패키지 다운로드 및 설정
pip install konlpy
pip install Jpype1import konlpy
from konlpy.tag import Okt
### 설정
# 시스템 환경 변수 편집
# 고급
# 환경변수
# 시스템 변수 (하단)
# 추가
# 변수 이름
# JAVA_HOME
# 변수 값
# C:\Program Files\Java\jdk-22\bin\server
# (jvm.dll이 있는 경로)
# 재부팅 후 import 성공하면 됨실습을 위한 데이터 크롤링 (잡플래닛)
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
import time
import random
import pyautogui
import pyperclip
import pandas as pd
import numpy as np
import re
# 크롬 페이지 접속
driver = webdriver.Chrome()
# 잡플래닛 로그인 화면 이동
driver.get('https://www.jobplanet.co.kr/users/sign_in?_nav=gb')
# 아이디 입력
driver.find_element(By.XPATH, '//*[@id="user_email"]').send_keys('hanaro.data.win@gmail.com')
# 비밀번호 입력
driver.find_element(By.XPATH, '//*[@id="user_password"]').send_keys('hanaro1234!')
# 로그인 버튼 클릭
driver.find_element(By.XPATH, '//*[@id="signInSignInCon"]/div[2]/div/section[2]/fieldset/button').click()
# 금융감독원 페이지로 이동
driver.get('https://www.jobplanet.co.kr/companies/43469/reviews/%EA%B8%88%EC%9C%B5%EA%B0%90%EB%8F%85%EC%9B%90')- .send_keys() : 입력값 전송
pyautogui.locateCenterOnScreen( 'img' )
: 이미지에 나타난 사항을 화면 상에서 찾아, 그 위치로 이동
nav_0 = pyautogui.locateCenterOnScreen('click.png')
pyautogui.moveTo(nav_0)
# time.sleep(0.3)
# pyautogui.click()EDA
# 구성요소 수집
src = driver.page_source
html = BeautifulSoup(src)
# 인적정보
hr_data = html.find_all('div', class_ = 'content_top_ty2')
hr_list = [x.get_text() for x in hr_data]
# 한줄평 작성 정보
comment = html.find_all('div', class_ = 'mb-[20px]')
# 위 데이터에는 평점(ex-5.0) & 한줄평(ex-밥이 맛있다)이 번갈아가며 저장됨
# 따라서 이를 나누어야 함
comment_list = [x.get_text() for x in comment]
# 점수
score_list = [comment_list[x] for x in range(len(comment_list)) if x % 2 == 0]
# 한줄평
comment_list2 = [comment_list[x] for x in range(len(comment_list)) if x % 2 != 0]
Konlpy 분석
import konlpy
from konlpy.tag import Okt
okt = Okt()
# open korean text
# 한줄평이 담긴 데이터(comment_list2)를 df로
df1 = pd.DataFrame(comment_list2)- 가장 첫 번째 한 줄평 문장 분석
text1 = df1[0].values.tolist()[0]
# '"밥이 매우 맛있다 다른 식당 안가도됨"'
p1 = pd.DataFrame(okt.pos(text1)) # 왼쪽 사진
# okt.pos() : 각 문장 내 요소의 형태소 분석
# pos : part of speech
# 특정 형태소 (명사) 추출
cond1 = p1[1] == 'Noun'
p1.loc[cond1] # 오른쪽 사진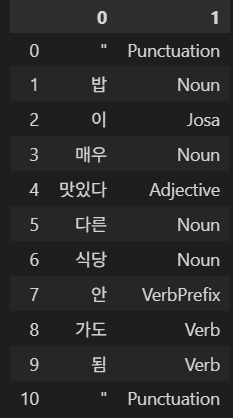 |  |
|---|
- 전체 데이터에 대해 위 형태소 분석 & 명사 추출
df_pos = pd.DataFrame()
for i in range(len(df1)):
df_n = pd.DataFrame(okt.pos(df1[0].values.tolist()[i]))
df_pos = pd.concat([df_pos, df_n], ignore_index = True)
df_pos.columns = ['형태소', '품사']
# 명사추출
df_N = df_pos.loc[df_pos['품사'] == 'Noun']
# 불용어 제거
cond1 = df_N['형태소'].isin(['및', '비', '배'])
df_N2 = df_N.loc[~cond1]WordCloud 시각화
pip install wordcloud
from worldcloud import WordCloud
import matplotlib.pyplot as plt
# 분석한 명사에 대해 워드클라우드 시각화
wc = WordCloud(background_color='white', width = 800, height = 800,
font_path = 'malgun.ttf').generate(' '.join(df_N2['형태소']))
# generate : 텍스트를 입력하는 부분
# .join : 형태소 안의 모든 단어들을 띄어쓰기로 구분하여 하나로 합침
# 예) '점심으로', '스테이크를', '먹었다' -> '점심으로 스테이크를 먹었다'
plt.figure(figsize = [10, 10])
plt.imshow(wc)
plt.show()

Analyse the world