[NLP | 논문리뷰] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding 하편
논문리뷰

상편을 쓰고 귀찮아하는 제 표정 절대 아닙니다.
앞의 WordPiece와 BERT 상편에서 이어지니 보고 오시는 것을 개인적으로 추천드립니다.
🔬 Experiment and Result
BERT는 총 11개의 NLP 분야에서 학습을 시켰고 이들을 종합해서 평가하고 있다. 직전에 나온 모델이 ELMO와 GPT-1이기 때문에 둘과의 비교가 상당히 많다.
GLUE
GLUE는 General Language Understanding Evaluation의 약자로 다양한 분야의 general language understanding task를 포함하고 이를 평가하고 있다. GLUE에 맞추어 fine-tuning하기 위해 추가해준 것은 분류에 있어서 결과 개수에 따른 가중치 행렬 변화 밖에 없다.
32개의 batch size를 사용했고 3epoch을 통해 핛브했다. lr rate는 5e-5, 4e-5, 3e-5, and 2e-5로 설정해주었다.
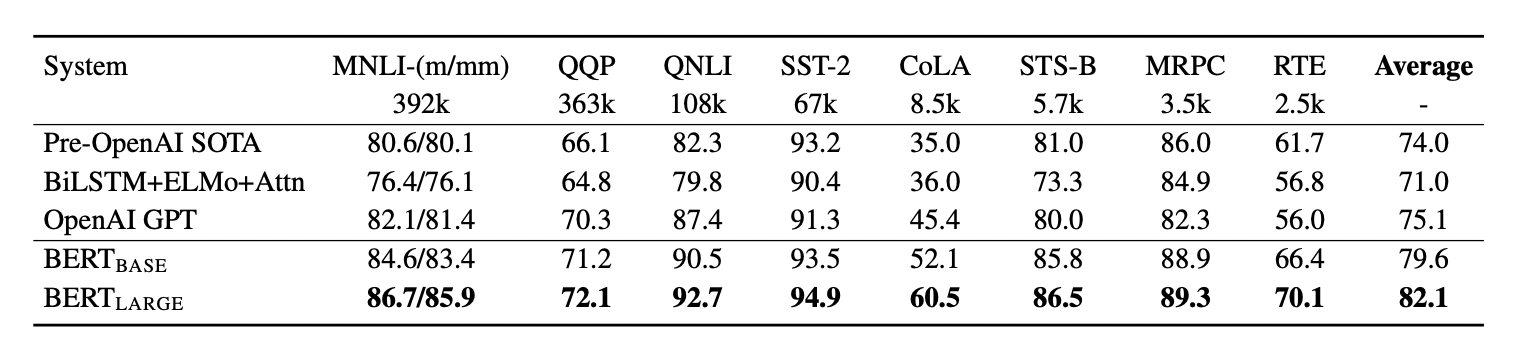
실험 결과 BERT Base,Large 모두 기존의 방법보다 좋은 성능을 보이고 있다.
SQuAD 1.1
SQuAD의 경우, Question, Answer로 이루어져 있는 데이터셋 Pair가 학습을 진행하게 된다. 위의 pre-train처럼 각 문장쌍을 하나의 Sequence로 넣게 되었고 answer가 시작할 때 S token과 마지막에 E token을 넣어주었다. 그리고 [SEP] token을 주지 않게 되는데 모델은 어디서부터 어디까지가 answer의 영역인지 구한다.
마지막의 hidden state에서 특정 단어 토큰 이 start toke이 될 score는 S와 의 dot porduct 결과로 나타나게 된다. End token 역시 E와 의 dot product 연산을 진행한다.
그리고 softmax를 구해주어 가장 높은 값을 찾는다.
start token S 로 부터 end token E 까지가 answer 일 score 는 S·Ti + E·Tj 로 계산된다.
그리고 j ≥ i 인 후보 중에서, 가장 값이 큰 <i, j> 쌍을 answer 의 영역으로 predict 한다.
결과적으로 목적식은
가 된다.
Loss 는 올바른 start 와 end position에 대한 sum of log-likelihoods 를 사용한다.
google은 3epoch, learning rate 5e-5, batch size 32 를 사용했다 한다.
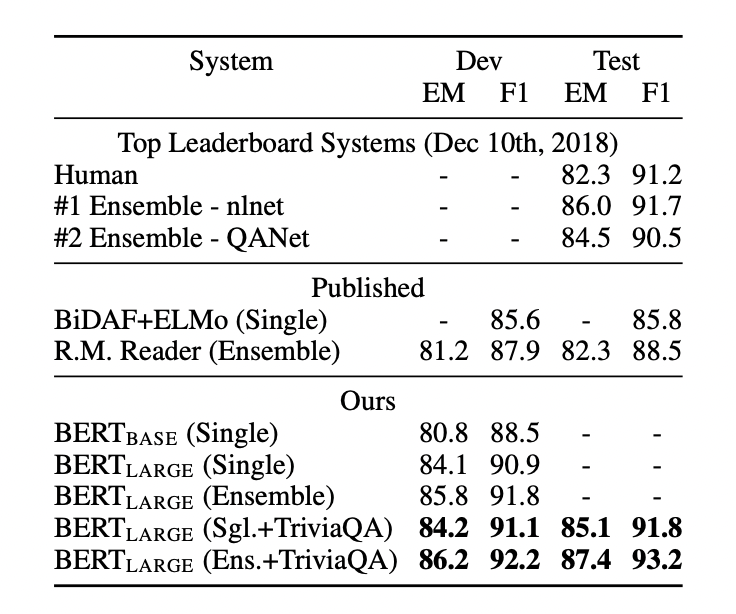
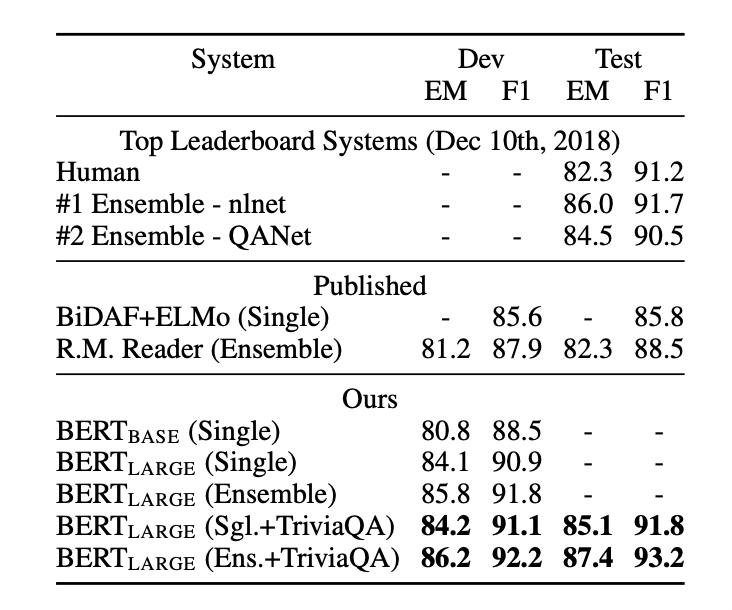
성능은 역시나 최고의 수준을 보이고 있다.
SQuAD 2.0
세번째 실험은 SQuAD 2.0 dataset을 통해 진행했다. SQuAD 2.0은 답이 지문에 없는 즉, 대답할 수 없는 경우를 포함하고 있어 SQuAD보다는 조금 까다로운 Dataset이다. 그리고 그런 경우에는 CLS token에 결과가 나타나게 된다.
인간의 능력에는 미치지 못하였지만, 기존의 baseline에 비해서는 매우 우수한 성능을 확인할 수 있습니다. 이것을 예측하는 수식은 답변이 있는 문장이라면, 기존 수식과 동일하게 진행한다.
대답 불가능한 경우에는 가 보다 작게 되는데 이를 통해 예측하게 된다. 이때 수식을 그대로 사용하는 것이 아니라 상수 r 이 추가된다. 결과적으로 이는 과 결합해 threshold로 활용된다.

성능은 인간의 능력에는 조금 부족하지만 전문가에 필적하는 성능을 보여준다.
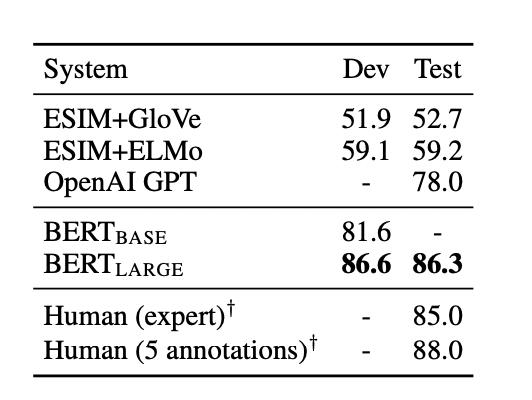
SWAG
The Situations With Adversarial Generations (SWAG)이라고 불리는 방식은 앞 문장이 주어지고, 보기로 4 문장이 주어진다. 그 주어진 문장중에서 가장 잘 어울리는 문장을 찾는 sentence pair inference task 이다.
Fine tuning 하기 위해, 앞 뒤 문장중 가능한 경우의 수의 문장들을 묶어 하나의 데이터로 만든다. 이때 앞 문장을 embedding A, 뒤 문장을 embedding B로
그 이후 GLUE 를 학습할때와 동일하게 CLS token 에 대응하는 token C 와 A 문장 이후에 나타나는 문장의 token의 dot product 한다. 이를 score 로 삼고, softmax 로 normalize 한다.
결과적으로 softmax 가 만든 확률로 classification을 진행해 가장 어울리는 문장을 찾게 된다.
📕 Ablation Study
인공지능, 특히 머신러닝 분야에서, ablation이란 학습이 사용되는데 AI 시스템의 일부를 제거한 것이다. 이를 통해 제거한 부분이 전체적인 시스템의 성능에 기여하는 바를 연구하는 것이다.
좀 더 직관적으로 말하면 제안한 요소가 모델에 어떠한 영향을 미치는지 확인하고 싶을 때, 이 요소를 포함한 모델과 포함하지 않은 모델을 비교하는 것을 말한다. 이는 딥러닝 연구에서 매우 중요한 의미를 지니는데, 시스템의 인과관계(causality)를 간단히 알아볼 수 있기 때문이다.
여기서는 NSP(Next Sentence Prediction), model size, feature-based Approach with Bert 이렇게 세가지로 나눠서 Ablation Study를 진행했다.
여기서 눈여겨 볼 점은 fine-tuning이 아닌 feature-based BERT 모델에 대한 것이다. Feature-based로 진행했을 때는 아래와 같은 실험으로 진행되었다.
Feature-based approach는 아래의 경우를 모두 고려하여 실험을 진행했다
1)Embedding만 사용
2)두번째 부터 마지막 Hidden을 사용
3)마지막 Hidden 만을 사용
4)마지막 4개의 Hidden을 가중합
5)마지막 4개의 Hidden을 concat
6)모든 12개의 층의 값을 가중합
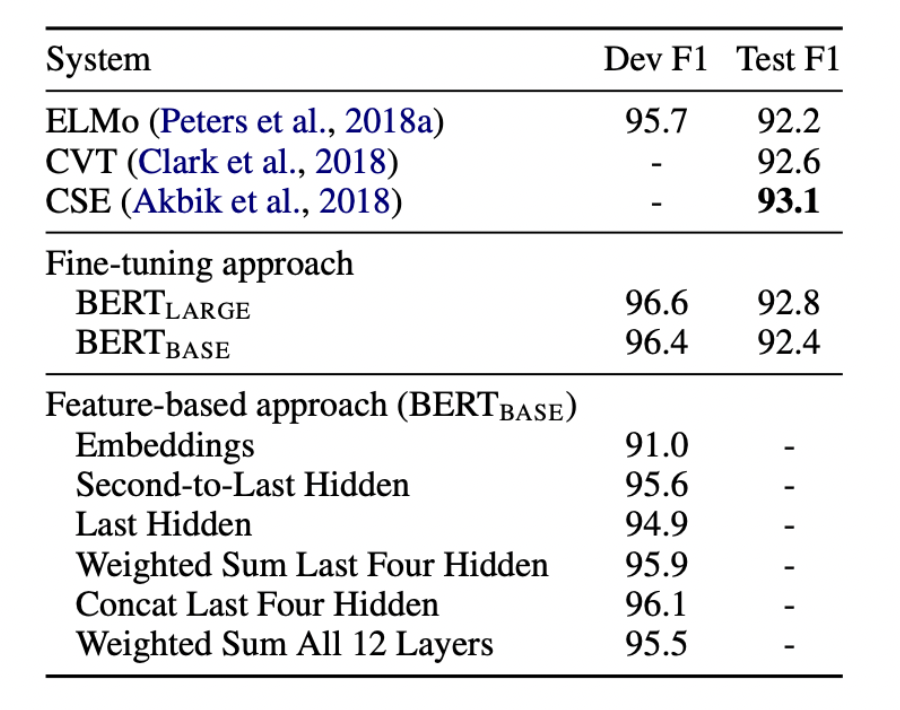
결과를 살펴보면, 전체 layer를 가중합 하는 것 보다 마지막 4개만을 layer를 concatenate하는 방법이 가장 성능이 좋았다.(미세한 차이이기는 하지만) 또한 fine-tuning의 성능과도 거의 차이가 없었다는 점이 인상깊다.
하지만 최근의 트렌드가 점점 fine-tuning으로 변화하는 이유는 그것이 성능이 더 좋기 때문도 있지만 학습에 대한 cost가 낮기 때문이다. feature-based는 위처럼 모델 자체를 task에 맞게 변형시켜주고 학습시켜야 하기 때문에 부담이 크다.
✏️ BERT 리뷰를 마치며
Transformer 논문을 일주일동안 4편을 통해 리뷰를 해서 그런지 BERT 논문은 비교적 쉽게 느껴졌다. 여전히 인기가 많은 모델이고 fine-tuning에서도 선호되기 때문에 BERT 구조를 뜯어보며 학습할 수 있었던 점에서 학업적으로 도움이 많이 되었던 것 같다.
GAN도 리뷰를 해야 하는데 요새 정신이 없어서 얼른 해야지,, 말만 하지 말고 해야겠다..
