논문 리뷰
https://arxiv.org/pdf/2203.11171.pdf
위논문에서도 해당 방식으로 모델 성능이 많이 오른다고 밝힘
사람이 reasoning 문제를 해결할 때에 여러 가지 방법론을 생각해보는 것과 유사한 방식의 방법론.
하나의 모델에서 다양한 reasoning path를 생성한다. 하나의 문제에 대해 path m개를 생성했을 때 i번째 은 이며 가 최종적으로 향하는 답(아래 그림에서는 18달러)을 라고 한다.
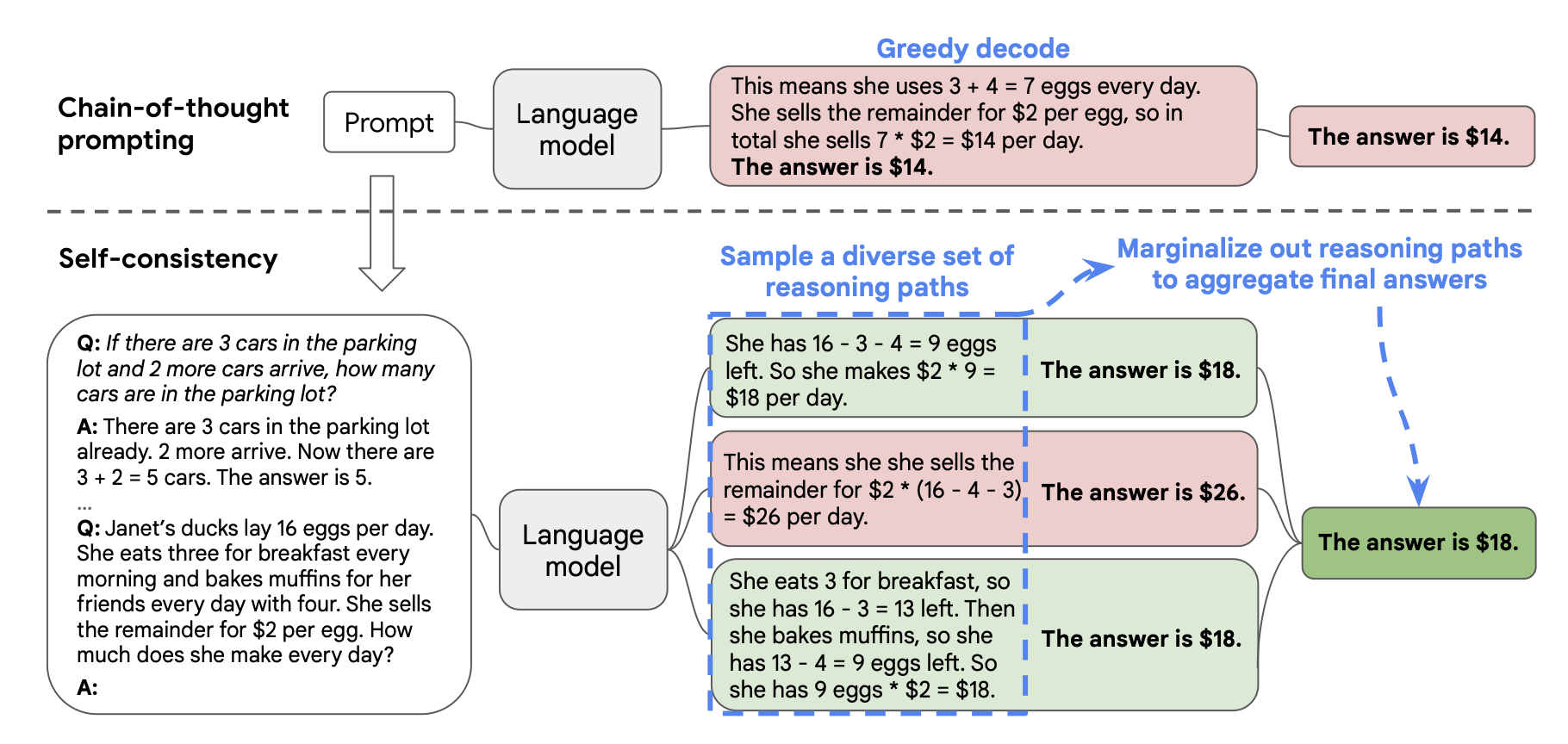
이후, ()에 대해 majority vote, normalized / unnormalized + weighted sum/avg등을 해주는 방식을 사용. 성능은 unweighted sum인 majority vote가 가장 높다고 한다.
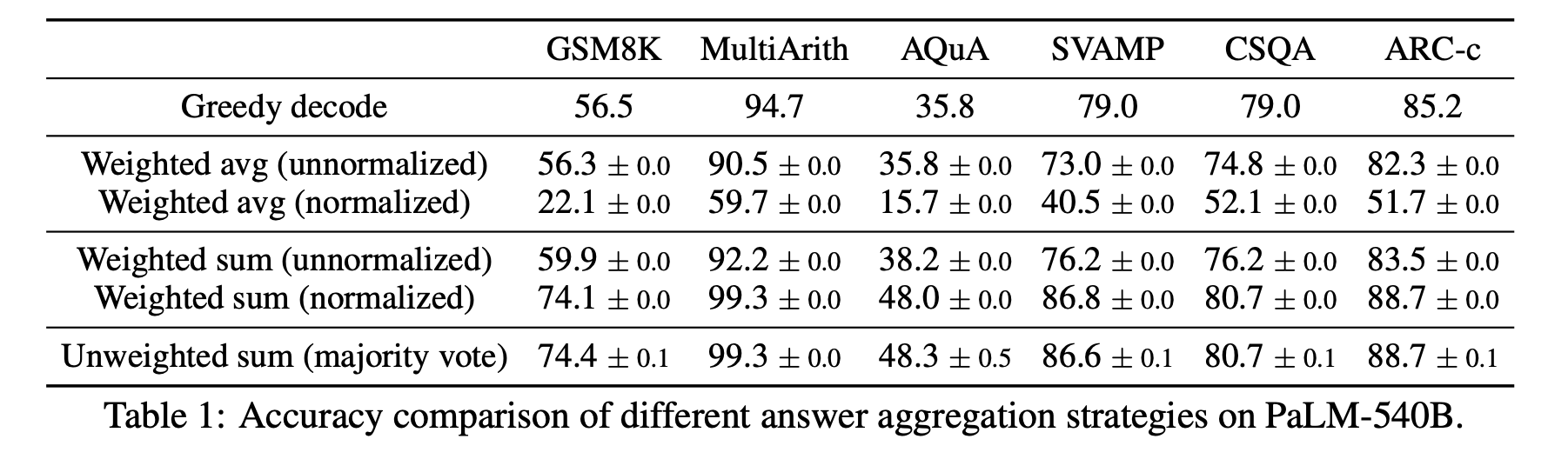
결과적으로는 probability를 계산해서 weighted sum을 하는 방식을 사용하거나 majority vote를 사용하는 방식이 성능이 높았다는 것이다. 이를 사용하면 reasoning 분야에서 거의 모든 모델이 높은 성능 상승을 보였다.
실험은 8개의 sample을 주는 few-shot setting으로 진행했다고 하며, 40개의 output을 1번의 run마다 생성해 총 10번의 run을 진행했다고 한다. 아래의 그래프를 보면 10개 이상의 output을 1번의 run에 생성하면 안정적으로 greedy decode보다 성능이 높았다.(당연해보이기는 하다)

COT가 도움이 되지 않은 상황에서도 self-consistency가 성능을 올리는 효과를 나타냈다고 밝혔다.
✏️ 발전 방향
문제점은 모델에게 400개의 답을 내놓고 majority voting을 하는 방식과 다를 것이 없기에 당연히 성능이 높아질 것이라는 것이다. 이를 위해서는 많은 resource가 필요할 것이기에 성능 고도화와 안정화에는 도움이 되지만 실제로 사용하기에는 애매한 것 같다. 구글 리서치라는 돈 많은 대기업이기에 이런 연구를 진짜로 해볼 수 있었던 것이 아닐까 싶다.
