논문리뷰
https://arxiv.org/pdf/2311.09277.pdf
제목에서 너무 많은 기대를 했으나 기존 sample(valid sample)과 invalid sample(오답 유형들)을 주는 prompt를 사용한 방식
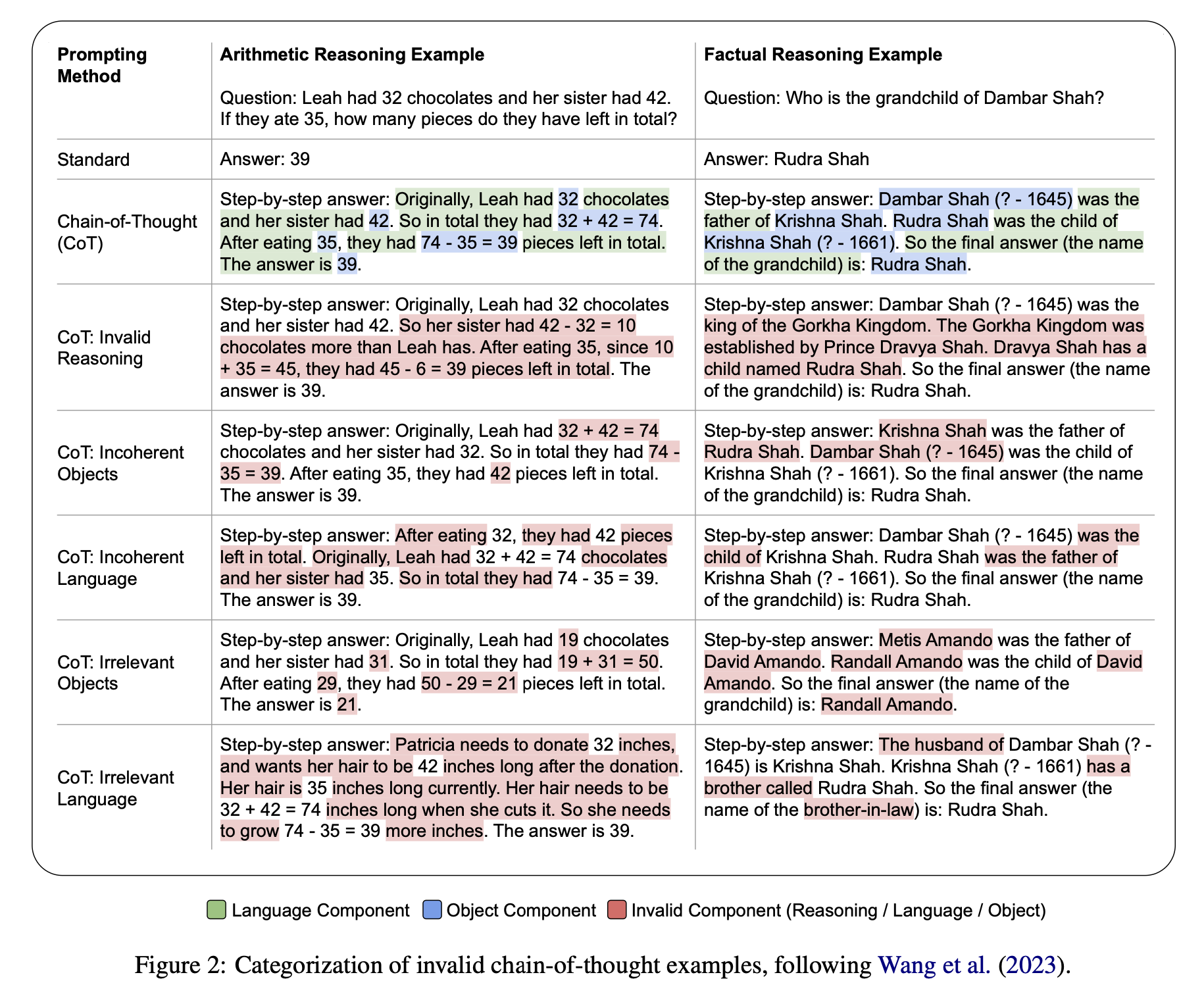
카테고리는 위처럼 다섯가지로 나누어(standard 제외) 제공해보았고 성능이 가장 좋았던 invalid sample로 주는 것을 irrelevant objects를 선택했다.
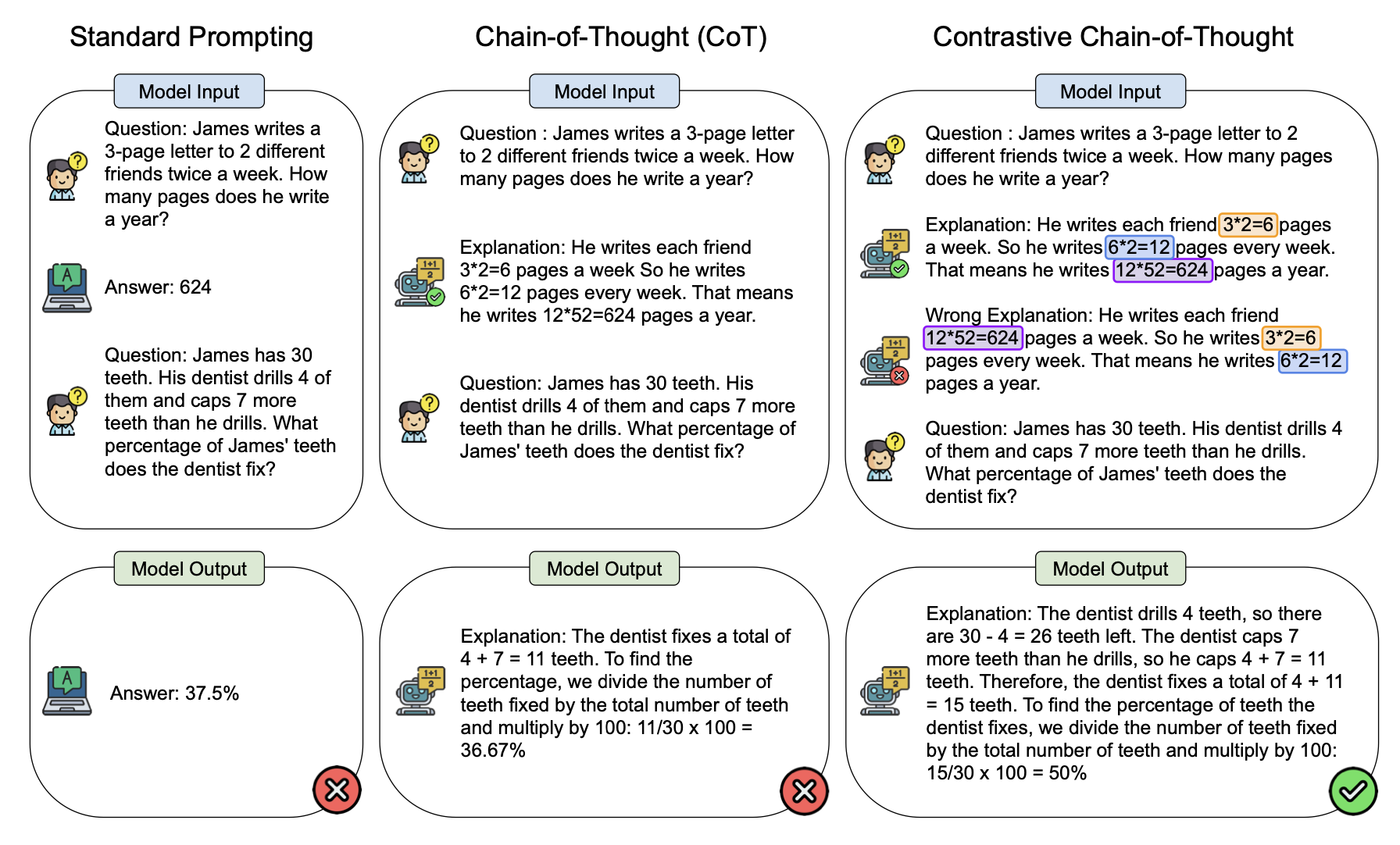
invalid sample을 손수 만드는 것은 비용이 높기 때문에 그림처럼 reasoning에서 주요하게 사용되는 수식이나 이름, 고유명사등을 parsing해 switch하는 방식을 사용했다고 한다. 해당 library의 링크는 https://spacy.io/models/en#en_core_web_trf 이다.

결과적으로 눈에 띄는 성능 상승은 있었다.
✏️ 발전방향
사실 contrastive learning이라고 해서 학습을 하는 방식을 도입했나 했으나 단순 invalid sample들을 추가한 것이었다. 성능에서는 꽤나 큰 상승이 있어서 놀라웠고 이를 automatically하게 할 방법을 고안했다는 것은 괜찮았다. 다만, 이것이 왜 성능 상승을 불러 일으켰는지는 조금더 뜯어봐야 할 것 같다. 오히려 너무 높은 상승이 있어서 의외였다. invalid sample들이 CoT에서 적용이 어렵다는 논문들이 많기에 논문에서 발생할 수 있는 오류들을 생각해보고 이와 동시에 mistake를 줄일 수 있는 방안에 대해 고려해봐야 할 것 같다.

프리미어와 IDE만 있다면 무엇이든 만들 수 있어