오늘의 학습 목표
- 데이터 전처리의 전 과정에 대해 살펴본다
- 중복 데이터 처리, 결측치 처리, 데이터 정규화, 이상치 처리에 대해 이해한다
- 범주형 데이터의 전처리 방법으로 원-핫 인코딩 방법을 이해한다
- 연속적인 데이터를 구간으로 나눠 범주형 데이터로 변환하는 방법을 이해한다
- 위의 전 과정을 python 환경에서 경험한다 (단, 처리 방법에 대해 경험하는 수준으로 완벽한 데이터 전처리를 요구하지 않는다)
0. 들어가며
- 전처리는 왜 중요할까요?
- 아무리 대단한 분석가가 와도, 최고 성능의 모델을 사용해도 결국은 좋은 데이터가 전제되어야 합니다.
- 데이터 분석의 8할은 데이터 전처리이다
- 전처리에 따라서 데이터 분석의 질이 달라지기 때문
- 데이터 분류
- 정형 / 반정형 / 비정형 데이터
- 수치 데이터
- 연속형 데이터
- 이산형 데이터
- 범주형 데이터
- 순서형 데이터
- 명목형 데이터
- 파이썬 라이브러리 Pandas, NumPy
- 보다 자세한 학습은 → Pandas, Numpy 정리본
- 핵심기능
- Pandas: 데이터 불러오기, 전처리, 데이터 합치기
- NumPy: 대규모 행렬 연산, 선형대수학, 수학적 함수 계산
- 캐글 Kaggle
구글이 운영하는 데이터 과학 및 머신러닝 경진대회 플랫폼- 다양한 분야의 실제 데이터를 무료로 다운로드할 수 있다
데이터 준비
- 데이터셋 다운로드 → Video Game Sales
(해당 포스트에서는 캐글의 video game sales 데이터셋을 사용합니다)!pip install kagglehub import kagglehub # Download latest version path = kagglehub.dataset_download("gregorut/videogamesales") print("Path to dataset files:", path) - 데이터 불러오기
import pandas as pd
trade = pd.read_csv("f{path}/vgsales.csv")
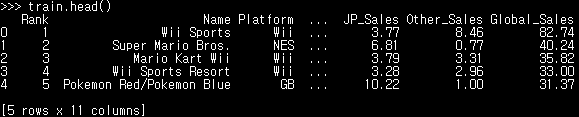
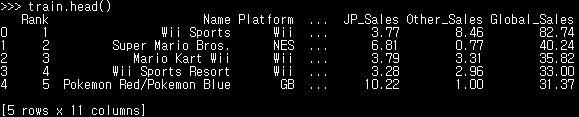
train.head() #데이터 상단의 n개 행 출력
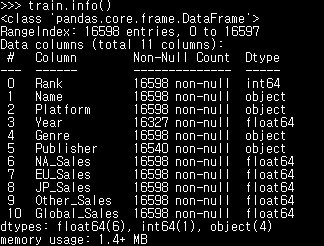
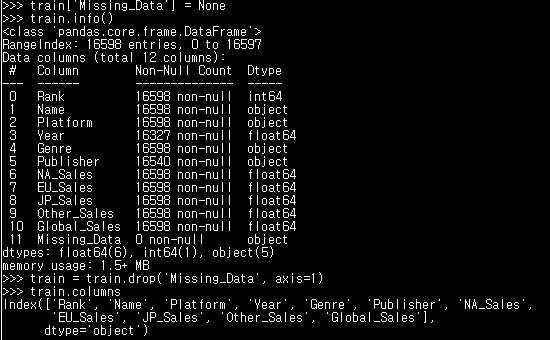
train.info() #변수 정보 확인하기1. 결측치 (Missing Data)
결측치 확인하기
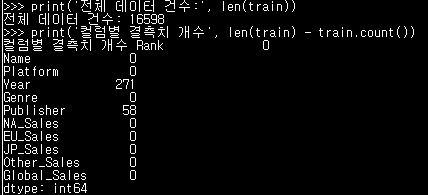
print('전체 데이터 건수:', len(train))
print('컬럼별 결측치 개수', len(train) - train.count())- 위의 코드와 같이 (전체 데이터 건수) 에서 (컬럼별 값이 있는 데이터 수)를 빼주어 결측치의 개수를 구할 수 있다
- 혹은, 앞에서 봤던
info()함수의 결과를 보면 변수별로 non-null count가 나오는데 이를 통해서도 알 수 있다 - 실습에서 다루진 않지만 또 다른 방법
train['Year'].isna().sum()
결측치 처리
- 삭제
- 결측치가 관측된 컬럼 중 모든 값이 결측치인 경우에는 아무런 정보가 없는 컬럼이므로 삭제한다
- 또한, 의미 없는 데이터로 판단 시 삭제할 수 있다 (이번 실습에서는 완벽한 전처리가 목표가 아니라 전처리 과정을 경험하는 것이 목표이므로 해당 과정은 생략)
- 실습 데이터에서는 그런 컬럼이 관측되지 않아 새로 아무런 값이 없는 컬럼을 추가 후 삭제하는 방식으로 경험
train['Missing_Data'] = None # Missing_Data 컬럼을 추가하고 NaN값으로 채워줌
train.info() # 실행해보면 Missing_Data 컬럼은 0 Non-Null 로 모두 null값임을 확인할 수 있다
train = train.drop('Missing_Data', axis=1) # drop() 사용자가 지정한 특정 행/열 삭제 함수. axis = 1은 열을 의미. axis=0은 행을 의미.
train.columnsdrop대신train.dropna(axis=1, how='any', subset=['Missing_Data'], inplace=True)를 사용할 수도 있다- 이 경우,
inplace = True덕분에 따로 train = train.dropna ... 을 할 필요 없이 원본 데이터에 바로 적용된다- 실습 사진에도 나오겠지만 pandas 3.0부터는 권장되지 않는 방식이다.
how옵션으로는all전부가 결측치인 경우any하나라도 결측치인 경우
dropna,fillna모두 결측치에 대해 동작
- 이 경우,
- 대체하기
- 수치형 데이터
- 특정 값 지정해주기
- 평균, 중앙값 등으로 대체
- 다른 데이터를 이용해 예측값으로 대체
- 시계열 특성을 가진 데이터의 경우 앞뒤 데이터를 통해 결측치를 대체
- 범주형 데이터
- 특정 값 지정 "Unknown"
- 최빈값 등으로 대체
- 다른 데이터를 이용해 예측값으로 대체
- 시계열 데이터의 경우 앞뒤 데이터를 통해 결측치 대체
- 수치형 데이터
- 실습
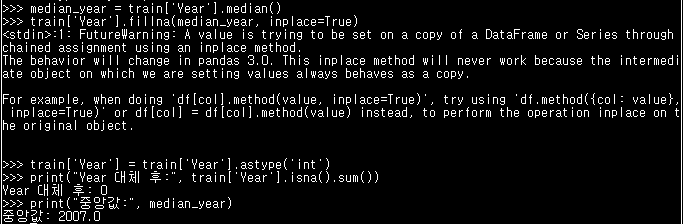
# Year 결측치: 중앙값으로 대체
median_year = train['Year'].median()
train['Year'].fillna(median_year, inplace=True) # 결측치 채워 넣기
# train['Year'] = train['Year'].fillna(median_year) 이 방식을 권장
train['Year'] = train['Year'].astype('int')
print("Year 대체 후:", train['Year'].isna().sum())
print("중앙값:", median_year)
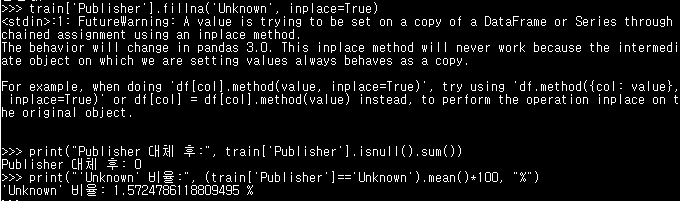
# Publisher 결측치: 'Unknown'으로 대체 (범주형)
train['Publisher'].fillna('Unknown', inplace=True)
print("Publisher 대체 후:", train['Publisher'].isnull().sum())
print("'Unknown' 비율:", (train['Publisher']=='Unknown').mean()*100, "%")- 실습에서 다루지 않았지만 알아두면 좋은 명령어
train.loc[row, column]특정 행과 열 추출
2. 중복된 데이터
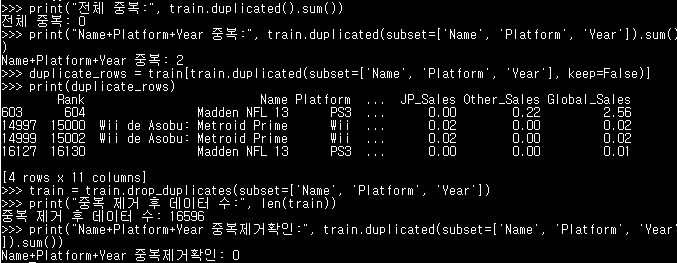
print("전체 중복:", train.duplicated().sum())
print("Name+Platform+Year 중복:", train.duplicated(subset=['Name', 'Platform', 'Year']).sum())
# 중복 데이터 확인
duplicate_rows = train[train.duplicated(subset=['Name', 'Platform', 'Year'], keep=False)]
print(duplicate_rows)
# 중복 데이터 제거
train = train.drop_duplicates(subset=['Name', 'Platform', 'Year'])
print("Name+Platform+Year 중복제거확인:", train.duplicated(subset=['Name', 'Platform', 'Year']).sum())3. 이상치 Outlier
- 이상치란?
대부분 값의 범위에서 벗어나 극단적으로 크거나 작은 값을 의미
이상치를 찾는 방법
z score방법
(실습에서는 IQR 방법을 사용하므로 여기에 코드 설명)abs(df[col] - np.mean(df[col]))데이터에서 평균을 빼준 것에 절대값을 취합니다.abs(df[col] - np.mean(df[col]))/np.std(df[col])위에서 얻은 값을 표준편차로 나눠줍니다.df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index값이 z보다 큰 데이터의 인덱스를 추출합니다.def outlier(df, col, z): return df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index- 데이터가 치우쳐 있거나(Skewed) 이상치가 너무 극단적일 경우 평균과 표준편차가 왜곡되는 한계
- IQR method
- 데이터의 중간 50% 범위를 의미하며, 데이터를 4등분했을 때 상위 75%(Q3)와 하위 25%(Q1)의 차이를 계산
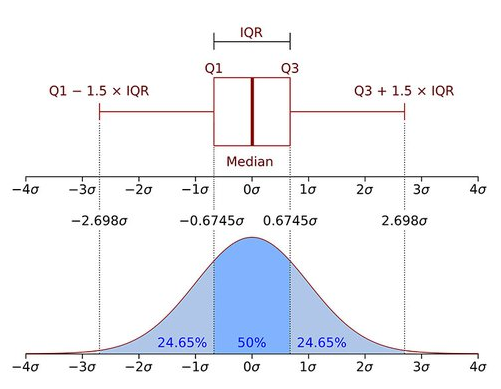
- 데이터의 중간 50% 범위를 의미하며, 데이터를 4등분했을 때 상위 75%(Q3)와 하위 25%(Q1)의 차이를 계산
이상치 처리
- 삭제
원래 데이터에서 이상치를 삭제하고, 이상치끼리 따로 분석하는 방안도 있다 - 대체
최댓값, 최솟값을 설정해 데이터의 범위를 제한 - 다른 데이터를 활용하여 예측값으로 대체
- binning을 통해 수치형 데이터를 범주형 데이터로 변환
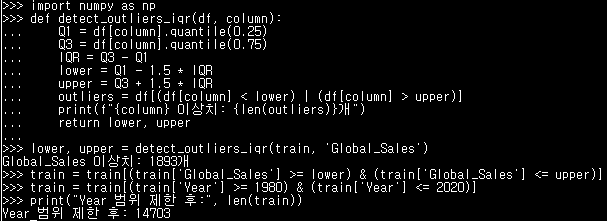
- 실습 (IQR 이용)
import numpy as np
# IQR 함수
def detect_outliers_iqr(df, column):
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
outliers = df[(df[column] < lower) | (df[column] > upper)]
print(f"{column} 이상치: {len(outliers)}개")
return lower, upper
# Global_Sales에 IQR 적용
lower, upper = detect_outliers_iqr(train, 'Global_Sales')
train = train[(train['Global_Sales'] >= lower) & (train['Global_Sales'] <= upper)]
# Year 이상치 제한
train = train[(train['Year'] >= 1980) & (train['Year'] <= 2020)]
print("Year 범위 제한 후:", len(train))4. 정규화 Normalization
- 정규화 왜?
데이터 컬럼마다의 크기를 통일 시켜서 피처들의 중요도 차이가 나지 않게 하기 위해서 - 종류
1. Standardization
x_standardization = (x-x.mean())/x.std()
z-score 공식- 데이터의 평균은 0, 분산은 1로 변환
- 보통 평균이 0이고 표준편차가 1일 때 사용한다
- 데이터가 가우시안 분포를 따를 경우 유용하다
- 범위에 제한은 없지만 보통 데이터의 99% 이상이 -3~3 사이에 들어온다
2. Min-Max Scaling
x_min_max = (x-x.min())/(x.max()-x.min())- 데이터의 최솟값은 0, 최댓값은 1로 변환
0~1 사이로 데이터 범위를 제한한다 - 피처의 범위가 다를 때 주로 사용
- 확률 분포를 모를 때 유용하다
- 실습
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
sales_cols = ['NA_Sales', 'EU_Sales', 'JP_Sales', 'Other_Sales', 'Global_Sales']
train[sales_cols] = scaler.fit_transform(train[sales_cols])
print("정규화 범위 (Global_Sales):", train['Global_Sales'].min(), "~", train['Global_Sales'].max())5. 원-핫 인코딩 One-Hot Encoding
- 원-핫 인코딩이란?
- 카테고리별 이진 특성을 만들어 해당하는 특성만 1, 나머지는 0으로 만드는 방법
- 머신러닝이나 딥러닝 프레임워크에서 범주형을 지원하지 않는 경우 원-핫 인코딩을 해야 한다
- 실습
from sklearn.preprocessing import OneHotEncoder
cat_cols = ['Platform', 'Genre']
encoder = OneHotEncoder(sparse_output=False, drop='first')
encoded = encoder.fit_transform(train[cat_cols])
encoded_df = pd.DataFrame(encoded, columns=encoder.get_feature_names_out(cat_cols))
train = pd.concat([train.drop(cat_cols, axis=1).reset_index(drop=True), encoded_df.reset_index(drop=True)], axis=1)
# concat: 두 데이터프레임을 합쳐주는 함수
print("원-핫 후 컬럼 수:", len(train.columns))- Pandas의
get_dummies함수 이용하는 방법도 있다
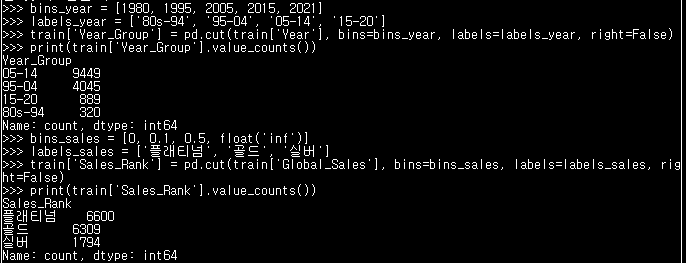
6. 구간화 Binning
bins_year = [1980, 1995, 2005, 2015, 2021]
labels_year = ['80s-94', '95-04', '05-14', '15-20']
# cut함수에 데이터와 구간을 입력하면 데이터를 구간별로 나눠준다
train['Year_Group'] = pd.cut(train['Year'], bins=bins_year, labels=labels_year, right=False)
print(train['Year_Group'].value_counts())
bins_sales = [0, 0.1, 0.5, float('inf')]
labels_sales = ['플래티넘', '골드', '실버']
train['Sales_Rank'] = pd.cut(train['Global_Sales'], bins=bins_sales, labels=labels_sales, right=False)
print(train['Sales_Rank'].value_counts()) # value_counts()로 구간별 값을 확인할 수 있다-
cut 함수 대신
qcut함수를 사용할 수도 있다qcut은 구간을 일정하게 나누는 것이 아니라 데이터의 분포를 비슷한 크기의 그룹으로 나눠줌
-
실습 마무리
print("최종 shape:", train.shape)
train.info()
train.head()
train.to_csv('processed_vgsales.csv', index=False)부록: z-score
- 정규화의 종류 중 하나인 stnadardization 에 사용
- outlier 탐지 방법으로 사용
- 무슨 차이?
우선 둘다 같은 공식 을 사용한다- standardization
- 목표: 데이터의 스케일을 맞추는 것.
서로 다른 변수들이 평균 0, 표준편차 1을 가지도록 변환\ - 특징: 데이터 전체에 적용, 스케일은 바뀌지만 데이터의 형태는 유지됨
- 목표: 데이터의 스케일을 맞추는 것.
- outlier 탐지
- 목표: 데이터 중 평균에서 지나치게 멀리 떨어진 이상치를 식별
- 특징: 임계값(보통 +-3)으로 사용. Z-SCORE를 기준으로 범위를 지정
- standardization
실습 결과 모음