첫 논문 리뷰를 시작하며,
아직 많이 부족하기에 논문 리뷰라고 하더라도 부족한 점이 많을 것 같다. 그래도 가장 기초적인 논문이기도 하고 RNN 모델에 어느 정도 익숙한 터라 나쁘지 않았던 것 같다.
오류가 있거나 틀린 부분에 대한 지적은 항상 환영입니다 :)
💡 전체적인 개요
NLP에서 Attention 기법을 사용해 기존에 통계적 수준에서의 학습에 불과했던 Neural Marchine Translation을 새로운 국면으로 끌고 간 중요한 논문이며 모델이다. 기본적으로 RNN 기반을 하고 있으며 LSTM을 차용한다.
기존 모델들과의 가장 중요한 차이점은 Context vector를 어떻게 설정하느냐이다. 기존 모델들은 거의 대부분 Encoder와 Decoder 형식으로 이루어져 있으며 Encoder를 통해 Fixed - Length의 전체 내용을 포괄하는 Context vector를 만들어주고 그것을 통해 Translation에 있어서 전체적으로 변경 없이 고려한다.
이 부분을 해당 논문은 개선시키고자 했으며 가변적인 길이의 Context vector를 하나의 output을 생성하기 위해 매번 만들며, 그것은 잠재적인 vector에 가중치를 고려해서 생성된다. 결과적으로 Encoder는 하나의 fixed된 길이의 vector를 만들기 위해 노력하지 않아도 되고 모델은 output을 만들 때마다 그것과 연관이 있는 문장에서의 postion에 "Attention" 한다. 그래서 Attention 모델이라고 부른다.
💡 논문의 배경
기존의 Translation 모델들은 하나의 큰 neural network를 이용하며 이것은 encoder - decoder을 이용한 형식으로 이루어져 있다. Encoder의 경우, 입력 문장을 고정 길이 벡터로 변환시키고, decoder는 해당 벡터를 이용해서 번역 결과를 생성해낸다. 해당 모델을 입력으로 제공된 Input sentence와 결과로 생성된 output sentence 사이의 probability를 최대화하는 방식으로 학습된다.(여기서는 BLEU를 사용하기는 했다)
이러한 encoder-decoder 구조는 bottleneck 문제를 발생시킬 수 있는데 이는 encoder가 억지로 전체 문장을 하나의 고정된 길이의 벡터로 생성하고자 할 때 발생한다.
이러한 문제는 문장이 길어질수록 심각하게 나타나고, encoder-decoder 모델의 성능 또한 문장의 길이가 길어질수록 떨어지게 된다. 논문에서는 30단어가 넘게 되면 모델의 성능이 매우 저하되게 된다. 문장 전체의 정보를 짧은 고정 길이의 벡터로 변환시키는 것이 쉽지 않기 때문이다.
결과적으로 필자가 작성하고 싶은 모델은 Input Sentence에 대해 Robust하며 통계적 계산에서 벗어나는 모델이다. 이를 위해 encoder-decoder 모델에서 새로운 구조를 추가해서 성능을 향상할 수 있는 방법을 제안했다.
해당 모델은 decoder에서 하나의 output을 내놓을 때마다, 입력 문장을 순차적으로 탐색해서 현재 생성하려는 부분과 가장 관련있는 영역을 적용시킨다. 그리고 이 관련 있는 부분은 생성 시점마다 변하게 된다. 최종적으로 encoder에서 생성한 context word 중 관련성이 크다고 판단되는 영역들과, decoder에서 이미 생성한 결과를 기반으로 다음 단어를 결과로 생성해낸다. 이를 통해 문장을 하나의 고정 길이 vector로 표현하지 않아도 되며, context word를 지속적으로 참조해 성능이 높아지게 된다.
⚒️ 모델의 구조
확률론의 관점에서 Neural Machine Translation(NMT)를 분석한다면, 입력 문장 s 가 주어졌을 때, 조건부 확률 를 최대화 하는 출력 문장 y를 찾아내는 방식이다. 즉, x의 데이터가 주어졌을 때 최대가능도를 가지는 y를 추정하는 것이다.
2014년 쯤에는 neural network 를 이용해서 이러한 조건부 확률을 직접적으로 학습하는 방법도 제안되었다. 이러한 방식은 앞서 언급한 RNN을 이용한 encoder-decoder 모델을 예로 들 수 있다. 이후에는 LSTM을 이용해서 RNN 보다 좋은 성능을 내는 모델도 제안되었다.
우선 모델을 파악하기 위해서는 RNN 모델부터 이해해야 한다.
RNN을 이용한 encoder-decoder 모델
Encoder는 입력으로 제공되는 문장 을 고정된 길이의 vector C로 변환하게 된다.
RNN을 이용하는 경우 아래의 식을 통해 고정 길이 벡터이자 context vector c를 생성한다. 는 time t 에서의 hidden state를 의미한다. f(),q()는 non-linear functiond이다.
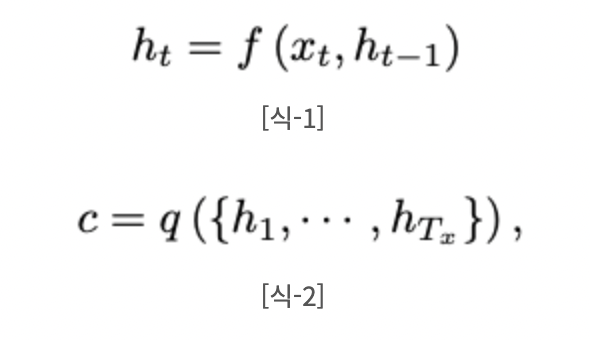
Decoder는 context vector c가 encoder로부터 주어졌을 때, c와 이전에 예측한 결과 을 기반으로 다음 단어 를 예측한다. 번역의 결과는 아래의 조건부확률을 통해 생성된다. 그리고 조건부 확률을 최대화하는 모델을 찾게 되는 것이다.
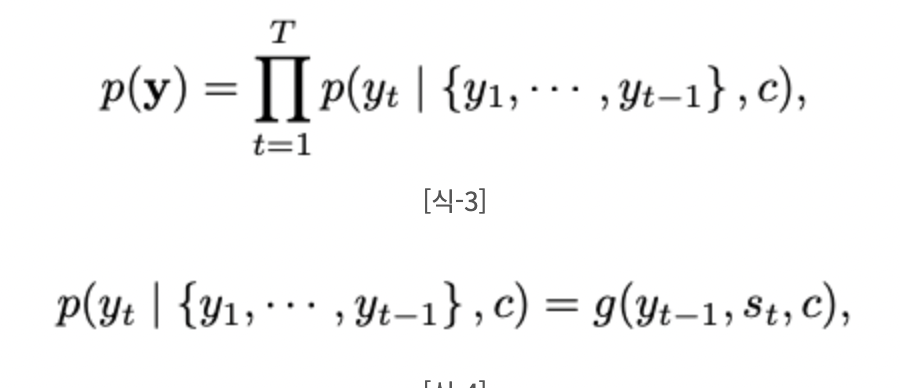
여기서 논문 저자는 RNN의 구조를 차용하며 변경시키고자 한다.
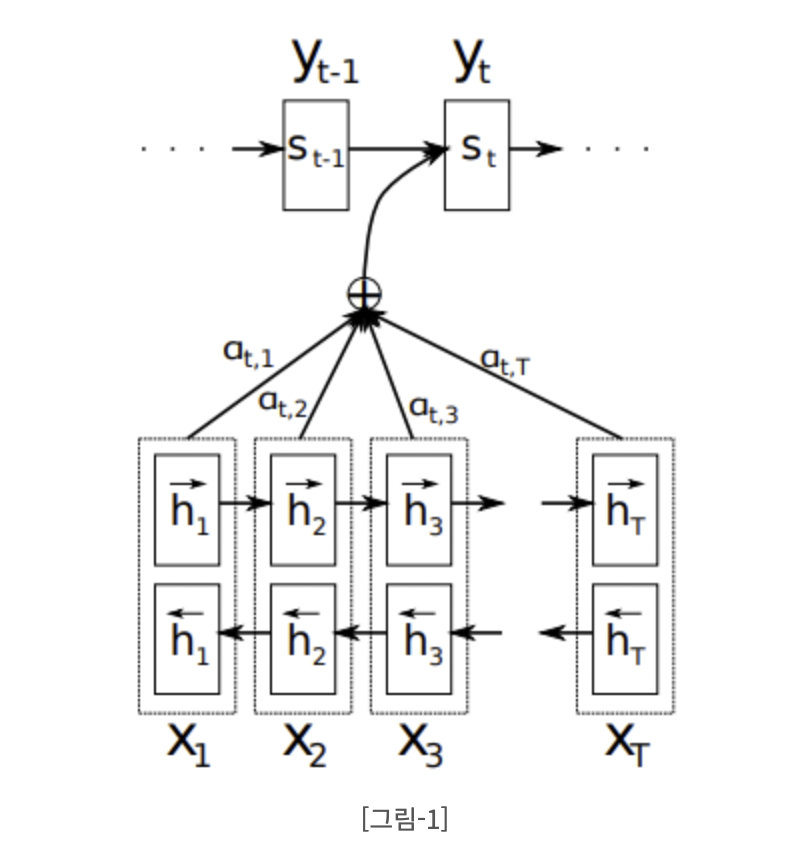
Encoder :
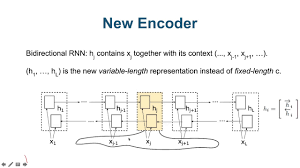
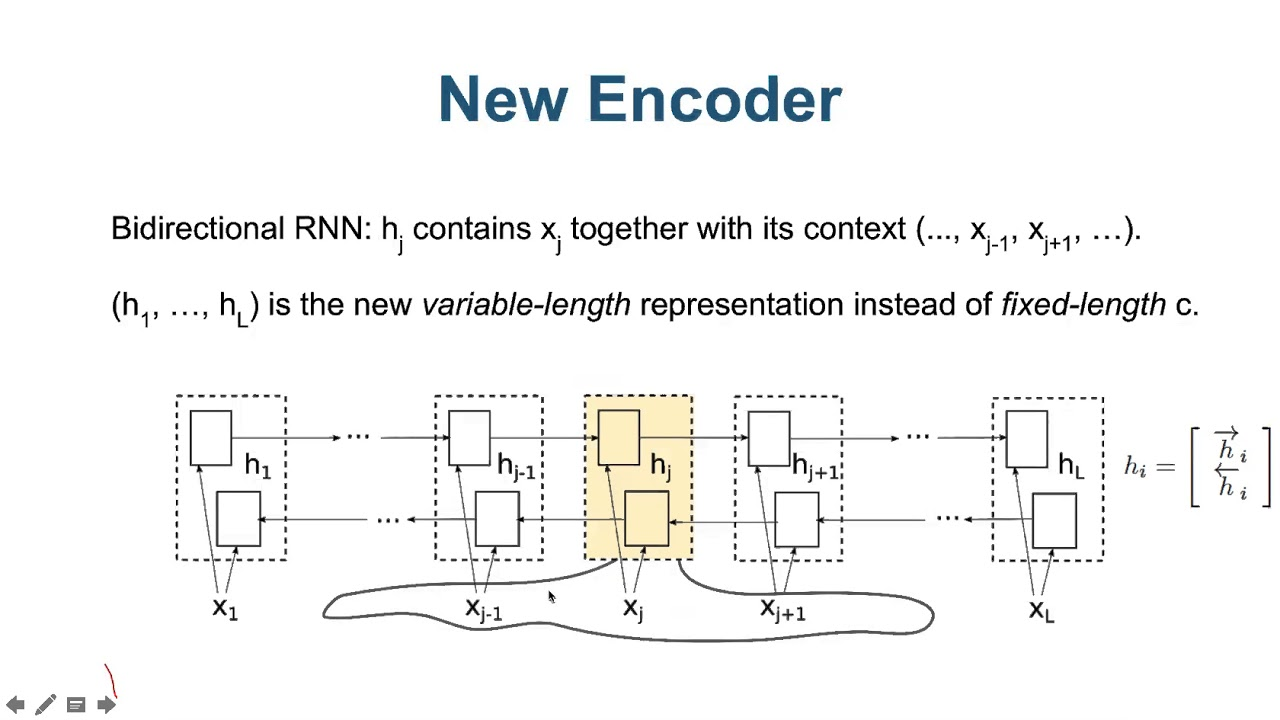
동일하게 입력 문장 는 encoder의 입력으로 제공된다. 그러나 한 방향만으로 input을 읽는 RNN과 달리 입력 문장에 대해서 이전에 나타는 내용과 함께, 이후에 나타나는 내용을 읽는 bidirectional RNN(BiRNN)을 사용한다.
BiRNN은 두 개의 RNN(forward RNN, backward RNN)으로 구성되며, Forward RNN은 처음부터 순차적으로 입력을 읽어서 hidden state를 생성한다. Backward RNN은 입력의 제일 뒤에서부터 역방향으로 입력을 읽어서 역방향의 hidden state 를 생성한다.
Time j에서의 입력 에 대해서 forward hidden state와 backward hidden state를 연결해서 j-번째 hidden state를 생성한다. 인접한 state의 정보를 더 많이 가지고 있는 RNN의 특성상, 는 입력 단어 의 가까운 위치에 있는 단어들의 정보를 더 많이 보유하게 된다.
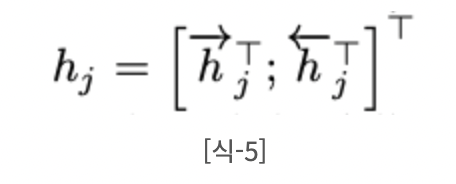
Decoder :
Time i에서 decoder의 hidden state를 이라고 한다. 즉, decoder 역시 hidden state가 존재한다. Alignment model에서는 decoder의 time i 에서의 정보다. 그리고 이는 encoder의 각각의 time j 에서의 정보와 얼마나 연관성이 있는지 score를 계산한다. 즉, 우리가 생성해낼 단어와 연관성이 높은 단어들만을 먼저 추출하는 것이다.
해당 Score는 decoder 의 바로 전 time (i−1)에서의 hidden state 과 encoder의 time j 에서의 hidden state 를 이용해 연산을 수행한다. 이 때 alignment model 인 a()는 feedforward neural network 라고 할 수 있다.
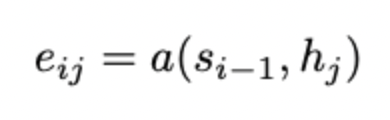
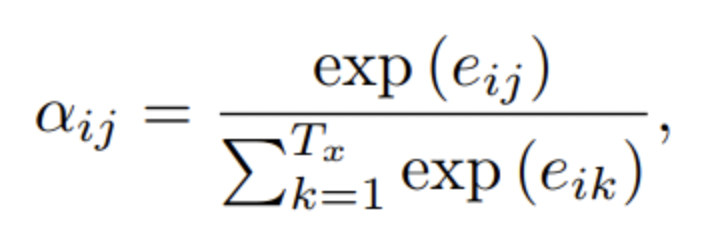
이 때, encoder의 각 hidden state에 대한 weight 는 alignment model에서 구한 score 를 이용해 구해진다.
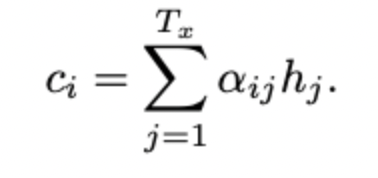
여기서 등장하는 α가 우리가 번역 단어를 생성해낼 때의 attention 정도로 파악하면 된다. 해당 weight 는 target word 가 source word 에 어느정과 연관이 있는지 나타낸다. 우리가 이미 구해놓은 잠재벡터 h에 대해 가중치가 곱해지며 어느 부분에 focus를 맞출지 결정한다.
그래서 decoder는 해당 weight 값을 기반으로 source sentence에서 어떤 위치의 단어에 더 attention을 줄지 판단할 수 있다. 기존 모델은 우리가 생성해낸 잠재 변수를 그대로 사용하는 경우가 많다. 그렇지 않고 이렇게 가중치를 곱해주며 각각의 output을 생성할 때마다 context vector를 만들면 오히려 모델의 성능이 상승하게 된다.
결과적으로 decoder의 hidden state를 계산하는 함수는 기존 RNN과 동일하다. 그러나 그것을 만들어주기까지의 과정은 상당히 상이하다고 볼 수 있다.
🔥 결론 및 성능
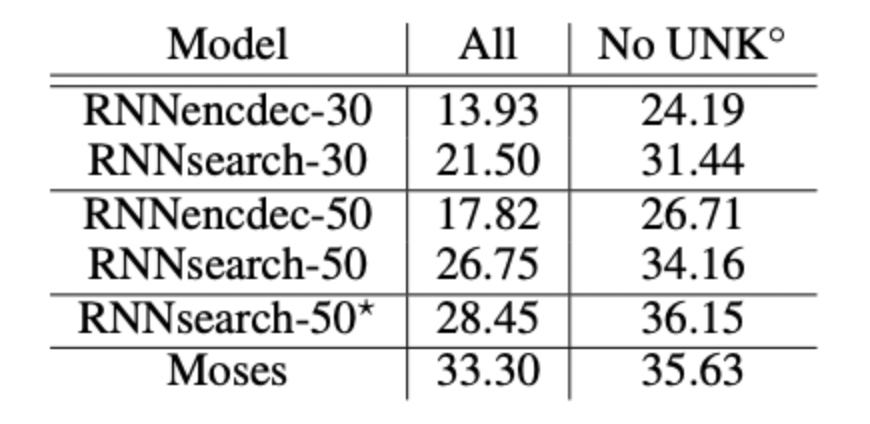
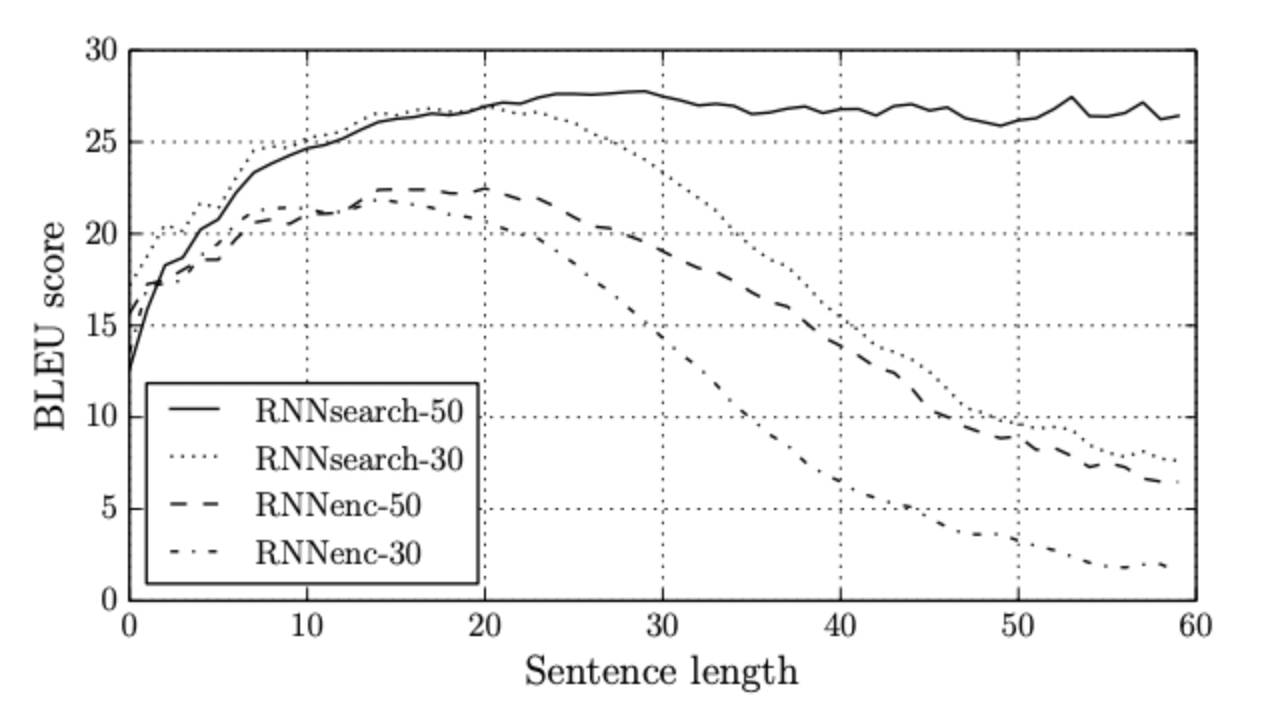
RNNencdec가 기존 모델 RNNsearch가 논문의 저자가 만든 모델이다. 성능이 월등히 뛰어나며 BLEU 점수는 문장의 길이가 길어질 수록 매우 높은 차이를 보이고 있었다. 즉 문장의 길이가 길어져도 성능의 저하가 나타나지 않는다는 것이다.
그리고 해당 모델의 중요한 특징은 hard alignment가 아닌 decoder에서 단어를 생성할 때마다 기존의 hidden state 그리고 문맥들을 모두 고려해 위치와 단어를 결정하는 soft alignment를 사용한다는 것이다. 이를 통해 각 언어에 맞는 문법에 맞게 문장을 생성해낸다.
예시로 프랑스어는 성수격이 있기 때문에 일치를 해주어야 하는데 모델 자체가 이를 정확히 판단해서 translation을 하고 있는 모습을 볼 수 있었다.
🛠 모델의 구조 상세 분석 내용
내용의 뒷부분은 model의 architecture를 구조적으로 뜯어보며 보여주고 있다. 이는 거의 RNN의 모델 그리고 LSTM과 매우매우 흡사하다. update gate를 통해 잠재변수 h와 s를 update시켜주고 reset을 통해 지워줄 필요성이 있는 벡터 요소들을 제거해준다. 그리고 이러한 잠재변수들을 통해 생성된 encoder와 decoder를 통해 만들어진 벡터의 관계를 의미하는 e는 가중치처럼 update가 되고 이를 통해 구해진 로 각각의 잠재변수를 얼마나 고려할 것인지를 output을 내놓을 때마다 만든다. 결과적으로 조건부 확률을 최대로 하며 생성된 는
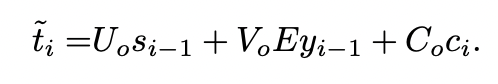
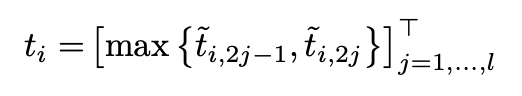
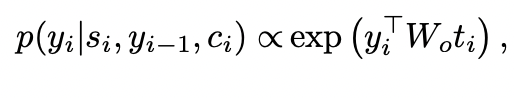
의 함수를 최대화하는 것을 찾는 것이다. 해당 U, V, E 등등은 가중치 행렬로 update가 계속 될 것이다.
✏️ 후기
논문을 읽으면서 크게 어려운 부분은 없었으나 BLEU와 alignment에 대한 부분의 내용이 적어 아쉬웠다. 다음 논문을 학습하기 이전에 이 둘에 대한 포스트를 작성하고자 한다. 모델이 어떻게 위치를 찾는 것인지 상당히 궁금했는데 조금 아쉬웠다
참고 : https://arxiv.org/abs/1409.0473 (논문)
https://misconstructed.tistory.com/49
https://heiwais25.github.io/nlp/2019/06/18/neural-machine-translation-by-jointly-learning-to-align-and-translate/

좋은 글 감사합니다