💡 1. Contrastive Learning
(1) 개요
Contrastive Learning은 간단하게 말하면 유사도가 높은 것은 가깝게 유사도가 낮은 것은 멀리 가도록 학습을 진행하는 것이다. 주로 self-supervised learning에서 사용된다.
예를 들어, 이미지 x를 augmentation 시킨 가 있다고 할 때에 둘은 아무리 augmentation한다고 하더라도(그렇다고 너무 시키면 안 되겠지만) similar할 것이다.
그에 반해, y라는 이미지와는 당연하게도 similarity가 낮을 것이고 object가 다르다면 다르다고 평가하는 것이 맞을 것이다.
이 과정에서 contrastive learning은 를 가깝게 그리고 y와는 멀게 학습을 진행할 것이다.
이를 이용한다면 data의 representation을 학습할 수 있을 것이고 이에 따라 labeling이 된 데이터에 대해서도 그것의 label에 따라 representation을 학습할 수 있을 것이다.
(2) Similarity Learning이란?
contrastive learning이란 결국에는 similarity라는 기준에 따라 학습이 진행되는데 그렇다면 similarity가 무엇인지부터 정해야 한다.
그리고 학습을 위해서는 이미지간의 유사도를 이미 알고 있어야 한다. 그래야만 학습이 진행될 수 있기 때문이다. 이것 역시 dataset 구축이기에 쉽지 않은 과정이다.
그것이 label, augmentation 여부 등을 통해 정해졌을 때 학습 방법에는 세가지가 있다.
- regression
- 유사도이기 때문에 유사한 수치가 얼마나 되는지를 정해줄 수 있다.
- 하지만 ground truth에 해당하는 유사도 수치를 정하는 것은 매우 어려운 작업이라 쉽지 않다.
- classification
- positive, negative로 간단하게 분류할 수도 있으며 그렇지 않고 multi label로도 분류를 진행할 수 있다.
- 하지만 얼마나 유사한지에 대한 label이 늘어날 수록 데이터 구축이 어려워지고 단순해질 수록 유사한 정도를 정확히 학습하기 어렵다.
- ranking similarity learning
- 이미지 x와 유사한 이미지 x+, 그리고 유사하지 않은 이미지 x- 세가지를 input으로 제공해 상대적인 거리에 대해 학습한다.
- 해당 방식을 사용하면 classification 보다 정확하게 distance를 학습할 수 있다는 장점이 있지만 이 역시 ranking으로 labeling을 수행해야 한다.
이러한 방식으로 학습된 것들을 대상으로 유사한 것은 가깝게 유사하지 않은 것은 멀게 학습한다.
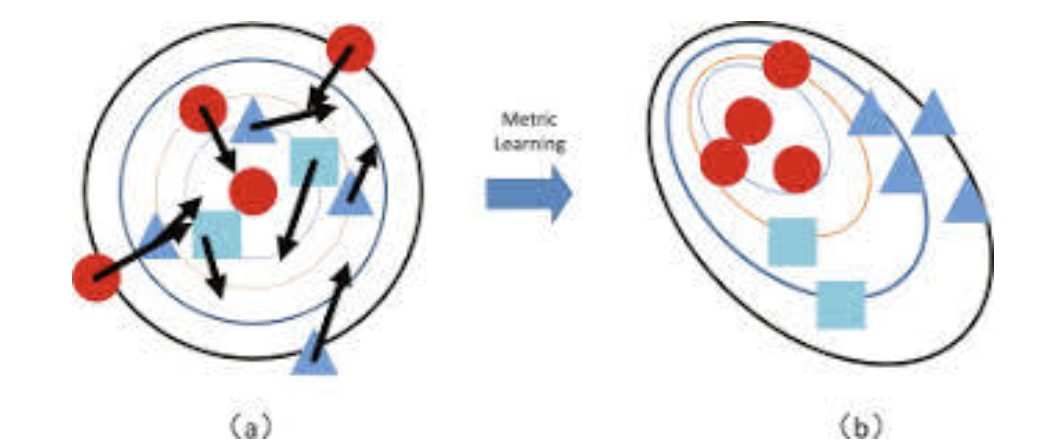
(3) Metric Learning이란?
그렇다면 유사도 즉, metric은 어떻게 결정될 수 있는가도 정해야 한다. 보통은 객체 간의 “거리”라는 개념으로 얘기되는 유사도는 여러 가지 방식을 통해 수량화를 시킬 수 있다.
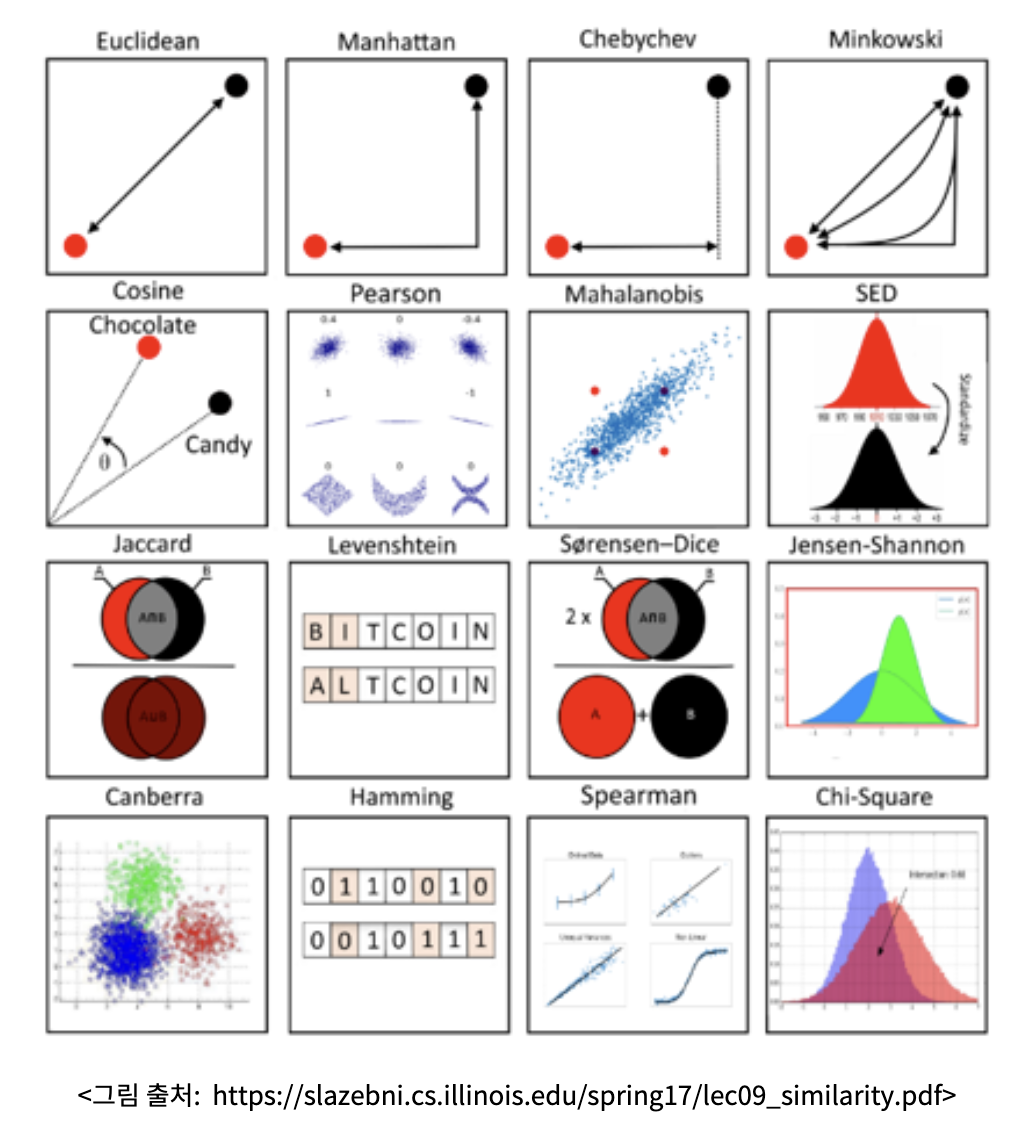
그리고 이 거리의 도출에는 두 가지 방식이 사용된다.
- Pre-defined Metrics
- labeling된 데이터
- Learned metrics
- 데이터들로부터 추정할 수 있는 다른 지표들을 metric 공식에 적용하여 거리를 도출하는 것
결국에는 아래 방식이 deep learning에서 사용하고 있는 data manifold learning 방식이고 거기서부터 distance를 도출한다.
여기서 positive pair와 negative pair를 학습하게 되는데 postivie pair는 loss에서 거리가 가깝도록 negatvie pair는 m이라는 일정 margin을 갖도록 학습된다.
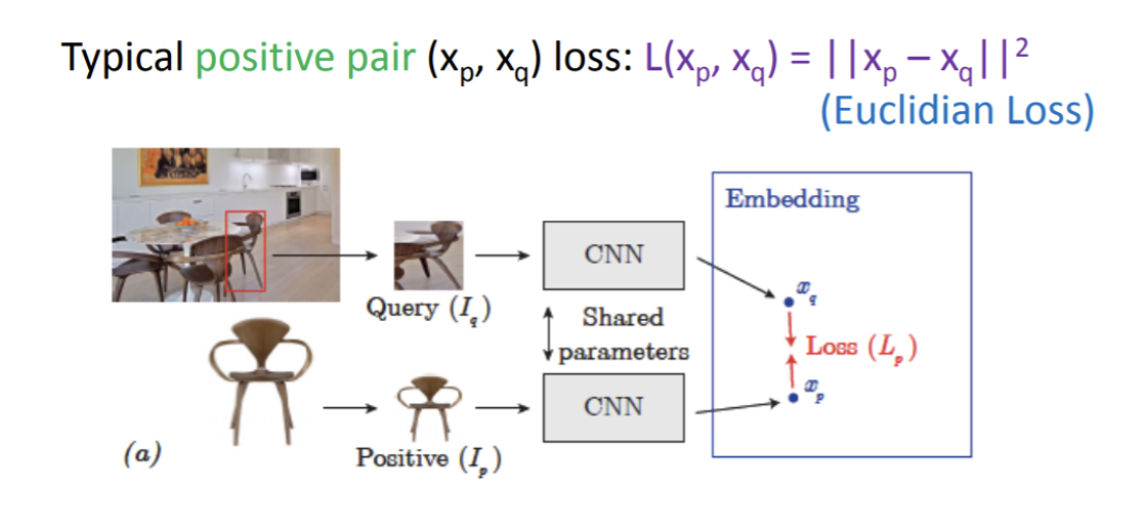

이 두가지를 합친 것이 contrastive loss라고 부른다.

pytorch의 경우 postive pair에도 margin 값을 설정할 수 있어 overfitting을 방지할 수 있다.

(4) Margin을 통해 본 데이터
Margin이라는 개념을 사용하면 negative pairs를 margin에 따라 종류를 나눌 수 있다.
- d : distance를 구하는 함수
- a : positive, negative pair의 기준이 되는 데이터
- Hard Negative Mining : positive pair에 해당하는 margin 안에 negative sample이 포함되어 있는 경우
- Semi-Hard Negative Mining : positive pair margin 범위 안에 속하진 않으나, negative pari margin에 속하지 않는 애매한 대상
- easy negative mining : negative pair margin 범위에 속하는 경우
결과적으로 거리를 적절히 파악할 수 있고 이를 학습에 사용할 수 있다면 학습 결과 유사 데이터들끼리 contrastive learning으로 clustering이 될 것이다.