https://arxiv.org/pdf/2212.10071.pdf
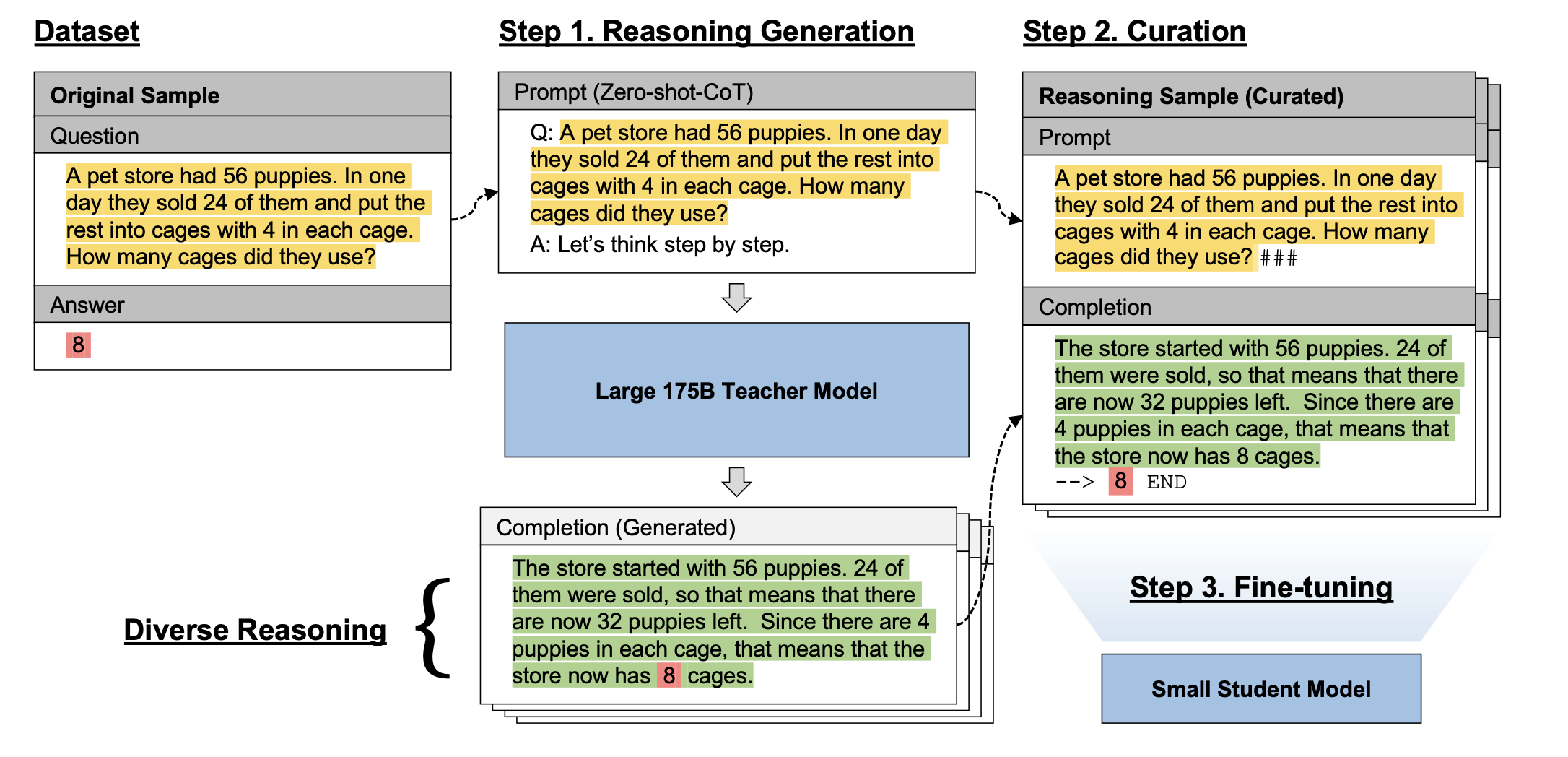
거대 모델을 사용 reasoning을 생성해낸다.
그리고 그것을 작은 모델에 학습시킴
작은 모델에게 있어 rationale 없이 reasoning task를 하는 것은 매우 어렵고 데이터를 생성하는 것도 cost가 높기에 pseudo-human인 large model을 사용
Step1: Generation
cost를 줄이기 위해서 teacher model에 생성할 때에는 task-agnostic Zero-shot-CoT prompting method를 사용했다고함
- let's think about step-by-step 방식
- 학습 데이터로 사용할 때는 제거한 것 같음
- Q: . A: Let’s think step by step. Therefore, the answer is
Step2: Curation
LARGE LANGUAGE MODELS CAN SELF-IMPROVE논문에서 사용한 방식으로 정답을 비교했다고 함
이 과정에서 잃어버리는 sample이 있다고 하는 것을 봐서는 regex로 추출해서 하는 방식 같다
그리고 format을 만드는 과정에서 token수를 적게 하기 위해 delimiter들을 사용했다고 한다.
- 최종 형태는 ### -->
- 정답을 통해 비교하는 것은 위험하기에 appendix에 이를 위해 확인했던 내용들 추가
Fine-tune
여러개의 sample을 사용하기 위해서 greedy sampling이 아닌 temperature를 이용한 stochastic sampling을 진행
D 개수만큼 생성을 하고 이를 degree of reasoning diversity라 명명
그리고 이들로 fine-tuning
동일한 query에 대해 diverse question을 주어서 학습하는 것이 더 좋은가?
diversity를 보완하려는 논문
- DIVERSITY OF THOUGHT IMPROVES REASONING ABILITIES OF LARGE LANGUAGE MODELS
학습에 사용한 모델은 GPT-2(small, medium, large), T5(small, base, large)
성능
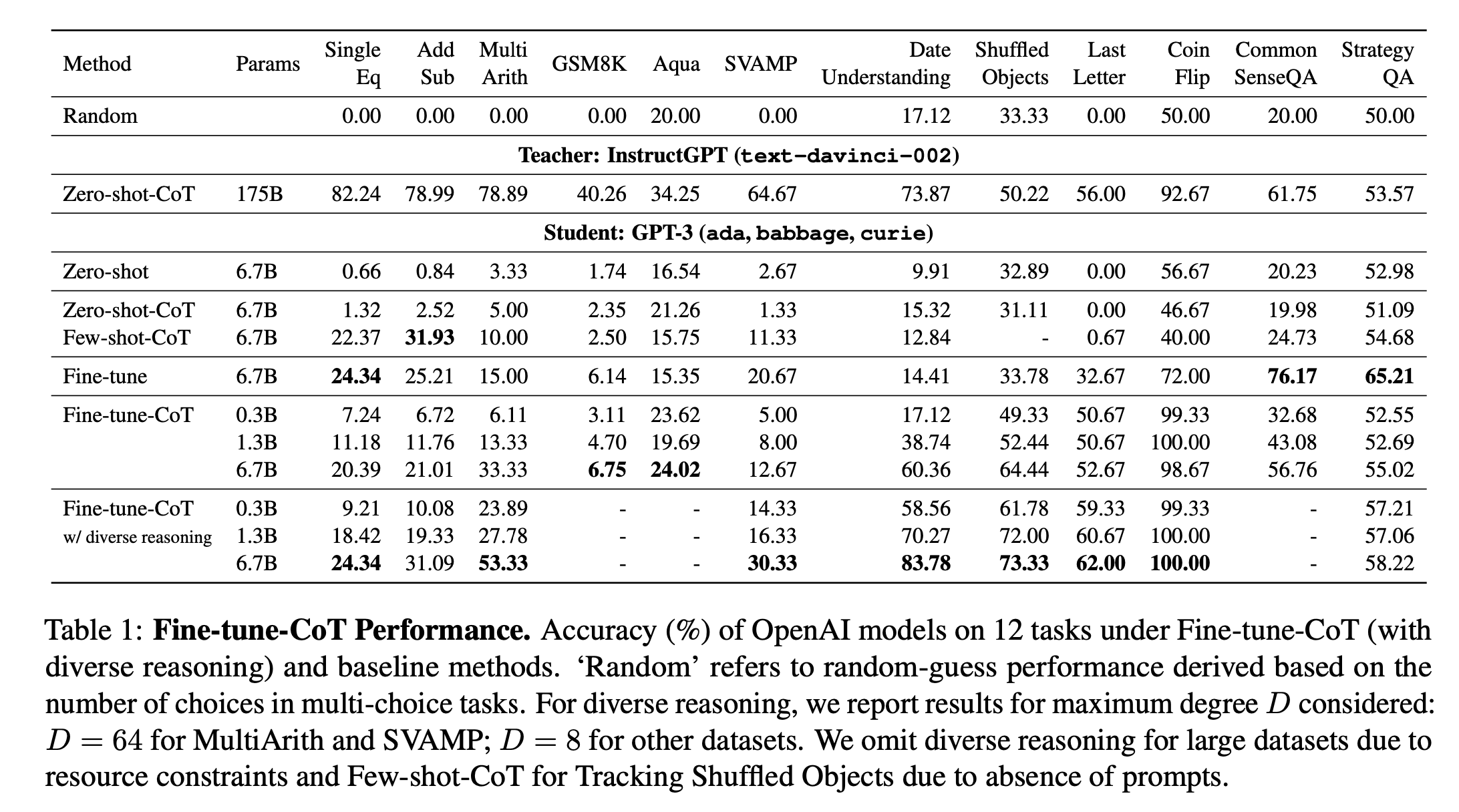
성능 상승이 확실히 일어나며, large의 경우 6.7B임에도 꽤나 높은 성능을 보임.
- 1.3B도 성능이 매우 높았다.
확실히 diverse reasoning을 사용했을 때 성능이 더 오른다는 점이 있다.
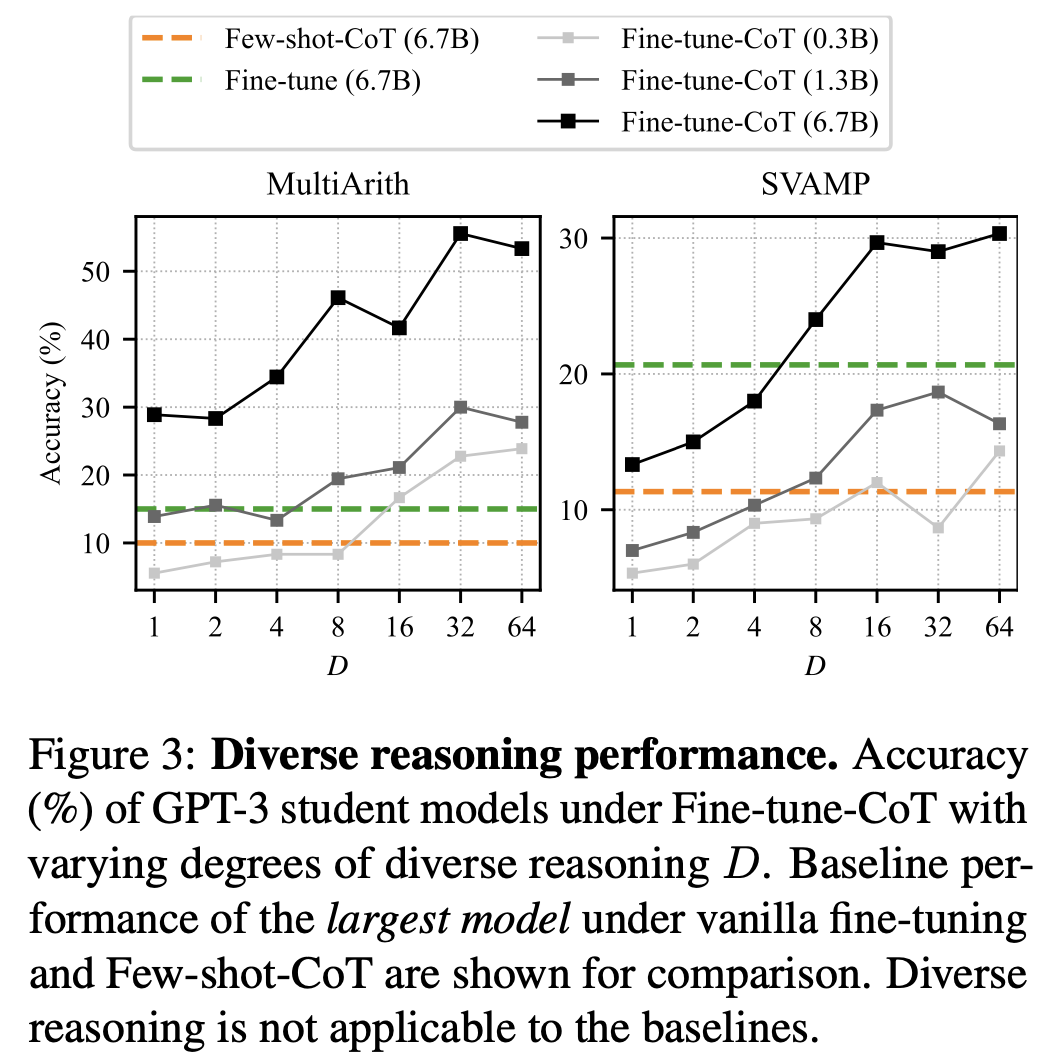
- 동일한 query에 데이터가 augment가 된 것임에도 불구하고 성능 상승이 있다는 점은 주목할만하다
- SVAMP에서만 D=8로 나머지는 64로 fine-tuning했다고 한다
또한, data size가 증가할 수록 성능이 올라가는 경향성을 보인다.
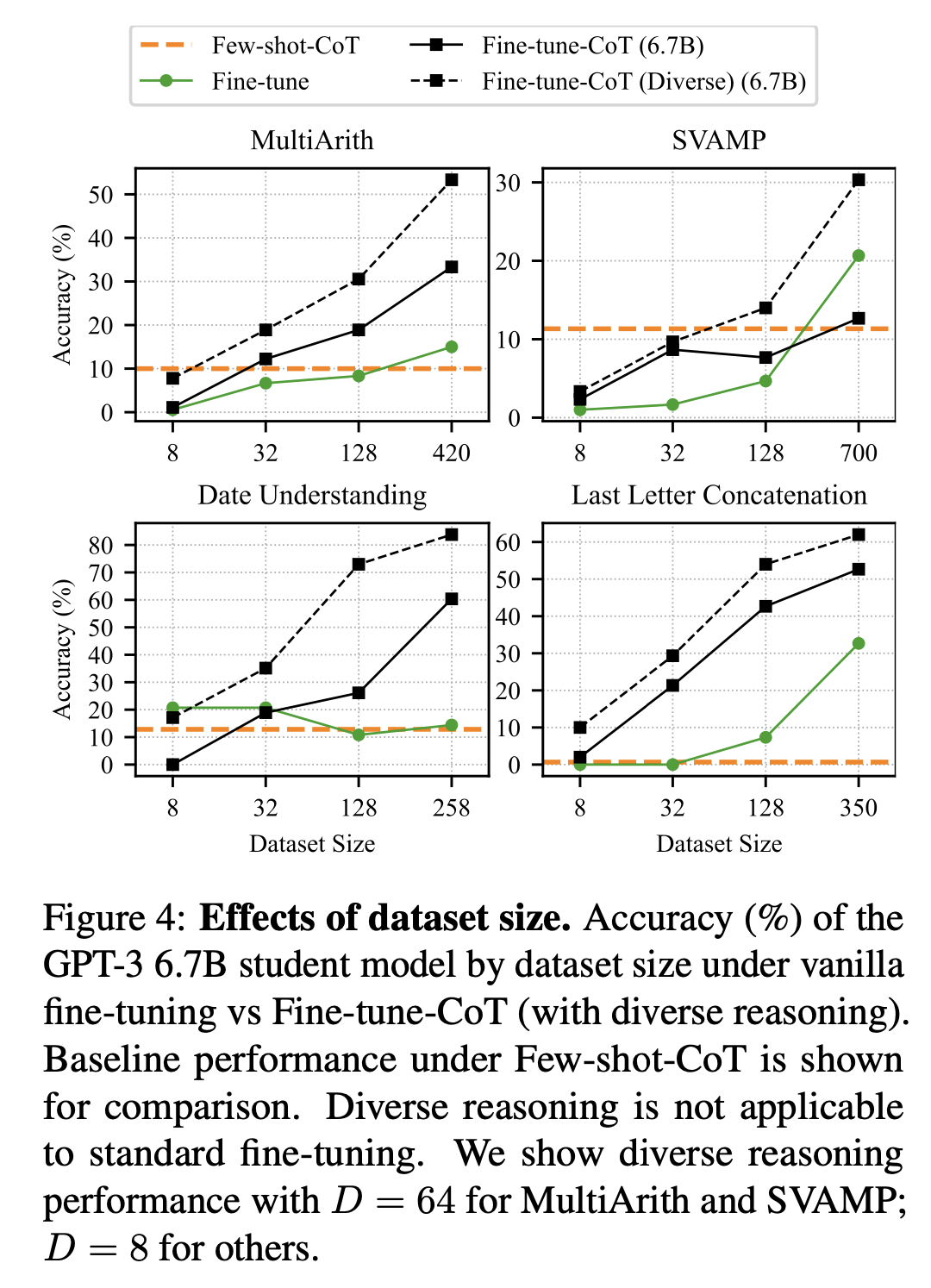
그리고 teacher model의 성능이 높을 수록 student의 모델 성능도 높아졌다고 한다.
- 이건 당연해보인다.
일반적으로 모델 size가 커지면 성능이 높아지지만 그렇지 않은 task들도 있다.
- MultiArith와 Date Understanding인데 다른 task보다 난이도가 쉬워서(overall 성능이 가장 높은 것들 중 2개임) overfitting된 경향이 있는 것 같다
- coin flip의 경우는 너무 쉬워서 모델 size의 영향을 덜 받은 것 같기도 하다
Analysis
Sample Study
sample을 들여다본 결과 대부분의 오류가 계산에서 나타남.
MultiArith와 SVAMP는 semanitc 오류가 많았으나 diverse reasoning을 통해 보다 해소됨.
Nuances of fine-tuning on CoT reasoning
분석 결과 Date Understanding의 27.6%의 생성된 데이터가 답은 맞았음에도 reasoning이 잘못됨
그러나 이들을 포함하는 것이 오히려 성능 상승에 도움이 되었다.
Appendix를 살펴보면, Date Understanding이 well-grounded multi-choice questions으로 구성되어 있어서 선택했다고 한다.
Golden은 Answer중 rationale들이 틀린 것들을 나타내며, Answer+는 Golden과 개수를 같게 하기 위해 random samle한 test set이다.

여기서 quantity > quality 순으로 중요하면서도 quality 역시 모델 성능에 영향을 미친다는 것을 알 수 있다.
결과적으로 Diversity Sampling이 도움이 된다는 것
maximum sequence lengths가 incomplete answer를 생성하는 요인이 되기도 한다.
template이 유사한 sample들이 많은데 이들이 train/test 중 한 곳으로 쏠리지 않도록 했다고 한다.
✏️ 발전방향
여러 분석을 담았다는 점에서 매력적인 논문이라고 생각한다.
diversity가 도움이 되는지, quality와 quantity의 영향력 등을 ablation study를 통해 입증해냈다는 점이 인상 깊었다.
distillation이 가능하고 효과적인지 알았으니 어떻게 하면 더 강화할 수 있을까도 좋을 것 같다.
RLHF나 DPO 등으로 모델을 강화시켜서 작은 모델들을 성능 고도화해보는 방식 등
6.7B fine-tuning할 수 있는 resource부럽다ㅎ...
