TIL
1.[NLP | TIL] Negative Sampling과 Hierarchical Softmax, Distributed Representation 그리고 n-gram
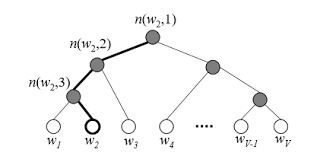
Efficient Estimation of Word Representations in Vector Space 논문을 해석하던 중에 해당 개념들이 나와서 정리하게 되었다. 논문에서 빈번하게 등장하기도 하고 중요한 개념이라 생각된다. 논문에 대한 포스트는 다음 주말 중으로
2.[NLP | TIL] Word2Vec(CBOW, Skip-gram)
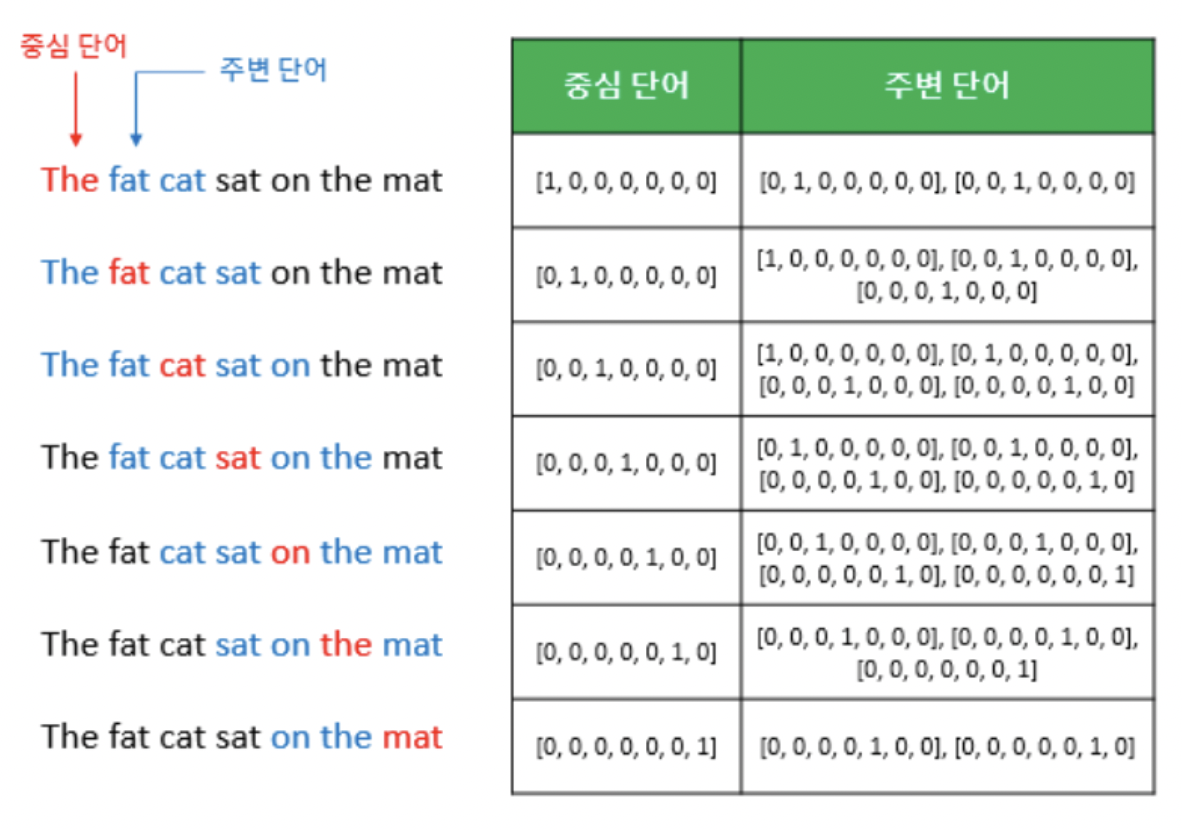
Efficient Estimation of Word Representations in Vector Space 논문에 대한 리뷰를 작성하기 이전에 해당 내용에 대해 먼저 숙지를 한 이후 작성하는 것이 좋을 것 같아 TIL 주제로 선정했습니다. Word2Vec을 기존에 정
3.[ML | TIL] Label Smoothing에 대해 알아보기 (feat. When Does Label Smoothing Help? 논문)
competition 대회를 진행하면서 loss의 설정에 대한 부분을 신경을 많이 쓰게 되었는데 label smoothing과 focal loss를 많이 다루게 되었다.그냥 좋다니까 가져다 쓰는 것 보다는 이해가 선행되는 것이 좋을 것 같아 TIL로 다루고자 한다. 그
4.GloVe(글로브) 개념정리(feat. GloVe: Global Vectors for Word Representation 논문)
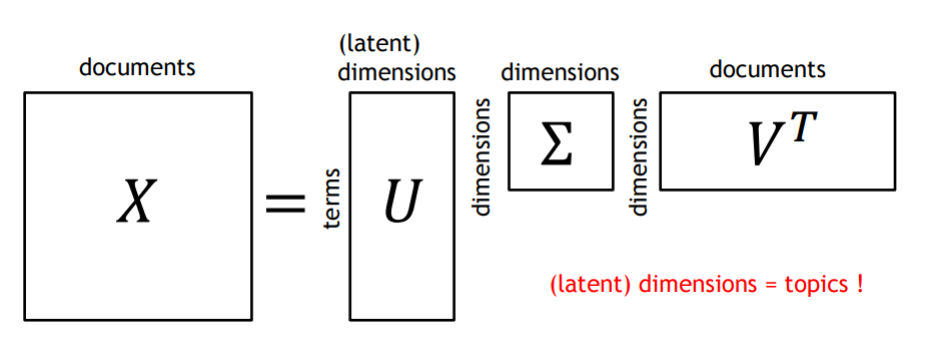
워드 임베딩에 대해서 공부를 하면 자주 등장하는 임베딩 기법으로 GloVe가 등장한다. Word2Vec과 함께 실제로도 가장 많이 사용되며 성능 차이도 거의 없으나 Word2Vec에 비해 개념 자체가 어려워 설명 없이 넘어가는 경우가 많다.본인도 이번 기회에 정리를 해
5.[TIL] Data Manifold 학습이란?

GAN을 학습하다 보면, Data manifold에 대한 개념이 등장합니다. 개념 자체가 간단하면서도 어려워서 정리해보고자 합니다.기존의 auto-regressive model들은 이미지의 픽셀들을 순차적으로 넣어주며 fully connected layer를 통해 학습
6.[TIL] Language Model (feat. Markov Assumption)
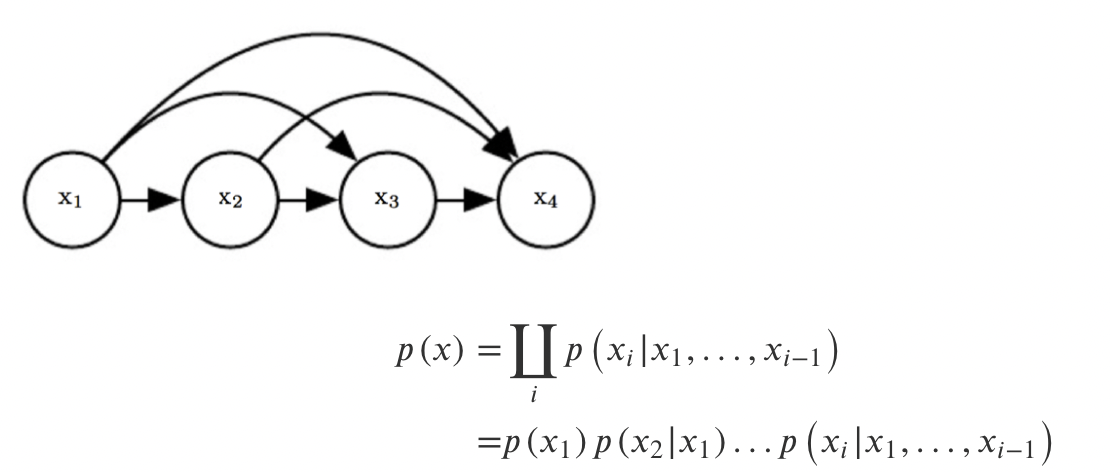
image 혹은 sequence data를 다루는 모델을 공부하다보면, Auto-Regressive라는 개념이 자주 등장한다. 또한, Sequence data를 다룰 때에 parameter를 너무 과도하게 가져가지 않기 위해 Markov Assumption을 이용하기도
7.[TIL] Auto-regressive model (feat. NADE, PixelRNN)
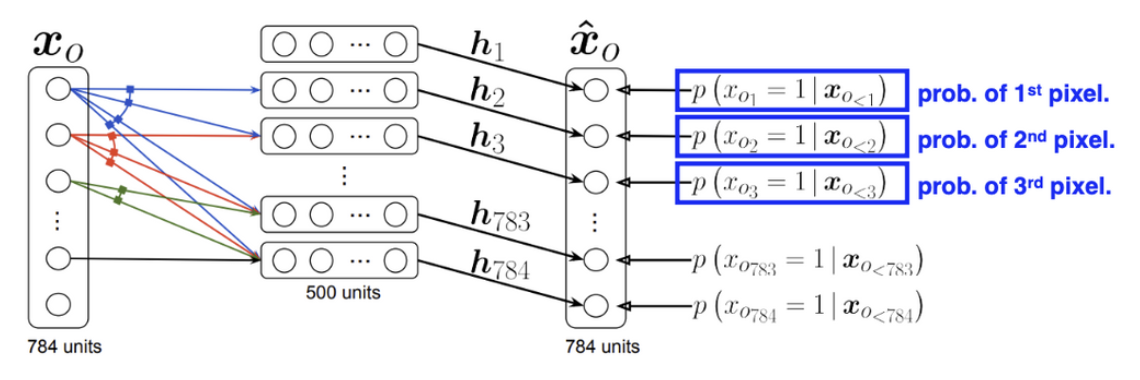
가장 먼저, 28 X 28짜리 binary pixel들로 이루어진 mnist dataset이 있다고 가정해보자. 우리가 하려는 것은 $p(x) = p(x1,... x{784})$를 구하는 것이다. 그러나 p(x)를 이렇게 구하게 되면 너무 작게 나타나고 구하는 것 조차
8.Transfer learning and fine-tuning
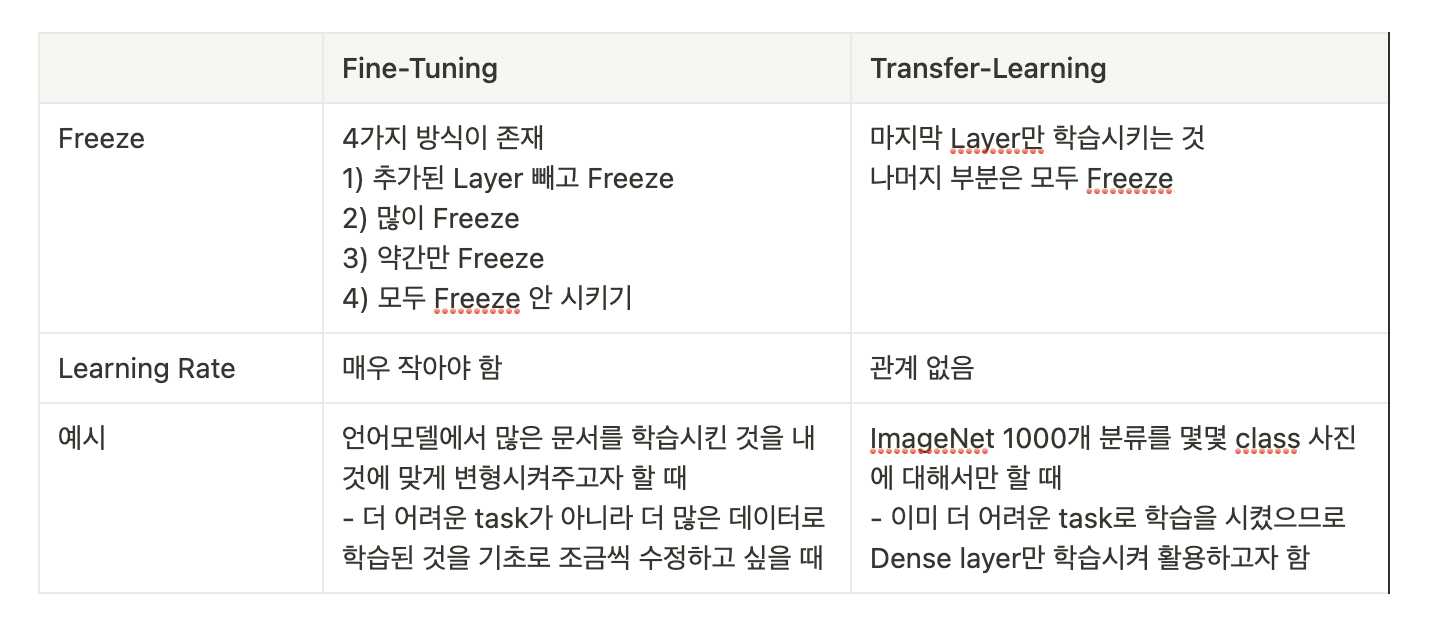
https://d2l.ai/chapter_computer-vision/fine-tuning.htmlKeras 문서를 기반 작성했다. Transfer Learning과 Fine-tuning의 차이에 대해 깊이 있게 다룬 문서가 없어 직접 작성해보았다.Transf
9.Automatic Mixed Precision
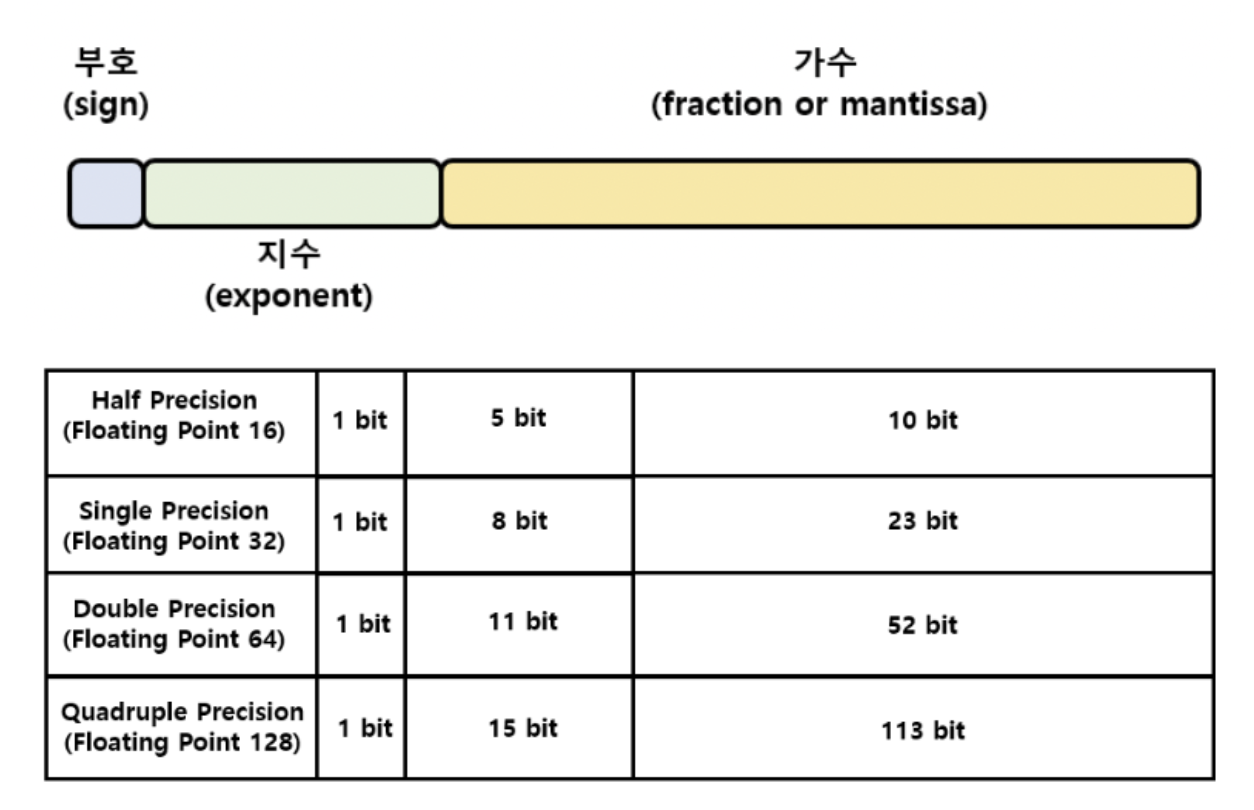
대회를 진행하면서 정말 많이 사용한 방식인데 이에 대해 이해가 부족한 것 같아 내 방식대로 정리해보았다. 종류FP32 (Single Precision, 단정밀도)FP64 (Double Precision)FP128 (Quadruple Precision)FP16 (Half
10.Self Training Methods란?
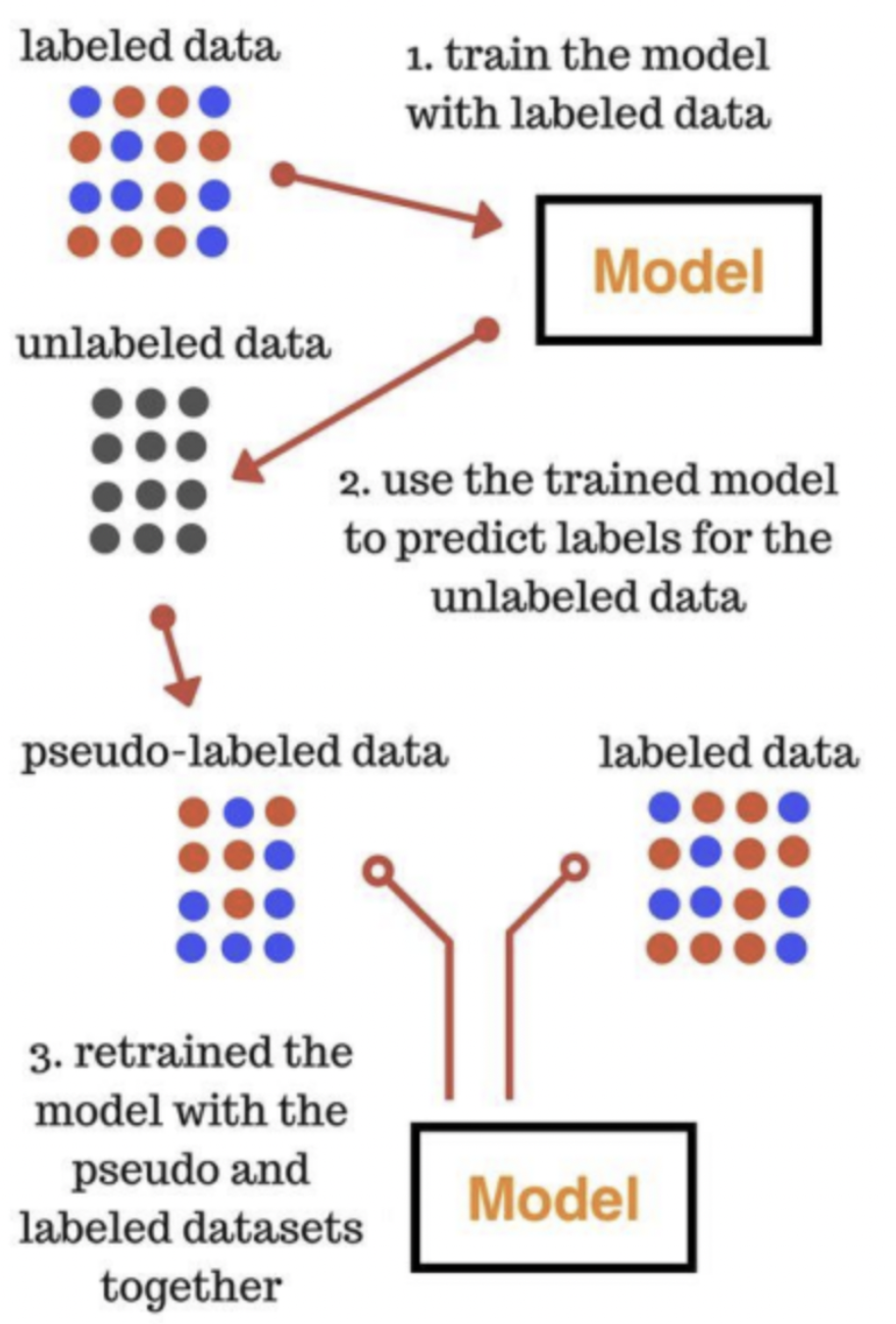
Self-training methods 방식은 대표적인 ELMo, GPT, BERT 모델들을 학습시키는 방식높은 확률값이 나오는 데이터 위주로 다시 학습에 가져가겠다는 것. 예를들어 로지스틱 회귀분석(logistic regression) 결과 한 데이터에 대한 1일 확
11.Transfer Learning과 Fine-Tuning
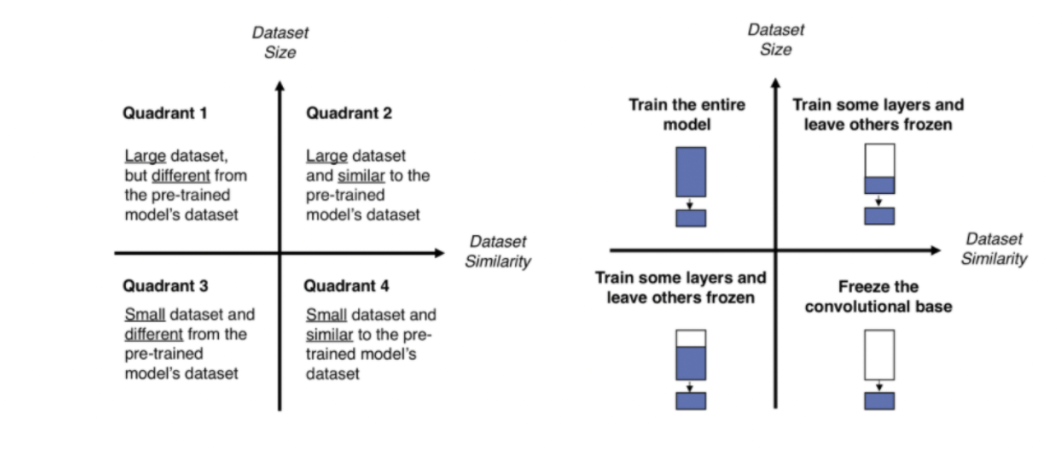
fine-tuning을 두 번 한다는 것이 가능한가? 그것을 전이학습(Transfer Learning)이라고 할 수 있는가? 그렇게 된다면 효과가 무엇인가라는 질문으로 시작해 둘에 대한 정의와 공통점 및 차이점을 공부하는 시간을 가졌습니다.해당 내용은 노션에 정리한 것
12.Cross-Encoder와 Bi-Encoder (feat. SentenceBERT)
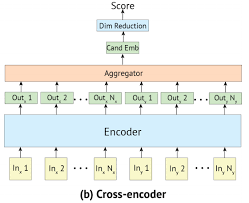
💡 개요 곰파다 프로젝트를 하면서 문장 간 유사도를 계산하는 모델을 구성할 때에 Bi-Encoder 구조 중 하나인 SentenceBERT를 사용해 학습시키고자 했다. 당시에 Cross-Encoder와 Bi-Encoder 방식을 사용할 때 성능 뿐만이 아니라 속도
13.How to implement Dynamic Masking(feat. RoBERTa)
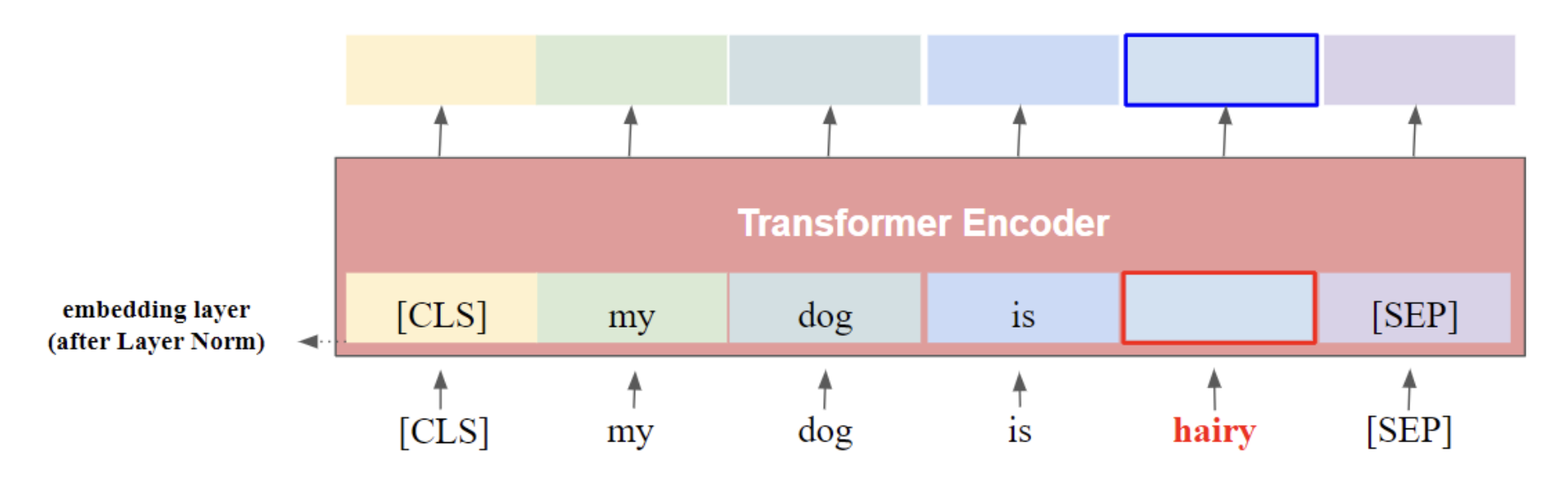
RoBERTa 논문에서는 기존에 MLM과는 다른 masking인 dynamic masking을 사용한다고 말한다. 기존 MLM은 계속 동일한 단어를 epoch마다 예측하기에 의미 없는 단어를 계속 masking하고 있을 수 있으며 overfitting이 발생할 수도 있
14.[TIL] Inductive Bias 란?
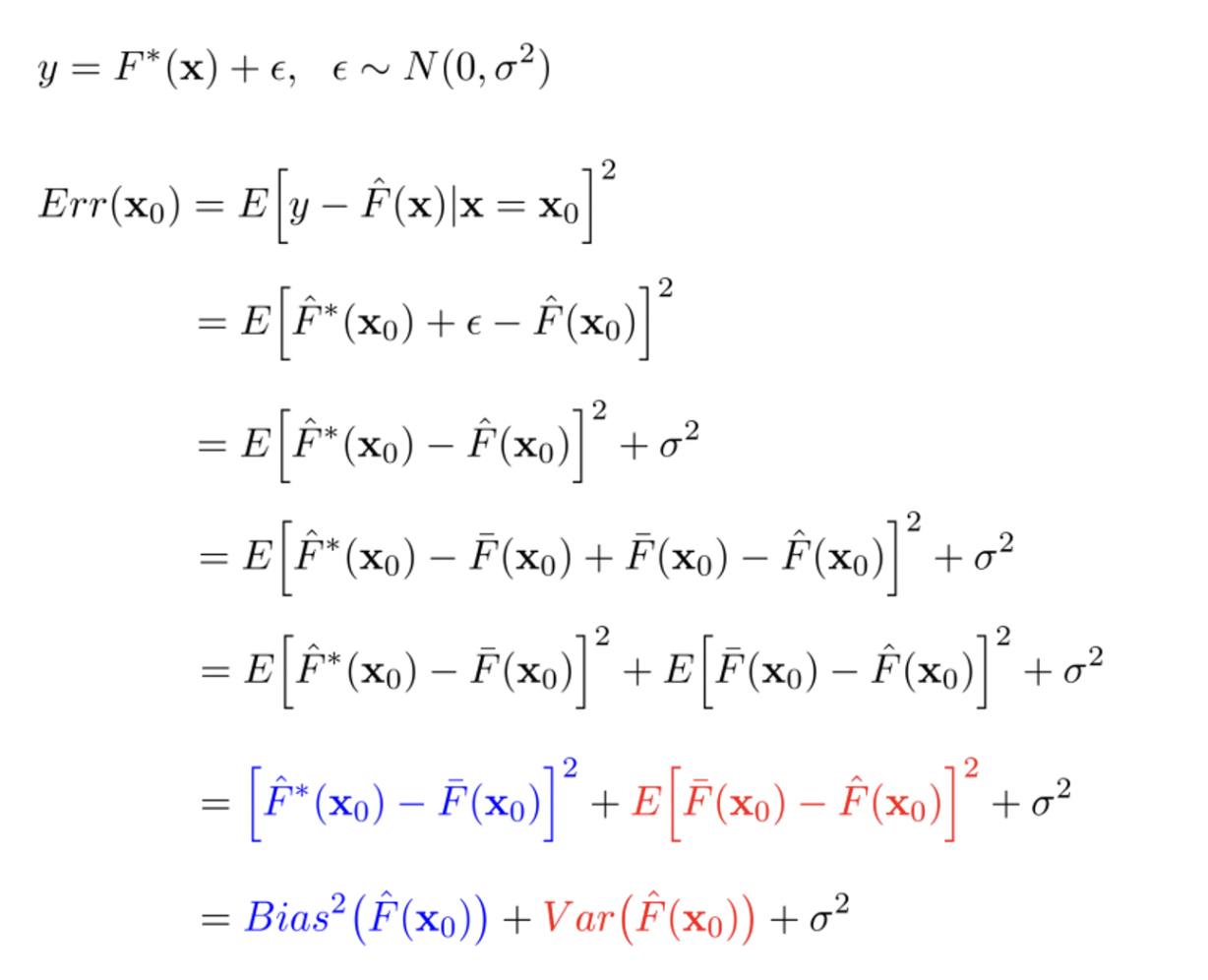
AlexNet과 ViT 논문을 읽다보면 Inductive Bias라는 것이 자주 등장했다. 해당 개념을 알 것 같으면서도 확실히 설명하는 것이 어려워 직접 정리를 한 번 해보고자 했다. 이 포스트를 작성하며 euisuk-chung님과 BaeMI님의 블로그를 많이 참고했
15.[TIL] Focal Loss, Class-Balanced Loss
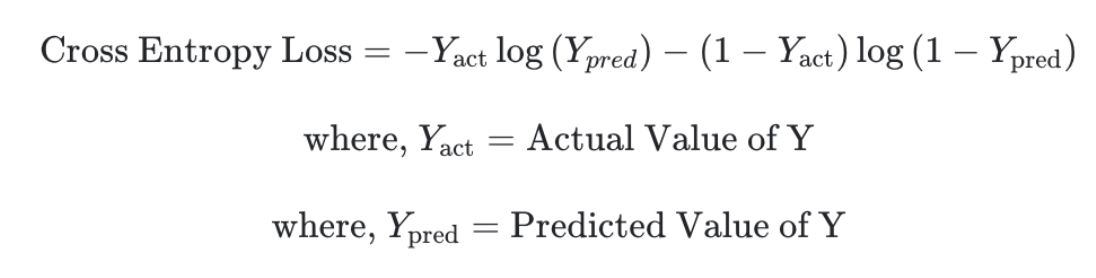
얼마전에 인턴으로 입사하게 된 회사에서 가장 처음 맡게 된 업무는 불균형한 데이터와 multi label을 위한 focal loss 제작 업무였다. 이를 위해 발표 자료를 정리하는 겸 해당 내용에 대해 정리를 해보았다.생각보다 잘 이해하고 있다고 생각했지만 늘 그렇듯,
16. [TIL] Contrastive Learning
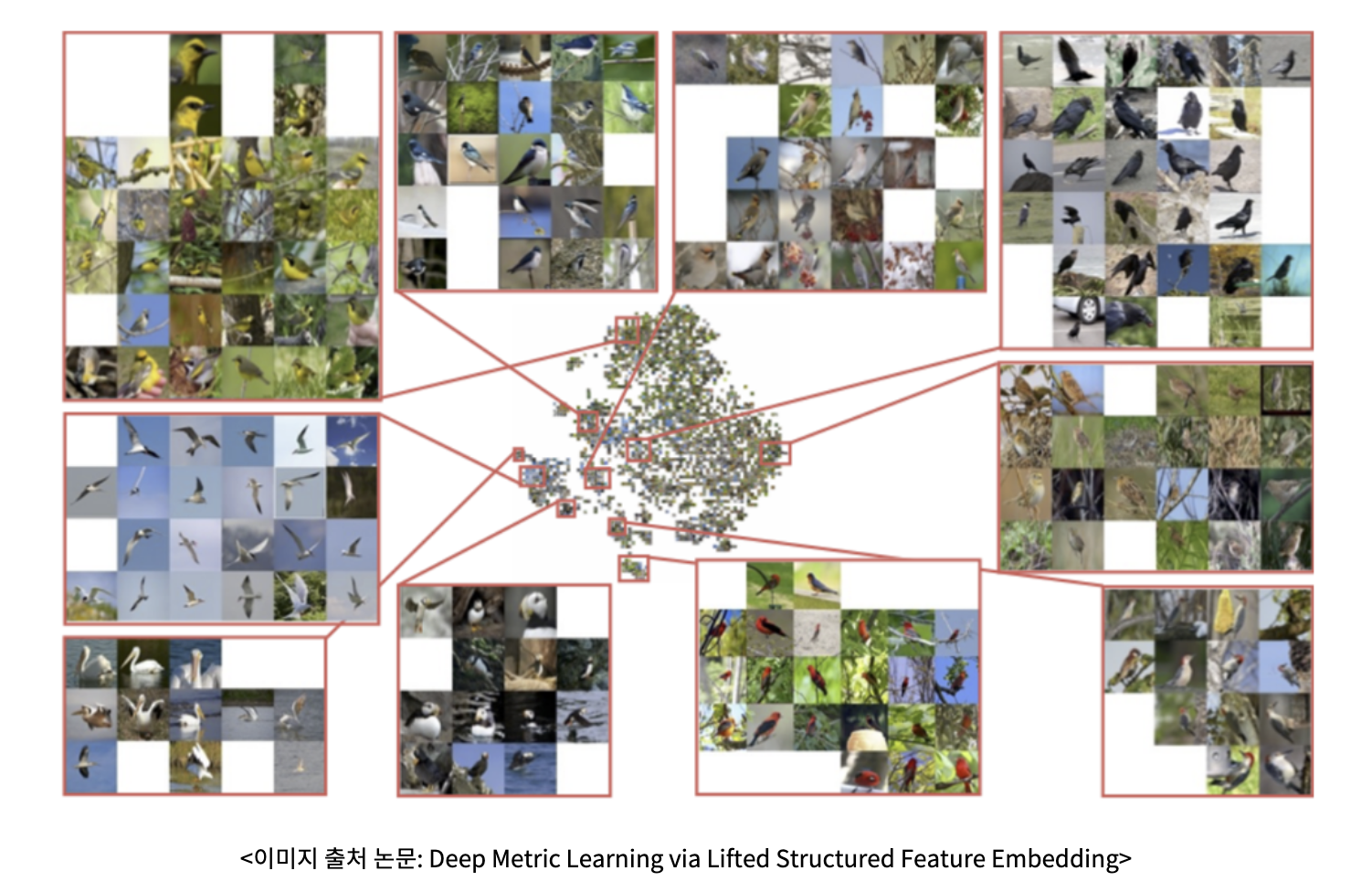
Contrastive Learning은 간단하게 말하면 유사도가 높은 것은 가깝게 유사도가 낮은 것은 멀리 가도록 학습을 진행하는 것이다. 주로 self-supervised learning에서 사용된다.예를 들어, 이미지 x를 augmentation 시킨 $x^\*$가