
https://arxiv.org/pdf/2310.07088.pdf
diversity를 prompt에서 어떻게 하면 줄 수 있을까
- 약간 SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS 논문과 유사
기존의 연구들은 prompt를 heuristic하게 혹은 trial-and-error방식으로 혹은 비싸게 구현하고 있다고 말함
stochastic은 비쌀 뿐만 아니라 thought의 diversity가 아닌 token-level의 diversity이다.
그런 부분을 보완하고자 함.
모델에게 n개(1~5)의 response를 생성해달라고 함
이때, instruction과 query 그리고 맞춰야 하는 template 순으로 모델에 제공
< i || q || t > 형태
구체적으로는 아래와 같다

해당 과정을 m번 반복해 개의 approach를 얻는다
방법을 다양화하기 위해 task별로 word cloud를 만들고 5개를 선택했다고 한다.
또한 persona를 주입해(요구해) diversity를 만들 수 있음
- 이 경우 persona를 직접 선택하지 않고 모델에게 관련이 있는 persona를 요구하고 persona끼리 묶어 set를 만들었다고 한다
왜지?
그렇게 만든 A개의 approach에 대한 power set
그리고 P개의 persona들
이들로 pair를 만들고 () 성능이 가장 높은 것을 선택
- 성능의 기준이 무엇인가?
그중 persona가 다른 것들이 포함되어 있다면 더 많은 approach를 포함하는 persona만 선택
- {(), (), ()}이 성능이 가장 높다면, {(), ()}이 선택된다.
그렇게 선택된 것들을 LLM으로 하여 주어진 approach들로 style transfer을 요청 - augmented demonstration이라 명명
이들을 가지고 새로운 방식의 inference를 진행
DIV-SE
각기 다른 inference call로 approach를 생성하고 solution을 aggregate
위의 과정을 통해 persona는 하나이며, 여러 개의 approach로 inference를 진행.

inference call을 여러 번 사용하기에 cost가 높다.
IDIV-SE
하나의 inference call에 생성했던 approach를 보여주며 이와 같이 여러 개의 approach를 요구하고 solution을 aggregate하는 방식
inference call을 한 번만 사용해도 된다.
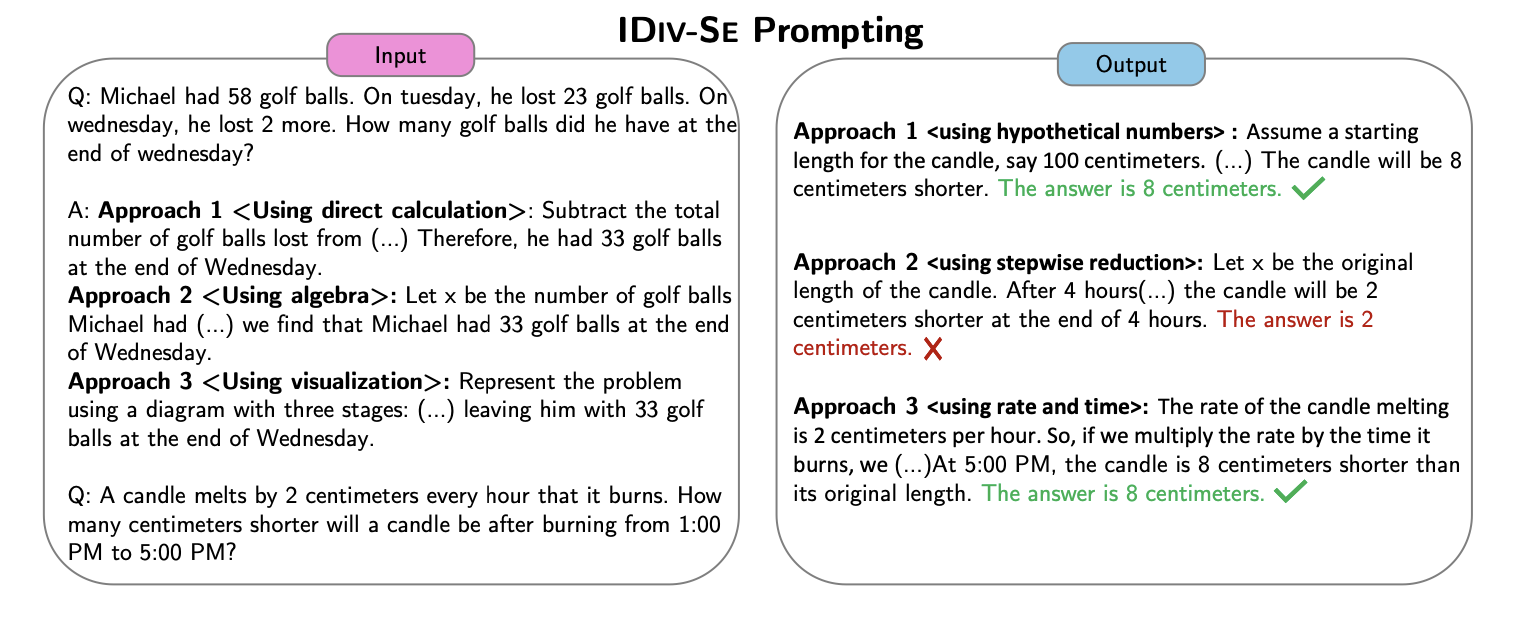
다만, DIV-SE에 비해 성능이 조금 떨어진다.
- 당연히 그럴 것
Aggregation
majority vote로 solution aggregate

LLM을 사용해서 meta reasoning을 하더라도 성능이 거의 유사.
Result
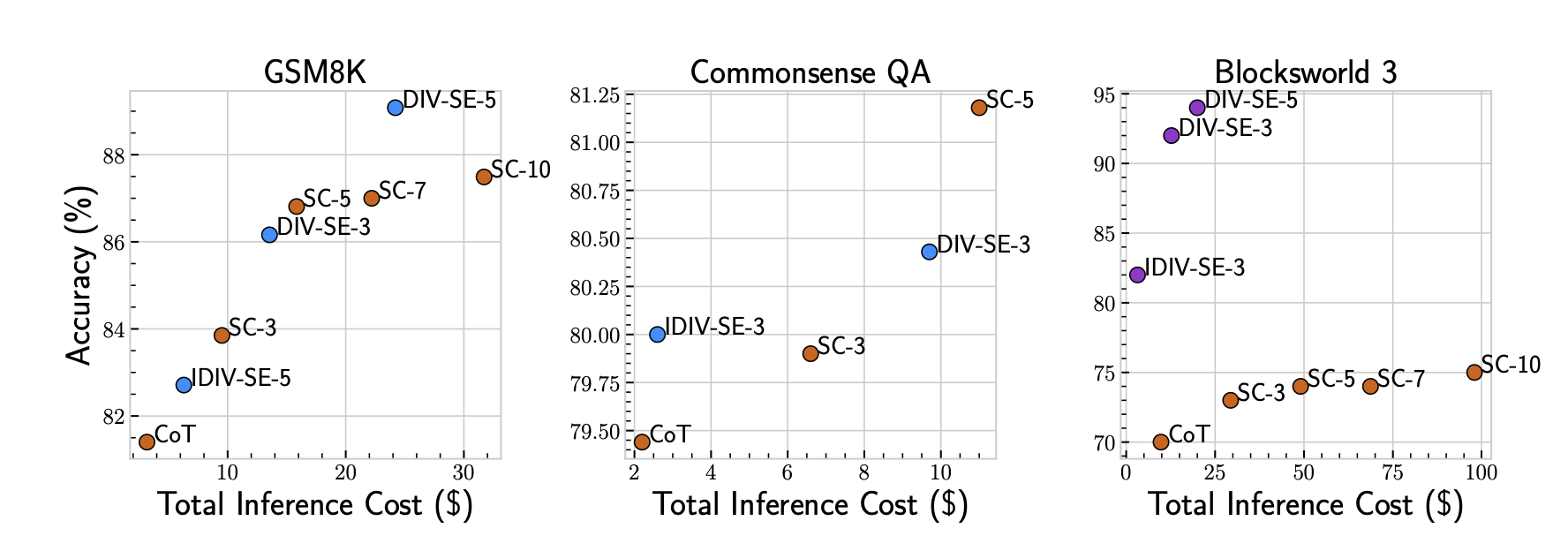
그래프를 80부터 설정해 왜곡이 좀 있기는 하지만 DIV가 성능과 cost 면에서 우월하다는 것을 보여준다.
발전방향
inference에서는 cost가 낮다고 나와 있다.
그러나, 주의해야 할 점은 prompt로 제공되는 sample approach가 어떤 것인지는 나와있지 않다.
즉, 각 sample마다 동일한 prompt를 제공하지는 않았을 것이며, 적합한 sample들을 추려 성능을 구했을 가능성도 있다.
- 아직 preprint이기에 그러한 내용이 나타나있지는 않다.
self-consistency의 경우에는 5번의 결과를 aggregate한 것이라면, 이 논문의 경우는 persona P개와 approach 5번 그리고 이를 m번 반복했다고 하면 의 결과에 대한 예측일 수 있다.
그렇게 치면, cost가 efficient하다고 보기는 어렵다.
CoT로 제공하는 sample들의 영향이 꽤나 크기에 동일한 prompt를 반복하지는 않았을 것 같기도 하다.
- Towards Understanding Chain-of-Thought Prompting 참고
더욱이, persona 선택 과정에서 성능이 높은 persona를 선택했다고 얘기를 했다.
여기서 성능 지표가 나와있지 않다.
정답이 동일한 상태에 둘다 rationale이 올바르다면 어떤 persona를 선택하는 게 적합한가?
이를 통해 보면, testset 성능에 dependent하게 인위적으로 sample마다 선택되었을 경우가 커 보인다.
따라서, 논문 자체가 제대로 나와야 알 수 있는 내용들일 것 같다.
그럼에도 token단위가 아닌 thought 단위의 diversity를 주려고 했다는 점은 논리적이다.
이처럼 token level에서가 아니라 step level로 혹은 logic level로 다양성을 주어 모델을 강화하는 것도 좋은 방법일 것 같다.
- Towards Understanding Chain-of-Thought Prompting에서 역시 prompt가 증가할 수록 성능이 강화되는 경향이 있었기에

정리 감사합니다 :)