대회를 진행하면서 정말 많이 사용한 방식인데 이에 대해 이해가 부족한 것 같아 내 방식대로 정리해보았다.
🚀 1) Automatic Mixed Precision이란?
(1) 개요
종류
- FP32 (Single Precision, 단정밀도)
- FP64 (Double Precision)
- FP128 (Quadruple Precision)
- FP16 (Half Precision)
부동 소수점
- 118.625(10진법)=-1110110.101(2진법) → 정규화: -1.110110101×2^6 (소수점이 이동!)
⇒ 부호: 1(음수) / 지수: 110 / 가수: 110110101
바이어스 표현법 (biased expression)
지수부분은 부호를 표현할 수 없기 때문에, 음수를 표현하기 위해 00000000을 -127로 01111111을 0으로, 11111111을 128로 표현하는 기법
⇒ 지수: 110 → 10000101
IEEE 754 표준
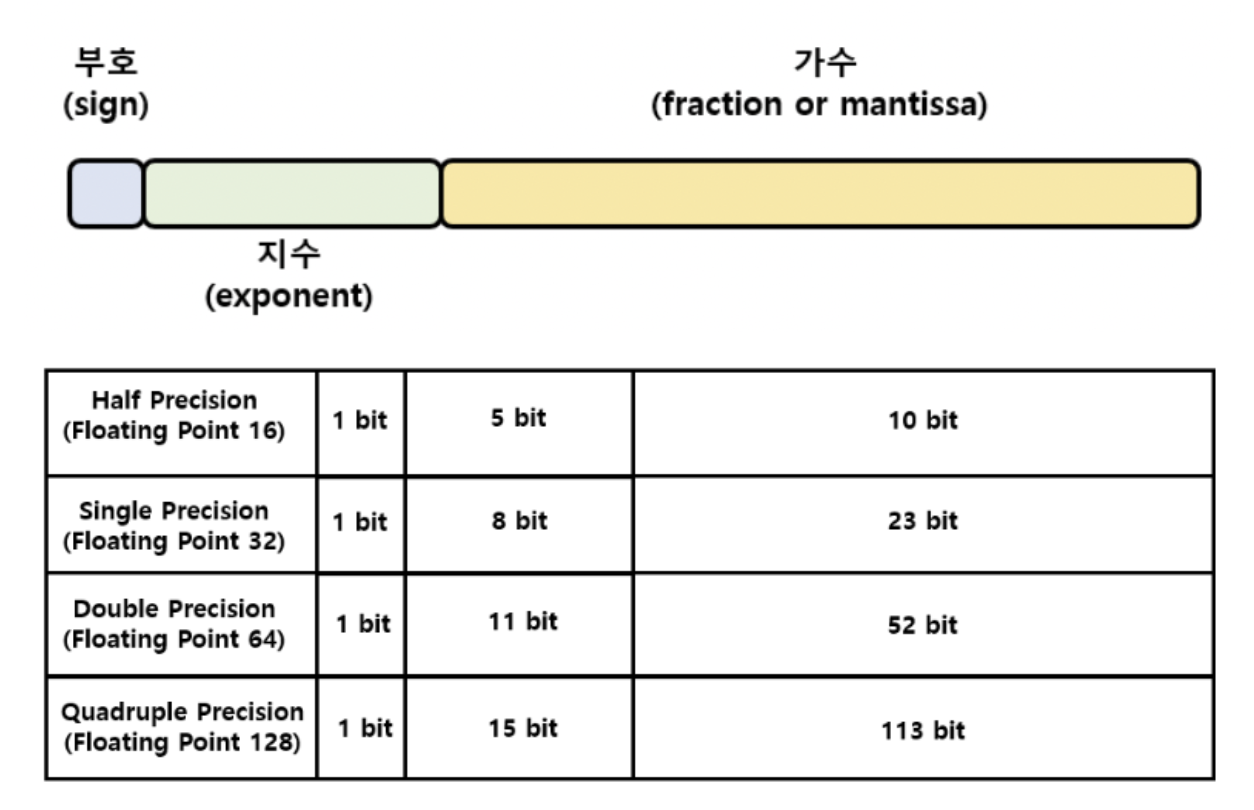
FP32(single precision) 기준으로,
⇒ 부호: 1 (1bit) / 지수: 10000101 (8bit) / 가수: 11011010100000000000000 (뒤에 0 붙여서 23bit로)
사용 방식
처리 속도를 높이기 위한 FP16(16bit floating point)연산과 정확도 유지를 위한 FP32 연산을 섞어 학습하는 방법
여기서 Dynamic Loss Scaling이 사용된다.
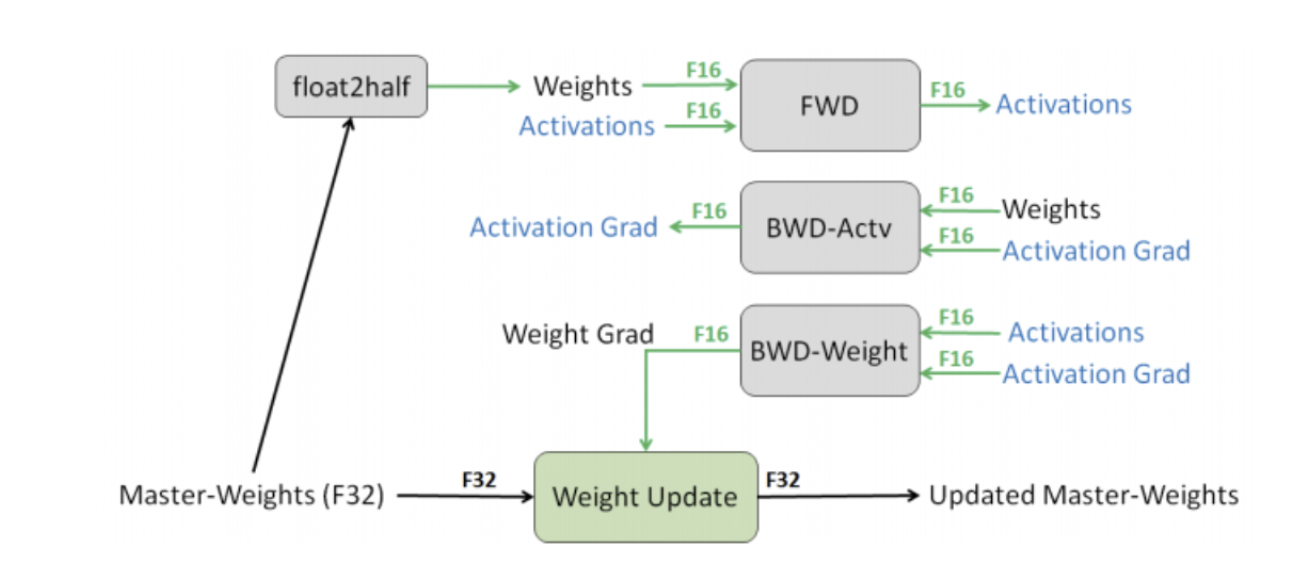
Dynamic Loss Scaling이란?
Loss Scaling에서는 사전에 정의해야 하는 S를 큰 값으로 초기화한 후에 지속적으로 업데이트시켜주는 방식
- 먼저 weight 자체는 fp32로 유지가 된다.
- 이에 대해 fp16으로 표현할 수 있는 copy를 만들어준다.
- 그리고 이를 가지고 foward를 진행해준다.
- 결과에 대해서 loss를 구하기 이전에 S를 곱해 소수점에서 손실이 일어나지 않도록 보완해준다.
- 만약 이때에 Inf, NaN이 뜨게 된다면 S를 줄여 overflow underflow를 방지시켜준다.
- 그리고 이때에 가중치 업데이트를 스킵하고 4번을 다시 진행한다.
- 그렇게 구해진 가중치 그레디언트에 다시 1/S를 곱해 업데이트하기 적합한 형태로 만들어준다.
- 그리고 이를 가지고 가중치 업데이트
- 이 과정에서 최근 N번 동안 Inf나 NaN이 나지 않았다면 S를 증가시킨다
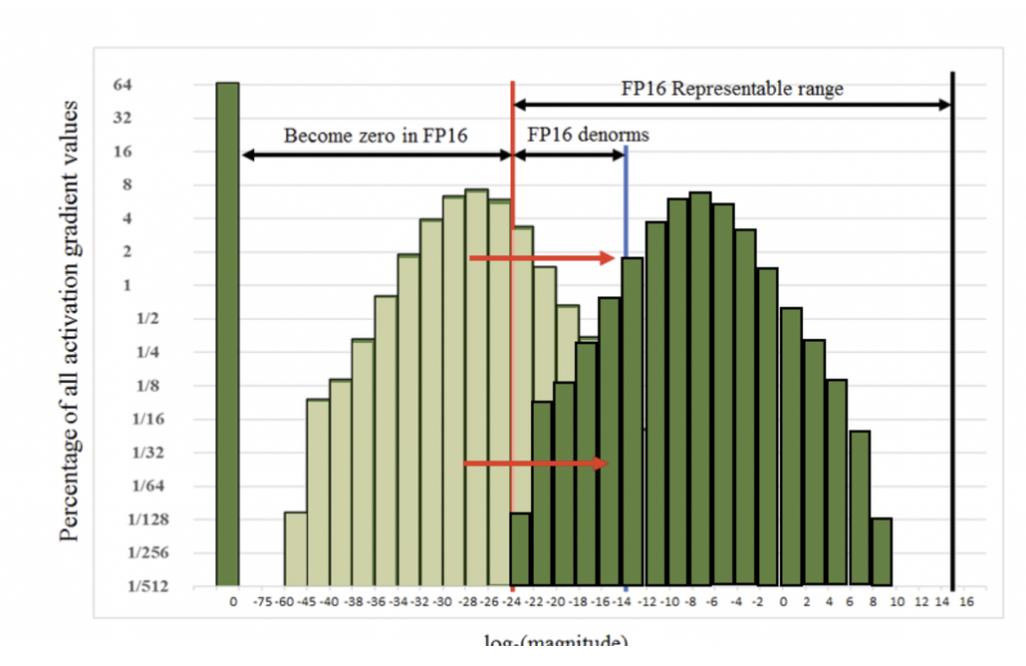
결과적으로 gradient 값들이 FP16이 나타내지 못하는 구간에 존재하는 것들을 factor S를 통해 표현이 가능한 형태로 만들어주는 것
가장 쉽게 접근할 수 있는 생각은 이 값들을 오른쪽으로 밀어주는 것
gradient에 큰 수를 곱해서 값들을 오른쪽으로 shift 시키는 아이디어
Mixed Precision 과정
Tensor Core에 맞는 연산들(ops)은 FP16으로 계산하고 정확한 계산이 필요한 부분은 FP32로 계산하는 Mixed Precision Training
- 정확한 연산이 필요한 부분이라는 것은 weight update 부분
별도로 지정하지 않는 한 dynamic loss scaling을 적용하여 학습함
- Model weights는 FP32로 유지시키기 때문에 loss를 이에 맞게 scaling 해야함
(2) 사용 이유 + 장점
속도
배치를 늘릴 수 있기 때문에 학습 속도가 빨라지지만 배치 뿐만 아니라 모델 최적화도 이루어지기 때문에 속도가 증가함
Tensor Core를 활용한 FP16연산을 이용하면 FP32연산 대비 절반의 메모리 사용량과 8배의 연산 처리량 & 2배의 메모리 처리량 효과가 있다
- 배치 크기가 2배로 증가하지만 속도는 2.5배, 3배씩 증가하는 것으로 보아 최적화를 위한 속도 향상도 존재함
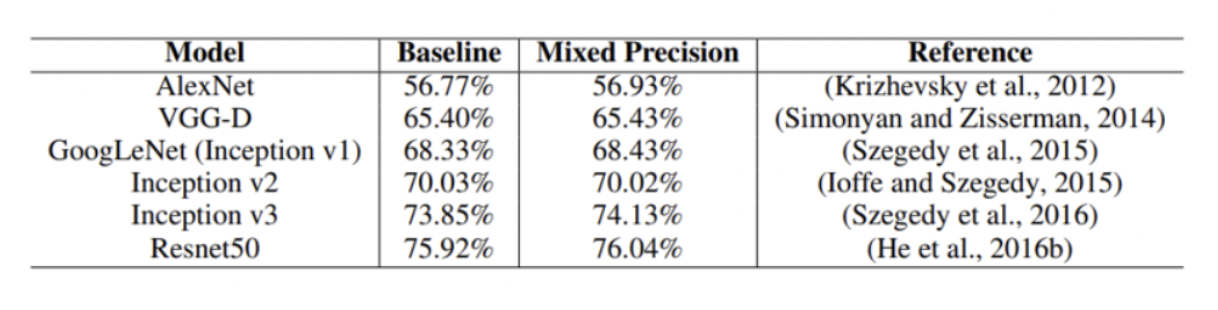
성능
약간의 증가를 보이는 추세
즉 fp32를 사용할 때보다 성능이 상승하게 된다.
- 성능이 향상되는 이유는 배치사이즈에 증가에 따른 학습 효과로 판단됨
(4) 단점
fp16을 사용하게 되면 성능이 떨어질 수도 있다는 위험성
💡 2) 내 프로젝트 어디 부분에 사용되었는가
(1) KLUE R.E.
AMP를 사용해 Batch Size를 늘리고자 했다.
RoBERTa-large 모델을 사용해 처음에 32 batch size를 사용했다.
모델 자체가 layer가 24나 되기 때문에 꽤나 무거운 모델이었다.
또한 32000개 문장 데이터로 이루어졌고 test data도 7000개 넘었으며 30개의 label에 대해 classification 해줘야 하는 매우 큰 task였다.
따라서 모델이 정확하면서도 빠르게 분석을 할 줄 알아야했기에 AMP 기법을 차용해 속도를 높이고자 했다.
덕분에 batch size를 64로 늘릴 수 있었으며 더 소요시간이 1/2로 감소한 빠른 학습과 성능을 유지할 수 있었다.
또한 덕분에 RoBERTa에 dense layer를 더 깊게 쌓아 classification에 더욱 적합한 형태로 만들어줄 수 있었다.
결과적으로 f1-score에서 3정도의 상승을 이루어낼 수 있었다.
(2) KLUE ODQA
retrieval한 wiki 문서에 대해 질문 query와 답변을 내놓을 수 있는 부분을 찾는 작업
문서를 모두 읽고 가장 가능성이 높은 부분을 답으로 설정해야 하기 때문에 많은 양의 문장이 문서에 들어가주어야 했다.
여기서도 RoBERTa-large 모델을 사용해 처음에 32 batch size를 사용했다.
모델 자체가 layer가 24나 되기 때문에 꽤나 무거운 모델이었다.
따라서 모델이 정확하면서도 빠르게 분석을 할 줄 알아야했기에 AMP 기법을 차용해 속도를 높이고자 했다.
덕분에 batch size를 64로 늘릴 수 있었으며 더 소요시간이 1/2로 감소한 빠른 학습과 성능을 유지할 수 있었다.
✏️ 3) 참고문헌
- 사용법과 간단 정리
- 도움되는 링크
