리뷰점수
def func3(x):
return float(x)
df1['리뷰점수'] = df1['리뷰점수'].apply(func3)
# 리뷰 개수
def func4(x):
if pd.isna(x):
return np.nan
else:
pattern = r'\d+'
x1 = re.findall(pattern, str(x))[0]
return int(x1)
df1['리뷰개수'] = df1['리뷰개수'].apply(func4)
- 특정 상품 찾기
# 상품명을 기준으로 중복 제거
df2 = df1.drop_duplicates(subset = '상품명')
cond1 = df1['상품명'] == '동원참치 스프레드 체다치즈 100g*4'
df1.loc[cond1]- 추출한 데이터를 csv 파일로 저장
df2.to_csv('emart_product.csv')2. 수집된 데이터에 리뷰수가 가장 많고, 별점이 높은 상위 50개 항목을 확인하시오
# 두 개의 항목을 기준으로 정렬 -> 리스트 형식 활용
df2.sort_values(by = ['리뷰개수', '리뷰점수'],
ascending = [False, False]).head(50)3. 판매 금액의 Histogram을 시각화하시오.
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
mpl.rc('font', family = 'Malgun Gothic')
# 전체 범위 시각화 (왼)
sns.histplot(df2, x = '상품가격')
# 데이터가 많이 분포하는 (0~25000) 부분만 시각화 (오)
plt.xlim([0,25000])
sns.histplot(df2, x='상품가격') | 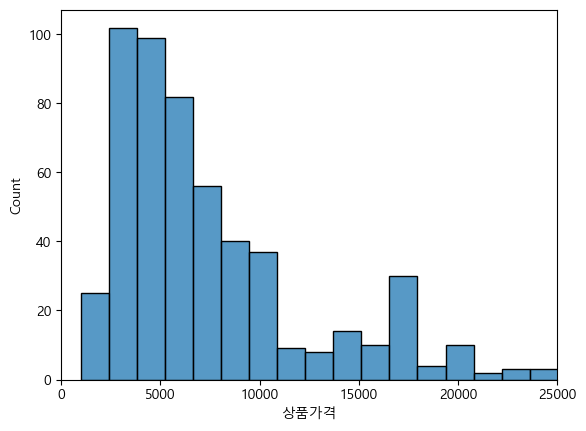 |
|---|
4. 판매 금액이 가장 높은 제품과 가장 낮은 제품을 확인하시오.
# 가장 높은 제품
df2.sort_values(by = '상품가격', ascending = False).head(1)
# 가장 낮은 제품
df2.sort_values(by = '상품가격', ascending = False).tail(1)5. 판매 브랜드를 구분하여, 가장 제품이 많은 판매 브랜드를 확인하시오.
# 브랜드 구분
def func5(x):
x1 = x.split(' ')[0]
return x1
df2['브랜드'] = df2['상품명'].apply(func5)
# 확인할 브랜드 범위를 선정하여 재분류
br_list = ['동원', '덴마크', '그레이니', '매일', '죽염', '빙그레', '노브랜드',
'피코크', '서울우유', '남양']
def func6(x):
for br in br_list:
if br in x:
return br
else:
return '기타'
df2['브랜드2'] = df2['상품명'].apply(func6)
# 판매 제품이 가장 많은 브랜드 확인
df2['브랜드2'].value_counts()6. 판매 브랜드 별 별점의 평균/최대/최소값을 계산하시오.
df2.pivot_table(index = '브랜드2', values = '리뷰점수',
aggfunc = ['mean', 'max', 'min'])7. 판매 브랜드 별 리뷰수의 합을 계산하시오.
df2.pivot_table(index = '브랜드2', values = '리뷰개수', aggfunc = 'sum')\
.sort_values(by = '리뷰개수', ascending = False)정규표현식
8. 이메일 주소 찾기: 주어진 문자열에서 이메일 주소를 찾으세요.
- 예제 문자열: "Please contact us at contact@example.com"
text1 = 'Please contact us at contact@example.com.'
pattern = r'[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}'
# A-Z a-z 0-9 : 대/소문자 알파벳, 숫자
# ._%+- : 해당 특수문자가 들어갈 수 있다
# + : 앞의 [ ]가 연속됨
# {n, } : n번 이상 반복
# {n} : 정확히 n회 반복
# {n, m} : 최소 n번, 최대 m번 반복
re.findall(pattern, text1)9. 웹사이트 URL 찾기: 주어진 문자열에서 http:// 또는 https://로 시작하는 URL을 모두 찾으세요.
- 예제 문자열: "Visit our website at http://example.com."
text9 = "Visit our website at http://example.com."
pattern = r'(?:https?://)\S+'
# \S+ : 공백이 아닌 문자 하나 이상이 연속됨
# (? .... ) : 논캡쳐 그룹 : 전체 링크가 필요한 것이기 때문에,
# http는 참조하지 않음
# http 뒤의 s? : s 가 있을 수도, 없을 수도 있다
re.findall(pattern, text9)[0]10. 전화번호 찾기: 주어진 문자열에서 "XXX-XXX-XXXX" 형태의 전화번호를 찾으세요.
- 예제 문자열: "Our phone number is 123-456-7890."
text10 = "Our phone number is 123-456-7890."
pattern = r'\d{3}-\d{3}-\d{4}'
# pattern = r'\d+-\d+-\d+'
# \d : 숫자
# {n} : 정확히 n번 반복
re.findall(pattern, text10)11. 대문자로 시작하는 단어 찾기: 문자열에서 대문자로 시작하는 모든 단어를 찾으세요.
- 예제 문자열: "London is the capital of England."
text11 = "London is the capital of England."
pattern = r'[A-Z][a-z]*'
# * 바로 앞의 패턴이 0번 이상 반복됨
# 대문자는 반드시 등장하되, 소문자는 없어도 됨
re.findall(pattern, text11)
# ['London', 'England']
text11 = "London is the capital of England. HAHAHAHA"
re.findall(pattern, text11)
# ['London', 'England', 'H', 'A', 'H', 'A', 'H', 'A', 'H', 'A']12. 날짜 찾기: "YYYY-MM-DD" 형식의 날짜를 찾으세요.
- 예제 문자열: "The event is scheduled on 2024-01-25."
text12 = "The event is scheduled on 2024-01-25."
pattern = r'\d{4}-\d{2}-\d{2}'
re.findall(pattern, text12)
# ['2024-01-25']13. 시간 형식 찾기: "HH:MM" 형식의 시간을 모두 찾으세요.
- 예제 문자열: "The meeting starts at 14:30 and 17:10."
text13 = "The meeting starts at 14:30 and 17:10."
pattern = r'\d{2}:\d{2}'
re.findall(pattern, text13)
# ['14:30', '17:10']14. HTML 태그 제거: 주어진 HTML 문자열에서 모든 태그를 제거하고 순수 텍스트만 추출하세요.
- 예제 문자열: Example Domain = "Example Domain"
text14 = "<title>Example Domain</title>"
pattern = r'<.*?>'
# . : 사용되는 모든 문자열
# * : 0 회 이상 반복
# ? : 있을수도 없을수도 있다
re.sub(pattern, '', text14)
# 'Example Domain'15. IP 주소 찾기: "XXX.XXX.XXX.XXX" 형식의 IPv4 주소를 찾으세요.
예제 문자열: "Ping this IP 192.168.1.1"
text15 = "Ping this IP 192.168.1.1"
pattern = r'(?:\d{1,3}\.){3}\d{1,3}'
# (?: ... ) : 논캡쳐 그룹
# d{1,3} : 숫자가 1~3자리수다
# {3} : 3번 반복
# \. : .
re.findall(pattern, text15)
# ['192.168.1.1']16. 단어 치환하기: 정규표현식을 사용하여 문자열에서 "Python"을 "You"로 치환하세요.
- 예제 문자열: "I Love Python."
text16 = "I Love Python."
change = 'You'
re.sub(r'Python', change, text16)17. 이메일 주소 유효성 검사: 주어진 이메일 주소가 유효한 형식인지 참/거짓을 반환하는 함수를 만드세요.
def func17(email):
pattern = r'[A-Za-z0-9._%-+]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}'
if re.match(pattern, email): # match되는게 없으면 None -> False
return True
else:
return False
func17('korea123@123.3') # False
func17('korea123@gmail.com') # True

Analyse the world