드디어 세번째 논문 리뷰이다. Word2Vec 1이라고 불리는 논문이며, one-hot encoding 방식이나 밀집표현 방식에 불과했던 Word Embedding을 보다 효율적으로 그리고 정확도를 높였다는 평가를 받는다.
방식 자체가 어렵지는 않으나 논문에 자세한 설명은 부족해 Word2Vec에 대해 더 자세히 보고 싶다면 이전 포스트를 참고하는 것이 좋을 것 같다.
💡 전체적인 개요
Word2Vec은 기존에 NLP에서 사용되기는 했으나 단어들을 원소적인 객체로만 보는 희소 표현방식(one-hot), 혹은 NNLM에서 사용되는 밀집표현 방식 등과 같은 간단한 방식이 주를 이루었었다.
논문에서는 이러한 표현방식의 한계점을 돌파하고자 NNLM에서 forward를 하기 이전 단어들을 벡터로 변환시키는 부분을 확장해 보다 잘 표현하고자 한다. 방식은 CBOW와 Skip-gram 두 가지가 소개되며 각각 학습 방식이 상이하다. 이들을 통해 단어들을 유사성을 표현할 수 있는 vector로 표현하게 되며 각 vector들을 선형대수적 연산을 통해 target 단어들을 도출 혹은 예측할 수 있다.
결과적으로 두 방식의 학습법은 가중치행렬 W 혹은 W'를 내놓게 되는데 이들을 통해 추후에 단어들을 벡터로 선형변환시킬 수 있다. 이를 다른 모델에 연결시키게 되면 기존의 학습 방식보다 더 높은 정확도를 보이며 특히나 Skip-gram이 다른 방식의 Word embedding보다 높은 성능을 보인다.
💡 Introduction
기존의 NLP에서는 단어들을 원소적 개체로만 보아서 단어들 간의 유사도 등을 측정할 수 없었고 index 역할 밖에 못했다. 그러나 단순성과 robustness로 인해 모델들에 많이 사용되었다. 이들을 기반으로 통계적 NLP에서 사용되는 n-gram 모델 역시 나쁘지 않은 성능을 보이기는 했다.
그러나 이러한 방식으로는 높은 수준의(정제된) 데이터와 corpora의 부족에 따른 단어 예측의 어려움(단어들의 조합은 무수히 많지만 그것을 모두 표현하는 것은 불가능하기에)명확한 한계점을 지니게 되고 이를 돌파하기 위해서는 더욱 진보된 기술이 필요하다.
💡 Goals of the Paper
해당 논문에서 소개하는 방식은 기존의 50-100차원의 벡터와 수백만의 데이터로 버거워하던 방식을 뛰어넘은 많은 데이터를 통해 학습할 수 있는 방법이다. 그리고 유사 단어들끼리는 벡터가 가까우며(cos 거리로 거리를 측정) 이러한 유사도는 다양한 차원으로 측정될 수 있다(의미적, 형태적 등등).
그리고 이는 단순히 단어의 굴절성과 같이 유사한 형태를 가지는 문법의 단어들을 가리는 것도 가능하지만 이런 구조적 차원을 넘어서 의미적 차원까지 확장될 수 있다고 말하고 있다. 그리고 이는 선형대수적 연산도 가능하도록 벡터 표현이 가능하게 한다고 말한다.
이러한 목적성을 위해 이를 위해 단어들 간의 선형 규칙성을 보존하는 모델 구조를 만들고자 했다.
💡 Previous Work
연속 벡터를 통해 단어를 표현하는 것(word embedding)은 이 논문이 처음이 아니다. 대표적으로 NNLM은 Linear Projection Layer와 Non-linear hidden layer를 사용해 단어들을 벡터로 표현하고자 했으며 이를 통해 통계학적인 언어 모델과 결합되어 사용되었다.
NNLM은 이처럼 단어 벡터들을 단어 벡터들은 single hidden layer를 갖는 Neural network에 의해 처음 학습시킨다. 그리고 그렇게 만들어진 단어 벡터들은 NNLM을 학습하는데 사용된다. 해당 논문은 이 부분에 집중해 보다 word embedding을 더욱 효과적으로 그리고 효율적으로 하고자 했다.
🛠 Model Architecture
이 논문에서 소개하는 방식은 LSA 혹은 LDA보다 성능도 좋으며 cost에 있어서도 훨씬 효율적이다. 모델의 복잡도는 파라미터 개수로 측정되는데 정확도를 최대화하면서 연산의 복잡도는 최소화하려는 것이 목적이다. 최종적으로 연산의 복잡도는 아래와 같다.
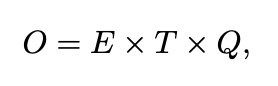
E는 epoch의 수 T는 학습될 단어의 개수 Q는 모델의 구조에 따라 결정된다. 모든 모델은 stochastic gradient descent와 backpropagation을 이용하여 학습되었다.
💡 Feedforward Neural Net Language Model
여기서 나타나는 Feedforward NNLM과 RNNLM은 이후 소개될 CBOW와 Skip-gram 모델의 구조를 소개하며 성능을 비교하기 위해 나타난 것이다. 즉, 이 모델을 소개하는 것이 주된 목적은 아니다.
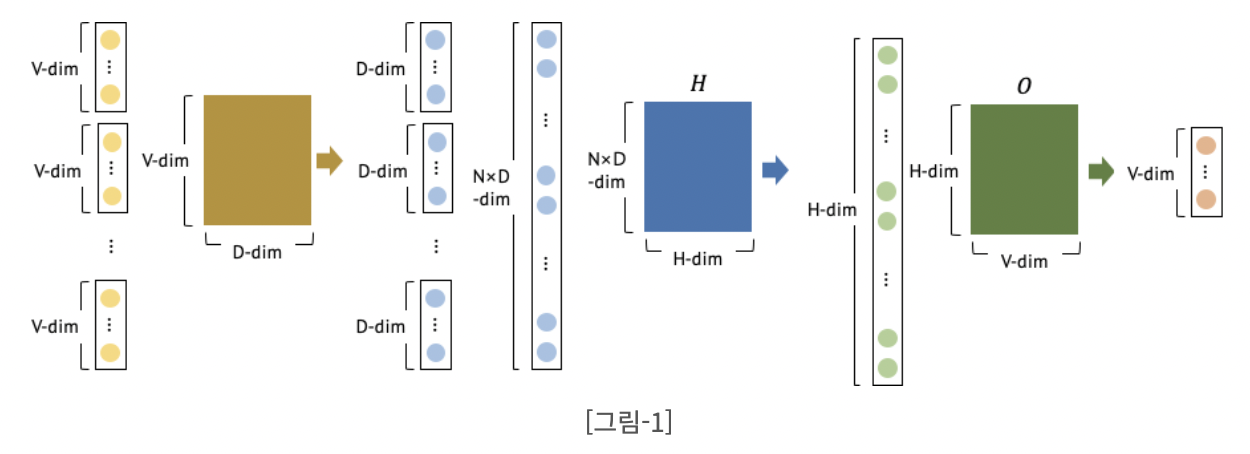
Feedforward Neural Net Language Model은 input, projection, hidden, output layer를 갖는다. 입력층에서는 one-hot encoding된 단어들이 input으로 주어진다. 총 단어의 개수는 V개 그리고 주어진 입력 단어의 개수를 N개라 했을 때(V내의 단어들이 중복 제공될 수 있으므로) 이들은 N x V의 행렬을 이룰 것이다. 이 입력 vector들은 각각 1 x V 형태로 주어지고 V x D projection matrix에 의해 1 x D(최종적으로는 N x D)의 vector로 투영되게 된다. 즉, 각각의 vector들을 모아 하나의 거대한 word 행렬을 만들어주는 것이다.
이렇게 만들어진 N x D 행렬은 다시 hidden layer에 해당하는 D x H 행렬을 만나 N x H 행렬을 출력하게 되고 최종적으로 H x V 출력층을 통해 N x V(각각은 입력과 동일하게 1 x V)로 출력되게 된다. 여기에 soft max를 합쳐서 확률분포로 제공하게 되고 정답과의 cross entropy를 최소화하는 방식으로 이루어진다. 이러한 구조의 cost는 아래와 같다.
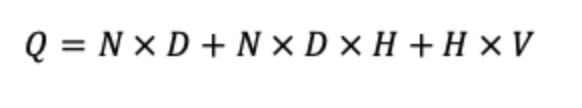
이때 최대 cost는 H x V이지만 hierarchical softmax를 사용해(참고 : https://velog.io/@xuio/NLP-TIL-Negative-Sampling%EA%B3%BC-Hierarchical-Softmax-Distributed-Representation-%EA%B7%B8%EB%A6%AC%EA%B3%A0-n-gram) cost를 H x 까지 낮추어 N x D x H 부분의 cost가 최대가 되도록 한다.
💡 Recurrent Neural Net Language Model(RNNLM)
RNNLM은 NNLM의 특정 단락의 길이의 필요와 입력 크기 제한과 같은 한계점을 극복하기 위해 제안된 모델이다. RNN 모델은 projection 층을 갖지 않고 입력, hidden 그리고 출력 층을 가진다.
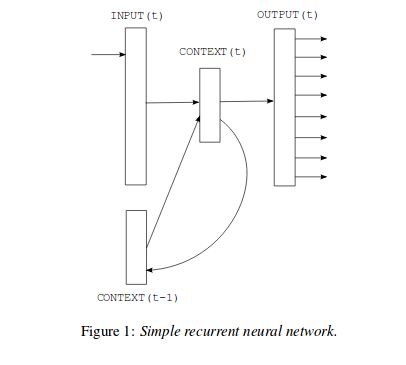
그 이유는 projection layer에 상관 없이 기존의 단어들로 만들어진 context vector와 input vector만을 고려해서 output을 내보내는 모델이기 때문이다. 결과적으로 각각의 단어들에 대한 적합한 W만을 고려하고 Context는 와의 연산을 통해 만들어지기 때문에 연속적인 단어의 input을 모아주는 것을 Context vector가 수행하기 때문이다.
이처럼 RNN 모델의 특별한 점은 시간의 흐름에 따른 연결을 위해 자신의 hidden 층에 연결된 반복되는 행렬입니다. RNN 모델 훈련의 계산 복잡도는 아래와 같다.
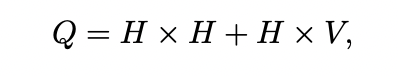
이것 역시 H x V 부분을 H x 로 교체할 수 있다.
💡 Parallel Training of Neural Networks
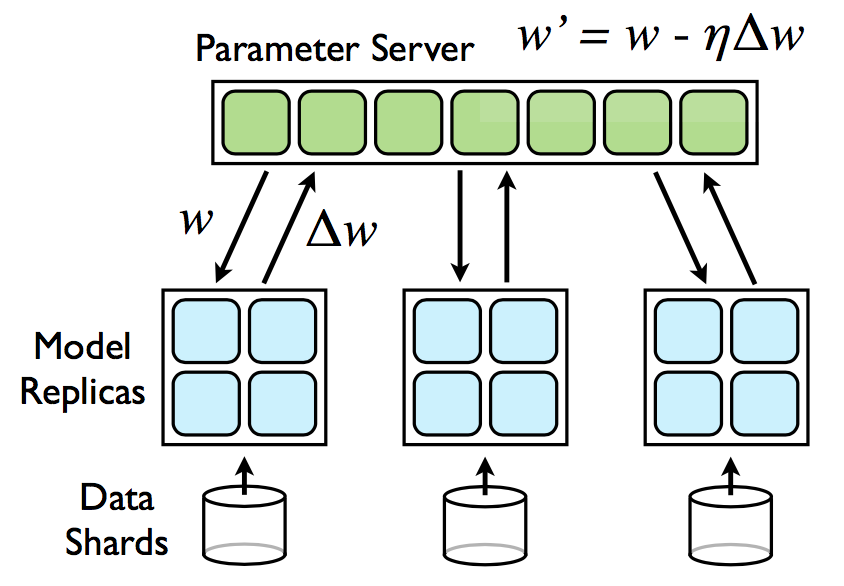
방대한 크기의 데이터 셋에 대하여 모델을 훈련시키기 위해, DistBelief를 사용한다.(모델의 experiment에서도 이를 사용) 이 framework는 같은 모델을 복제시켜 데이터 batch들에 대해 병렬적으로 실행된다. 각각의 복제본은 중앙의 server를 통하여 기울기 update가 동기화 된다. 이런 병렬적인 훈련을 위해서는 mini-batch의 비동기적인 기울기 손실을 Adagrad를 이용하여 최적화하고 경사하강법을 이용해 최적의 learning rate를 알아서 찾는다. 이는 우리가 알고 있는 Data Distributed Parallel Modeling이라고 생각하면 된다.
🔥 New Log-linear Models
여기서 본격적인 논문의 주제인 CBOW와 Skip-gram이 등장
해당 챕터에서 연산량을 최소화하면서 단어의 분산 표현을 학습할 수 있는 새로운 두 모델의 구조를 제안한다. 이전 챕터에서 주요한 점은 연산의 복잡성이 non-linear hidden layer 때문이란 것이다.
본 논문에서 제안하는 새로운 모델의 훈련은 두 단계로 이루어진다. 연속적인 word vector는 단순한 모델을 이용하여 학습된다. 그리고 그 위에 N-gram NNLM은 그렇게 학습된 word vector들로 학습을 진행한다.
🔥 Continous Bag-of-words
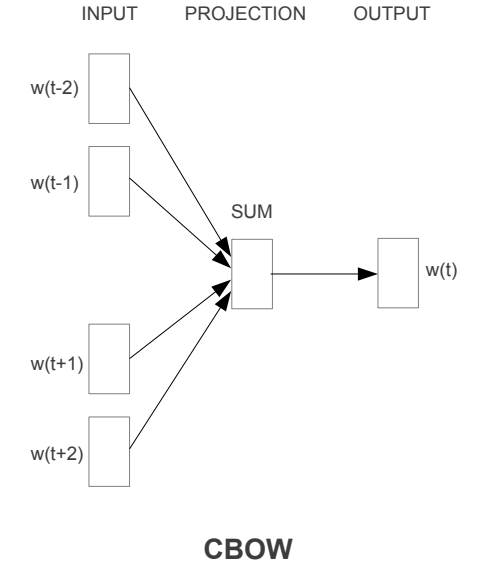
첫 번째로 제안된 CBoW model은 hidden layer가 제거되고 모든 단어가 projection layer를 공유하고 있는 형태의 feedforward NNLM과 유사하다. 모든 단어는 동일한 행렬으로 projection 된다. 우리는 이러한 구조를 Bag of Word(BoW)모델이라 하는데 단어의 순서가 큰 영향을 미치지 못 하기 때문이다.(단어를 가방 안에 담고 흔드는 느낌쓰) log-linear classifier를 4개의 과거 단어와 4개의 미래 단어를 input으로 사용하여 가운데 있는 현재 단어(target)가 나타나도록 훈련하여 가장 좋은 성능을 획득하고자 한다.
논문의 내용은 상당히 불친절하므로 학습을 위해서라면 이전 포스트 참고
훈련 복잡도는 아래와 같다.

NNLM 내부에 있는 projection layer의 weight matrix는 모든 단어들이 공유한다는 특성을 가지고 있다. 이처럼 CBoW도 이러한 특성을 갖고 진행된다.
🔥 Continous Skip-gram Mpodel
두 번째 모델 구조는 CBoW와 유사하다. 대신에 각각의 단어를 input으로 사용하여 정해진 범위들의 단어를 예측한다. 단어 간의 간격이 멀수록 보통 단어 간의 연관성이 낮으므로 훈련 데이터로 적게 부여해 weight를 낮게 하도록 만들었다.(stochastic sampling 방법) 예측 범위 증가는 word vector의 결과 quality를 향상하지만 복잡도가 상승한다. 때문에 적절한 범위 설정이 필요하다.
훈련복잡도는 아래와 같다.
C는 예측할 단어의 최대 거리이며 R만큼의 개수의 단어들을 랜덤하게 선택한다. 그리고 이들을 쌍으로 만들어 단어들을 학습시키고 최종적으로는 중심단어를 통해 주변 단어를 예측하는 모델 구조를 형성한다.
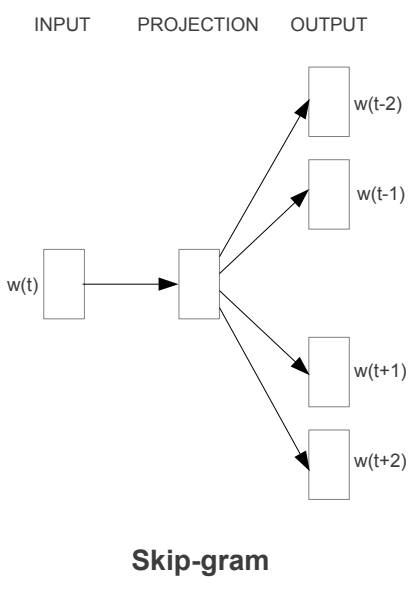
⚒️ Results
과거의 연구는 직관적으로 단어간의 유사도가 높은 것들을 테이블로 제시했었다. 그러나 단어의 유사도라는 것은 vector에 있어서 그냥 단순하게 만들 수 있는 것은 아니다. 예를 들어, 프랑스와 이탈리아가 국가명이라는 연관성을 만들어주는 것은 어렵지 않지만 그것을 확장해서 다른 나라들까지의 유사성을 만들어주는 것은 쉽지 않다.
그러나 논문에서 제안한 모델구조를 통해 나타난 word vector들은 선형대수의 연산으로서 우리가 찾고 싶은 vector X를 구하고 그것과 코사인 distance가 멀지않은(유사도가 높은) 단어를 정답으로 채택한다. 그러한 방식을 훈련시키는 것이며 정확성과 효율성이 매우 뛰어나다. 거대한 데이터 양으로의 학습은 단어사이의 미묘한 의미상의 관계를 학습시킬 수 있었다. 이것은 추후에 NLP의 여러 분야에서 활용될 것이라 말했다.
실험은 의미와 형태적 질문을 나누어서 구성했다. 질문에 대해 정확히 동일한 단어로 답변이 나올 때만 정답 처리했다. (유사어도 안 됨) 그래서 정확도 100%는 불가능하다.
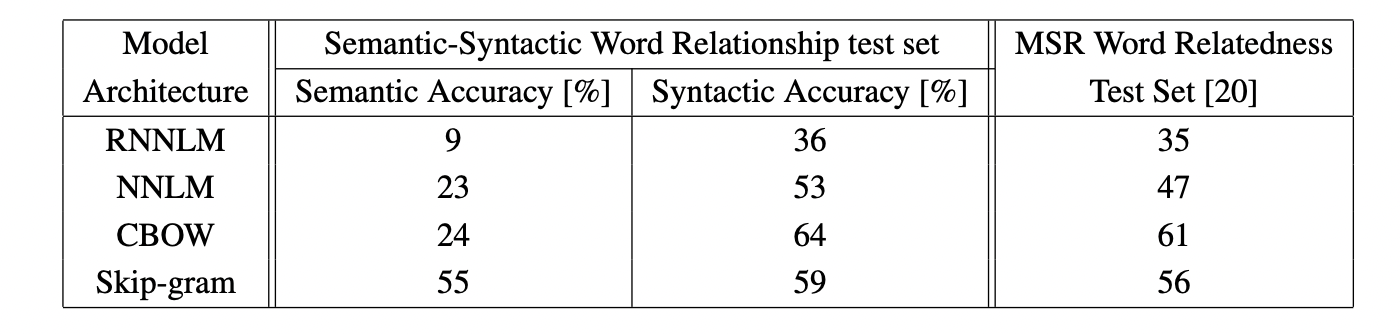

성능은 위에서 볼 수 있듯이 매우 뛰어났다. CBOW의 성능은 데이터 양과 차원이 동시에 높아질 수록 높아진다. 그러나 하나만 증가할 경우는 오히려 감소하는 경향을 보였다.
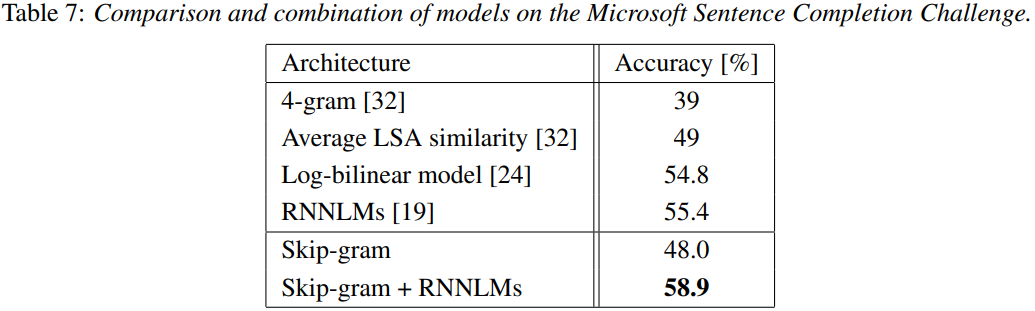
그리고 MS soft에서 진행했던 대회에서 단일 Skip-gram을 사용했을 때는 성능이 매우 높지는 않았으나 RNNLMs를 추가적으로 연결하자 매우 높은 성능을 보였다.
✏️ 후기
논문의 내용이 너무 불친절하고 애매모호해서 학습하는데 힘들었다. 이전 포스트 내용을 먼저 참고하고 논문 리뷰를 진행했더라면 훨씬 수월하게 진행했을 것 같기는 하다. 추가적으로 LDA와 LSA에 관심이 생겨 그 부분에 대해서도 공부를 진행하고자 한다.
참고 : https://coshin.tistory.com/43
https://misconstructed.tistory.com/34
https://medium.com/@mldevhong/efficient-estimation-of-word-representations-in-vector-space-%EB%B2%88%EC%97%AD-ac2a104a23ca
논문링크 : https://arxiv.org/pdf/1301.3781.pdf

정리해주셔서 너무 감사해요 논문 아무리 봐도 이해가 안됐는데 도움이 많이 됐어요!