오늘의 학습목표
- 정칙화 (Regularization) 의 개념을 이해하고 정규화 (Normalization) 와 구분한다
- L1 regularization과 L2 regularization의 차이를 설명한다
- 실습을 통하여 Lp norm, Dropout, Batch Normalization에 대해 학습한다
Regularization과 Normalization
Regularization 정칙화
- 오버피팅을 해결하기 위한 방법 중의 하나이다
- 기본적으로 모델의 학습은 loss의 값을 최소화하는 방향으로 진행
- overfitting?
아래의 사진처럼 학습 데이터를 과도하게 학습한 경우를 말하는데,
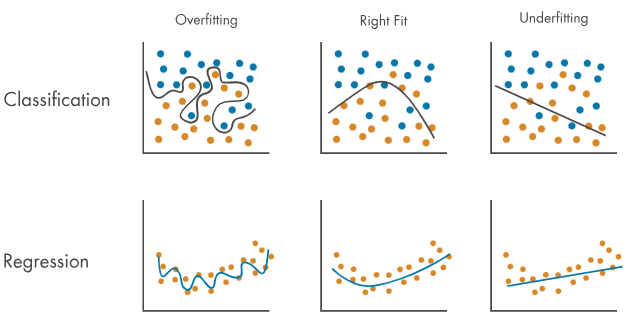
- train set은 잘 맞히지만, validation/test set은 맞히지 못하는 현상
- 예를 들자면, 특정 문제집만 답을 외우다시피 공부를 해서 해당 문제집에 대해서는 모든 문제를 맞히지만 같은 유형의 다른 문제를 내면 전혀 맞히지 못하는 상황
- train loss는 낮은데 accuracy도 높지 않은 상황
- 그래서, regularization 기법들은 모델에 제약 조건을 걸어서 모델의 train loss를 증가시키는 역할을 한다.
- 어떻게? (α : 제약조건)
loss + α
- 어떻게? (α : 제약조건)
- 종류
- L1, L2 Regularization
- Dropout
- Batch normalization
Normalization 정규화
- 앞선 포스트에서 데이터의 전처리 과정을 다루며 나왔던 개념
- 학습 시 서로 범위가 다른 데이터들을 같은 범위로 바꿔주는 전처리 과정이다
L1 Regularization
1. linear regression 문제가 L1regularization으로는 풀리지 않는다?
-
문제
from sklearn.linear_model import LinearRegression import numpy as np X = np.array(X) Y = np.array(Y) # Iris Dataset을 Linear Regression으로 학습합니다. linear= LinearRegression() linear.fit(X.reshape(-1,1), Y) # Linear Regression의 기울기와 절편을 확인합니다. a, b=linear.coef_, linear.intercept_ print("기울기 : %0.2f, 절편 : %0.2f" %(a,b)) # 기울기와 절편을 가지고 만든 일차함수와 산점도 그리기 plt.figure(figsize=(5,5)) plt.scatter(X,Y) plt.plot(X,linear.predict(X.reshape(-1,1)),'-b') plt.title('petal-sepal scatter with linear regression') plt.xlabel('petal length (cm)') plt.ylabel('sepal length (cm)') plt.grid() plt.show() -
Lasso방법을 이용하여 위의 문제를 풀면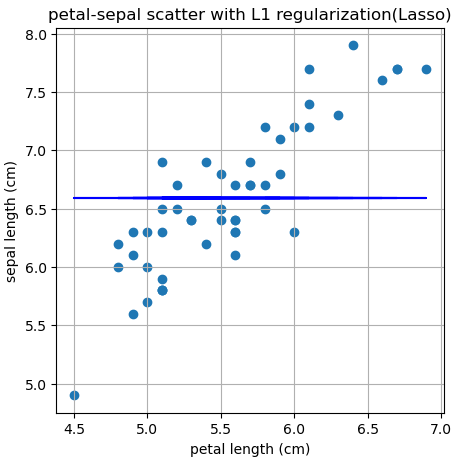
- 기울기가 0인 일차함수가 나온다
Ridge방법을 이용하면linear regression과 큰 차이가 없는 결과를 얻게 된다
(참고) Lasso와 Ridge는 사이킷런이나 케라스, 텐서플로우 등의 패키지에서 사용하는 이름이다
-
그렇다면 왜 이런 결과가 나올까?
다음 그림과 관련이 있다. (이 그림을 'loss최소 그림' 이라 하자.)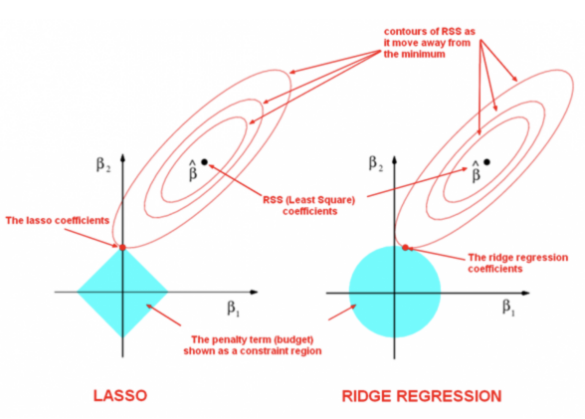
2. L1 regularization (Lasso)의 정의
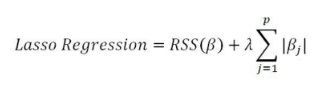
- RSS(β)는 loss 함수이다
- 중요하게 봐야할 부분은 이다
- 이 부분이 없다면 linear regression과 동일하다
- L1 norm에 해당하는 부분
- 앞서, 모델의 학습은 loss의 값을 최소화하는 방향으로 진행된다는 것을 다시 생각해보자.
- 즉, Lasso Regression도 loss를 줄이는 방향으로 진행되어 loss가 0을 갖게된는 경우를 생각하자. → L1 norm만 남음
- 최솟값의 범위를 그려보면 위에서 봤던 'loss최소 그림'의 왼쪽처럼 사각형 공간이 그려진다
단서1. 모델의 학습은
Loss 함수인 를 최소화하는 β 를 찾는 과정이다
단서2. 마름모꼴의 제약 범위:
L1 norm () 을 시각화하면 중심이 원점인 마름모 형태의 영역이 생긴다
추론.
- 성능을 결정하는 RSS의 등고선과 L1 norm의 제약 범위가 만나는 지점에서 최적의 해가 결정된다
- 이때 RSS 등고선이 축 위에 만날 확률이 매우 높다
- 특정 축 위에서 만난다는 것은 ( ex. y = 0, x = 0 )
즉 우리가 구하려는 계수들이 정확히 0이 된다
결론.
-
아래 그림과 같이 13개 중 7개를 제외한 나머지 값이 모두 0이 나옴

-
에러 부분에서는 큰 차이가 없다.
// Result of linear regression Mean Absolute Error: 0.2512897393972267 Mean Squared Error: 0.10624587409525586 Mean Root Squared Error: 0.3259537913497186 // Result of Lasso Mean Absolute Error: 0.24233731936122138 Mean Squared Error: 0.0955956894578189 Mean Root Squared Error: 0.3091855259513597- 그 말은 0 값이 나온 컬럼들이 유의미하지 않은 변수였다는 것.
⇾ 중요한 변수만 골라낼 수 있다
- 그 말은 0 값이 나온 컬럼들이 유의미하지 않은 변수였다는 것.
-
Lasso는 유의미한 변수가 적을 때 좋은 성능을 보인다
L2 Regularization
1. L2 regularization(Ridge)의 정의
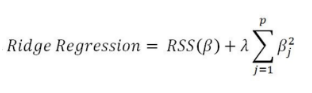
- L2 Norm
2. L1/L2 Regularization의 차이점
- 아까 L1의 제약조건이 마름모 형태로 생겼던 것과 달리,
L2의 제약조건은 원의 형태로 나타난다 - 따라서 RSS의 등고선이 축 위에 있을 가능성보다 축과 가까운 다른 곳에 있을 가능성이 높다
- 이런 이유로 L2는 L1과 달리 선형 회귀와 같은 결과를 보임
모든 값이 0이 아닌 유효한 값을 보임
- 이런 이유로 L2는 L1과 달리 선형 회귀와 같은 결과를 보임
L1의 특징
- 가중치가 적은 벡터에 해당하는 계수를 0으로 보내면서 차원축소와 비슷한 역할을 한다
L2의 장점
- 계수를 0으로 보내지는 않지만 제곱 텀이 있기 때문에 L1보다 수렴 속도가 빠르다
3. L1/L2의 공통점 (필자 의견 포함)
- Lp norm을 이용한다
- 모델에게 강제로 경계 범위를 지정해서 loss가 최소화될 때 벌점을 부여함
그래서 모델이 벌점을 피하게끔 학습을 유도하여 과적합을 방지
Extra: Lp norm
- Norm
벡터 뿐만 아니라 함수, 행렬의 크기를 나타내는 개념- 딥러닝을 배우는 과정에서는 주로 벡터와 행렬의 norm 정도만 알면 된다
Vector norm
- 실습 코드 1
# x와 p를 바꾸어가며 norm 값이 어떻게 변하는지 실험해봅시다! x = np.array([10,10,10,10,1]) p = 1 norm_x = np.linalg.norm(x, ord=p) making_norm = (sum(x**p))**(1/p) print("result of numpy package norm function : %0.5f "%norm_x) print("result of making norm : %0.5f "%making_norm)- p가 작아질수록 결과값이 커진다
- 왜 그럴까?
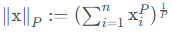
- 0과 1 사이의 작은 값일 때를 생각해보자
- 지수 p의 관점:
p가 작을수록 작은 숫자를 더 크게 유지하거나 그대로 반영한다 - 전체 루트 1/p 의 관점:
p가 작을수록 안쪽의 값을 더 크게 만든다
- 지수 p의 관점:
- 왜 그럴까?
- 즉, p가 작을수록 작은 값들(주어진 배열의 원소들)의 존재감을 강하게 유지하기 때문에 전체 결과값이 더 커진다
- p가 작아질수록 결과값이 커진다
- 실습코드 2
norm_x = np.linalg.norm(x, ord=np.inf) print("result of infinite norm : %0.5f "%norm_x)- p가 자연수가 아닌 경우
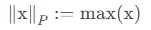
- 왜 이렇게 되는가?
지수의 증가율 때문에 결국 가장 큰 값만 남게 된다
- 왜 이렇게 되는가?
- p가 자연수가 아닌 경우
Matrix norm
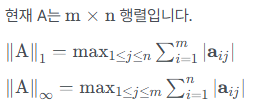
-
행렬의 norm은 '행렬이 벡터를 얼마나 변하시키느냐'는 변환의 관점에서 정의된다.
- 계산법은 아주 명확한 규칙이 있다
- 행렬곱과 관련이 있다
- 주로 P = 1, (inf)인 경우만 알면 된다
- P = 1인 경우에는
column의 합이 가장 큰 값이 출력 - P = (inf)인 경우에는
row의 합이 가장 큰 값이 출력
- P = 1인 경우에는
- 계산법은 아주 명확한 규칙이 있다
-
실습 코드
A = np.array([[1,2,3], [1,2,3], [4,6,8]]) one_norm_A = np.linalg.norm(A, ord=1) print("result one norm of A :", one_norm_A) inf_norm_A = np.linalg.norm(A, ord=np.inf) print("result inf norm of A :", inf_norm_A)- 최대 열 합
- 각 column별로 원소들의 절댓값을 모두 더하고 그 중 max를 선택
- 최대 행 합
- 각 row별로 원소들의 절댓값을 모두 더하고 그 중 max를 선택
- 최대 열 합
-
왜 이런 계산법이 나올까?
- 아까 벡터에서 p의 값이 1일때와 무한대일때를 생각해보자.
- 1일 때는 작은 값에 집중했다
- 무한대일 때는 가장 큰 값에 집중했다
- 이를 행렬곱 관점에서 보자.
- 행렬곱
mxn * nx1 = mx1- 즉, 앞에 주어진 행렬의 열을 기준으로 곱해진다
- 그러니 주어진 행렬에 대해 벡터를 곱하는 상황에서,
'행렬이 벡터를 얼마나 변화시키냐'라는 norm의 정의를 생각하자.- p가 1이라는 것은 곱할 벡터가 1로 보면 되는데,
여기서 더 큰 변화를 일으키는 것은 max(열의 합) - p가 무한대라는 것은 모든 열에 곱할 벡터가 존재한다고 보면 되므로,
얻을 수 있는 변화 중 가장 큰 조합을 고르면 max(행의 합)
- p가 1이라는 것은 곱할 벡터가 1로 보면 되는데,
- 행렬곱
- 아까 벡터에서 p의 값이 1일때와 무한대일때를 생각해보자.
Dropout
-
드롭아웃 기법은 2014년에 나온 논문이다
Dropout 논문 -
드롭아웃이란?
- 확률적으로 랜덤하게 몇 가지의 뉴런만 선택하여 정보를 전달하는 과정
- 즉, 랜덤하게 몇가지 컬럼을 버리면서 남은 컬럼만 모델에 전달
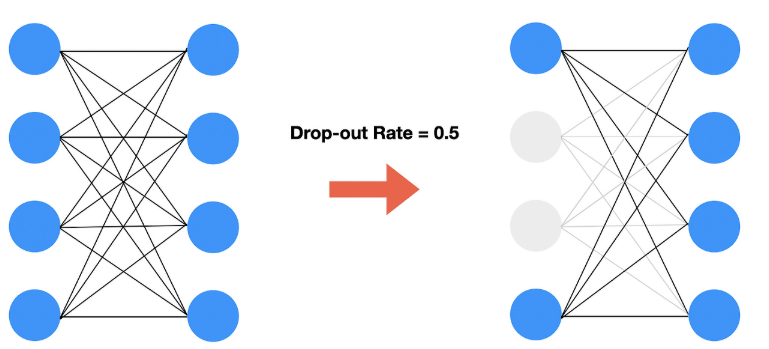
-
오버피팅을 막는 regularization layer 중 하나이다
- 앞에서 봤던 L1, L2 regularization과는 뭐가 다를까?
(필자 의견)
L1, L2는 벌점을 줌으로써 모델이 벌점을 피하게 만드는 방식이라면
드롭아웃은 애초에 과도한 학습을 못하게끔 정보를 다 주지 않고 랜덤으로 몇 개씩 던져줘서 오버피팅을 방지한다
- 앞에서 봤던 L1, L2 regularization과는 뭐가 다를까?
-
실습코드 (not-overfitting)
- 드롭아웃의 확률 값 (dropout_rate)를 너무 높이면 학습이 잘 되지 않아 accuracy가 떨어진다.
- 너무 낮추면 과적합 발생 위험이 생긴다 (랜덤으로 탈락시키는 컬럼이 거의 없어지기 때문)
-
데이터 전처리 및 형태 변환
astype(np.float32) / 255.0: 이미지는 보통 0~255 사이의 정수(unit8)인데, 이를 0~1 사이의 실수로 만드는 Normalization 과정입니다. 모델 학습이 훨씬 안정적으로 변합니다..view(-1, 28*28): 2차원 이미지(28x28)를 1차원(784) 긴 줄로 쭉 펴주는 작업입니다. nn.Linear 층은 1차원 벡터만 입력으로 받을 수 있기 때문입니다.
-
모델 구조의 핵심 문법
super().__init__(): 파이토치 모델을 만들 때 필수입니다. 부모 클래스인 nn.Module의 기능을 그대로 물려받겠다는 선언입니다.nn.Dropout(dropout_rate): 아까 공부한 드롭아웃 레이어입니다. fc1과 fc2 사이에 위치하여 중간 정보 전달을 랜덤하게 끊어줍니다.forward(self, x): 데이터가 모델에 들어왔을 때 어떤 순서로 통과할지 정의하는 '길'입니다.
-
학습 루프의 3단계
1.optimizer.zero_grad(): 지난번 계산했던 기울기를 싹 지웁니다. (안 지우면 계속 누적되어 엉뚱한 방향으로 학습함)
2.loss.backward(): 현재 오차(loss)를 바탕으로 각 가중치들이 얼마나 변해야 하는지(기울기)를 계산합니다.
3.optimizer.step(): 계산된 기울기를 보고 실제로 가중치(
) 값을 업데이트합니다 -
파이토치의 특유의 유용한 기능
model.train(): 모델을 "학습 모드"로 전환합니다. 이게 있어야 아까 말한 드롭아웃이 실제로 작동합니다. (반대로 평가할 땐 model.eval()을 써서 드롭아웃을 꺼야 합니다.)torch.randperm(num_samples): 데이터를 랜덤하게 섞기 위한 인덱스 번호표를 만드는 기능입니다. 매 에폭마다 순서를 섞어줘야 모델이 문제 순서를 외우는 것을 방지합니다..item(): 텐서(Tensor) 안에 들어있는 숫자 하나를 파이썬의 일반 숫자로 꺼내올 때 씁니다. 합계나 오차를 출력할 때 필수입니다.
Batch Normalization
- 왜 하는가? (Internal Covariate Shift 해결)
주의. internal covariate shift와 연관성이 없다는 반론도 있으므로 가볍게 읽고 넘어가기- 문제: 데이터를 미니배치로 나눠서 학습시키다 보면
각 미니배치마다 데이터의 분포가 조금씩 달라서 모델에 혼란이 발생 - 결과: 모델의 학습 속도가 느려지고 에러가 커지는 등 불안정
- 문제: 데이터를 미니배치로 나눠서 학습시키다 보면
어떻게 하는가?
- 데이터를 모델에 넣기 전에 표준화
- 평균 0, 분산 1로 정규화
- 데이터의 중심을 0으로 이동시키고 데이터의 퍼진 폭을 1로 만들어주는 과정
- 모델이 직접 학습하는 변수인 파라미터들을 곱하고 더함
- 모든 미니배치를 똑같이 정규화하면 모델의 표현력에 한계가 생김
(데이터들이 0~1사이의 범위에 밀집하게 되기 때문에 특징을 제대로 표현하기 어려워짐)
- 모든 미니배치를 똑같이 정규화하면 모델의 표현력에 한계가 생김
Batch, Epoch, Iterate 개념 정리
- Epoch 에폭: 전체 학습 데이터셋을 모델이 1회 끝까지 학습한 단위
- Batch 배치: 에폭 내에서 학습 데이터를 나누는 작은 묶음
- Iteration 반복: 1 Epoch를 마치기 위해 필요한 Batch 학습 횟수
코드 실습 (batch normalization layer)
1. nn.BatchNorm1d(128)의 의미
- 숫자 128: 바로 앞 단계인
fc1의 출력 크기(뉴런 개수)와 똑같이 맞춰줘야 합니다. 128개의 뉴런 각각에 대해 평균과 분산을 구해서 정규화하겠다는 뜻이에요. - 위치: 보통
Linear->ReLU->BatchNorm순서나Linear->BatchNorm->ReLU순서로 배치합니다. (위 코드에서는 활성화 함수 다음에 위치)
2. model.train()과 model.eval()의 필수 전환
model.train(): 학습할 때는 현재 미니배치의 평균과 분산을 계산해서 정규화를 수행합니다.model.eval(): 테스트(검증)할 때는 현재 배치의 통계치를 쓰지 않고, 학습할 때 미리 계산해둔 전체 데이터의 평균과 분산(Running Mean/Var)을 가져와서 씁니다.- 만약
eval()을 안 하면? 검증 데이터 한두 개가 들어올 때마다 결과가 들쑥날쑥하게 변할 수 있습니다.
- 만약
3. with torch.no_grad() (검증 루프)
- 검증(Validation) 단계에서는 가중치를 업데이트할 필요가 없으므로,
- 이 코드를 감싸주면 파이토치가 기울기(Gradient)를 계산하지 않아서 메모리도 아끼고 속도도 훨씬 빨라집니다.
Mini-batch Gradient Descent
앞에 나온 Internal Covariate Shift 문제가 발생한 기법에 대해 좀 더 알아보자.
0.배경
- Gradient Descent 경사하강법 기반 모델 가중치 업데이트 방식
- Batch Gradient Descent
- 전체 데이터 셋을 한 번에 사용하여 모델의 가중치를 업데이트
- 계산량이 많으나, 안정적인 gradient
- Stochastic Gradient Descent
- 데이터를 1개씩 사용하여 가중치 업데이트
- 빠르나 gradient가 noisy
- Batch Gradient Descent
- 안정적이지만 계산량이 많아 속도가 느린 Batch 경사하강 방식과,
- 빠르지만 데이터를 하나씩 사용하다보니 모델에 혼란을 가져다주어 안정적이지 못한 Stochasticc 경사하강 방식
- 위 두 방식의 절충안으로 Mini-batch 경사하강법이 제안
1. Mini-batch Gradient Descent
-
데이터를 여러 개의 mini-batch로 나눠서 업데이트하는 방식
-
속도와 안정성의 균형을 잡음
-
[예시 상황: No Batch Normalization]
Model architecture
mini batch → layer 1 → layer 2 → output- [첫 epoch] Layer1의 출력: 평균 = 2, 분산 =15
- [둘 epoch] Layer1의 출력: 평균 = 4, 분산= 70
- layer 2의 입장에서는 입력 데이터가 완전히 바뀜.
- gradient vanishing, gradient explode와 같은 문제
- 즉, gradient 불안정 → 학습 불안정
-
gradient란?
쉽게 말해, loss 함수를 보고 앞으로 학습할 방향을 알려주는 요소- gradient vanishing 기울기 소실 문제
신호가 뒤로 갈수록 너무 작아져서 제대로된 학습이 이뤄지지 않음 - gradient exploding 기울기 폭주 문제
신호가 너무 강해서 가중치 값이 한 번에 튀어버리는 상태.
계산 결과가 NaN으로 뜨면서 모델이 망가진다
- gradient vanishing 기울기 소실 문제
