
출처 : 추억의 sakeL
BERT 논문에서 가장 많이 등장하고 관련된 논문인 ELMo 논문. 두 논문 모두, 당시 NLP에서의 한계점이었던 단어 예측에 있어서의 돌파구를 마련하기 위한 노력이었다.
ELMo의 경우, 2018년 논문임에도 불구하고 당시 인기를 끌었던 Transformer를 완전히 배제한 모형이여서 신기했다.
그럼에도 양쪽 방향을 읽어서 문맥을 보다 잘 파악하고 이를 통해 돌파구를 찾으려고 했다는 점이 인상 깊었다.
💡 전체적인 내용
ELMo 논문은 문맥을 반영한 새로운 임베딩 방식을 제안했다. 당시 모델들은 하나의 단어에 대해 하나의 vector로의 표현만을 가지기 때문에 여러 단어의 의미를 포함할 수 없었다. 예를 들어, state라는 단어에 '주'라는 의미와 '주장'이라는 의미를 동시에 표현하지 못한다는 것이다.
ELMo는 이러한 문제를 문맥적 특성을 반영한 단어 vector로의 변환을 통해 해결하고자 했다. 이를 위해 앞, 뒤 두 방향으로 문장을 읽는 biLSTM을 사용했으며 총 3개의 layer를 통해 임베딩을 하고자 했다.
각 biLSTM은 문장을 읽어나가며 vector를 만들어내고 softmax-normalized weight와 선형변환을 통해 하나의 벡터를 만들어낸다. 결과적으로 이 하나의 벡터는 단어의 문맥적 의미를 담고 있기 때문에 context-dependent하므로, 그 문장 내에서의 의미를 담고 있을 수 있다.
🎯 들어가기 전, ELMo와 BERT
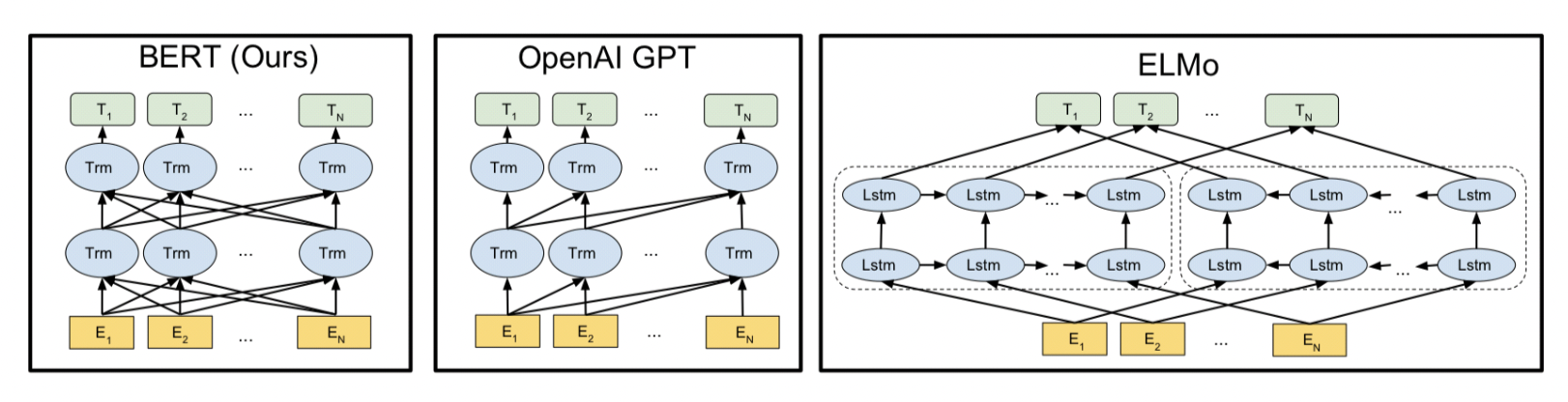
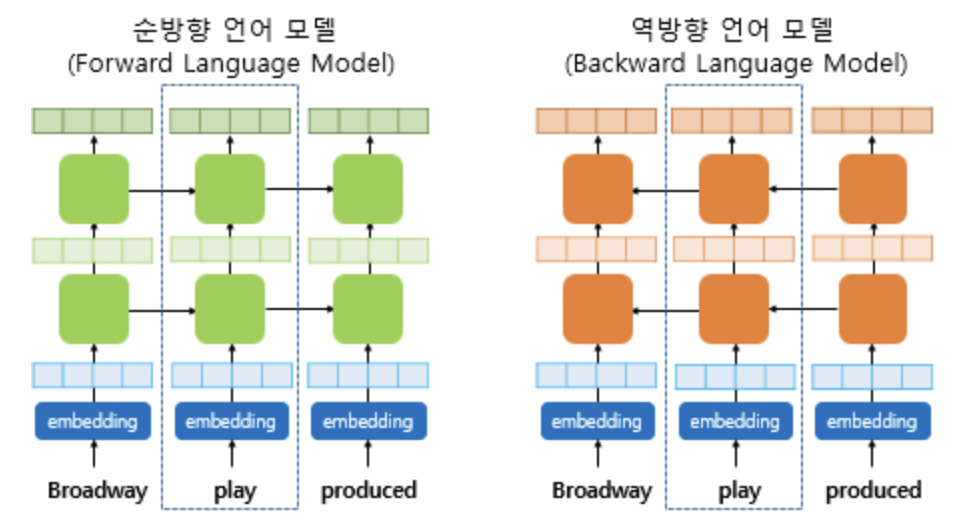
BERT가 나타나기 이전 ELMo 모델과의 차이를 한 눈에 볼 수 있는 그림이다. ELMo의 경우 임베딩을 위해 각각의 LSTM 모델이 사용되는 반면에 BERT는 하나의 모델이 여러 방향으로 읽어나가며 임베딩을 하게 된다. 또한 BERT에는 ELMo와 다르게 Transformer를 사용해 단어와 단어 사이의 관계를 파악하고자 했다. BERT의 자세한 내용은 이전 BERT 논문 리뷰를 참고하시면 된다.
📕 ELMo의 Bidirectional Language model
일반적인 언어모델은 다음과 같은 흐름으로 진행된다. input 를 받은 상황에서 output 를 예측하기 위해 아래의 조건부 확률을 통한 식으로 진행된다. NLP에 대해 학습하신 분이라면 많이 익숙할 것이다.
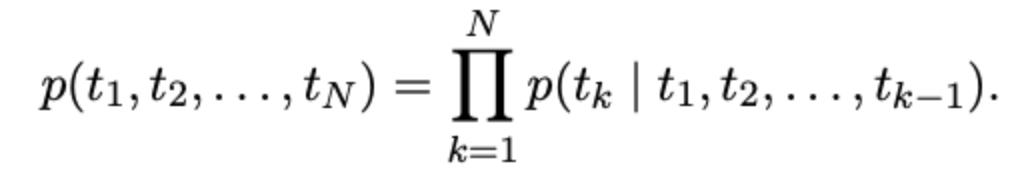
ELMo가 나오기 이전에는 CNN을 통해서 각 단어에 대해 문맥에 독립적인 token 표현 를 만들고 그것을 L개의 Layer로 이루어진 LSTM으로 보내는 것이었다.
ELMo도 이와 비슷한 형식을 반영하는데 Embedding된 를 하나의 LSTM으로만 보내는 것이 아니라 두 개의 LSTM으로 보낸다. 역방향으로 읽는 LSTM이다. 해당 model의 목적식은 아래와 같다.
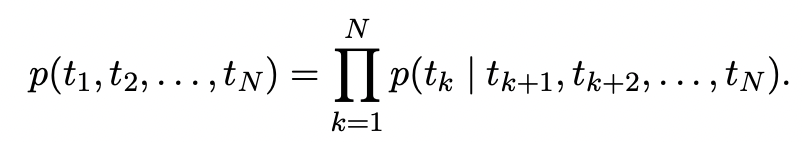
이렇게 만들어진 두 식을 종합해서 log 가능도가 최대가 되는 것을 구하게 된다. 즉, 양방향을 고려했을 때의 최대 가능도를 가지는 단어를 예측하는 것이다.
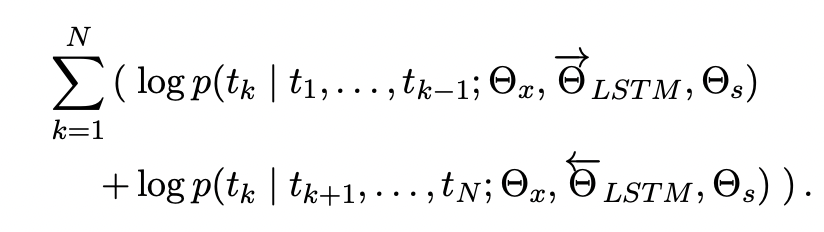
이때 식을 보면 기존 목적식과 다른 식들이 존재한다. 는 token representation(t1,...,tNt1,...,tN)에 대한 parameter이고, 는 softmax layer에 대한 parameter이다.
이 두 parameter는 전체 direction에 관계 없이 같은 값을 공유한다. 즉, 임베딩과 softmax는 동일한 값을 사용한다는 것이다. 하지만 이들을 제외한 LSTM의 parameter들은 두 LSTM model이 서로 다른 값을 갖는다.
🛠 ELMo
위의 방식으로 구현된 모델의 모습이다.
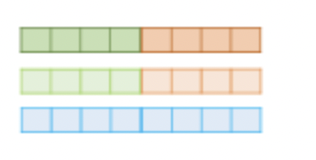
ELMo에서는 기존과는 다른 문맥을 반영하는 representation을 사용하는데, 이를 얻기 위해서는 LSTM layer의 개수를 L이라고 했을 때 총 2L+1 개의 representation을 concatenate해야 한다. input representation layer 1개와 forward, backward LSTM 각각 L개이다.

그리고 각 token에 대한 2L+1개에 대해 softmax-normalized weight 를 곱해주게 된다.
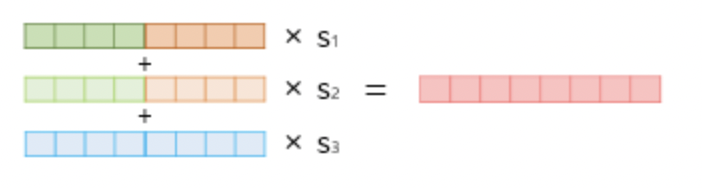
결과적으로 단일한 벡터로 변환되게 되고 이것에 대해 출력 dimension을 맞춰주기 위해 를 곱해주게 된다. 해당 파라미터는 optimization 과정에서 중요한 혁할을 수행하게 된다.
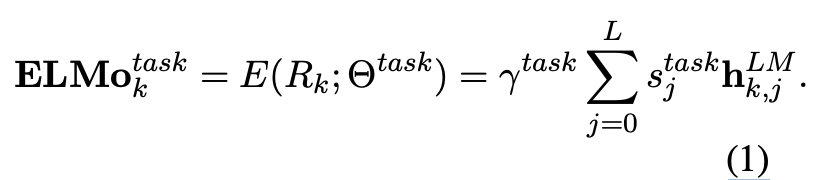
🐣 ELMo를 지도 학습에 활용하기
보통의 언어 모델들은 lower laye에서 먼저 문맥으로부터 이미 학습된 모델을 통해 독립적인 단어의 표현들로 임베딩하고 그것에 대해서 RNN, CNN, LSTM과 같은 모델들이 문맥을 담고 있는 표현으로 만들어준다.
그렇기에 ELMo를 추가하기 위해서는 먼저 pre-trained된 ELMo를 합쳐주기만 하면 되는 것이다. 먼저, ELMo를 지도 모델에 합치기 위해 ELMo의 weight들은 모두 freeze시킨다. 즉, ELMo model은 NLP model이 train될 때 함께 train되지 않는다.
NLP model의 input layer와 다음 layer 사이에 ELMo를 삽입한다. 이후 ELMo 이후 layer에서는 input을 [ 를 사용한다. 이런 방식으로 기존 input과 문맥으로 고려한 input 두가지를 모두 볼 수 있는 것이다.
몇몇 특정 task에서는 RNN의 output 를 [; ] 로 교체했을 때 더 좋은 성능을 보이기도 했다.
또한 일반적으로 dropout과 정규화 방식을 사용했을 때 더 좋은 성능을 보였다.
🛠 ELMo의 세부 구조
앞선 논문들과 유사한 pre-trained biLMs 구조이지만 양방향 학습을 보다 잘 하기 위해 residual connection을 LSTM layer 사이에 추가해주었다. 또한, 모델의 성능을 유지하면서 학습 시간 단축을 위해 단어 embedding과 hidden demension을 앞선 논문에서의 반으로 이용했다.
논문에서 다루는 최종 모델은 2개의 LSTM 층(L=2)만을 사용했다. 각 층은 4096 개의 unit과 512 차원의 출력을 갖고 있다. 또한, 첫 번째 층과 두 번째 층을 residual connection으로 연결하고 있다.
처음 임베딩을 시키는 문맥으로부터 자유로운 word embedding은 2048 character n-gram convolution filter를 사용했고, 2개의 highway layer를 추가적으로 사용했다.
최종적으로 512 차원의 출력을 제공한다. 이러한 구조를 기반으로 biLM은 입력에 대해서 총 3개의 representation을 생성하게 된다.
Forward perplexity와 backward perplexity 는 거의 유사한 수치를 보였으나, backward perplexity가 조금 더 낮게 측정되었다.
✏️ 후기
BERT 논문을 읽은 이후 리뷰하는 ELMo 논문이기에 BERT보다 치밀함이 떨어지는 느낌이 들었다. 또한, 구조에 대한 그림이 논문에 삽입되어 있지 않고 설명도 어려워서 리뷰가 쉽지는 않았다.
몇몇 부분은 내용 자체가 모호하게 넘어가는데 ex, convolution의 higway layer 등,, 해당 부분은 추가적인 학습을 해야 할 것 같다.
그리고 하편은 주말 내에 작성하기로 약속...
참고 : https://cpm0722.github.io/paper-review/deep-contextualized-word-representations
