fine-tuning을 두 번 한다는 것이 가능한가? 그것을 전이학습(Transfer Learning)이라고 할 수 있는가? 그렇게 된다면 효과가 무엇인가라는 질문으로 시작해 둘에 대한 정의와 공통점 및 차이점을 공부하는 시간을 가졌습니다.
해당 내용은 노션에 정리한 것을 기반으로 했습니다.
📌 1. Transfer-Learning & Fine-tuning?
(1) 개요
Keras 기반 작성
Transfer learning consists of taking features learned on one problem, and leveraging them on a new, similar problem.
Transfer learning is usually done for tasks where your dataset has too little data to train a full-scale model from scratch.
전이 학습(Transfer Learning)은 특정 분야에서 학습된 신경망의 일부 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경망의 학습에 이용하는 것을 의미
보통 내가 학습시키고 싶어하는 대상에 대해 데이터가 적을 때 많이 사용된다.
The most common incarnation of transfer learning in the context of deep learning is the following workflow:
- Take layers from a previously trained model.
- Freeze them, so as to avoid destroying any of the information they contain during future training rounds.
- Add some new, trainable layers on top of the frozen layers. They will learn to turn the old features into predictions on a new dataset.
- Train the new layers on your dataset.
Transfer Learning을 하는 방법은
1) 사전 학습된 모델을 가져온다
2) Freeze 시키기
3) 새로운 layer들을 freeze된 곳 위에 쌓는다. 그렇게 하면 기존 freeze layer들이 학습된 것을 기반으로 새로운 데이터셋에 맞추어 freeze 안 된 것 학습
4) 그렇게 새로운 레이어를 학습시킨다.
- 결국에 전이학습이란 학습된 것을 Freeze시킨 채로 맨 위 Layer만 학습을 시키는 것
A last, optional step, is fine-tuning, which consists of unfreezing the entire model you obtained above (or part of it), and re-training it on the new data with a very low learning rate.
This can potentially achieve meaningful improvements, by incrementally adapting the pretrained features to the new data.
Fine-tuning은 일부만을 Freeze 혹은 모두 Freeze 안 시키고 다시 새로운 것에 대해 매우 작은 Learning rate로 학습을 진행한 것
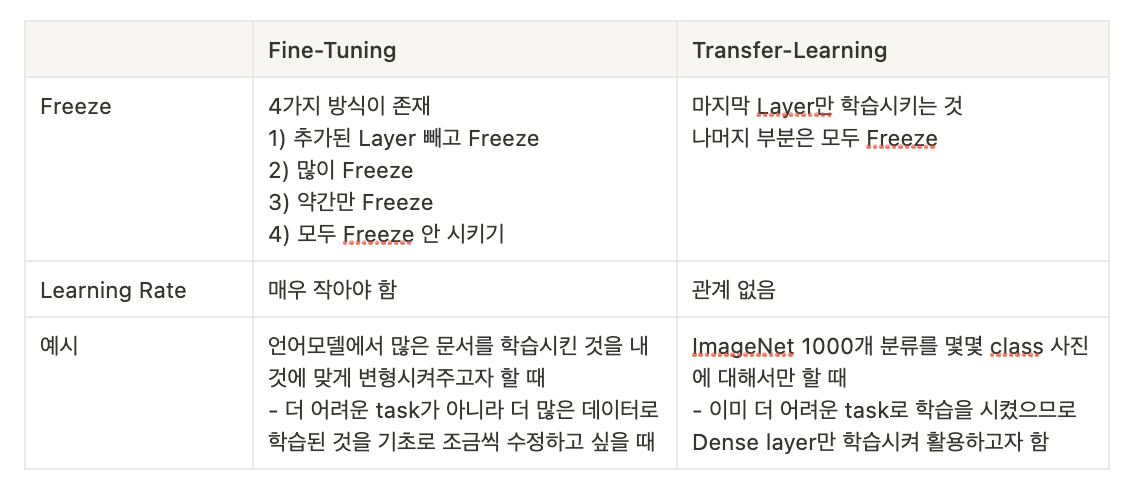
(2) **Task의 성격에 따른 Fine tuning 전략**
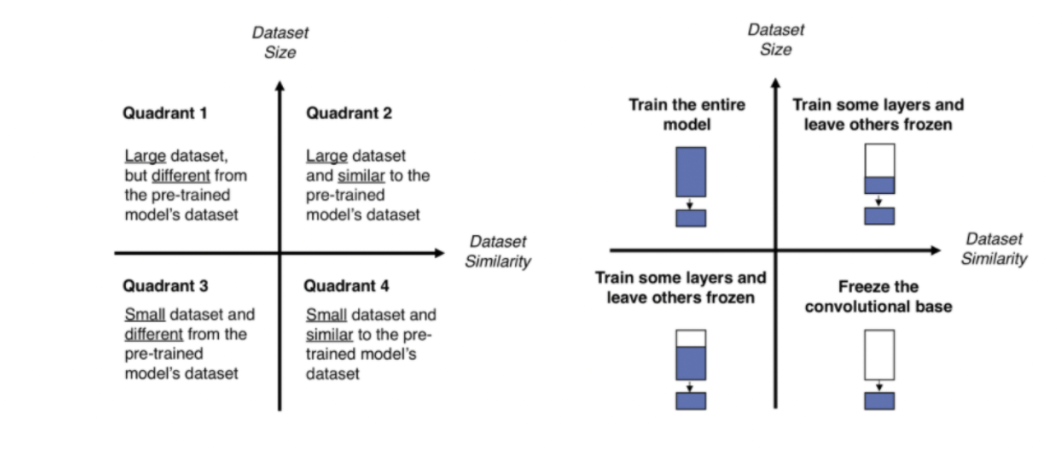
우리가 가지고 있는 (우리가 학습시킬) 데이터셋의 크기와, 이 데이터셋이 Pre-trained model이 기존에 학습한 데이터셋과 얼마나 유사한지에 따라 전략이 달라진다.
- 1) 우리 데이터셋이 크고, 유사성이 작다.
- 모델 전체를 학습시키는 것이 낫다.
데이터셋의 크기가 크기 때문에 충분히 학습이 가능하기 때문. 유사성이 작다고 해도 모델의 구조와 파라미터들은 여전히 재사용 가능하므로, 모델 전체를 학습 시켜주는 편이 낫다.
- 모델 전체를 학습시키는 것이 낫다.
- 2) 우리 데이터셋이 크고, 유사성이 크다.
- Pre-trained Model의 일부분과 Classifier를 학습시킨다.
사실 최적의 경우이기 때문에 모든 옵션을 선택할 수 있지만, 데이터셋이 유사하기 때문에 전체를 학습시켜도 괜찮지만, 강한 feature가 나타나는 Pre-trained Model의 뒷부분과 Classifier만 새로 학습시키는 것이 최적이다.
- Pre-trained Model의 일부분과 Classifier를 학습시킨다.
- 3) 우리 데이터셋이 작고, 유사성이 작다.
- Pre-trained Model의 일부분과 Classifier를 학습시킨다.
가장 나쁜 상황. 데이터가 적기 때문에, 적은 레이어를 Fine tuning하면 별 효과가 없고, 많은 레이어를 Fine-tuning했다가는 오히려 오버피팅이 발생할 것이다. 따라서 Pre-trained Model의 어느 정도를 새로 학습시켜야 할지를 적당히 잡아주어야 한다.
적당히 잡는다는 것 자체가 어려운 게 현실
- Pre-trained Model의 일부분과 Classifier를 학습시킨다.
- 4) 우리 데이터셋이 작고, 유사성이 크다.
- Classifier만 학습시킨다. 데이터가 적기 때문에 많은 레이어를 Fine tuning할 경우 오버피팅이 발생한다. 따라서 앞부분의 Feature Extraction은 그대로 쓰고, 최종 Classifier의 FC Layer들에 대해서만 Fine tuning을 진행한다.
그리고 앞부분의 Pre-trained Model을 재학습시키는 경우에는 미리 학습된 가중치를 잊지 않으면서도 추가로 학습을 해 나갈 수 있도록 learning rate(lr)을 작게 잡아주는 것이 바람직하다.
What happens if the fine-tuning is done twice?
You will likely be rewriting the parameters you learned for the first set to some degree. I'd think the easy solution would be to concatenate the two datasets and then use the combined dataset for 1 stage of training. Could also be worth trying the datasets individually followed by the combined dataset (so 3 total stages).
And a word about fine-tuning, you of course won't be fully rewriting the parameters when fine-tuning; if you did, there'd be no point in using a pre-trained model. Fine-tuning also can refer to further training of a whole model - it doesn't necessarily mean just the last layer, though I believe that's the general practice for the large pre-trained models because they are so cumbersome.
Fine-tuning을 2회 실시하게 되면 이미 학습된 것에 대해 Rewriting이 이루어질 것
즉, 큰 의미가 존재하지 않을 것이라는 의미
그리고 Fine-tuning은 모델 전체를 혹은 last layer만을 학습할 수 있다.
결국, 전략에 따라 Fine-tuning을 어떻게 가져갈 것인가도 중요할 것
🔬 2) 내 모델에서는 어떻게 쓰였나?
(1) 대회
일반적으로는 NLP Task를 다루기 때문에 fine-tuning 작업을 많이 진행했다
많은 문서를 이미 읽은 모델에 대해서 약간의 파라미터 수정을 진행해주는 것
해당 모델이 더 어려운 task에 대해서 pre-trained된 것이 아니라 더 많은 문서를 읽었으며 우리의 task에 적합하도록 변형시켜주는 것이 필요하므로 fine-tuning을 진행
또한 기본적으로 모델의 모든 부분에 대해 fine-tuning 작업을 진행했다.
이 때문에 scheduler와 learing rate 그리고 optimizer 조작이 매우 중요했다.
- 그렇지 않으면 기존에 pre-trained 된 것으로부터 크게 멀어질 수 있기 때문!
이 과정에서 KLUE R.E.의 경우 LSTM 혹은 Dense layer를 RoBERTa 구조에 더 깊게 쌓어주어 classification을 더 잘 하도록 구현했다.
결과적으로 성능이 더 나왔던 것도 모델 전체가 학습이 되는 동시에 Dense Layer도 학습을 진행했기 때문
(2) 프로젝트
프로젝트에서 역시 fine-tuning을 기본적으로 사용
하지만 이 과정에서 fine-tuning을 2회 사용하는 기법도 진행해보았다.
두 task의 난이도를 보았을 때 STS가 더 어렵고 데이터가 많으므로 처음 학습을 시킨 후에 2차적으로 Binary Classification을 진행했다.
Ablation Study로 두 데이터를 하나의 데이터로 만들어 한번에 학습시킨 것과의 비교를 하지 못한 것이 아쉬웠다. 이는 Binary Clssification이 워낙 쉬운 task 였기에 이를 Regression으로 교체해주는 것이 가장 수월했지만 쉽지 않았다.
이후 Self Training Method를 활용해 모델을 발전시키는 것도 생각해보았다.
3) 참고문헌
https://eehoeskrap.tistory.com/186
https://keras.io/guides/transfer_learning/
