대회와 프로젝트를 진행하며 정말 많이 들었던 DAPT와 TAPT. 2020년에 ACL에서 최우수 논문으로 선정되기도 했으나 제대로 읽어본 적이 없어 아쉬웠다.
DAPT와 TAPT를 진행하면 성능이 상승된다는 얘기도 들었으나 정확한 구현방식을 알지못해 사용해보지 못했던 것이 기억이나 리뷰할 논문으로 선택하게 되었다.
추후에 당연하게도 실험을 진행해볼 것이라 확신하기에 논문리뷰를 진행했다.
💡 Abstract
pertrained 모델이 각광을 받고 있으나 모든 범위를 포괄해 모델의 성능이 계속 잘 나올 수 있는가에 대한 의문이 들었다. 이에 domain에 관련된 데이터로 2차적으로 pertrain을 진행해보니(DAPT) 성능이 개선되는 모습을 볼 수 있었다. 이에 더해 더 좁게 task와 관련된 문서들에 대해 pretrain을 또다시 시키니 성능 개선이 한 번 더 되었다.
연구진들은 이와 함께 DAPT와 TAPT를 위한 간단한 데이터 증강방식에 대한 연구도 진행했다.
💻 1. Introduction
RoBERTa와 같은 모델은 160기가가 넘는 큰 데이터에 대해 학습을 진행했다. 하지만 이 많은 데이터도 모든 domain을 포괄하는 것은 불가능하다. 그렇다면 domain specific한 곳에 대해서도 일반화된 성능을 유지할 수 있는가와 혹은 domain 관련 데이터로 추가적 학습을 시켜주는 것이 모델 성능 개선에 도움이 될 것인가에 대해 연구진들은 의문을 품었다. 기존에 연구도 있었으나 대량의 데이터로 학습한 것을 다시 추가적으로 학습한 것에 대한 연구는 존재하지 않았다.
결과적으로 데이터가 많냐 적냐에 상관없이 DAPT는 전반적으로 성능의 개선을 야기했다. 이와 함께 task와 더 관련이 높은 데이터로 학습을 시켜주는 TAPT를 진행했을 때 더 높은 성능 개선이 있었으며 두 가지를 모두 사용했을 때에는 더 높은 성능 개선을 보였다.
최종적으로 연구진들은 사람들이 선별한 데이터를 통해 추가적인 pretrain을 시켰을 때에 높은 성능 개선을 보였다. 하지만 이는 쉽지 않기 때문에 이를 만들 수 있는 간단한 방식을 고안했다. 결과적으로 이 모든 것이 높은 성과를 보였다.
결과적으로 연구진이 진행한 것을 요약하면 다음과 같다
- DAPT, TAPT를 통해 데이터량에 상관 없이 성능을 높였다는 것
- 해당 방식을 loss를 관찰하며 면밀히 연구했다는 점
- 이러한 데이터셋을 만들기 위해 자동화된 시스템을 고안했다는 점
🔬 3. Domain-Adaptive Pretraining
이들이 진행한 것을 요약하면 domain에 관련된 데이터를 더 구해 pretrain을 추가적으로 시켜주었다는 것이다. BioMed, CS, News, Reviews 네 가지 카테고리에 대해 진행했으며 선택된 이유는 데이터를 얻는 것이 용이했기에이다.
3.1 Analyzing Domain Simiraity
DAPT를 진행하기 이전에 RoBERTa의 pretrain domain과 target domain간의 유사도를 정량화하고자 했다. 이때에 각 도메인에서 가장 빈번한 unigrams 10000개(stopwords 제외)를 포함한 도메인 사전을 만들었다. 그후 reviews 데이터셋은 데이터들의 길이가 짧기 때문에 150K개의 문서를 구했고 다른 세 개의 domain에서는 50K개의 문서를 사용했다.
또한 기존 RoBERTa에서 사용된 말뭉치는 공개되지 않았기 때문에 사전학습 말뭉치와 유사한 sources에서 50K개의 문서를 직접 샘플링했다.
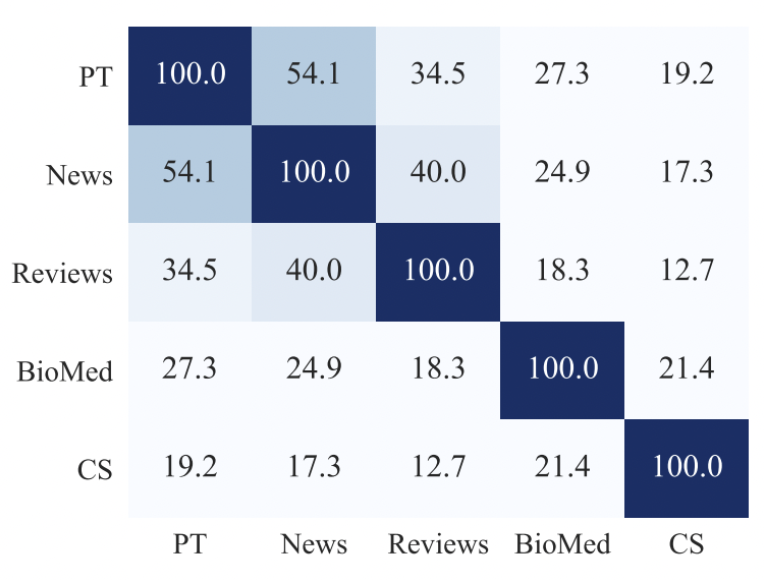
위의 그림은 단어간의 중복을 보여준다. PT는 기존 사전학습 말뭉치와 유사한 것을 구한 말뭉치이다. 이를 통해 볼 때 PT는 News와 가장 유사하며 CS와 가장 낮은 유사도를 보인다. 이들을 보았을 때 기본 모델이 PT와 가장 유사한 것에서 높은 성능을 CS에 대해서 낮은 성능을 보일 것을 예측할 수 있다.
3.2. Experiments
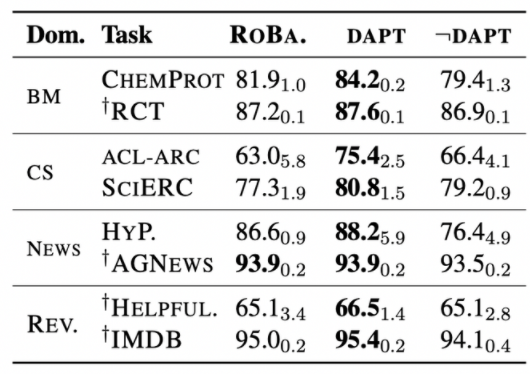
기본 RoBERTa 모델은 ROBA, not DAPT는 관련도가 가장 적은 데이터셋으로 DAPT를 진행했을 때의 성능이다. 거의 모든 경우에 대해서 DAPT를 진행했을 때 성능의 개선이 있음을 볼 수 있었다. News에 대해서만 성능 개선이 없었는데 이는 기존 pretrain 데이터셋이 news와 거의 유사했기 때문으로 보인다.
각 경우에 대해서 high resource와 low resource의 차이는 5K 이상 이하로 나누었다.
베이스라인 모델의 성능을 보면 그 자체로 좋다. 하지만 DAPT를 진행했을 때 모든 도메인에 대해 성능 개선이 있었다. 그리고 이러한 경향은 데이터가 high resource인지 low resource인지에 상관 없이 일관되게 나타났다.
AGNews Dataset이 성능 개선을 유발하지는 못했으나 Hyperartisan을 통해 성능 상승이 일어났음을 볼 때에 pretrain 데이터셋과 DAPT 데이터셋이 유사하더라도 효과가 크다는 것을 실험적으로 증명할 수 있었다.
not DAPT를 통해 그저 데이터를 늘려주는 것이 효과를 발생시키는 것인지에 대한 연구를 진행했다. 표에서 볼 수 있던 것처럼 데이터를 그저 늘려주는 것은 오히려 역효과를 발생시킬 수 있음을 볼 수 있었다. 즉, 데이터를 아무런 고려 없이 DAPT로 사용하는 것은 위험할 수 있다는 것이다. 하지만 몇몇 case에 대해서는 성능 개선이 있는 것으로 보아 완전히 의미 없는 행위로 치부하기는 어려웠다.
3.4. Domain Overlap
DAPT에 대한 분석은 task 데이터가 domain의 어떤 부분을 차지하는지 에 대한 사전의 직관들을 바탕으로 하였다 예를 들어 HELPFULNESS(유용한 리뷰인지에 대해 분류하는 task)에 DAPT를 수행하기 위해 저자들은 AMAZON reviews 데이터만을 적용하고 RealNews 기사들에 대해서는 적용하지 않았다.
그러나, 단어의 유사도 표에서 볼 수 있듯이 도메인간의 경계선은 완벽하지 않다. 예를 들어, unigram의 40%은 Reviews와 News가 공동으로 갖고 있다. 또한 질적으로 도메인간의 overlapped documents를 확인해보았는데, 아래 Table 4에서 확인할 수 있다.
(왼쪽이 리뷰, 오른쪽이 뉴스)

실험적으로 RoBERTA를 News 데이터에 적용하는 것은 Reviews task에 적용하는 것에 큰 악영향을 끼치지 않는다.
- 이는 도메인간의 분류는 확실할 수 없기 때문이다.
비록 이러한 분석이 모든 것을 포괄하지는 못하지만, 도메인 간의 성능 차이를 야기하는 요소들이 상호적으로 배타적이지 않은 가능성이 있음을 나타낸다.
- 즉, 두 도메인이 관련이 있으면 두 도메인 모두에서 성능 개선이 있을 수 있다는 것
그럼에도 전통적인 도메인 경계선을 넘는 pretraining이 더 효과적일 것이라 예측된다.
🧪 4. Task-Adaptive Pretraining
task를 위한 데이터셋은 더 넓은 domain에서 일부만을 다루지 못한다. 예를 들어, CHEMPROT 데이터셋은 화학성분과 단백질간의 관계를 추출하기 위해 최근에 출판된 주요 논문들의 요약에 집중했다. 이러한 특성들을 볼 때에 task dataset은 domain dataset보다 더 영역이 좁으며 task dataset으로 pre-train을 하는 것이 매우 효과적일 수 있다는 것이다.
TAPT 수행의 결과는 매우 효과적이라고 나왔다. DAPT와 비교해보았을 때 TAPT는 적은 말뭉치지만 task에 대해 더욱 연관이 깊은 데이터셋이다. 따라서 DAPT를 구하는 것이 TAPT보다 쉽다. 이와 같은 특성들이 있을 때에 성능을 비교해보고자 했다.
4.1. Experiments
DAPT와 유사하게 TAPT도 사용가능한 task-specific 데이터들로 RoBERTa의 두번째 pretrain을 진행했다. DAPT에서 12.5 epoch을 수행한 것과는 달리 TAPT는 100 epoch을 진행했다.
또한 각 데이터셋에서 랜덤하게 선택해 masking 처리의 비율을 0.15로 높였으며 DAPT 실험과 동일하게 CLS에 대한 분류를 진행했다.
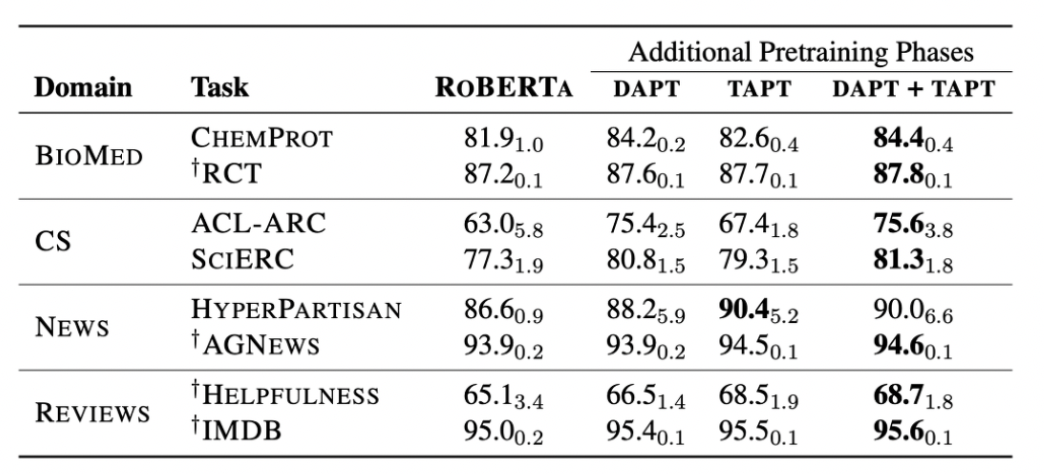
TAPT는 일관되게 RoBERTA의 성능을 뛰어넘었고 더 나아가 성능 개선이 뚜렷하지 않던 News 도메인에서도 TAPT의 성능이 더 나았다.
특히 주목할 점은, TAPT와 DAPT간의 차이인데 DAPT에 더 data가 많이 들어감에도 불구하고 TAPT는 몇몇의 task에 대해 DAPT의 성능을 넘어서는 모습을 보였다.
Combined DAPT and TAPT
RoBERTa에 DAPT를 한 후 TAPT하는 방식 사전 훈련의 세 단계가 더해져 앞서 나온 설정 중 가장 cost가 많이 든다. 그러나 DAPT+TAPT는 모든 task에서 가장 좋은 성능을 보여준다.
또한, 논문에서는 순서를 반대로 하는 것, TAPT후에 DAPT를 적용하는 것은 task 관련 말뭉치(더 높은 관련성이 있는 말뭉치)의 심각한 망각을 유발할 것이라고 말하며 성능 결과 또한 낮게 나왔다.
Cross-Task Transfer
이 논문에서는 또한 한 task에 적용시키면 같은 domain의 다른 task로 transfer하는지를 연구하며 DAPT와 TAPT간의 비교를 진행하였다. 예를 들어, RCT unlabeled data를 사용하여 pretrain을 진행하고 CHEMPROT labeled data로 fine-tuning하고자 하는 것이다..
- 둘은 동일한 BIO-MED이지만 task는 완전히 다르다. 즉, domain은 동일하다고 하더라도 task가 다를 때에 전이 학습이 가능한지를 탐색하고자 했다.

결과적으로 오히려 성능 저하를 유발했다. 위의 결과를 통해, TAPT는 하나의 task performance에 대해 최적으로 성능을 내는 것을 알 수 있다. (cross-task transfer에서는 성능이 떨어짐)
- 즉, 이 결과는 한 도메인에서도 tasks의 데이터 분포는 다름을 알려준다.
또한, 왜 한 broad domain으로 학습시키는 것(기존 pretrain)이 충분하지 않은지, 왜 DAPT후에 TAPT를 진행하는 것이 효과적인지를 알려준다.
- 한 도메인에서 마저도 task가 다르면 transfer이 잘 되지 않으니 같은 domain, task 데이터를 가지고 학습해야하는데 데이터가 충분하지 않기 때문에)
🔥 5. Augmenting Training Data for Task-Adaptive Pretraining
TAPT의 우수한 성능에 영감을 받아, 다음으로는 또다른 setting을 고려해보았는데, 이는 task 분포로부터 unlabeled data인 더 큰 pool이 존재하는 경우이다.
- TAPT 데이터가 많은 경우(unlabeled)
두개의 시나리오에 대해 조사했다.
1) 세 개의 tasks(RCT, HYPERPARTISAN and IMDB)에 대해서 사용가능한 human-curated 말뭉치에서 unlabeled data의 pool을 사용하는 것.
- 이는 사람이 직접 데이터셋중에서 task 관련 말뭉치를 선택하는 것이다.
2) TAPT에 관련된 unlabeled data를 큰 unlabeled in-domain corpus로부터 retrieving 하는 것이다.
- extra human-curated data가 사용불가능할 때
5.1. Human Curated-TAPT
데이터셋 생성은 가끔씩(sometimes) sources로부터 큰 unlabeled 말뭉치 collection을 기반으로 한다. 그런 다음 이 말뭉치는 annotation budget에 기초하여 annotation을 수집하기 위해 다운샘플링된다.
그러므로, 더 큰 unlabeled 말뭉치는 task의 학습데이터와 비슷한 분포(비슷한 내용)를 가질 것이라 생각된다. 여기서 tapt로 해당 데이터셋을 사용하는 것을 고려해보았다.
Data
BIOMED :
이 논문에서는 RCT 데이터셋을 500개의 예제로 다운샘플링(fine-tuning)하는 경우를 고려하였다.(전체는 18만개이다.) 그리고 학습 데이터의 나머지를 unlabeled 데이터(TAPT)로 가정하였다.
News :
HYPERPARTISAN shared task는 low- and high-resource의 두 가지 트랙을 가진다. 저자들은 5천개의 문서들을 high-resource 셋팅으로부터 Curated-TAPT unlabeled data로 사용하고 original low-resource 학습 문서들을 task fine-tuning에 대해 사용했다.
Reviews :
IMDB에 대해서는 task annotators에 의해 일일이 curated된 추가적인 unlabeled data를 사용하였다.
- (labeled data와 같은 분포로부터 뽑아짐)
Results
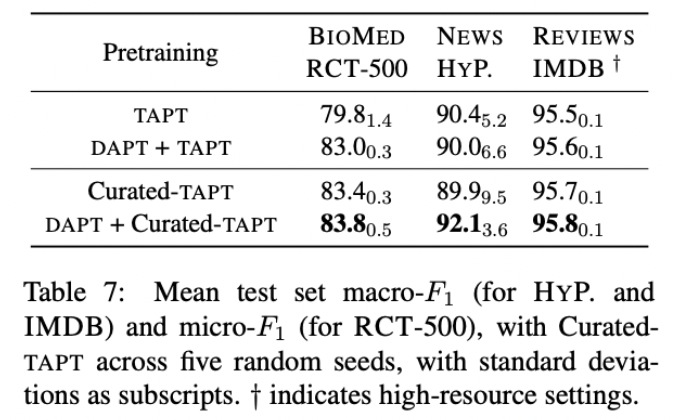
논문에서는 Curated-TAPT를 TAPT와 DAPT+TAPT에 비교했다. Curated-TAPT는 이전의 결과들보다 모든 경우에서 더 나은 성능을 보여주었다. 특히나 DAPT후에 Curated-TAPT를 적용하는 것은 모든 task들에 대해 가장 높은 성능 개선을 보였다.
결과적으로, 많은 데이터를 task 분포로부터 curating하는 것은 end-task 성능 향상에 도움이 된다는 것을 실험적으로 증명했다. 저자들은 또한 task designers에게 많은 unlabeled task data를 사전학습에서의 모델 adaptation에 사용하라고 추천한다고 한다.
- TAPT 데이터가 많으면 많을 수록 효과적이라는 것이다.
Automated Data Selection for TAPT
하지만 unlabeled data뿐만 아니라 DAPT resource 또한 충분치않다면? 이 경우를 타파하기 위한 방법론으로 논문에서는 큰 도메인내의 말뭉치에서 task 분포와 유사한 unlabeled text를 가져오는 간단한 unsupervised 방법을 제시한다.
이 접근은 text embedding을 통해 먼저 text군을 설정하고 task data를 사용한 쿼리를 기반으로 도메인으로부터 후보들을 선택하는 방식이다. 이를 통해 task-relevant 데이터를 도메인에서 찾는다.
- text embedding을 통해 유사한 분포의 데이터를 뽑아오는 방식
중요한 점은, 임베딩방식이 reasonable한 시간내에 모든 문장들을 임베딩할 수 있을 정도로 가벼워야한다는 것이다.
이러한 계산소요 방면에서, 논문에서는 VAMPIRE라는 간단한 bag-of-words language model를 사용하였다.
- VAE 모델로 Embedding을 하는 Encoder를 학습시키는 방식이다.
task와 domain 모두에서 텍스트 임베딩을 처리하기 위해 VAMPIRE를 큰 중복제거된 도메인의 샘플(1M개의 문장)에서 사전학습을 한다. 이를 통해 텍스트들이 임베딩될 것이다.
그다음 각 task 문장들(query)에 대해 도메인 샘플로부터 k개의 후보를 선정한다.
후보들은 두 가지 방식 중 하나를 사용하여 선정된다.
1) KNN-TAPT(knn)
2) RAND-TAPT(random)
이렇게 선정된 후보들을 추가하여 augmented된 말뭉치를 가지고 RoBERTA를 더 학습한다.
Results
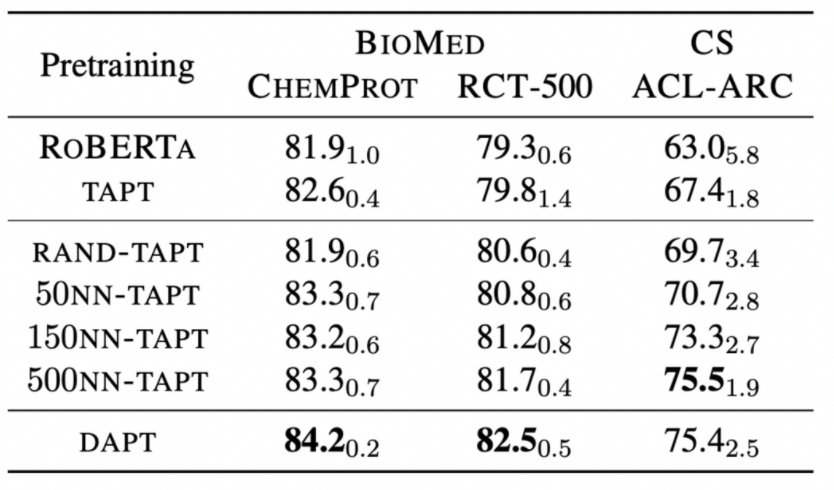
결과를 통해 knn 방법을 통해 데이터를 추가한 kNN-TAPT가 TAPT을 모든 경우에 대해 가장 높은 성능을 보인 것을 알 수 있었다. 즉, KNN을 사용하는 방법이 연관성을 어느정도 확보해줄 수 있다는 것이다. RAND-TAPT는 오히려 TAPT보다 성능이 낮았다.
하지만 한 표준편차내의 random 선택은 몇몇의 데이터셋에서 성능의 향상을 보여주었다.
k를 증가시킬수록 kNN-TAPT의 성능은 점점 증가했고 DAPT의 성능까지 가까이 갔다.
✏️ 후기
생각보다 DAPT, TAPT 내용이 단순해서 읽기에 어렵지 않았다. 결국에는 우리가 집중하고 있는 task로 domain을 적절하게 옮겨주면 모델은 그것을 잘 파악하기에 성능개선이 있을 수 있다는 것이다.
이를 위해 VAMPIRE라는 Encoder 학습 방식을 사용했는데 이 부분이 인상 깊었다. VAE를 통해 문서 임베딩을 완료한 후 Query로 유사도가 높은 문서들을 추출하면 더 높은 성능을 유발할 수 있다는 것이었다.
우리가 진행했던 서술형 자동 채점 프로젝트에 접목하면 과학, 사회과학 등 분야에 적합한 데이터로 DAPT 혹은 TAPT를 진행해주면 채점의 정확도도 높일 수 있을 것이다. 그러나 우리가 하고자 했던 것은 문장의 유사도를 적절하게 파악하는 모델이기에 General 모델 개발과는 거리가 있었다.
모델을 여러 개 구동하며 채점을 한다면 이 역시 가능하겠지만 이는 cost가 높을 것이다. 즉, 각 task에 대해 적절하게 학습시켜주는 방식이 중요할 것 같다. 더불어 이를 위해서는 데이터도 충분해야 하므로 KNN과 같은 방식에 많이 익숙해져야 할 것 같다.
TODO : VAE로 문장 임베딩 시켜보기
참고문헌 :
