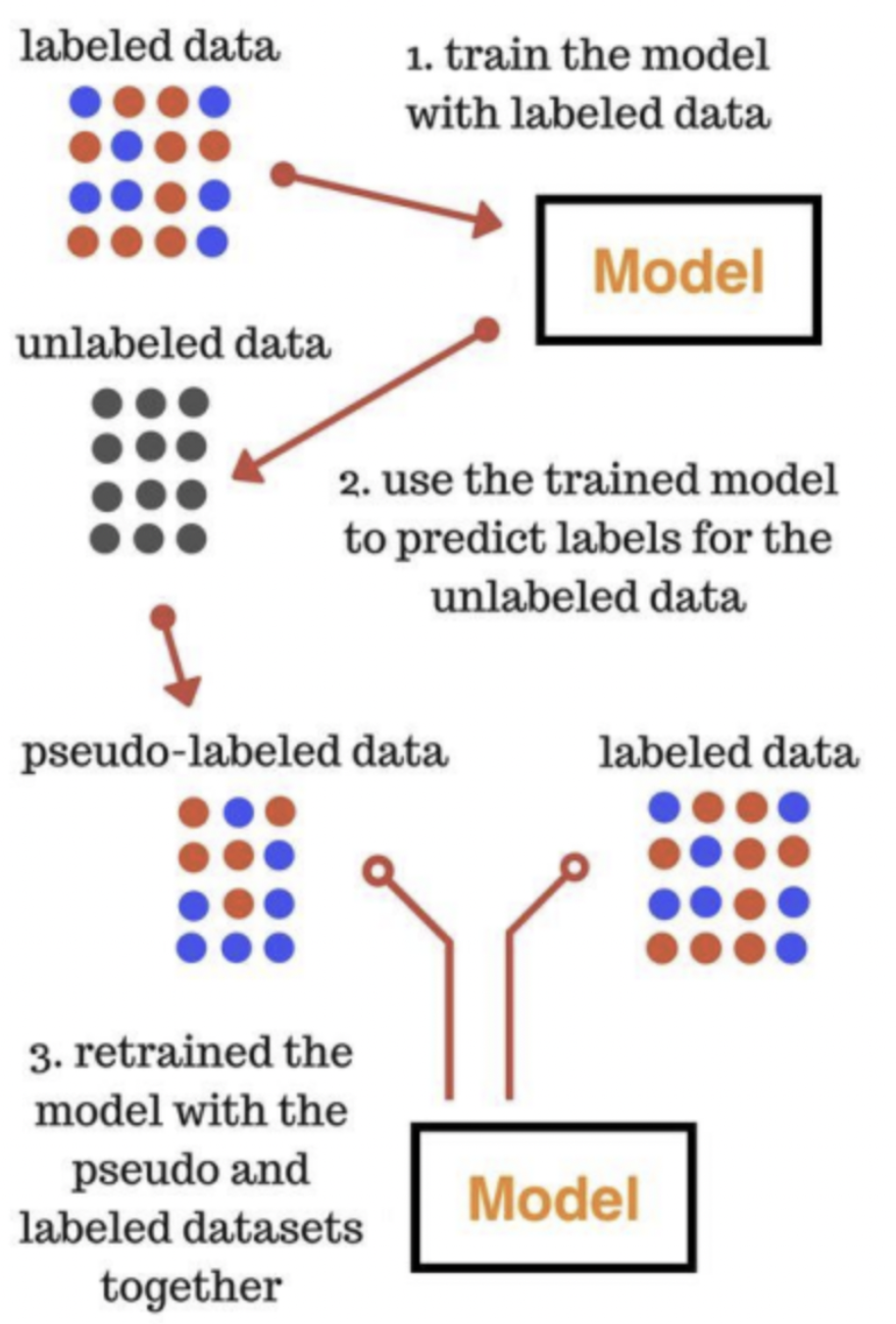
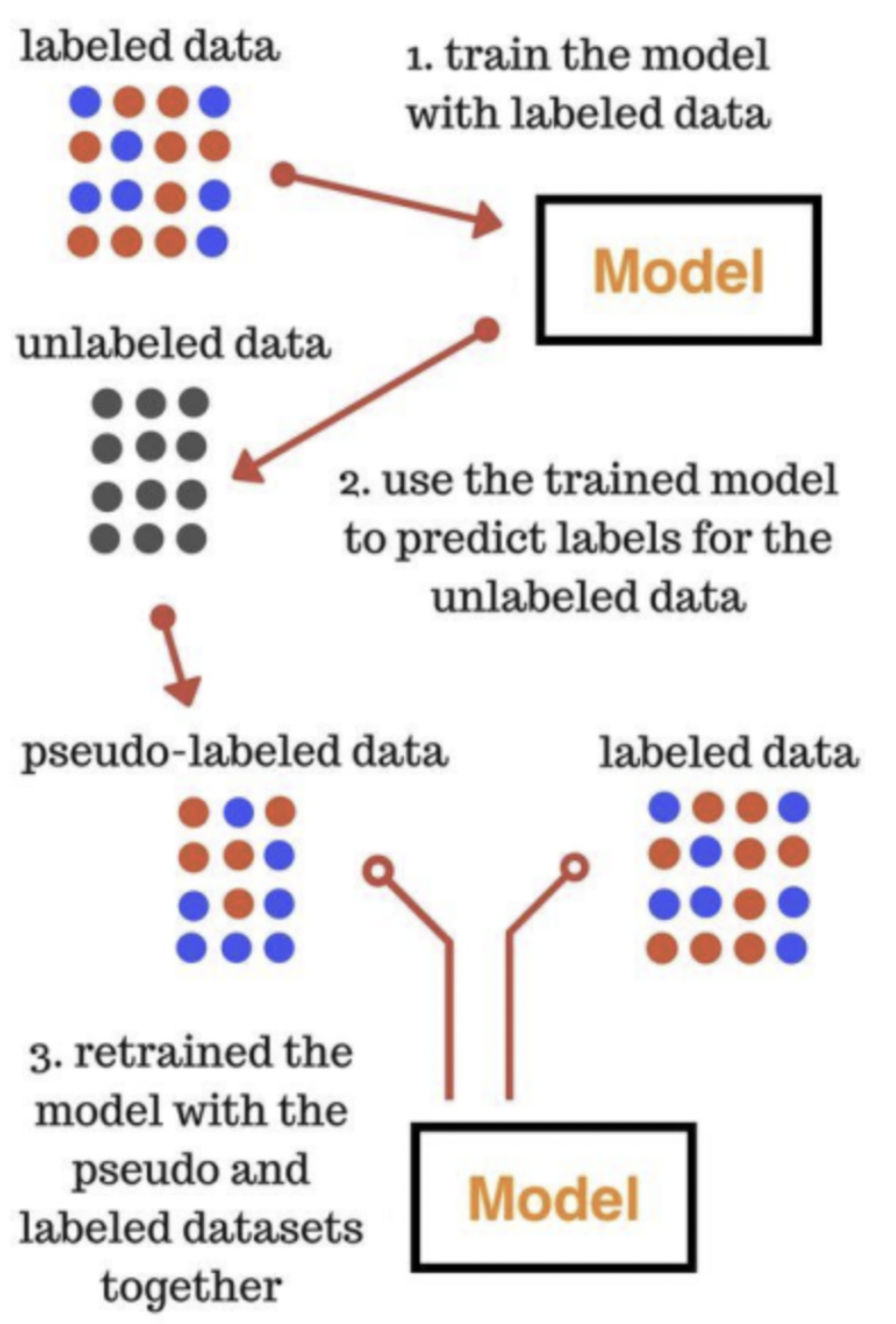
Self-training methods 방식은 대표적인 ELMo, GPT, BERT 모델들을 학습시키는 방식
높은 확률값이 나오는 데이터 위주로 다시 학습에 가져가겠다는 것.
예를들어 로지스틱 회귀분석(logistic regression) 결과 한 데이터에 대한 1일 확률값이 0.95가 나온 경우가 있고 0.55가 나온 경우가 있다면, 0.95로 예측한 데이터를 가져간다는 뜻.
즉, 예측을 진행하고 예측에서 높은 확률이 나오면 그 데이터를 labeled data로 치환하고 그렇지 못한 데이터들에 대해서 학습을 시키는 것
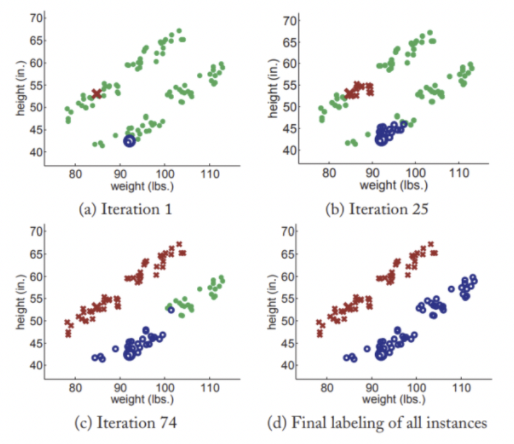
이런 방식은 outlier에 대해서 취약할 수 있다.
ex) k-nearest neighbor 모델
k = 1에 넣고 데이터를 하나씩만 제공
iter가 반복됨에 따라 정확하게 분류
하지만 Outlier(혹은 Nosie)가 있다면?
아래 그림처럼 될 수 있다
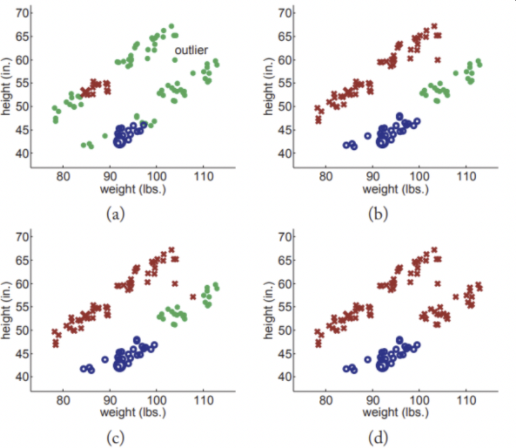
🚀 결론
장점
- 가장 간단한 준지도학습(semi-supervised learning)이다.
- 어떤 알고리즘이라도 적용 가능하다(wrapper method).
- NLP 같은 분야에서 종종 쓰인다.
- 왜냐하면 label이 명확하지 않은 데이터셋이나 labeling이 다르게 된 데이터셋에 대해서 하나로 만들어 학습을 시킬 수 있기 때문
단점
- 초반에 잘못 저지른 실수(early mistakes)가 잘못된 길로 인도할 수 있다.
- 완전히 수렴(convergence)한다고 딱 말할 수 없다(Cannot say too much in terms of convergence)
- 모델의 결과가 local minia에 빠질 수 있기 때문

프리미어와 IDE만 있다면 무엇이든 만들 수 있어