https://aclanthology.org/2023.acl-long.153.pdf
invalid sample을 주더라도 생각보다 잘 한다는 것
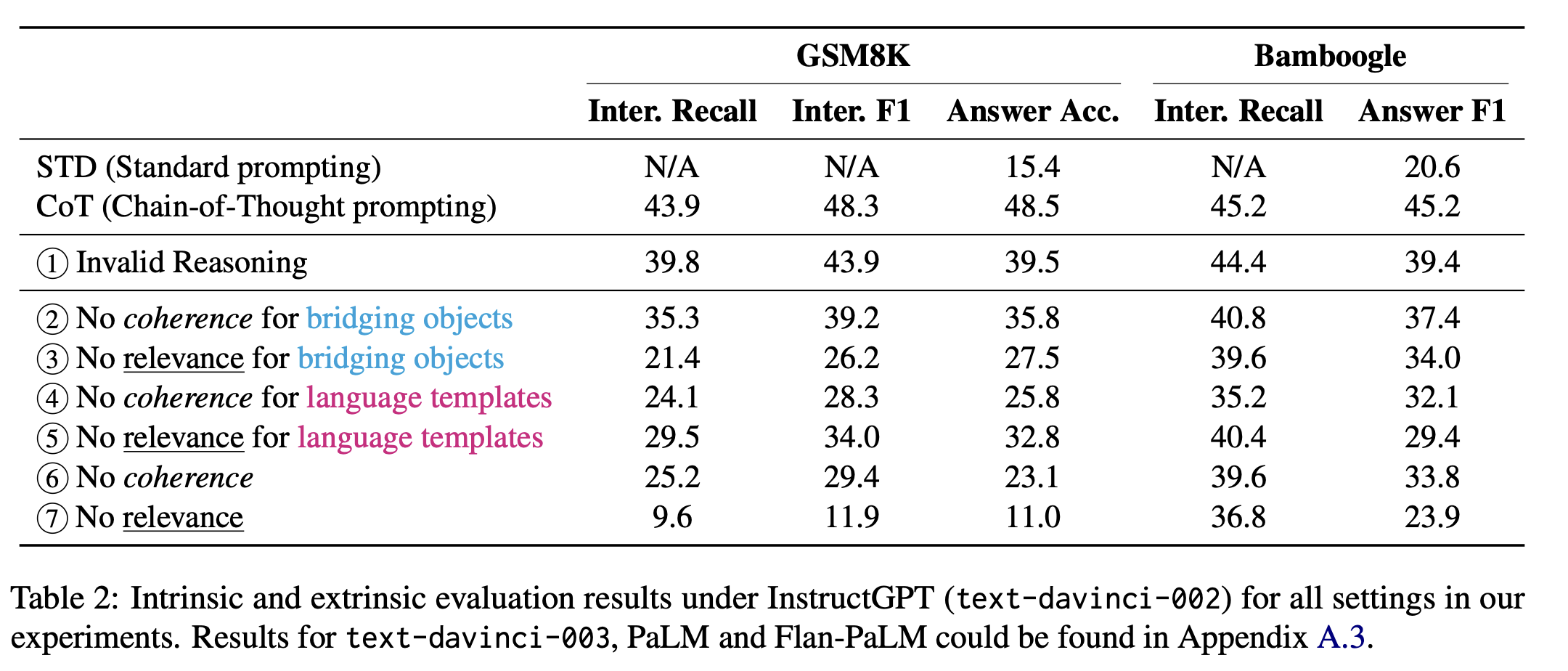
논문내용
CoT를 제공할 때에 invalid한 sample들을 주어도 성능의 80-90%는 얻을 수 있다. 그렇다면, CoT의 영향을 주는 요소에 대한 ablation study를 해보자는 것으로 시작된 논문.
해당 논문에서는 크게 relevance와 coherence를 다루었다.
relevance는 query로 주는 내용과 reasoning step 간 관계가 있는가 없는가를 다루는 것.
coherence는 reasoning step에서 사용되는 요소의 순서가 올바른가.
그리고 reasoning step을 bridging object와 language template으로 나누었다.
bridging object은 등식, 숫자, 명사와 같이 reasoning을 하면서 중요하게 사용되는 중간 다리 역할을 하는 객체들.
language tempalte은 해당 bridging object를 통해 만들어지는 문장 구조.
LLMs learn about how to reason under CoT prompting could be limited. Rather, they have already gained a lot of such “reasoning abilities” from pretraining, and the demonstrations may mainly specify an output space/format that regularizes the model generation to look step-by-step while being in order and relevant to the query
논문에서는 해당 내용과 더해 LLM은 이미 reasoning에 대해 학습했고 CoT가 그것으로부터 배우는 것은 아니라고 말한다.
- prior knowledge에 over-rely하는 경향이 있는 것 같다고 얘기함
그럼에도 output의 형태(format)와 coherence와 relevance를 맞춰야 한다는 것에 대해서는 인지시킬 수 있음
그러면서도 in-context learning으로 모델을 학습시킬 수 있다는 것은 부정하지는 않았음.
sample들을 보면, 모든 sample들은 답은 맞도록 setting이 되어 있기는 하다(no relevance 제외)
성능면에서는
- Invalid reasoning
- 답은 맞지만 뭔가 step이 이상한 것
- 해당 sample은 직접 만들었다고 했다.
- no coherence for bridging objects
- bridging objects들을 shuffle한 것(답은 맞음)
- object들의 순서가 틀림
- no relevance for language templates
- bridging objects은 맞지만 reasoning step이 완전 다른 내용
- no coherence
- laguage랑 objects 모두 shuffle
- no coherence for language templates
- reasoning step을 shuffle한 것
- 이때 object는 shuffle이 되지 않았기에 엉성하다.
- no relevance for bridging objects
- 완전 관련이 없는(다른 sample의) bridging objects들을 배치한 것(답도 틀림)
- no relevance
- 그냥 다른 내용(답도 틀림)
논문에서의 분석
- relevance가 매우 중요하다
- 아예 관련이 없으면 성능이 매우 저하되기 때문(7위)
- bridging object는 relevance가 coherence보다 중요하다
- language template은 coherence가 relevance보다 중요하다
분석이 너무 단순하기는 하다.
개인적 견해 및 발전방향
살펴보면, 인위적으로 만든 것이 꽤나 유효.
no relevance for language templates이 3위를 한 것이 신기하다.
- 문장자체가 관련이 없으나 object가 맞았다고 해서 꽤나 높은 성능을 보였다는 점.
no coherence for bridging objects과 no relevance for bridging objects가 형태적으로는 유사해보인다.
그러나 성능 차이가 매우 크다
- 2위, 6위
- 이 지점이 왜 그런지에 대한 생각이 필요할 것 같다.
- query에서 나오는 object를 사용했냐와 답이 맞았냐가 상당히 큰 영향을 주는 것 같기도 하다.
- 또한,
결과적으로 보면, language template 구조 자체에 영향을 많이 받는 것 같다
- 2위 3위 모두 language template은 말이 되기 때문
- 그러나 6위 역시 language template 구조는 말이 된다.
생각해볼 수 있는 것.
이미 pre-trained에 해당 데이터가 사용되었을 가능성이 있어 해당 문제에 대한 likelihood를 파악하고 있는 상황이라면?
- 이상하게 제공해도 맞은 sample들이 있다면 해당 sample들을 그냥해도 맞을 것으로 예상됨
- zero-shot으로도 된다는 것
- 그러한 연관성을 체크하면 CoT는 흐름만을 제공해주는 대상일 것
