
너무 좋아서 소리지르는 겁니다ㅎㅎ,,,
ELMo 논문의 Evaluation과 Analysis 부분을 다루고자 한다. 내용 자체가 많다기 보다는 논문 자체의 해석이 쉽지 않은 편이라 어떤 의미를 전달하려고 했는지를 중점으로 얘기해보고자 한다.
앞서, ELMo의 구조와 학습 방식에 대해서는 상편에서 다루었으므로 이전 포스트를 참고하자.
🔥 ELMo의 전반적 성능
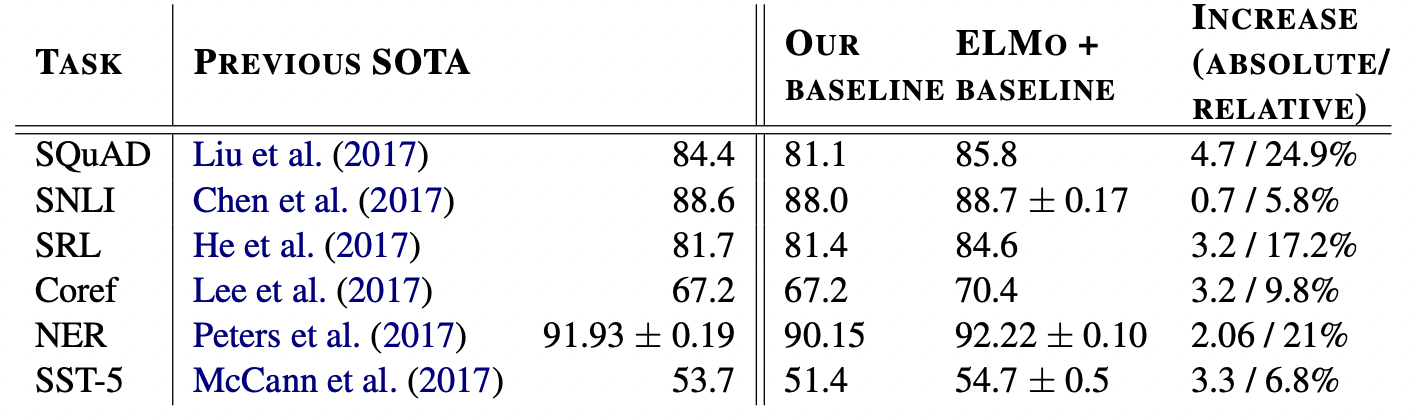
해당 내용은 이 표로 요약이 가능하다. ELMo를 추가하기 전 SOTA를 보이는 모델에 ELMo를 추가했을 때 성능도 상승했고 Error도 감소가 되었다. 모든 분야에 대해서 성능이 좋았는데 기존 논문의 baseline과 다르게 설정한 부분도 있었다.
보통 embedding에서 self-attention 기법을 추가하거나, local inference 추가하는 방식 등 기존의 모델에서 약간씩의 발전된 baseline model을 만들었다. 그리고 그것의 성능과 ELMo를 추가했을 때의 성능을 비교했다.
영역의 순서는
- Question answering = 질의응답
- Textual entailment = 주어진 전제에서 가설이 참인지 판단하는 문제
- Semantic role labeling = 의미역 결정
- Coreference resolution = 상호참조
- Named entity extraction = 개체명 인식
- Sentiment analysis = 감성 분석
🔬 성능에 대한 분석
해당 챕터에서는 성능이 어떨 때 상승하고 어떠한 학습이 되는지를 다루었다. Deep contextual representation 을 사용하는 것이 다양한 task의 성능을 향상시킬 수 있다는 것을 보였다.
구조를 분석해보면 두 개의 Intrinsic evaluation을 이용해서 lower layers가 문법적인 특징을 학습하고, higher layers이 문맥을 학습한다는 것을 보인다. 이를 통해 기존의 CoVe 보다 좋은 성능을 보이는 문맥 표현을 학습할 수 있다는 것을 알 수 있다.
마지막으로, ELMo representation이 어디에 추가되는지에 따라 다른 효과가 발생하며 이에 따라 task 마다 더 좋은 위치가 달라지게 된다.
Weighting shcemes λ 에 대해서
Regularization parameter인 λ는 그 수치에 달라서 영향력이 달라지기에 매우 중요한 역할을 수행한다. 해당 값이 1과 같이 매우 큰 경우 전체 weight function이 단순히 평균을 내는 역할을 수행하게 되고, 값이 매우 작아지면, 각 층에 대한 weight 값이 다양하게 적용된다.
즉, 수치가 크면 종합적인 의미의 embedding이 작으면 다양한 값을 통한 embedding이 적용된다고 생각하면 편하다.
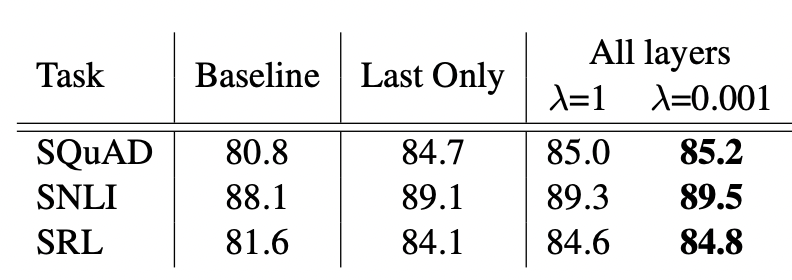
이 표는 λ의 수치에 따라 달라지는 성능이다. 거의 대부분(모두 그런 거는 아님)의 영역에서 λ 값이 작을 때 더 좋은 성능을 보이고 있었다. 이는 서로 다른 각 층의 weight을 학습하도록 하는 것이 더 좋은 성능을 제공한다는 것을 의미한다.
ELMo 위치에 대해서

ELMo는 결과적으로 Embedding이기 때문에 그것이 들어가야 할 위치가 정해져있지는 않다. 대부분의 Task에서 nput과 output에 모두 ELMo를 추가한 경우 성능이 더 좋아졌다. 특히, SQuAD와 SNLI의 경우, biRNN 이후에 Attention을 사용하기 때문에 output에 ELMo representation을 추가하는 것이 성능을 향상시켰다.
이것의 의미는 ELMo를 통해 문맥적 의미를 파악한 이후 attention 사용은 문맥적 의미를 포함한 후의 관계에 대한 학습이기에 더욱 효과적이지 않은가 싶다.
반면, SRL의 경우에는 input에만 있는 것이 가장 좋은 성능을 보였다. SRL의 경우 그 단어가 문장에서 어떤 역할을 하고 있는지가 중요하기 때문에 task-specific 즉, context representation이 중요하기 때문이라고 말한다.
biLM layer 별로 어떤 내용을 담고 있을까
biLM이 효과적이기 위해서는 다의어에 대해 문맥에서 어떠한 정보로 사용되었는지에 대한 정보를 갖고 있어야 한다.
WSD는 다의어의 의미를 구분짓는 task로 embedding이 얼마나 semantic 정보(문법 정보)를 잘 담고 있는지에 대한 지표이다.
가장 좋은 성능을 보였다는 것 외에도 주목할만한 것은 ELMo의 first LSTM layer의 output보다는 second layer (top layer)의 output이 WSD에서 좋은 성능을 보였다는 점이다.
POS tagging은 word의 품사를 tagging하는 task로 embedding이 얼마나 syntax 정보(문맥 정보)를 잘 담고 있는지에 대한 지표이다.
WSD와는 다르게 오히려 first LSTM layer의 output이 top layer의 output보다 POS tagging에서 더 좋은 성능을 보였다.
결과적으로 ELMo의 layer 별로 담고 있는 정보가 상이하다.
ELMo의 특이점
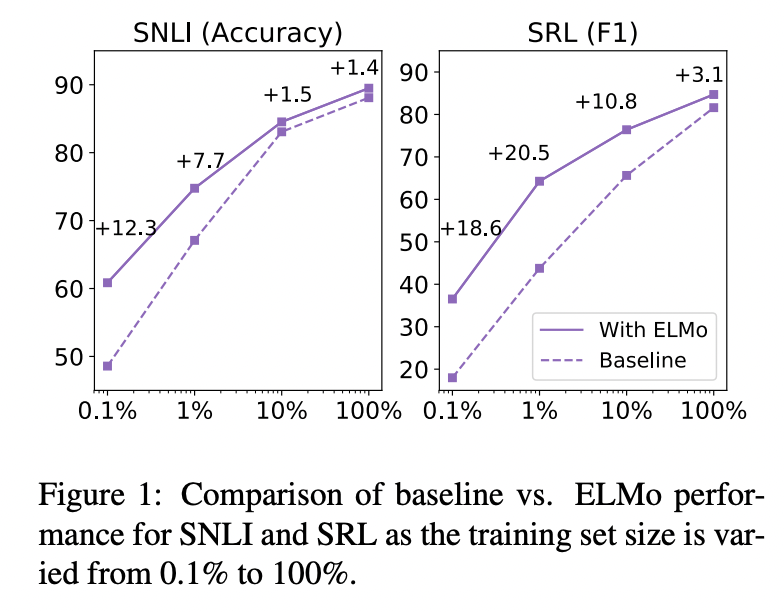
ELMo를 통한 학습은 일정 수준 이상의 성능 달성에 필요한 parameter update 횟수 및 전체 training set size를 획기적으로 줄여준다.
위의 그림에서도 볼 수 있듯이 데이터 셋을 조금만 학습했음에도 불구하고 매우 좋은 성능을 보인다는 것이다.
심지어 SRL task에서는 ELMo를 사용한 model이 training dataset의 1%을 학습했을 때 달성한 성능 수치와 baseline model이 training dataset의 10%를 학습했을 때의 성능 수치가 유사하다.
ELMo 논문에서의 특이한 Visualization
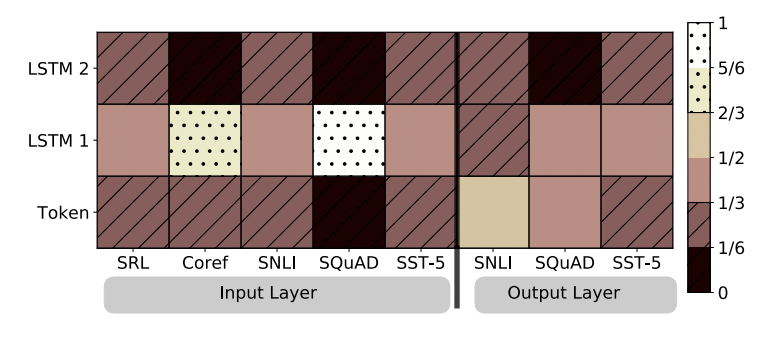
해당 heatmap은 어떤 분야에서 ELMo를 어느 위치에 추가하는 것이 좋은지 보여주는 것이다. 이는 softmax-normalized parameter 를 시각화한 것인데, 보통 first LSTM layer가 더 좋은 성능을 보인다.
특히, SQuAD에서 이러한 경향성이 가장 두드러지게 나타났다. 그와 달리 ELMo가 output에 사용된 경우에는 weight가 균형있게 분배되기는 했지만 대체로 낮은 layer가 더 좋게 나왔다.
✏️ 후기
네이버 부스트캠프 competition으로 바쁜 와중에 그래도 1주일 1논문을 완료했다. 후.. 수고했다 나 자신... 다음주는 GPT-1을 다룰 예정이며, 이번 논문보다 재밌었으면 했다. 뭔가 LSTM을 쓴다는 것 자체가 되게 예전 모델처럼 느껴지기도 했다. 아무튼 바쁜 와중에 리뷰 끝~~
참고 : https://cpm0722.github.io/paper-review/deep-contextualized-word-representations
