저번 Attention 논문 이전 Base가 되는 논문이라고 할 수 있는 Seq2Seq 논문을 읽었습니다. 논문 자체는 상당히 쉽게 서술되어 있고 LSTM이나 RNN에 익숙하다면 어렵지 않게 읽을 수 있었습니다.
내용을 보다보면 Beam Serach에 대한 부분이 나타나있는데 이 부분은 간단하게 다루고 추가적인 포스트로 작성하고자 합니다.
오류에 대한 지적은 언제나 환영입니다 :)
💡 전체적인 개요
해당 논문이 이전에 DNN을 통한 Translation은 SMT 즉, 통계적 방식을 통한 Translation의 부분적 요소로 활용되기만 했다. 언어의 특성상 각 요소들이 관계를 가지고 있으며 연속적인 데이터를 통해 Output을 내놓는 것이 쉽지 않기 때문.
그러나 RNN과 LSTM처럼 Sequence Data에 대해서도 상당히 좋은 성능을 보이는 모델이 등장했다. 그러나 이들의 문제점은 Input으로 Fixed - Length Vector를 넘겨주어야 한다. 가변적인 길이를 가질 수 밖에 없는 언어의 특성상 이 부분을 해소하는 것이 어려웠는데 해당 논문은 이 부분을 해소하고자 했다.
Encoder와 Decoder 두개의 LSTM으로 구성된 모델이 먼저 Encoder를 통해 언어를 읽고 Context에 해당하는 큰 하나의 고정길이 Vector를 만들어낸다. 그리고 Decoder는 Input과 잠재변수 H 그리고 Context C까지 고려해 조건부 확률을 최대화시키는 output을 내놓는다.
특이한 점은 Encoder를 통해 문장을 읽을 때 역순으로 읽는 점이다. 이를 통하면 순방향으로 읽을 때보다 성능이 훨씬 좋게 나온다. 이 부분에 대해서 실험적으로 증명을 하지는 못했지만, 처음 단어들을 마지막에 읽게 되니 초반부에 대한 Gradient가 적게 소실되게 되고 이를 통해 첫부분의 Output을 내놓을 때 정확도를 높일 수 있으므로 이후에 차용되는 Beam Search 방식을 통해 SGD를 통한 목적함수 최대화를 효과적으로 이루지 않았나라고 가설을 내놓았다.
해당 모델은 긴 길이의 문장에 대해서도 좋은 성능을 보였으며, Translation에 있어서 방향점을 제시했다는 점에서 상당히 유의미할 것이라고 말한다.
🛠 모델의 구조
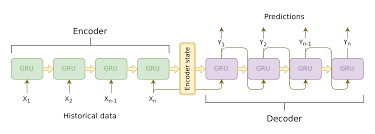
기본적인 구조는 Encoder를 통해 Input Sentence를 하나의 누적된 Cell State로 계산하는 부분과 Encoder에서 Input으로 받은 Cell State를 기반으로 Output에 해당하는 Sequence를 생성하는 Decoder 부분으로 나눠볼 수 있다.
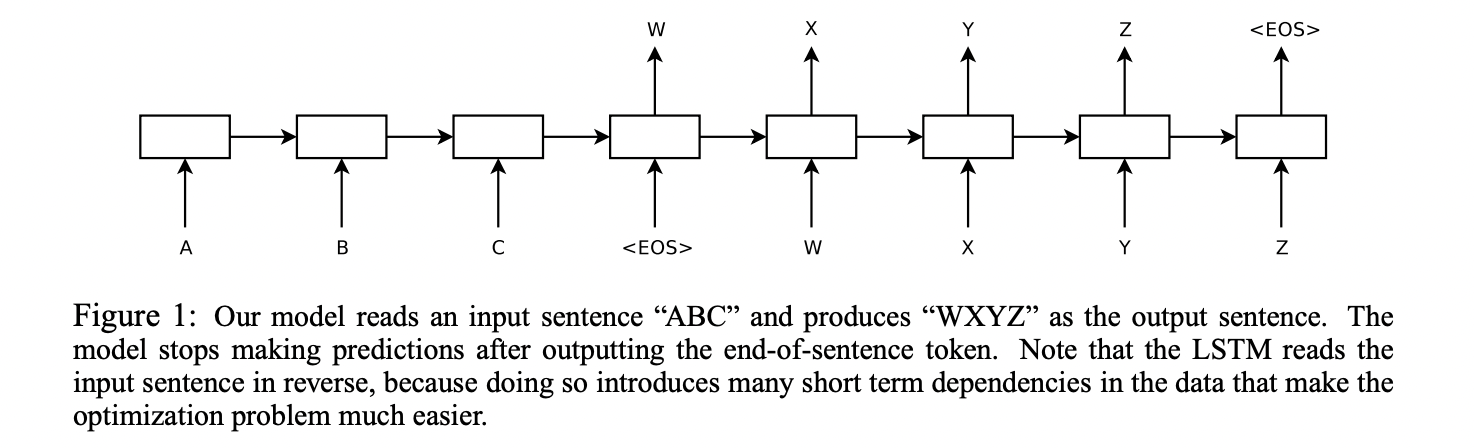
위 그림을 보면 입력으로 "ABC"가 첫 번째 LSTM에 입력되고, 해당 입력에 대한 결과(번역)인 "WXYZ" 가 두 번째 LSTM을 통해서 제공된다. 즉, 두가지의 모델이 순차적으로 실행이 되는 것이다. 그리고 각 문장의 끝은 EOS 라는 토큰으로 구분한다.
LSTM을 이용해서 가변 길이의 입력에 대해서 유연하게 처리할 수 있었다. LSTM의 큰 장점 중 하나는, 이러한 가변 길이의 입력에 대해서 고정길이의 vector representation을 생성할 수 있다는 것이다.
Translation을 수행하기 위해서 어느정도의 paraphrasing 을 수행하게 되는데, vector representation은 입력 문장의 의미를 paraphrased 한 vector representation을 생성 즉, context vector를 생성한다고 볼 수 있다. 유사한 의미의 문장에 대해서 유사한 vector representation을 생성하게 된다.
Encoder부분에서는 위에서 서술한 것과 같이 Input Sentence를 누적된 Cell State로 계산하는 역할을 한다. 여기서는 Sequence의 길이에 관계없이 EOS토큰이 나올때까지 Input을 계속 모델에 입력한다.
참고 : 이 부분은 이론과 실제가 다르다고는 한다. 실제로는 Training의 편의성 내지 병렬처리를 위해서는 Fixed Length를 가질 필요가 있을 것이며, 해당 실험에서도 8개 GPU를 사용하기 위해 Sentence를 분할시킨다. 이는 최대길이를 설정하거나 또는 원하는 길이를 설정해준 후 Padding / Clipping을 해줘야 할 것이라고 얘기된다.
이렇게 생성된 Vector는 Context Vector이자 Latent Vector로 파악 가능하다. Sequence Data를 다루기 위해 RNN을 사용하고자 했으나 RNN은 Long term dependency에 취약하다. (장기의존성을 Vanishing Gradient가 훼손하기 때문)
그래서 LSTM 모델을 사용해 이를 해소하고자 했으며 긴 기간에 대해 고려할 수 있어 보다 높은 성능을 보장할 수 있었다. LSTM은 우리의 입력과 잠재벡터 H를 고려해 Vecotr H를 만들고 이를 통해 output을 내놓는 형태이다.
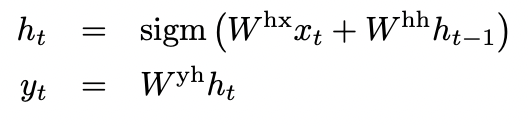
LSTM 모델이 하고자 하는 것은 우리가 출력한 가 input 에 대해 조건부 확률에서 최대화하고 그렇게 만들어낸 예측 문장 T’가 Target sentence T와 최대로 유사하게 하는 것이다.

이때 결과값에 softmax를 씌우게 되면 확률값으로 변하게 된다. 이를 통해 조건부 확률을 최대화하고자 했다. 순차적으로 ABC의 문장을 읽고 난 후에 WXYZ로 내놓을 output에 대한 조건부 확률을 파악하게 된다.
여기에 더해 논문 저자는 4층의 Deep한 LSTM 모델을 사용했으며 문장을 역순으로 읽도록 만들었다. 이는 위의 요약에서 서술한 것처럼 이렇게 진행했을 때 성능이 훨씬 뛰어나기 때문이다.
LSTM은 long sequence 에 대해서 취약하다는 연구들이 있었지만, 해당 논문에서 제안하는 모델에서는 긴 문장에 대해서도 좋은 성능을 보장했다.
💡 Decode, Beam Search
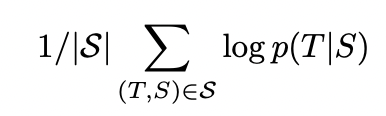
찾고자 하는 목적함수는 위와 같이 log 확률 즉, log likelihood의 최대화이다. 이는 결과적으로 조건부확률을 도출해낼 것이다. 또한 이러한 가능도들의 총합을 최대화시키는 것이 목표이기 때문에 이를 Training set 전체에 해당하는 1 / |S|로 나눈다. 이를 통해 일부 문장만을 너무 정확하게 맞추는 모델보다 평균화된 성능이 높은 거을 유도하고자 했음을 알 수 있다.
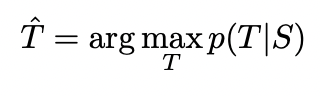
그리고 여기서 Decoder를 통해 Target 문장을 만들 때에 Beam Serach 기법이 사용된다.
https://velog.io/@nawnoes/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-Beam-Search
해당 내용은 위 링크를 참고하자.
간략적인 방식은 아래와 같다.
- 각 후보 시퀀스는 가능한한 모든 다음 스텝들에 대해 확장된다.
- 각 후보는 확률을 곱함으로써 점수가 매겨진다.
- 가장 확률이 높은 k 시퀀스가 선택되고, 다른 모든 후보들은 제거된다.
- 위 절차들을 시퀀스가 끝날때까지 반복한다.
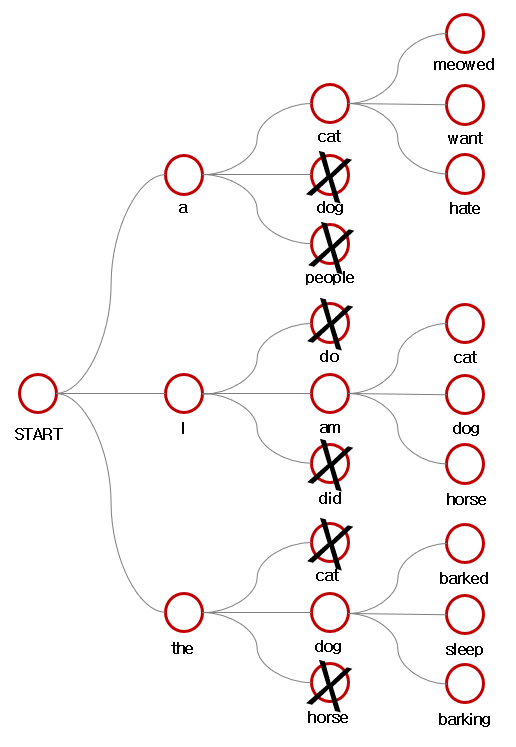
결과적으로 Decoder로 결과물을 출력하고자 할 때에 greedy choice를 약간 보완한 방식으로 위치와 단어 선택에 대한 설정을 하고 있는 것이다.
그리고 길이에 대한 penalty를 부여해서 길이가 긴 문장이 짧은 문장보다 터미뉘 없이 작게 나오지 않도록 조절해준다.
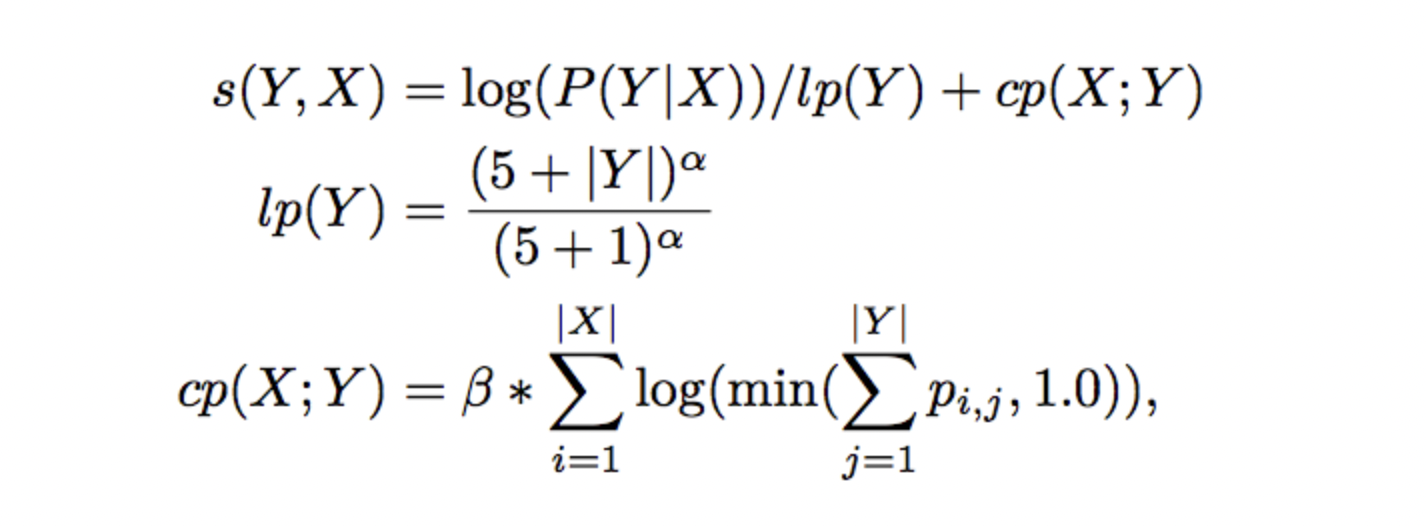
🔥 문장을 왜 거꾸로 읽는가
신기하게 Encoder가 문장을 거꾸로 읽을 때 Translation 성능이 훨씬 좋아졌다. 이는 아직은 가설에 불과하나, 초기의 translation 단어 output이 가장 최근에 읽은 데이터를 통해 만들어지기 때문에 backpropagation이 훨씬 수월하고 쉽게 진행되지 않아서일까라고 논문저자는 말한다. 결과적으로 Decoder를 진행할 시에 처음 Beam Search의 순위가 높은 것을 찾아야 하는데 여기서 최대 확률이 거의 결정되게 된다. 이에 대한 정확도를 가장 높이는 방법이 문장을 역순으로 읽어 Latent Vector를 만들어내는 것이기 때문이라고 말한다.
그렇다면 마지막 부분에서의 정확도가 낮아지지 않을까?라는 것에 대해서도 오히려 그렇지 않다고 논문저자는 말한다. 결과적으로 문장을 역순으로 읽을 때 보다 높은 성능을 기대할 수 있다고 말한다.
🔥 GPU 병렬처리
Our models have 4 layers of LSTMs, each of which resides on a separate GPU. The remaining 4 GPUs were used to parallelize the softmax, so each GPU was responsible for multiplying by a 1000 × 20000 matrix. The resulting implementation achieved a speed of 6,300 (both English and French) words per second with a minibatch size of 128. Training took about a ten days with this implementation.
위와 같이 신기하게 모델의 병렬처리 부분에 대한 글이 나타나있다. 8개의 GPU를 사용함에 있어서, 4개는 LSTM에 그리고 4개는 softmax 계산에 진행하고 이들을 연관시킴으로써 계산의 효율을 극대화했다고 말한다.
✏️ 후기
아무래도 Attention 논문을 이미 리뷰한 이후였기 때문에 Seq2Seq 논문을 이해하기 훨씬 수월했다. 거기에 더해 지난번 공부에서 LSTM을 많이 공부했던 것이 도움이 많이 된 것 같다. BLEU 점수와 Beam Search 에 대한 부분이 많은데 이 부분에 대한 공부가 필요하다고 생각했다.
출처 :
https://arxiv.org/abs/1409.3215 (논문)
https://velog.io/@nawnoes/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-Beam-Search
http://incredible.ai/nlp/2020/02/20/Sequence-To-Sequence-with-Attention/
