지난주부터 CV 논문 리뷰를 시작했다. 그것의 첫 시작으로 AlexNet을 선택했다. 지금까지 NLP 위주로 공부를 진행해왔기에 조금은 어색하기도 하지만 딥러닝을 이해하기 위해서는 넓은 분야에 대해 알아야 하기 때문에 도전해보았다.
CV 논문을 리뷰하다 보면 어려운 부분도 많았고 특히나 inductive bias나 kernel method와 같은 그동안 확실히 이해하지 못한 부분들이 등장해 이 부분에 대한 공부도 추가적으로 해보고자 한다.
📌 간단한 요약
AlexNet은 CV의 영역을 딥러닝으로 끌어온 최초의 모델이자 논문으로 볼 수 있다. 이 논문이 근간이 되어 CNN을 기반으로 하는 모델들이 많이 등장하게 되었다. 그와 동시에 multi-GPU를 사용한 방식과 최근에도 사용되는 augmentation과 dropout과 같은 regularization 방식을 사용했다는 점에서 의의가 있다. 다만, 이제는 사용되지 않는 큰 filter들과 구조를 사용하기는 했다.
💡 1. Introduction
객체 인식에 대한 현재 접근 방식은 기계 학습 방법을 필수적으로 사용한다. 이러한 모델의 성능을 향상시키기 위해 보다 큰 데이터 세트가 필요하고 더 강력한 모델을 배우며 overfitting을 방지하기 위해 더 나은 기술과 같은 것들을 사용한다. 하지만 CIFAR과 같은 수만개의 이미지로 이루어진 데이터셋은 상대적으로 클래스의 수가 적고 학습에 큰 의미가 없다.
특히 라벨 보존 변형으로 augmentation된 경우, 데이터의 증가로 문제 해결을 잘 할 수 있도록 만들 수 있다.
예를 들어, MNIST 숫자 인식 작업에서 현재까지 나온 모델의 최고 오류율은 인간의 능력과 유사한 수준이다. 그러나 실질적인 객체인식에는 상당한 변동성을 나타내므로 이를 인식하려면 훨씬 더 큰 훈련 세트를 사용 해야 한다. 최근에는 레이블이 설정된 수 백만 개의 이미지 데이터 세트를 확보가 가능해졌다.
Imagenet과 같은 수 백만개 이미지에서 수 천 개의 이미지에 표현된 객체에 대해 학습하기 위해서는 큰 학습 능력을 갖춘 모델이 필요하다. 그러나 ImageNet으로도 객체인식 문제를 포괄할 수 없으므로 모델에 없는 모든 데이터를 보완 할 수 있는 사전 지식이 많이 있어야 한다.
- 즉, 모델이 거의 모든 사진에 대해 잘 학습해야 한다는 것
- inductive bias가 뛰어나야 한다.
이때 CNN은 이러한 것을 가능하게 한다. CNN을 사용하면 network의 깊이와 폭을 변경하여 용량을 제어 할 수 있으며, 이미지의 특성(여기서 특성은 통계의 정상성 및 픽셀 종속성의 국소성)에 대해 강력하고 대부분 정확한 가정을 하는 모습을 보인다.
- 즉, 이미지의 통계적 수치와 각 픽셀이 이루는 국소적인 특성을 잘 파악한다는 것
CNN은 상당히 매력적이고 구조 또한 효율적이지만, 고해상도 이미지에 대규모로 적용하기에는 여전히 엄청난 비용이 든다. 이를 위해 2개의 GPU로 병렬 학습을 실시했다.
이 논문의 구체적인 기여는 아래와 같다.
- 연구진은 ILSVRC-2010 및 ILSVRC-2012 대회에 사용 된 ImageNet 데이터로 AlexNet을 학습시켰고 이를 통해 SoTA 달성.
- 2D 컨볼루션 신경망 훈련에 내재 된 다른 모든 작업에 대해 최적화 된 GPU 구현을 작성하여 공개적으로 사용할 수 있게 했다.
- alexnet은 성능을 향상시키고 훈련 시간을 단축시키는 여러 특이한 특징들을 포함하고 있는데, 이는 section 3에 다룸
네트워크 규모가 120만 개에 달하는 훈련 된 예에서도 과도하게 큰 문제를 야기 시켰으며, 연구진은 overfitting을 방지하기 위해 몇 가지 효과적인 기술을 사용했으며, 이는 4번 챕터에 설명되어 있다. 우리의 최종 네트워크는 5개의 컨볼루션 레이어와 3개의 완전 연결 레이어를 포함하고 있으며, 이 깊이는 중요한 것으로 보인다
- 사실 안 중요함
연구 결과 컨볼루션 레이어를 하나라도 제거하면 성능이 저하된다는 것을 발견했다고 한다.
- 이는 그냥 레이어의 깊이가 낮아지니 당연한 결과
- 이때 각각 모델 매개변수의 1% 이하 포함한다
📦 2. Dataset
ImageNet은 가변 해상도 이미지로 구성되며, 시스템에는 일정한 입력 크기가 필요하다.
따라서 이미지를 고정 해상도 256 256 으로 줄였고. 직사각형 이미지를 고려할 때 먼저 짧은 면의 길이가 256이 되도록 이미지의 크기를 조정한 중앙 부분으로 256 256이 되도록 잘랐다.
We did not pre-process the images in any other way, except for subtracting the mean activity over the training set from each pixel. So we trained our network on the (centered) raw RGB values of the pixels.
각 픽셀에서 훈련 세트에 대한 mean activity을 빼는 것을 제외하고는 다른 방법으로 이미지를 사전 처리하지 않았다. 즉, 연구진은 중심화된 raw한 픽셀 값 에 대해 네트워크를 학습했다.
- RGB마다 평균수치를 빼줘서 정규화를 했다는 것 같다.
🛠 3. Architecture
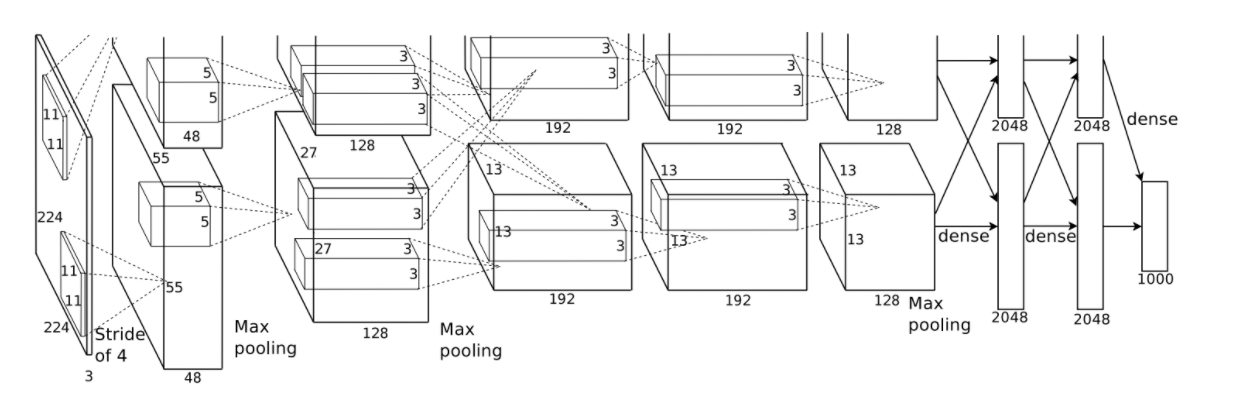
기본적으로 8개의 학습 레이어(5개의 convolution layer와 3개의 fc layer)가 포함된다.
3.1. ReLU Nonlinearity
입의 함수로 뉴런의 출력 f를 모델링하는 방법은 아래와 같다
gardient descent 에 따른 훈련 시간의 관점에서, 이러한 포화 비선형성 함수는 비포화 비선형성 함수 보다 훨씬 느리다.
- saturation이란?
- 일정 수치 이상 혹은 이하가 될 때 기울기 값이 0이 되어 학습이 안 되는 현상
연구진은 이에 비선형 성을 갖는 뉴런을 ReLU로 activation function을 지정하고 실험을 진행했다. 이를 사용한 것은 tanh를 사용하는 것보다 몇 배 빠르게 훈련이 가능했다.
이는 아래 그림으로 볼 수 있고 압도적으로 적은 epochs로 학습이 가능함을 보여준다.
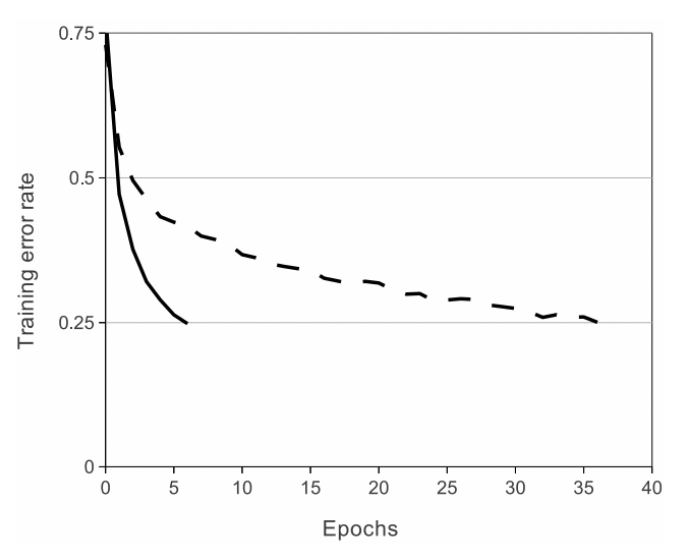
만약 전통적인 saturation activation function을 사용했다면 alexnet 을 실험하는 것은 불가능했다는 것을 의미한다. 일례로 비선형 함수인 는 특히 Caltech-101 데이터 세트에 대한 평균 풀링과 함께 대비 유형 정규화와 잘 작동한다고 주장한다.
- 대비 유형 정규화란?
- 수치적인 대비성을 보고 정규화를 시켜주는 것
- 최근에는 batch normalization이나 group을 사용하기에 큰 의미는 없다.
빠른 학습은 큰 데이터 집합에 대해 훈련 된 큰 모델의 성능에 큰 영향을 미친다.
- 더 빠른 optimization으로 더 많은 실험을 할 수 있고 overfitting을 더욱 방지할 수 있다.
3.2 Training on Multiple GPUs
당시의 GPU로는 많은 데이터와 큰 모델을 학습하는 것이 어려웠다. 따라서 이를 단일 메모리가 아닌 해결하고자 GPU를 두 배로 늘렸다.
연구진이 사용한 병렬화는 기본적으로 각 GPU에 절반의 커널(또는 뉴런)을 추가하고 하나의 트릭을 추가합니다. 그것은 GPU는 특정 계층(일부 계층)에서만 통신하도록 만든 것.
- 이는 예를 들어 계층3의 커널이 계층 2의 모든 커널맵에서 입력을 받는다는 것을 의미
모델의 구조는 “columnar cnn”과 열이 독립적이지 않다는 점을 제외하고 다소 유사합니다.
- 3번째 conv layer에서는 종합적인 처리가 이루어지기 때문에 완전히 독립적인 columnar cnn과는 다소 거리가 있다.
이러한 병렬 처리는 하나의 GPU에서 훈련 된 것과 비교하면 top-1 및 top-5 오류율을 1.7% 및 1.2% 줄인다. 더불어 2-GPU net은 1-GPU net2보다 훈련하는데 약간 더 적은 시간이 걸린다.
3.3 Local Response Normalization
ReLU는 saturation를 방지하기 위해 입력 정규화를 할 필요가 없다는 특징을 갖고 있다.
- -6 ~ 6의 범위를 넘게 되면 기울기가 0이 되어 weight update가 사라지는 현상
ReLU는 sample에서 양수가 들어오기만 하면 뉴런이 활성화가 된다. 그럼에도 Local Response Normalization이 일반화에 도움이된다. 이에 아래와 같은 정규화를 도입했다.
는 위치 (x, y)에 커널 i를 적용한 다음 ReLU 비선형 성을 적용하여 계산 된 뉴런의 결과물을 나타낸다
- convolution → activation의 결과로 보인다
- 그런데 kernel i란 무엇인가?
그리고 그것에 정규화 된 결과물인 는 해당 위치에 커널을 거칠 때 겹쳐지는 이웃 픽셀들을 의미한다.
그리고 N은 해당 layer의 총 커널 수이다.
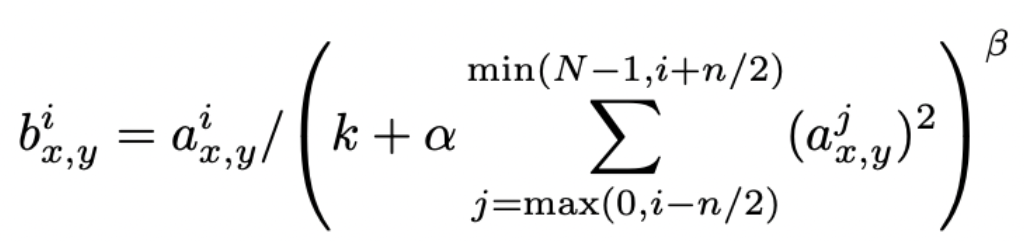
커널 맵의 순서는 물론 임의적이며 훈련이 시작되기 전에 결정된다. 이는 하나의 커널이 높은 수치가 나타나면 주변과 경쟁하도록 만들어 정규화를 진행해준다.
- 무슨 말이냐 하면 하나의 커널이 높은 수치를 나타내지 못하도록 주위의 뉴런들과 normalization 시켜주어 일정 수치로 유지시켜주는 현상
상수 k, n, α 및 β는 검증 세트를 사용하여 값이 결정되는 하이퍼 파라미터이다. 논문에서는 k = 2, n = 5, α = 10−4 및 β = 0.75를 사용했다고 한다.

특정 계층에 ReLU 비선형 성을 적용한 후이 정규화를 적용했다. 이 방식은 국소 대비 정규화(local contrast normalization) 체계와 조금 유사하다.
- 그니까 일정 위치에 대해 대비가 너무 크지 않도록 정규화를 해주는 방식
하지만 우리는 평균 결과물을 빼지 않기 때문에 "brightness normalization"라고 더 정확하게 불릴 것
- 주변 농도에 맞추어서 너무 튀지 않도록 정규화를 해준다는 것
이 결과로 높은 성능을 얻을 수 있었다.
- 하지만 현재는 잘 쓰이지는 않는다.
3.4 Overlapping Pooling
풀링계층은 같은 커널맵 내의 인접한 뉴런들을 압축하여 출력을 내보낸다. 전통적으로 인접한 뉴런들은 중복되지 않게 풀링계층을 통과시킨다. 정확하게 말하면 s픽셀단위로 이루어진 풀링 그리드가 중심에서 z x z 크기의 인접 뉴런들을 요약하며 s = z 으로 설정하는 것이 CNN의 기초적인 풀링 방법이다.
- 그룹이 중복되지 않도록 구현
하지만 연구진은 s = 2, z = 3으로 s<z이되게 설정하여 풀링되는 뉴런들의 중복을 허용했으며 이를 통해 과적합에 좀 더 강하고 오류율 감소하도록 만들었다.
3.5 Overall Architecture
신경망은 5개의 컨볼루션 레이어와 3개의 완전연결계층을 포함한 총 8개의 계층으로 구성되어 있고 마지막 softmax 계층은 1000개의 클래스를 구별하기 위해 1000-way로 되어 있다.
alexnet은 다항 로지스틱 회귀 목표를 최대화하는 것이 목표이다.
- 이는 예측 분포에서 올바른 레이블의 로그 확률에 대한 훈련 케이스의 평균을 최대화하는 것
- 즉, 올바른 레이블을 맞추는 로그 확률 값을 최대화하고자 하는 것
3번째 계층은 특이하게 모든 2번째 계층과 연결되어 있고 이를 제외한 2, 4, 5번째 합성곱 계층의 커널은 오직 같은 GPU에 있는 이전 계층의 커널만 연결되어 있다. 한편 완전연결계층의 뉴런들 또한 이전계층의 모든 뉴런들과 연결되어 있다.
response-normalization 계층은 1, 2번째 계층뒤에 따르고, overlapping pooling 계층은 response-normalization과 5번째 계층뒤에 따른다.
비선형적 ReLU는 모든 합성곱, 완전연결계층의 output에 적용이 되도록 했다. 각 필터를 통과하며 CNN layer를 학습하고 dense layer는 4096개의 뉴런들로 구성되어있으며 이를 통해 분류를 학습했다.
🔬 4. Reducing Overfitting
alexnet에는 6 천만 개의 parameter가 존재하며 이는 적지 않은 수치이다. 이는 상당한 과적 합없이 너무 많은 매개 변수를 학습하기에 어려워 이를 해소하고자 overfitting 방지를 위한 두 가지 주요 방법을 적용했다.
4. 1 Data Augmentation
이미지 데이터의 overfitting을 줄이는 가장 쉽고 일반적인 방법은 레이블 보존 변환을 사용하여 데이터 세트를 인위적으로 확대하는 것이다.
- 사진을 뒤집거나 회전시키거나 noise를 추가하는 등의 방법
연구진은 두 가지 다른 형태의 데이터 증대를 사용했으며 두 가지 모두 매우 적은 계산으로 원본 이미지에서 변환 된 이미지를 생성 할 수 있으므로 변환 된 이미지를 디스크에 저장할 필요가 없었다.
- 첫번째 데이터 증강은 이미지 변환 및 수평 반사 생성
256 × 256 이미지에서 무작위 224 × 224 패치 (및 수평 반사)를 추출하고 추출한다. 이를 통해 학습 세트의 크기가 2048 배 증가하지만 결과 학습 예제는 물론 상호 의존성이 높다.
그럼에도 위와 같은 증강이 없으면 alexnet의 overfitting으로 훨씬 더 적은 layer를 사용할 수 밖에 없다. 테스트 시간에 네트워크는 5 개의 224 × 224 패치 (4 개의 코너 패치 및 중앙 패치)와 수평 반사 (따라서 모두 10 개의 패치)를 추출하고 네트워크의 소프트 맥스 계층에서 만든 예측을 평균하여 예측을 수행한다.
- test time 만이다!
- 두 번째 형태의 데이터 증가는 훈련 이미지에서 RGB 채널의 강도를 변경하는 것
즉 색체의 변환만을 제공하지만 형태는 변화하지 않도록 구성하는 것이다.
특히 ImageNet 학습 세트 전체에서 RGB 픽셀 값 세트에 대해 PCA를 수행한다. 그리고 각 훈련 이미지에 평균 0 및 표준 편차 0.1을 사용해 정규분포에서 추출한 랜덤 변수를 곱한 해당 고유 값에 비례하는 크기로 발견 된 주성분의 배수를 추가
즉, RGB를 곱하는 방식이 아니라 기존 RGB에 주성분의 배수를 더하는 방식
- 곱하게 되면 너무 큰 왜곡이 있을 수 있으므로 주성분에 대해서 매우 작은 유동값만을 주려고 하는 것으로 보인다.
따라서 각 RGB 이미지 픽셀 에 아래와 같은 수량을 추가
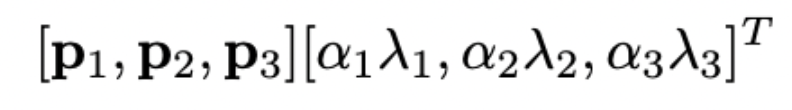
여기서 pi와 λi는 i 번째 고유 벡터와 고유 값
즉 주성분을 분해를 통해 나타난 백터와 고유 백터 그리고 거기에 랜덤변수를 곱해주는 형태이다. RGB 픽셀 값의 3 × 3 공분산 행렬과 αi는 앞서 언급 한 랜덤 변수이다. 각 αi는 특정 트레이닝 이미지의 모든 픽셀에 대해 해당 이미지가 다시 트레이닝에 사용될 때까지 한 번만 설정되며, 학습이 다시 되면 다시 설정되도록 한다. 이 방식을 통해 top-1의 오류율을 1 % 이상 줄일 수 있다.
4.2 Dropout
여러 모델의 예측을 결합하는 것은 테스트 오류를 줄이는 매우 성공적인 방법이다.
- 결국에는 dropout은 ensemble과 동일하기 때문
그러나 이렇게 많은 모델을 학습하는 데 이미 며칠이 걸리는 큰 신경망에는 너무 많은 비용이 든다. 그러나 훈련 중 약 2 배의 비용 만 드는 매우 효율적인 모델 조합 버전이 있다. 최근에 도입 된 기술인 dropout은 각 은닉 뉴런의 출력을 0.5 확률로 0으로 설정하도록 한다. 이러한 방식으로 dropout된 뉴런은 forwar로 기여하지 않으며 역전파를 통한 학습에도 관여되지 않는다.
- 즉 출력이 0이면 gradient descent의 영향을 받지 않기에 뉴런이 학습되지 않음
따라서 입력이 제공 될 때마다 신경망은 다른 아키텍처를 샘플링하지만 이러한 모든 아키텍처는 가중치를 공유한다.
- 그니까 하나의 모델을 여러 방식으로 사용한다는 것
- 그러면서 파라미터는 공유
- 즉, 모델 여러 개를 불러서 multi-gpu로 학습시키는 방식인데 업데이트는 같이 한다는 것
이 기술은 뉴런이 특정 다른 뉴런의 존재에 의존 할 수 없기 때문에 뉴런의 복잡한 co-adaptions을 줄일 수 있다.
- 즉 같은 층위의 뉴런들이 같이 적응하는 것이 아니라 특정 뉴런들만 학습이 된다.
따라서 다른 뉴런의 다양한 무작위 하위 집합과 함께 유용한 더 강력한 기능을 학습해야 한다.
테스트 시간에 연구진은 모든 뉴런을 사용하지만 출력에 0.5를 곱하고 두 모델을 한 번에 inference한다. 결국에는 예측 분포의 기하학적 평균을 취하고자 하는 것이다. alexnet 구조에서 dense layer에서도 드롭 아웃을 사용했다. 결괒거으로 드롭 아웃이 없으면 네트워크는 상당한 overfitting 발생했을 것이다. 한편, 드롭 아웃으로 학습을 일부만 하기는 하므로 수렴하는 데 필요한 반복 횟수를 대략 두 배로 늘려야 한다.
🧪 5. Details of learning
학습 디테일 : batch size 128, momentum 0.9, weight decay 0.0005 인 확률 적 경사 하강 법을 사용한다.
이때 weight decay가 매우 중요하다. 즉, 여기서 가중치 감소는 단순한 정규화가 아니라 모델의 학습 오류를 줄이는 것 에 효과가 있다.
가중치 w에 대한 업데이트 규칙은 아래와 같다.

여기서 i는 반복 횟수, v는 momentum 변수이다. 은 학습률이고, 는 wi에서 평가 된 w에 대한 목적 도함수의 i 번째 배치 Di에 대한 평균이다.
- 즉 iteration이 반복됨에 따라 weight가 업데이트 되는데 momentum을 계속 줄여나가면서 업데이트가 되고 업데이트를 줄여나가는 것은 weight의 도함수에 대한 평균 수치로 이루어진다.
최초로 표준 편차가 0.01이고 0 평균 가우스 분포에서 각 계층의 가중치를 초기화한다. 그리고 상수 1을 사용하여 두 번째, 네 번째 및 다섯 번째 컨벌루션 계층뿐만 아니라 완전히 연결된 숨겨진 계층에서도 뉴런 bias도 초기화시킨다. 해당 초기화는 ReLU에 양의 입력을 제공하여 학습의 초기 단계를 가속화합니다.
- ReLU의 특성상 양수가 들어오면 학습의 대상이 되기 때문에
- 2, 4, 5 layer에 대해 학습을 가속화
- 3을 뺀 이유는 아무래도 fully-connected이기에 양수가 하나라도 들어올 것이라는 기대 + 중요한 layer이기 때문에 천천히 학습시켜주려고 한 것 같다.
나머지 계층의 뉴런 bias를 상수 0으로 초기화했습니다. 모든 계층에 대해 동일한 학습률을 사용했으며, 훈련 내내 수동으로 조정을 실시했다.
- 그렇다면 그게 효과가 큰 거 아닌가.
🚀 6. Result
매우 성과가 좋았다.
6.1 Qualitative Evaluations

위의 그림은 alexnet의 첫번째 레이어에서 두 데이터 연결 계층이 학습한 convolution kernel이다. alexnet은 다양한 주파수와 orientation selective 커널(방향성에 대한 정보 같음)과 다양한 색상의 얼룩을 학습한다.
이때 GPU 1의 커널은 색상과 무관 한 반면 GPU 2의 커널은 색상 정보를 받고 있다. 이러한 종류의 전문화는 항상 발생하고 특정 임의 가중치 초기화 (모듈로 GPU 번호 재 지정)와는 독립적으로 나타난다.
- 즉 학습에 따라 알아서 분리가 된다는 의미

그림 4의 왼쪽 패널에서 연구진은 8 개의 테스트 이미지에 대한 top-5의 예측을 계산해 네트워크가 학습 한 내용을 질적 평가를 진행했다.
- 정성적 평가를 시도
왼쪽 상단의 진드기와 같이 중심에서 벗어난 물체도 network로 잘 인식 할 수 있었다. 대부분의 상위 5 개 레이블은 합리적으로 보임
아래에서 오른쪽 두번째 그림은 체리로 나오는데 포커스를 어디에 주느냐에 따라서도 잘 인식하고 있다.
- 하지만 이에 대해서 좀 자세히 볼 필요는 있을 듯
네트워크의 시각적 지식을 조사하는 또 다른 방법은 마지막 4096 차원 히든 레이어에서 이미지에서 나타난 이미지의 벡터를 살펴보는 것이다.
두 이미지가 유클리드 공간에서 분리가 작은 feature activation 벡터를 생성하는 경우 신경망의 높은 수준이어야 이미지들이 유사하다고 간주한다고 말할 수 있다.
- 즉 image의 semantic을 잘 학습했는가이다.
위 그림에서는 해당 계산에 따라 각각에 가장 유사한 테스트 세트의 5 개 이미지와 훈련 세트의 6 개 이미지를 보여줍니다.
픽셀 수준에서 검색된 학습 이미지는 일반적으로 L2에서 첫 번째 열의 쿼리 이미지에 가깝지 않다.
- 예를 들어, 검색된 개와 코끼리는 다양한 포즈로 나타납니다.
- 즉 픽셀 단위로는 같은 이미지일 수 없다는 것
- 아하 hidden vector에서 feature들을 기반으로 산출된 hidden vector이기에 이름을 그렇게 붙인 듯
2 개의 4096 차원 실수 값 벡터 사이의 유클리드 거리를 사용하여 유사성을 계산하는 것보다 이러한 벡터를 짧은 이진 코드로 압축하도록 자동 인코더를 훈련하는 것이 더 효율적이다.
- alexnet이 이미지 인코더로써 상당히 의미가 있다는 것
이것은 이미지 라벨을 사용하지 않기 때문에 의미 상(이미지가 담고있는 정보의) 유사 여부에 관계없이 유사한 edges의 패턴을 가진 이미지를 검색하는 경향이 있는 원시 픽셀에 auto-encoder를 적용하는 것보다 훨씬 더 나은 이미지 검색 방법을 생성합니다
- edge를 기반으로 하면 의미가 아닌 형태를 고려하기 때문에 효과적이지 못함
✏️ 느낀점
최초의 논문이기에 신기했던 부분과 지금은 사용되지 않는 부분들이 많기에 부실한 자료들이 많아 조금 아쉬웠다. 특히 normalization이나 기타 weight decay의 수식적인 해석 등에 대한 자료가 거의 존재하지 않아서 직관적으로 이해할 수 밖에 없었던 것이 아쉬웠다. 그래도 스스로 CV 논문을 리뷰해보며 CNN에 대해 조금 더 이해할 수 있게 된 것 같다
참고문헌 : 이수진의 블로그
https://deep-learning-study.tistory.com/376
https://daeun-computer-uneasy.tistory.com/33
