Attention is all you need 논문을 리뷰하는데 있어서 참고가 될 만한 개념들을 정리했습니다. Transformer 논문 자체가 매우 어렵기 때문에 Attention 부터 시작해 흐름으로 파악하지 못한다면 이해하는 것이 매우 어렵습니다.
틀린 부분에 대한 지적은 언제나 환영입니다 :)
💡 Transformer의 Attention
트랜스포머에서는 총 3가지의 어텐션이 사용됩니다. 이는 아래 그림으로 분류됩니다.
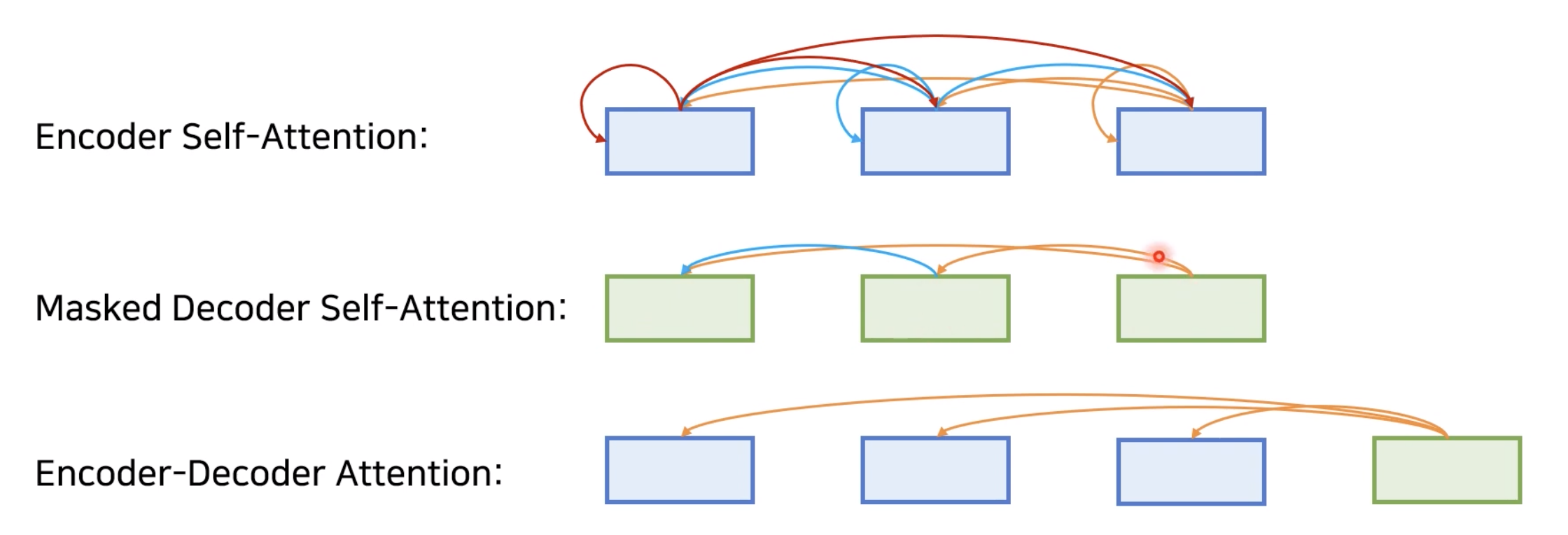
첫번째는 Encoder Self-Attention, 두번째는 Masked Decoder Self-Attention, 마지막으로 Encoder-Decoder Attention입니다. 셀프 어텐션은 본질적으로 Query, Key, Value가 동일한 문장에서 이루어지는 경우를 말합니다. 그러나 마지막 인코더-디코더 어텐션에서는 Query가 디코더의 벡터인 반면에 Key와 Value가 인코더의 벡터입니다.
💡 Encoder Self-Attention
어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구합니다. 이 유사도를 가중치로 하여 키와 맵핑되어있는 각각의 '값(Value)'에 반영해줍니다. 그리고 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴합니다. 즉, I love you라는 문장이 있을 때 I가 I love you 모든 단어에 대해 유사도를 구하고 그것을 값에 반영하고 최종적으로 가중합하여 리턴하는 것입니다.
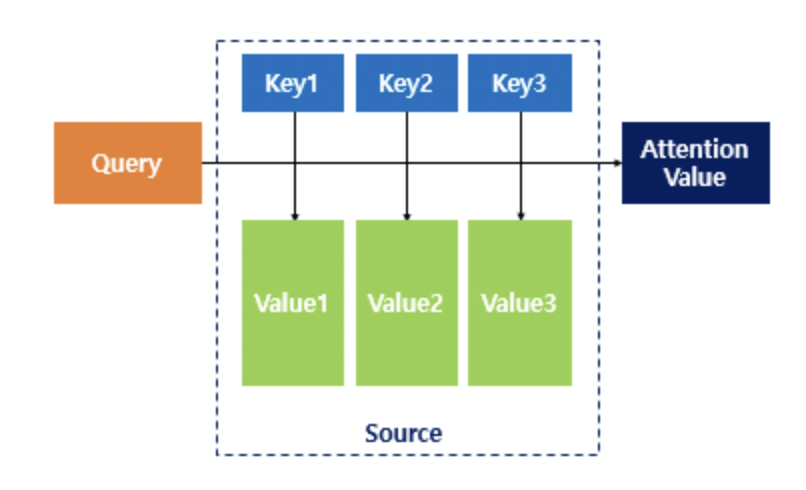
앞의 것이 일반적인 Attention 이라면, 셀프 어텐션(self-attention)은 어텐션을 자기 자신에게 수행합니다.
이와 같은 Self-Attention을 모든 시점에 모든 단어에 대해 진행하게 됩니다. 결과적으로 Q, K, V는 입력 문장의 모든 단어와 벡터들이 되고 그것으로부터 Attention을 모두 구해주게 되는 것입니다. 이러한 Self-Attention을 모든 단어에 대해 진행해주면 Attention을 통해 리턴된 벡터는 단어들간의 관계를 잘 파악하고 있습니다.

우리가 번역이나 NLP를 진행함에 있어 중요한 부분은 이렇게 단어와 단어간의 관계를 확실히 파악하는 것입니다. RNN이 단어간의 간격이 먼 단어들에 대해 잘 관계를 파악하지 못하자(Long term Dependecy) LSTM이 등장했듯이 Self-Attention을 활용하면 본래 단어와도 잘 연관이 되지만 문장 내 다른 단어들과의 유사도도 잘 파악할 수 있습니다.
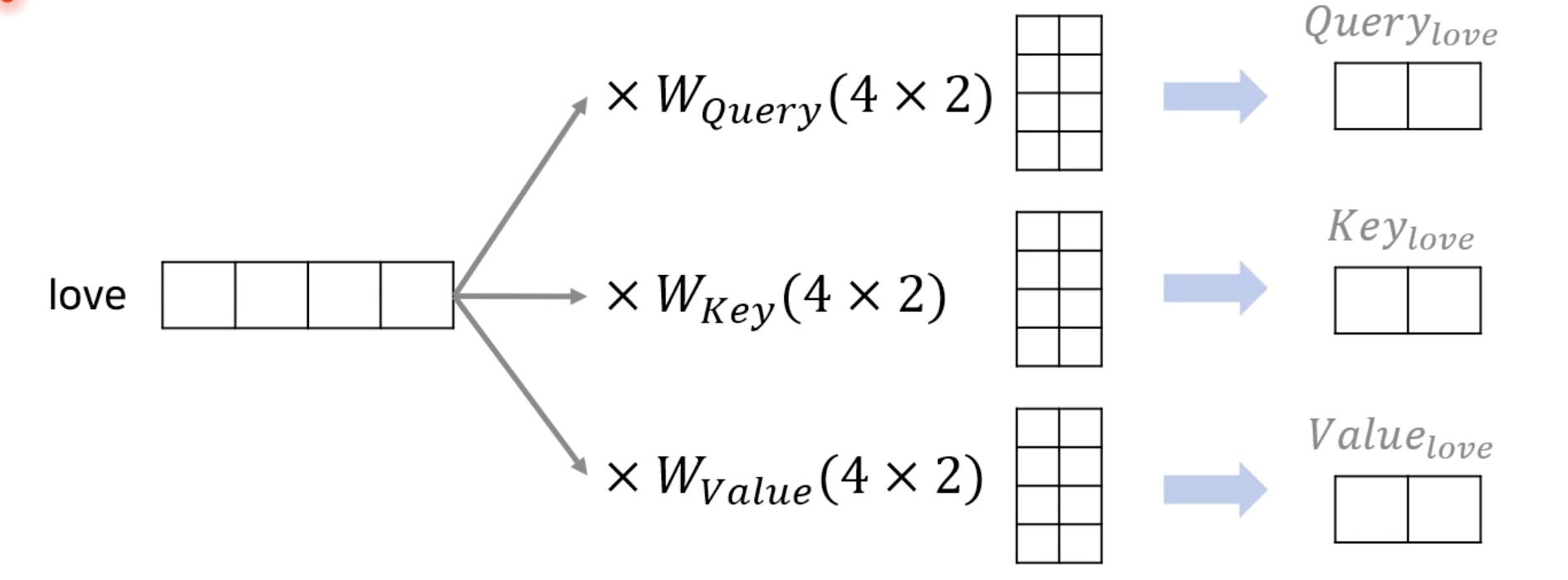
이렇게 진행하기 위해서 self-attention은 인코더의 초기 입력인 의 차원을 가지는 단어 벡터들을 사용하여 셀프 어텐션을 수행하는 것이 아니라 우선 각 단어 벡터들로부터 Q벡터, K벡터, V벡터를 얻는 작업을 거칩니다. 이때 이 Q벡터, K벡터, V벡터들은 초기 입력인 의 차원을 가지는 단어 벡터들보다 더 작은 차원을 가지는데, 논문에서는 =512의 차원을 가졌던 각 단어 벡터들을 64의 차원을 가지는 Q벡터, K벡터, V벡터로 변환하였습니다.
초기 이 512차원인 것에 대해서는 뚜렷한 이유는 없으나 64라는 값은 트랜스포머의 또 다른 하이퍼파라미터인 num-heads로 인해 결정됩니다. 트랜스포머는 을 num_heads로 나눈 값을 각 Q벡터, K벡터, V벡터의 차원으로 결정합니다. 이 부분은 Self-Attention이 단일하게 이루어지는 것이 아니라 Multihead로 이루어지기 때문입니다. 논문에서는 num_heads를 8로하였습니다.
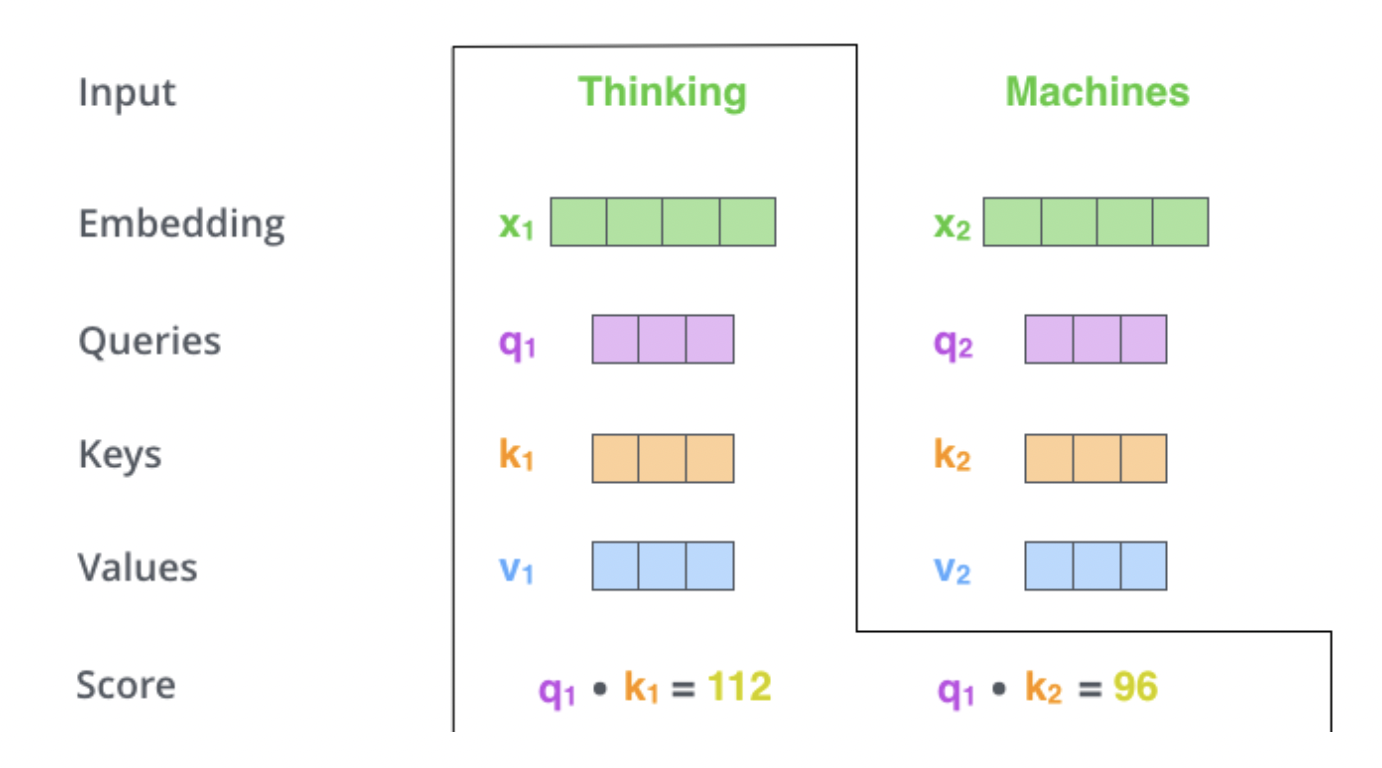
아래의 그림은 I love you라는 문장을 3 x 4 벡터로 임베딩한 후에 Q, K, V를 구하는 것입니다. 기존의 벡터로부터 더 작은 벡터는 가중치 행렬을 곱하므로서 완성됩니다. 각 가중치 행렬은 * /num-heads)의 크기를 가집니다. 이 가중치 행렬은 훈련 과정에서 학습됩니다. 논문과 같이 = 512이고 num_heads =8라면, 각 벡터에 3개의 서로 다른 가중치 행렬을 곱하고 64의 크기를 가지는 Q, K, V 벡터를 얻어냅니다. 모든 단어 벡터에 위와 같은 과정을 거치면 I love you는 각각의 Q, K, V 벡터를 얻습니다.
Q, K, V 벡터를 얻은 후 기존의 Attention mechanism과 동일하게 진행합니다. 각 Q벡터는 모든 K벡터에 대해서 어텐션 스코어를 구하고, 어텐션 분포를 구한 뒤에 이를 사용하여 모든 V벡터를 가중합하여 어텐션 값 또는 컨텍스트 벡터를 구하게 됩니다. 그리고 이를 모든 Q벡터에 대해서 반복합니다.
트랜스포머에서는 어텐션 챕터에 사용했던 내적만을 사용하는 어텐션 함수 가 아니라 여기에 특정값으로 나눠준 어텐션 함수인 를 사용합니다. 이러한 함수를 닷-프로덕트 어텐션(dot-product attention)에서 값을 스케일링하는 것을 추가하였다고 하여 스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention)이라고 합니다.
이렇게 해주는 이유는 최종적으로 구해진 벡터에 대해 Softmax를 구해주어야 하며 이들을 학습시키기 위해서는 최종적으로 역전파를 진행해야 합니다. 이때 Softmax 특성상 중앙의 값은 기울기가 크지만 양 끝단은 기울기가 매우 작기 때문에 Gradient가 Vanishing 되는 것을 방지하기 위해 이러한 방식을 사용합니다.
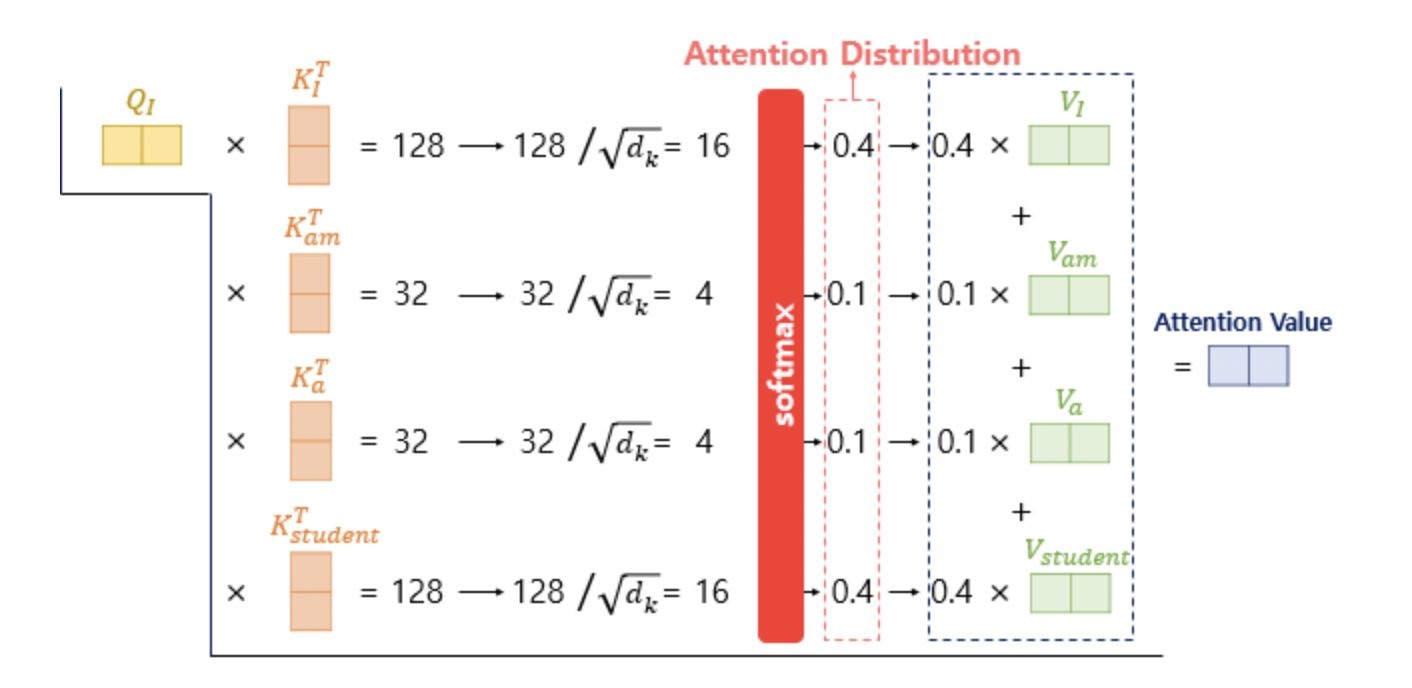
위의 그림은 단어 I에 대한 Q벡터가 모든 K벡터에 대해서 어텐션 스코어를 구하는 것을 보여줍니다. 그리고 어텐션 스코어에 소프트맥스 함수를 사용하여 어텐션 분포(Attention Distribution)을 구하고, 각 V벡터와 가중합하여 어텐션 값(Attention Value)을 구합니다. 이를 단어 I에 대한 어텐션 값 또는 단어 I에 대한 컨텍스트 벡터(context vector)라고도 할 수 있습니다. 모든 Q벡터에 대해서도 동일한 과정을 반복하여 각각에 대한 어텐션 값을 구합니다.
🛠 단순화
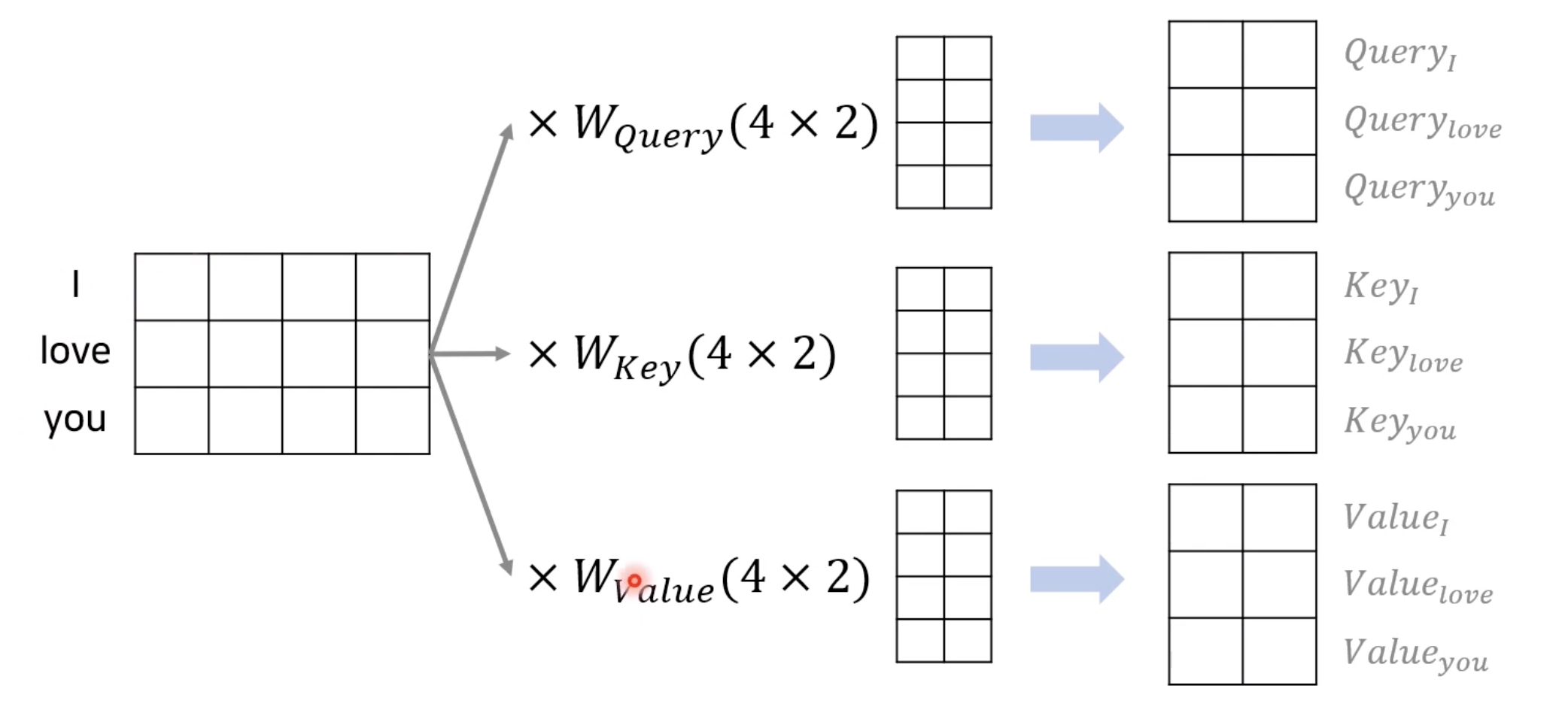
사실 각 단어에 대한 Q, K, V 벡터를 구하고 어텐션을 수행하였던 과정들은 벡터 연산이 아니라 행렬 연산을 사용하면 일괄 계산이 가능합니다. 실제로 모델 내에서도 행렬 연산으로 구현됩니다. 우선, 각 단어 벡터마다 일일히 가중치 행렬을 곱하는 것이 아니라 문장 행렬에 가중치 행렬을 곱하여 Q행렬, K행렬, V행렬을 구합니다.
여기서 Q행렬을 K행렬을 전치한 행렬과 곱해줍니다. 이렇게 되면 각각의 단어의 Q벡터와 K벡터의 내적이 각 행렬의 원소가 되는 행렬이 결과로 나옵니다.
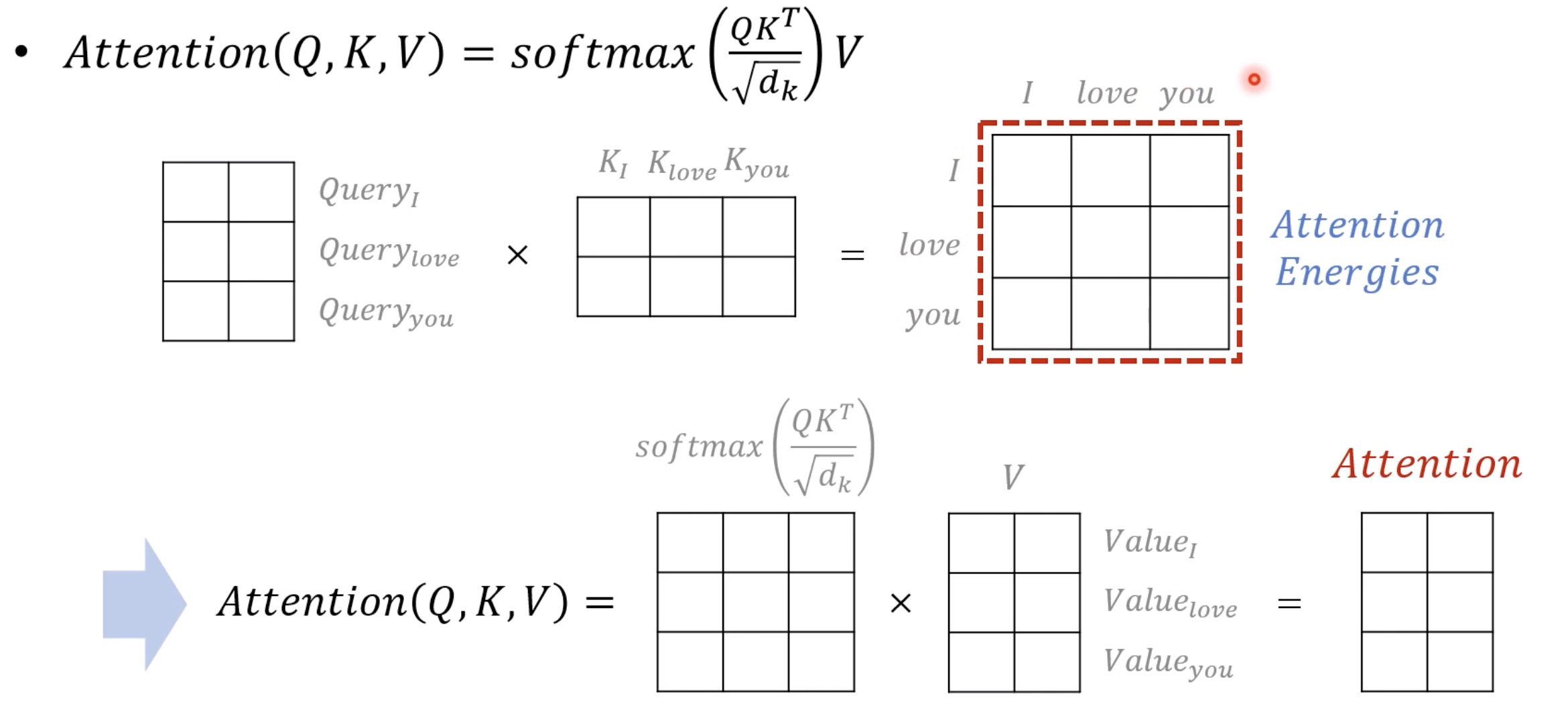
위의 그림의 결과 행렬의 값에 전체적으로 를 나누어주면 이는 각 행과 열이 어텐션 스코어 값을 가지는 행렬이 됩니다. 이후ㅡ=, 간단하게 어텐션 스코어 행렬에 소프트맥스 함수를 사용하고, V행렬을 곱하면 완성됩니다. 이렇게 되면 각 단어의 어텐션 값을 모두 가지는 어텐션 값 행렬이 결과로 나옵니다.
위를 단순화하면 아래의 그림과 같습니다. 해당 식은 실제 트랜스포머 논문에 기재된 아래의 수식과 정확하게 일치하는 식입니다.
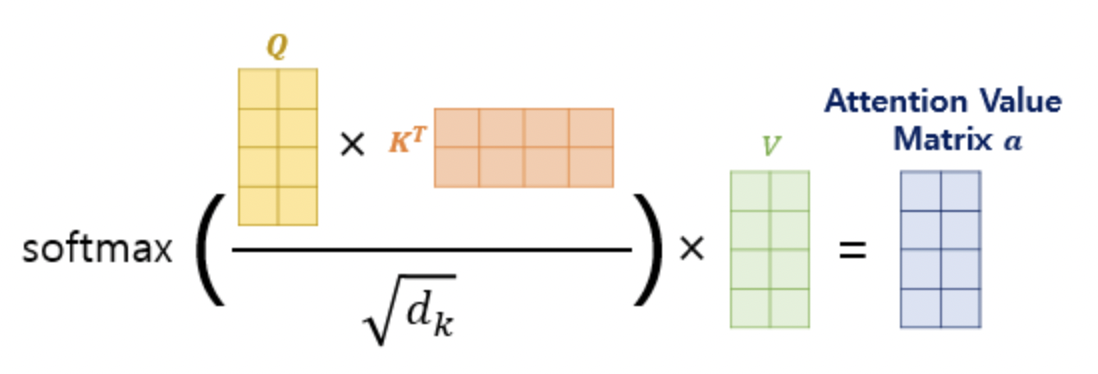
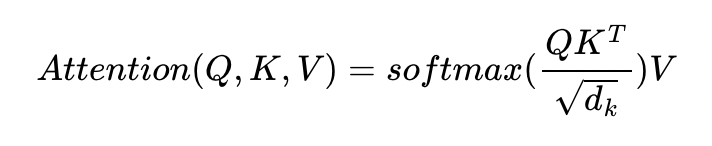
🔥 Multi-head Attention
Encoder Self-Attention은 최종적으로 Multi-head Attention로 이루어집니다. 앞서 진행한 어텐션에서는 의 차원을 가진 단어 벡터를 num-heads로 나눈 차원을 가지는 Q, K, V벡터로 바꾸고 어텐션을 수행하였습니다. 논문 기준으로는 512의 차원의 각 단어 벡터를 8로 나누어 64차원의 Q, K, V 벡터로 바꾸어서 어텐션을 수행한 셈인데, 이는 multi-head attention을 위해서 입니다.
트랜스포머 연구진은 하나의 Attention Vector를 구하는 것보다 여러번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단하였습니다. 그래서 의 차원을 num-heads개로 나누어 /num-heads의 차원을 가지는 Q, K, V에 대해서 num-heads개의 병렬 어텐션을 수행합니다. 이때 각각의 어텐션 값 행렬을 어텐션 헤드라고 부릅니다. 이때 가중치 행렬 의 값은 8개의 어텐션 헤드마다 전부 다릅니다.
이렇게 어텐션을 병렬로 수행하게 되면 여러 시각으로 정보들을 수집할 수 있다는 즉, 여러 관점의 관계를 생성할 수 있게 됩니다. 각 어텐션 헤드는 전부 다른 시각에서 보고있기 때문입니다.
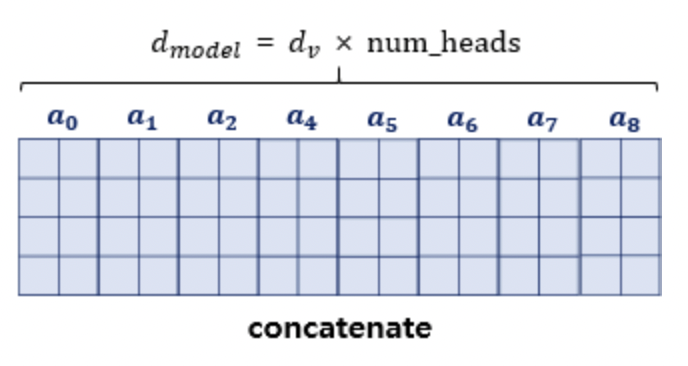
병렬 어텐션을 모두 수행하였다면 모든 어텐션 헤드를 concatenate합니다. 최종적으로 모두 연결된 어텐션 헤드 행렬의 크기는 가 됩니다.
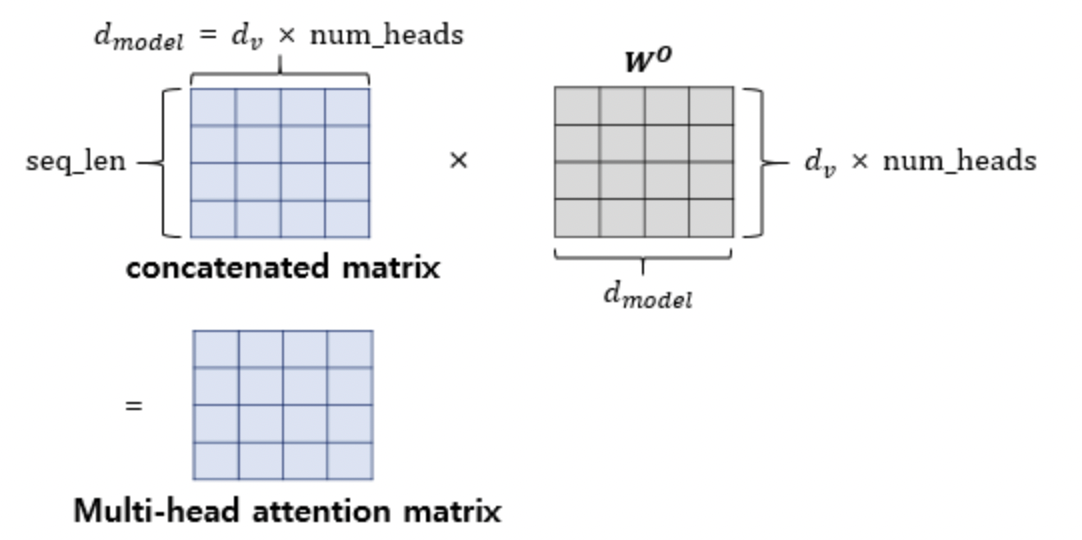
어텐션 헤드를 모두 연결한 행렬은 또 다른 가중치 행렬
을 곱하며 최종 결과물을 내보냅니다. 이때 결과물인 멀티-헤드 어텐션 행렬은 인코더의 입력이었던 문장 행렬의 크기와 동일합니다.
다시 말해 인코더의 첫번째 서브층인 멀티-헤드 어텐션 단계를 끝마쳤을 때, 인코더의 입력으로 들어왔던 행렬의 크기가 아직 유지됩니다. 첫번째 서브층인 멀티-헤드 어텐션과 두번째 서브층인 포지션 와이즈 피드 포워드 신경망을 지나면서 인코더의 입력으로 들어올 때의 행렬의 크기는 계속 유지되어야 합니다. 기본적으로 트랜스포머는 동일한 구조의 인코더를 쌓은 구조입니다. 따라서 인코더의 input과 output의 결과의 차원이 동일한 크기이기 때문에 반복적인 수행이 가능합니다.
💡 Masked Decoder Self-Attention
Decoder의 첫 번째 sub layer은 encoder와 동일한 self-attention이다. 그러나 decoder의 Self-attention과는 다른 조건이 더 붙습니다. 그것은 Decoder는 sequence를 출력하는 역할을 하기 때문에 등장하지 않은 단어에 대한 계산을 하지 못하도록 막는 것입니다.
예를 들어, "I am a student" 문장을 번역하는데 decoder가 "I am" 뒤에 올 단어를 예측할 차례일 때 세 번째 단어를 예측함에 있어 뒤이어 등장하는 "student"를 보고 결정해서는 안된다는 것입니다. 이러한 식으로 진행하게 되면 Cheating의 우려가 있으며 모델 자체가 정답만을 보고 예측하는 Overfitting의 위험성도 있습니다.
이를 위해 Attention은 모든 단어들을 통해 구해주지만, 후처리적으로 아직 등장하지 않은 단어들의 softmax값들을 0으로 만들어주는 것입니다.
그렇게 되면 softmax 값의 합이 1이 되지 않으므로 다시 Normalize를 진행해주게 됩니다.
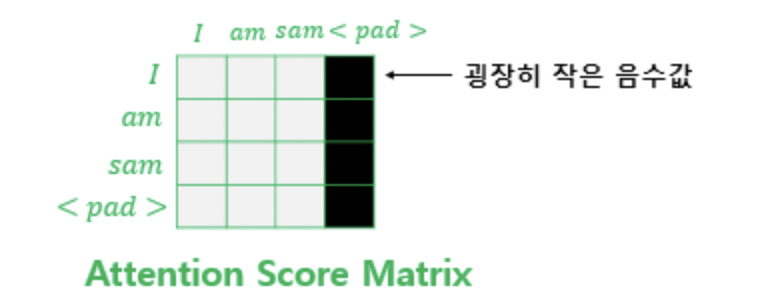

위의 사진처럼 마스킹을 하는 방법은 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수값을 넣어주는 것입니다.
마스킹 위치에는 매우 작은 음수 값이 들어가 있으므로 어텐션 스코어 행렬이 소프트맥스 함수를 지난 후에는 해당 위치의 값은 0이 되어 단어 간 유사도를 구하는 일에 masking된 곳은 반영이 거의 되지 않습니다.
참고 : seq2seq의 decoder에 사용되는 RNN 계열의 신경망은 입력 단어를 매 시점마다 순차적으로 받으므로, 다음 단어 예측에 현재 시점 이전에 입력된 단어들만 참고할 수 밖에 없습니다.
그러나 transformer는 문장 행렬로 입력을 한 번에 받기 때문에 현재 시점의 단어를 예측하고자 할 때, 입력 문장 행렬로부터 미래 시점의 단어까지도 참고할 수 있는 상황이 벌어질 수 있습니다.
아래의 사진은 최종적으로 Encoder와 Decoder에서 Attention이 어떻게 이루어지는 지를 보여주고 있습니다.

참고 : https://wikidocs.net/31379
https://www.youtube.com/watch?v=Yk1tV_cXMMU
https://better-tomorrow.tistory.com/entry/Transformer-Decoder-Masked-Self-Attention
https://www.youtube.com/watch?v=AA621UofTUA&list=PLRx0vPvlEmdADpce8aoBhNnDaaHQN1Typ&index=9
