image 혹은 sequence data를 다루는 모델을 공부하다보면, Auto-Regressive라는 개념이 자주 등장한다. 또한, Sequence data를 다룰 때에 parameter를 너무 과도하게 가져가지 않기 위해 Markov Assumption을 이용하기도 한다.
이번 포스트에서는 해당 내용을 다루고자 한다.
🐣 Basic Discrete Distributions
우선 이산적 분포에 대해 생각해보자. 베르누이 분포(Bernoulli distribution)를 표현하기 위해서는 단 하나의 숫자가 필요하다.
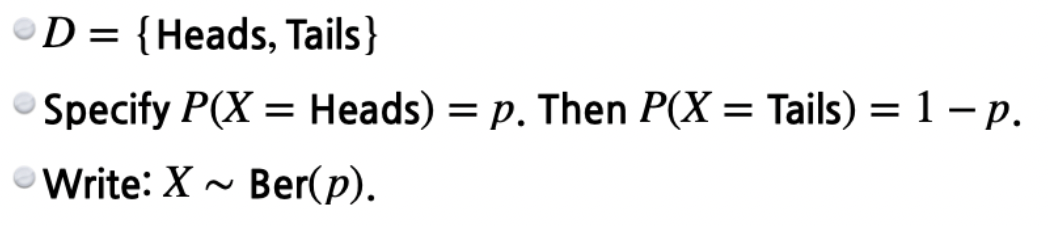
또다른 카테고리 분포를 m개의 state가 있다면 표현하기 위해서는 m-1개의 parameter가 필요하다. m개가 아닌 이유는 m-1개의 확률만 정의가 되더라도 마지막 하나는 결정되기 때문이다.
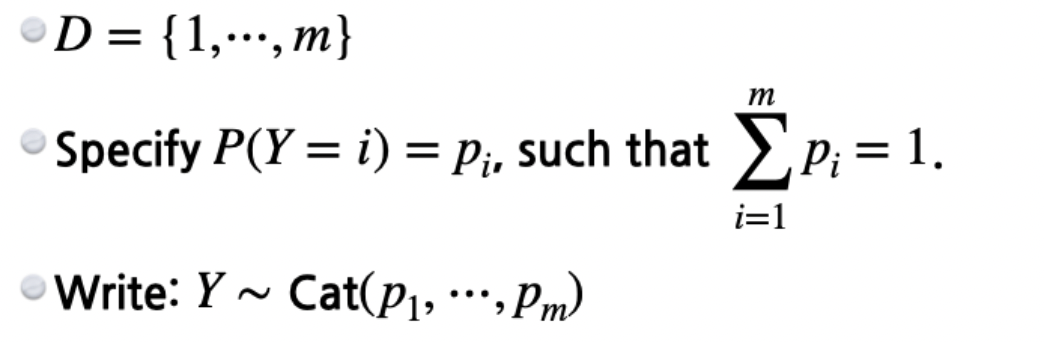
그렇다면 RGB 이미지를 표현하는데 필요한 parameter수는 어떻게 될 것인가?

이들은 서로 independent하기 때문에 세제곱의 case가 나온다. 이 Case에 대한 분포를 표현하기 위한 parameter 수는 여기서 1을 빼준 것이다. 즉, 하나의 픽셀에 대해서 RGB를 표현하기 위해서는 parameter 수가 매우 많이 필요하다. 일단 너무 많으므로 binary로 바라보자.

해당 이미지를 표현하기 위해 n개의 픽셀들이 있다면 필요한 parameter 수는 개일 것이다. 이렇게 해도 많은 parameter 숫자가 나타난다. 그리고 parameter 숫자가 너무 많게 되면 학습이 어려워진다.
그렇다면 어떻게 parameter 숫자를 줄일 수 있을까? n개의 binary pixel을 모두 사용하지 말고 쉽게 표현할 수 있는 방법을 찾아야 한다.
n 개의 pixel들이 모두 independent하다면?
- 사실 말이 안 되는 가정, 인접한 픽셀은 유사한 색을 가질 것이라 가정하는데 이를 어기는 것
역시나 possible state는 위와 동일하게 이다. 그러나 이 distribution을 표현하기 위한 숫자는 n개만 있으면 된다. 각각의 pixel마다 1개의 숫자만 필요하기 때문이다. 즉, parameter가 n개의 parameter로 교체된다.
- 이를 보고 전체 표현과 independent 표현의 중간 어디쯤을 표현하고 싶다.
- 이걸 위해서 Trick을 사용하게 된다.
⛓ Conditional Independence
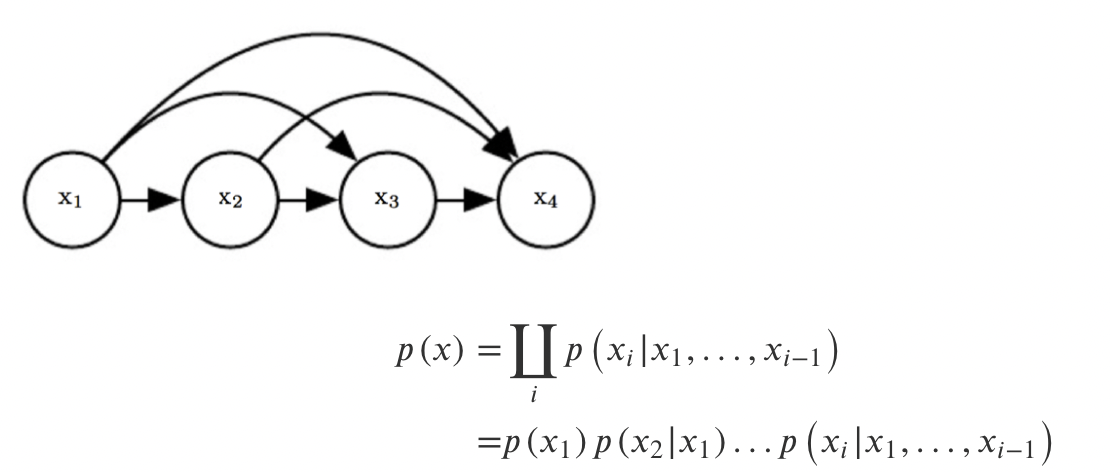
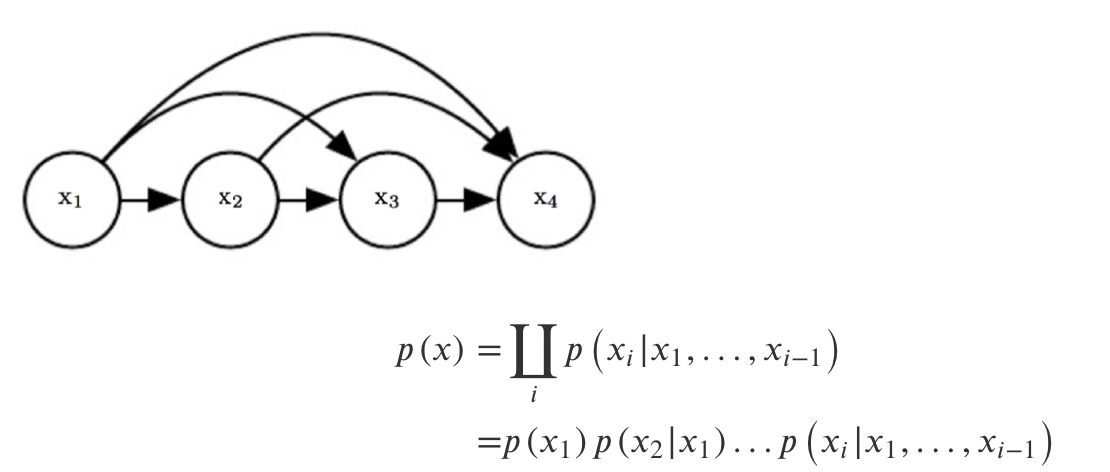
이러한 trick으로 Chain Rule을 사용하게 된다. n개의 Joint Distribution을 n개의 conditional distribution으로 교체하는 것이다. 해당 방식은 이미 존재하는 방식이기 때문에 어떠한 문제도 없다.
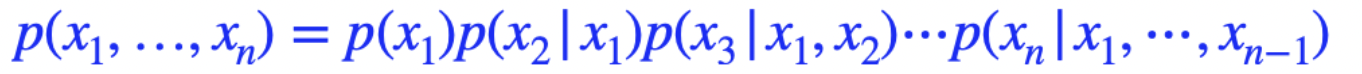
그리고 여기서 베이즈 정리도 사용하게 된다.
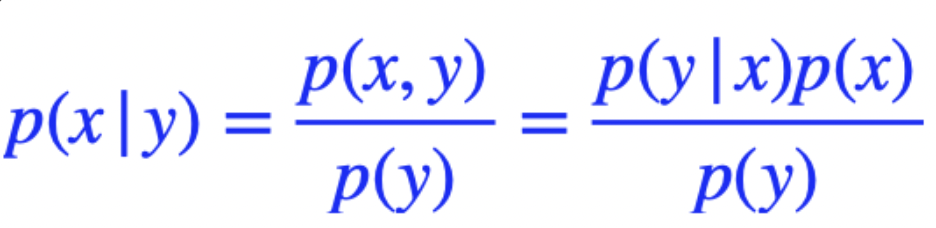
마지막으로 Conditional Independence도 사용된다. 어떠한 조건 z가 주어졌을 때 x와 y가 independent하다고 가정하는 것이다. 그러면 아래 식을 만족하게 된다.
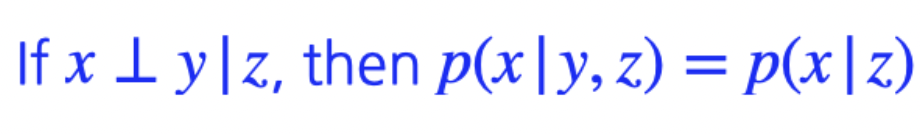
이것의 의미는 z가 주어지면 x와 y는 independent하므로 x에 아무런 영향을 미치지 못하기 때문에, y를 조건부 확률에서 없애도 된다. 즉, chain rule에서 나온 혹은 임의의 conditional distribution의 conditional 부분을 날려주는 효과가 있다. 따라서 이 두가지를 잘 섞어서 fully dependent와 fully independent 사이의 어딘가 좋은 모델을 찾아나갈 것이다. 이것이 바로 auto-regressive model이라고 불린다.
input으로 받은 sequence를 모델에 넣어주고 그 다음 예측된 token을 sequence에 추가해주어 재귀적으로 학습을 하는 모델이다. 이 과정에서 모두 사용하는 것이 아니라 특정 부분은 independent하다고 여겨 날려줄 수도 있다.
가장 먼저 joint distribution을 chian rule로 conditional distribution으로 교체해준다. 여기서 Parameter 관점에서는 아무것도 변하지 않았다는 것이다.

이때 의 경우 일 때와 일 때 2가지의 경우를 고려해야 하므로 변수는 parameter는 2개가 필요하다.
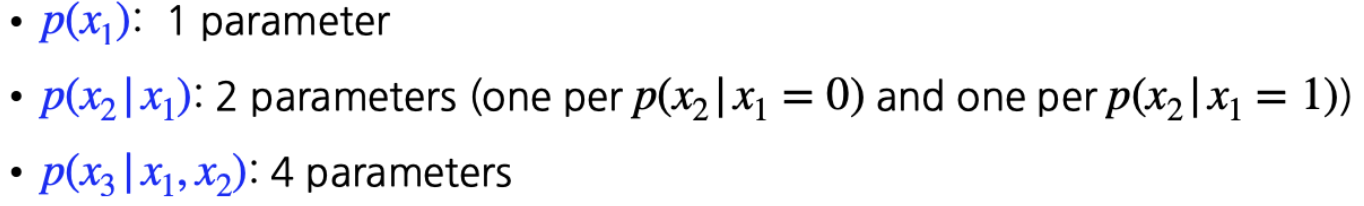
결과적으로 1부터 까지의 합은 이 나타나게 된다. 여기서 Markov Assumption을 진행해보자
- 는 에만 dependent**하다!
- 그렇다면 우리가 chain rule을 통해 얻어지는 conditional distribution의 곱이 상당히 간소화된다.
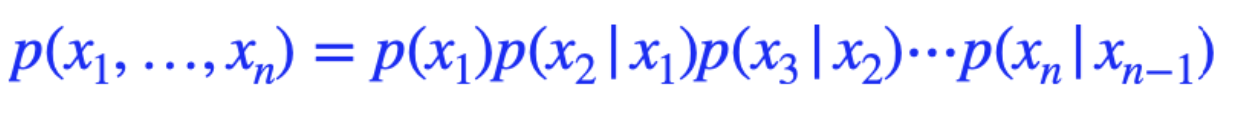
이렇게 된다면 2n-1개의 parameter가 필요하게 된다. 결과적으로 지수를 다항으로 줄일 수 있다.
그렇게 나온 것이 Auto-regressive model이다.
- 자기 자신을 입력으로 하여 자기 자신을 예측하는 모형
✏️ 후기
Language Model에 대해서 공부를 하다보니 Auto-Reggressive Model 그리고 Markov Assumption까지 공부를 하게 되었다. 언젠가 정리를 해야지 했는데 이렇게 공부하면서 정리하니 속시원~~하다.
출처 : https://ratsgo.github.io/generative%20model/2018/01/31/AR/
네이버 부스트캠프 자료
