TIL: LLM Training - From Transformer & Learning Paradigms to RLHF, Architecture and MLOps
TIL
오늘의 학습
- Transformer의 Decoder 기반 모델들에 대해 알아본다
- 인공지능 학습 방법론을 정리한다
- 방법론이 실제 모델 학습 시에 어떻게 활용되는지, chatGPT에는 어떤 기법이 적용되었는지 이해한다
- 머신러닝 아키텍처를 정리한다
- MLOps 내용을 정리한다
이 포스트의 전반적인 개념은 주로 해당 도서의 1장을 참조하고 있습니다.
[파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습] - 윤대희,김동화,손종민,진현두
인공지능이란?
Artificial Intelligence, AI
- 패턴 인식, 학습, 의사결정과 같이 일반적으로 인간 지능이 필요한 작업을 컴퓨터 시스템이 수행하는 기술
- 강인공지능
- 스스로 학습과 인식 등이 가능하며, 지능 또는 지성의 수준이 인간과 근사한 수준까지 이른 경우
- 주로 SF 영화에 등장하는 휴머노이드를 생각하면 된다
- 약인공지능
- 인간이 해결할 수 있으나, 기존의 컴퓨터로 처리하기 힘든 작업을 처리하기 위한 일련의 알고리즘
- 현재 많은 곳에서 활용되는 AI 서비스가 이에 해당
- 다양한 유형이 존재
- 규칙기반 AI (Rule-based)
미리 결정된 일련의 규칙 또는 알고리즘에 따라 문제를 해결하거나 작업을 수행 - 머신러닝
데이터를 이용해 모델을 학습하고, 이를 통해 예측이나 분류를 수행 - 딥러닝 (머신러닝의 한 유형)
정보를 처리하고 전송하는 방식을 시뮬레이션하도록 설계된 알고리즘인 인공 신경망을 사용
- 규칙기반 AI (Rule-based)
머신러닝
-
전통적 프로그래밍과의 차이
- 전통적 프로그래밍: 데이터와 규칙 → 결괏값
- 머신러닝: 데이터와 결괏값 → 규칙
-
신경망 ⊂ 딥러닝 ⊂ 머신러닝 ⊂ 인공지능- Artificial Neural Netwrok, ANN (인공 신경망)
- 인간의 뇌에 있는 신경 세포 뉴런의 네트워크에서 영감을 얻은 통계학적 학습 알고리즘
- 서로 연결된 노드의 집합으로 구성되었다
- 여러 계층(레이어)으로 이뤄져 있다
- 딥러닝
- 여러 신경망 계층과 대량의 데이터를 활용해 학습을 진행
- input layer, 입력층
- hidden layer, 은닉층
- 여러 개의 복잡한 은닉층을 활용해 구현되어서 Deep 러닝이다
- output layer, 출력층
- Artificial Neural Netwrok, ANN (인공 신경망)
-
머신러닝은 학습에 사용되는 알고리즘 기법으로 그 유형을 나눌 수 있다
(뒤에 나오는 학습 방법론 파트에서 자세히 다룬다)
Transformer의 Decoder 기반 모델들
각 모델들의 특징, 적용 기법(성능향상, 경량화 등), 사이즈 등을 조사해보고 어떤 상황에 어떤 모델을 사용하면 좋을 지 생각해보는 것이 이 파트의 목표입니다.
Major LLMs rank
- claude 4.5 opus
- Substring removal
- train set과 validation set에서 5개 이상의 문제-정답을 공유하는 데이터를 제거.
→ 과적합(overfitting) 방지.
- train set과 validation set에서 5개 이상의 문제-정답을 공유하는 데이터를 제거.
- Fuzzy decontamination.
- segment overlap analysis을 활용해서, validation set이 평가하는 기준을 파악한 다음 training set에서 20 token 이상 일치하는 비중이 40% 이상인 데이터를 validation set에서 제외.
- 역시 과적합 방지 및 모델 성능의 일반성 개선.
- Canary string filtering
- 모델 훈련에 어떤 문자열(string)이 포함되지 말아야 한다는 것을 알려주는 canary string을 파악하고, training set에서 canary string을 포함하는 document을 제거함.
- Substring removal
- kimi k2 Thinking 중국 AI 스타트업에서 개발한 차세대 추론형 AI 모델
- OpenAI의 o1 모델과 유사
- 복잡한 문제를 해결하는 데 특화되어 있다.
- 전체 파라미터 : 1조 개(1 Trillion)
- Native INT4 양자화 (Quantization): 모델 학습 단계에서부터 4비트 양자화를 고려하는 QAT(Quantization-Aware Training)를 적용
- 모델을 나중에 압축될 것을 대비해 미리 4비트 수준에서 학습을 훈련
- MLA (Multi-head Latent Attention): 데이터 처리 과정에서 메모리 사용량을 줄이면서도 긴 문맥을 효율적으로 처리
- Muon 옵티마이저: 대규모 모델 학습 시 안정성을 높이고 성능을 최적화하는 새로운 최적화 알고리즘을 사용
- Gemini 2.5
특징- 생각하는 모델:
- 반응하기 전에 생각을 정리
- 내부적으로 여러 단계로 사고를 전개한 뒤, 정리한 답만 사용자에게 보여주는 구조를 사용해서 추론 성능을 올림
- 강력한 추론.코딩.수학.과학
- MMLU, GPQA, SWE-Bench 등 여러 벤치마크에서 상위권 성능을 기록
- 네이티브 멀티모달:
- 텍스트, 이미지, 비디오, 코드 저장소까지 한 모델로 처리하는 것을 전제로 설계
- 긴 컨텍스트:
- 2.5 Pro는 100만 토큰 컨텍스트 윈도우(200만 토큰 지원 예정)를 제공
- 즉, 수천 페이지 문서나 대형 코드베이스도 한 번에 다룰 수 있음
- Gemini 모델의 강점인 네이티브 멀티모달리티와 긴 컨텍스트 윈도우를 기반으로 더욱 발전
- 긴 컨텍스트 최적화:
- 1M 컨텍스트를 위해 RoPE/ALiBi 계열 스케일링, sparse attention, chunking/압축 등 긴 시퀀스 최적화 기법이 적용된 것으로 알려짐
- 1M+ 토큰용 전용 아키텍처를 강조
- Post-training으로 추론 강화:
- 강화학습과 chain-of-thought prompting 기술을 이용해 ‘반응 전 내부 사고’ 능력을 키운 게 핵심 포인트
- Deep Think / Thinking budget:
- Pro에 대해 ‘생각 예산(thinking budget)’을 늘리거나 줄여 속도-정확도 트레이드오프를 제어하는 기능 제공
- deepthink모드
- thought summary 모드
- Thought summary:
- API/Vertex에서 모델의 내부 사고를 요약한 ‘생각 요약’을 제공해, 디버깅과 에이전트 동작 분석을 돕는 기능이 추가됨
- 공식 파라미터 수치는 공개 되지 않았음
- 모델 시리즈별 용도와 리소스 특성
모델 용도 리소스 특성 2.5Pro 고난도 추론, 리서치, 복잡한 코딩 가장 무겁고 비쌈, 속도는 Flash보다 느림 2.5Flash 일반 챗, 대량 트래픽 서비스 가볍고 빠름, 대규모 배포에 적합 2.5 Nano 온디바이스(모바일, IoT 등) 디바이스에 직접 실행 가능
- 생각하는 모델:
- Deepseek V3.1
- 모델 사이즈 및 제원
- 총 파라미터(Total Parameters) : 6,710억개 (671B)
- 활성화 파라미터(Activated Parameters) : 토큰당 370억개(37B)
- 실제 단어 하나를 생성할때에는 전체의 약 5.5%만 활성화, 거대 언어 모델의 성능을 유지하면서도 구동 비용을 극단적으로 낮춤
- 컨텍스트 길이(Context Length) : 128K 토큰 (약 10만 단어 이상의 방대한 문맥을 한번에 처리)
- 적용 기법
- MoE(Mixture of Expert) 라우팅 : 입력된 데이터가 전체 신경망을 모두 통과하는 것이 아니라, 수백 개의 ‘전문가(Expert)’ 네트워크 중 가장 적합한 소수의 경로로만 배분되는 기법(연산 속도, 비용 효율성 결정의 핵심 기술)
- MLA(Multi-head Latent Attention) : 128K에 달하는 긴 문맥을 기억, 처리할 때 발생하는 메모리 병목 현상을 해결하기 위해, 데이터를 효율적으로 압축하여 처리 속도를 높이는 독자적인 Attention 아키텍쳐
- Attention 아키텍쳐
- 입력된 데이터(단어들)가 서로 어떤 연관성을 가지는지 수학적으로 계산, 특정 단어를 생성하거나 이해할 때 문장 내의 어떤 단어들에 더 높은 가중치(집중도)를 두어야 할지 결정
- Q(Query : 질문)와 문장 속 모든 K(Key : 키표)를 비교하여 연관성 점수(Attention score)를 매기고 그 점수가 높은 쪽의 V(Value : 내용)를 더 많이 끌어와서 최종적으로 문맥을 종합해 내는 방식
- Deepseek에 적용된 MLA는 이 기본적인 어텐션 구조에 ‘메모리 효율성’을 극한으로 끌어올린 기술로 데이터를 고도로 압축하여 128K라는 엄청나게 긴 문맥도 빠르고 가볍게 처리할 수 있게 모델
- Attention 아키텍쳐
- 초고효율 FP8 훈련 (FP8 Microscaling) : 모델 훈련 및 추론 과정에서 데이터 처리 형식을 고도로 최적화(UE8MO FP8)하여 성능 저하 없이 GPU 메모리 사용량과 전력 소모를 대폭 줄였음.
- 모델 사이즈 및 제원
대표 LLM 모델들의 분야별 성능 비교 분석 및 정리: 멀티 모델 활용의 필요성을 포함하여
- 위 링크는 필자가 2025년도 여름에 작성한 보고서입니다.
- 참고하면 학습에 도움이 될 수 있을듯하여 공유합니다.학습 방법론
지도학습
Supervised Learning
- training data를 통해 입력과 label의 관계를 알고리즘으로 학습시킨다
- 훈련 데이터는 입력 데이터와 출력 데이터로 구성된다
입출력데이터의 관계는 (문제-답)이라고 생각하면 된다 - label이 바로 출력 데이터. 답이다
- 훈련 데이터는 입력 데이터와 출력 데이터로 구성된다
- 입력데이터
- 일반적으로 벡터 형태로 구성되어있고, 해당 벡터들이 어떤 의미를 내포하고 있는지 레이블링(labeling) 되어 있다
Ex. [키, 몸무게, 나이]를 생각하면 된다
[160, 50, 20] - (저체중) 이런식으로 한 명의 사람에 대한 키, 몸무게, 나이를 하나의 벡터로 두고 '저체중'이라는 상태가 labeling 되어 있다- 여기서 스칼라, 벡터는 방향의 유무보다는 단일값과 1차원 배열이라 생각하는게 좋다
- 일반적으로 벡터 형태로 구성되어있고, 해당 벡터들이 어떤 의미를 내포하고 있는지 레이블링(labeling) 되어 있다
- 높은 정확도와 안정적인 학습을 기대할 수 있다
- 훈련 데이터에 정답이 포함되어 있기 때문
- 그만큼 레이블링을 하는 데에 시간도 오래 걸리고
- 레이블링 품질이 매우 중요하다
회귀 분석 (Regression)
- 둘 이상의 변수 간의 관계를 파악함으로써 독립 변수인 X로부터 연속형 종속 변수인 Y에 대한 모형의 적합도를 측정하는 통계적 분석 방법
- X는 특징(피처, feature) / Y는 목표(Traget)이다
- 크게 linear regression과 non-linear regression으로 나눌 수 있다
- Linear Regression
함수가 선형. 직선의 특징을 갖는다
- 중첩의 원리(Superposition Principle)가 적용된다
-결과값이 각 독립변수가 개별적으로 미치는 영향력을 단순히 더한 결과와 같다 - 단변량과 다변량으로 나눌 수 있다
- 종속 변수가 하나일 때 = 단변량
단변량은 독립 변수가 하나 이상의 값을 사용할 수 있다- 독립 변수가 하나라면 = 단순(Simple) → 단순 선형 회귀 분석 :
- 독립 변수가 두 개 이상 = 다중(Multiple) → 다중 선형 회귀 분석 :
(는 가중치, 는 편향성을 의미)
- 종속 변수가 두 개 이상 = 다변량
- 종속 변수가 하나일 때 = 단변량
- 대표적으로 로버스트 회귀와 라쏘 회귀가 있다
a. Robust Regression
b. Lasso Regression
- Non-linear Regression
방정식이 한 가지 형태로 제한되지 않고 여러 가지 형태인 곡선으로 도출된다
- 선형과 달리 함수의 수식을 예측하기 어렵다
- 그래서 다층 퍼셉트론 MLP을 활용한다
분류 (Classification)
- 훈련 데이터에서 지정된 레이블관의 관계를 분석해 새로운 데이터의 레이블을 스스로 판별하는 방법
- 새로운 데이터를 대상으로 카테고리 또는 범주를 스스로 판단, 할당한다
- 이진 분류와 다중 분류가 있으며 대표적인 알고리즘은 다음과 같다
- 이진분류 → 로직스틱 회귀
Logistic Regression- 이산형 종속 변수를 예측하는 데 logit transformation을 사용해 편향성이 없는 타다한 계수를 추정할 수 있음
- 다중분류 → 소프트맥스 회귀
Softmax Regrsssion- 가중치를 정규화해 나온 결괏값을 모두 더할 때 1이 되게끔 구성하는 것을 의미
- Ex: A,B,C를 분류하는 알고리즘을 만들었을 때,
출력값은 A: 0.1, B: 0.1, C:0.8 로 나오고
C일 확률이 80%로 가장 높으므로 C를 선택한다 (확률분포를 통해 다중분류 진행)
- 이진분류 → 로직스틱 회귀
비지도학습
Unsupervised Learning
- 훈련 데이터에 레이블을 포함시키지 않고 알고리즘이 스스로 독립 변수 간의 관계를 학습하는 방법
- 특정한 규칙을 지정하여 패턴이나 상관관계를 찾는 모델을 생성한다
- 사전학습이 필요 없다 (labeling을 할 필요가 없이, 데이터로만 결과를 유추하기 때문)
- 데이터의 근본적인 구조를 발견하거나 직관적으로 처리하기 어려운 작업을 수행할 수 있다
- 레이블이 존재하지 않아, 결과에 대한 성능평가는 어렵다
군집화 (Clustering)
입력 데이터를 기준으로 비슷한 데이터끼리 몇 개의 군집으로 나누는 알고리즘
- K-Means Clustering
K-평균 군집화- 임의의 중심점(Centroid)을 기준으로 최소 거리에 기반한 군집화를 진행
- 각 데이터는 가장 가까운 중심에 군집을 이룬다 (이때는 임의의 k개의 중심점)
- 데이터는 각 군집 중심과 가장 가까운 군집으로 할당 (각 군집 데이터들의 평균 위치로 중심점을 업데이트)
- 반복
- K는 군집의 개수를 의미
- 군집의 크기, 밀도, 형태가 특이하거나 서로 다를 경우 좋지 않은 결과가 나올 수 있다
- 임의의 중심점(Centroid)을 기준으로 최소 거리에 기반한 군집화를 진행
- Density-based spatial clusstering of application with noise, DBSCAN
밀도 기반 군집화- 특정 공간 내에 데이터가 많이 몰려 있는 부분을 대상으로 군집화하는 알고리즘
- 임의의 P 점(Sample)을 기준으로 특정 거리(Epsilon) 내에 점이 M(Min samples)개 이상 있다면 하나의 군집으로 간주한다
- 여기서 임의의 점 P는 모든 점에 대해 해당 과정이 이뤄진다고 보면 된다
- ɛ-이웃 (Epsilon-neighborhood) : P를 기준으로 특정 거리 내의 영역
- ɛ-이웃 안에 샘플이 M개 이상이라면 핵심 샘플(Core sample) 또는 핵심 지점(Core point)이라 부르며, 핵심 샘플을 찾는 과정을 반복한다
- 모든 점들에 대해 편입과정이 이뤄지고나서도 핵심 샘플이 아닌 영역은 이상치로 간주
- 임의의 P 점(Sample)을 기준으로 특정 거리(Epsilon) 내에 점이 M(Min samples)개 이상 있다면 하나의 군집으로 간주한다
- k-means와 달리 사전에 군집 개수를 정하지 않아도 된다
- 밀도를 기준으로 군집화
- 복잡한 분포의 데이터를 분석할 수 있다
- 어떤 군집에도 속하지 않는 이상치를 구분할 수 있다
- 특정 공간 내에 데이터가 많이 몰려 있는 부분을 대상으로 군집화하는 알고리즘
- 이외에도 병합 군집화(Agglomerative Clustering), 평균 이동 군집화(Mean-Shift Clustering), 계층적 군집화(Hierarchical Clustering), 스펙트럼 군집화(Spectral Clustering)등이 있다
이상치 탐지 (Outlier Detection, Anomaly Detection)
밀도가 높은 데이터 분포에서 멀리 떨어져 있는 샘플을 찾는 것
- 왜?
이상 데이터가 많이 분포하면 학습 모델이나 알고리즘의 정확도와 신뢰도가 낮아진다 - 크게 이상치와 이상 탐지가 있다
- 이상치 Outlier Detection
횡단면 데이터(Cross-sectional data)에서 비정상적인 데이터를 찾는 것 - 이상 Anomaly Detection
시계열 데이터에서 비정상적인 데이터를 찾는 것
- 이상치 Outlier Detection
- 밀도가 높은 지역의 데이터는 정상치(Inlier)로 부르며 밀도가 낮은 지역의 데이터는 이상치로 부름
- 이상치 탐지 알고리즘
- 고립 포레스트(Isolation Forest)
- LOF(Local Outlier Factors)
- One-class SVM 등이 있다
차원 축소 (Dimensionality Reduction)
고차원 데이터의 차원을 축소해 저차원의 새로운 데이터로 변환하는 것
- 연산량 감소, 노이즈 및 이상치 제거, 시각화 등에 이점
- 크게 특징 선태과 특징 추출이 있다
- 특징 선택
Feature Selection- 모델의 성능 향상에 유용한 특징 변수들을 선택하고 불필요한 변수들을 제거하는 것
- 특징 추출
Feature Extraction- 여러 특징을 하나로 압축해 새로운 특징을 만들어내는 것
- 특징 선택
- 차원 축소 알고리즘
- 주성분 분석(Principal Component Analysis, PCA)
- 특잇값 분해(Singular Value Decomposition, SVD)
- 음수 미포함 행렬 분해(Non-negative Matrix Factorization, NMF) 등이 있다
준지도학습
Semi-supervised Learning
- 레이블이 포함된 데이터와 포함되지 않은 데이터를 함께 학습에 활용
- 주로 많은 데이터를 보유하고 있으나, 레이블이 할당된 데이터가 적을 때 사용
- 명확하게 레이블을 나눌 수 있는 시스템을 구축 할 때(학습시킬 때) 적용할 수 있으며, 다음의 세 가지 기준을 가정해 진행
- 평활도 Smoothness 가정
특징이 비슷한 데이터는 동일한 레이블을 가질 가능성이 높다 - 저밀도 Low-density 가정
데이터의 확률 밀도가 높은 곳에는 결정 경계(Decision boundary)가 생기지 않는다- 현재 시스템 구축에 사용되는 데이터가 이산형(Discrete) 군집을 형성할 가능성이 높다는 가정
- 다양체 Manifold 가정
고차원 공간의 데이터 특징을 잘 표현하는 저차원 공간이 존재한다- 복잡한 특징을 가지고 있는 데이터라도 초평면(Hyperplane)에 투영하거나 정사한다면 더 구분하기 쉬운 특성(characteristic)으로 변환된다는 의미
- 평활도 Smoothness 가정
- 군집화가 필요한 시스템이나 오토 인코터(Auto Encoder), 생성적 적대 신경망(Generative Adversarial Networks, GAN)과 같은 생성 모델(Generative Model) 등에 활용
- 비지도학습과 닮은 장점: 레이블이 없는 데이터를 활용해 클러스터링 과정을 진행 → 군집화 시스템에서의 활용
- 레이블이 없는 방대한 데이터로 데이터 간의 유사성을 먼저 파악
- 이를 통해 데이터의 클러스터를 알아내고 소량의 레이블을 이용해 각 군집의 정체를 확정 지음.
- 군집화 시스템의 정확도를 높인다
- 다양체 가정 → 오토인코더에서의 활용
- 오토인코더는 이 다양체를 찾아내어 데이터를 압축하는데
- 준지도학습은 이 과정에서 레이블 정보를 가이드로 삼아 더 의미 있는 피처를 추출하게 도움
- 지도학습처럼 답을 내는 것 뿐 아니라 비지도학습처럼 분류도 학습하게 된다 → 생성적 적대 신경망에서의 활용
- 레이블이 없는 데이터로부터는 데이터의 일반적인 구조(분류)를 배우고
- 레이블이 있는 데이터로는 정확한 클래스 정보를 학습
- 결과적으로 생성 모델이 특정 카테고리에 맞는 고품질의 데이터를 생성할 수 있도록 유도
- 비지도학습과 닮은 장점: 레이블이 없는 데이터를 활용해 클러스터링 과정을 진행 → 군집화 시스템에서의 활용
- 대표 기법 2가지
- Consistency Training (일관성 훈련)
- 원본 데이터에 Noising(Swap, Delete, Insert, Substitute)을 가해도 모델의 예측값이 변하지 않도록 학습
- 원본 데이터와 노이즈 낀 데이터가 같다 = 평활도 가정에서 기반되는 판단
- 데이터의 외형이 바뀌어도 본질(Label)은 같다는 일관성을 모델에게 주입하는 것
- 원본 데이터에 Noising(Swap, Delete, Insert, Substitute)을 가해도 모델의 예측값이 변하지 않도록 학습
- Pseudo-Labeling (가짜 라벨링)
- 라벨이 있는 소량의 데이터로 학습된 모델이 라벨 없는 데이터의 정답을 추측하게 함
- 그 추측값을 가짜 정답(Pseudo Label)으로 삼는다
- 저밀도 가정과 연관 (모델이 판단한 데이터에 대해 라벨을 붙여 경계를 더 명확히 하는 과정)
- 소량의 진짜 라벨과 가짜 라벨 데이터로 모델을 학습시킴
(가짜 라벨을 만든 모델과는 다른 모델임)
- Consistency Training (일관성 훈련)
자기지도학습
Self-supervised Learning
- 배경
지도학습에는 질 좋은 라벨링에 많은 비용이 든다는 문제점이 존재했음.
그래서, unlabelled dataset만으로 데이터를 잘 표현하는 좋은 모델을 얻으면 얼마나 좋을까? 라는 생각에서 시작.
비지도학습을 통해 좋은 표현을 얻는다면 다양한 후속 작업에 빠르게 적응할 수 있을 것이다, 더 나아가서는
지도학습보다 더 좋은 성능을 얻을 수 있을 것이다- Label이 없는 대량의 데이터를 활용하여 모델을 학습시키는 방식
(이 때문에 비지도학습에 포함된다)- 다만 학습 방식이 지도학습의 메커니즘(Loss 계산 등)을 그대로 빌려 쓰므로 지도학습과 비지도학습의 가교 역할을 한다고 보기도 함
- 또한 현재는 그 영향력이 커져 self-supervised learning이라는 독립적인 영역으로 굳어지고 있다
- 데이터 내부의 정보를 사용하여 '보조문제(pretext task)'를 모델이 스스로 정의하고, 이 보조 문제를 통해 사전 학습(pre-training)한다
- 레이블이 존재하지 않는 원본 데이터로부터 레이블을 자동 생성하여, 지도 학습에 이용하는 방법 (이 때문에 self지도학습이라고 한다)
- 학습 과정
- 사전 학습 (Pre-training)
먼저, pretext task를 통해 모델을 학습시킨다- 데이터의 본질을 파악하는 눈을 갖게 하는게 목적이다 (스스로 깨우침)
- representation learning 이라고도 한다
(데이터의 유의미한 특징을 추출하는 표현 학습)pretext task의 종류 - 이미지 분야 Computer Vision: Relative Patch Location 위치 맞추기 Jigsaw Puzzle 퍼즐 맞추기 Rotation Prediction 회전 맞추기 Colorization 색칠하기 - 텍스트 분야 NLP: Masked Language Modeling 빈칸 채우기 Next Sentence Predicton 다음 문장 찾기
- 전이 학습 (Transfer Learning)
사전 학습된 모델을 실제 문제(downstream task)에 적용하기 위해 전이학습을 수행- Linear Probing: 가중치는 고정하고 레이블이 있는 데이터셋을 활용해 정확도를 높인다
- 일반적으로 레이블이 있는 작은 데이터셋을 활용
- Fine-tuning: 사전 학습된 모델의 가중치를 고정하지 않고 목적에 맞게 미세 조정한다
- Linear Probing: 가중치는 고정하고 레이블이 있는 데이터셋을 활용해 정확도를 높인다
- 사전 학습 (Pre-training)
- 주요 기법
- Self Prediction (대표 모델 BERT, MAE)
하나의 data sample내에서 한 파트를 통해서 다른 파트를 예측하는 task- Intra-sample prediction이라고도 부름 (데이터.샘플 내부의 관계를 학습)
- context prediction이 이에 해당한다
데이터 내 요소들 사이의 상대적 위치나 문맥적 관계를 맞추는 구체적인 보조 문제
- Contrastive Learning (대표 모델 SimCLR, MoCo)
batch내의 data sample들 사이의 관계를 예측하는 task- Inter-sample prediction으로 보기도 함 (샘플 간의 관계를 학습)
- 데이터의 다양한 변형 버전을 생성(Data Augmentation)하고 이러한 변형들이 원래 데이터와 얼마나 유사한지 판결
- (주요 아이디어) 유사한 데이터 포인터는 가까이 있어야 하고, 다른 데이터 포인트는 멀리 떨어져 있어야 한다
- 단순히 유사도 판결을 넘어,
고차원 데이터를 저차원의 특징 벡터 공간으로 투영하여 그 거리를 조절하는 것이 궁극적인 목적이다
- 단순히 유사도 판결을 넘어,
- 즉, 데이터 증강으로 생긴 다양한 변형들이 하나의 이미지로부터 positive pair(같은 이미지의 다른 뷰)를 추출하는 것 → 데이터의 표현 방식을 추상화(정제)
- negative pair: 의미적으로 무관한 두 데이터 포인트
- Self Prediction (대표 모델 BERT, MAE)
강화학습
Reinforcement Learning
- 행동중의 심리학 이론을 토대로 구현한 알고리즘
- 행동주의: 모든 동물은 학습 능력을 갖추고 있으므로 어떤 행동을 수행했을 때 보상이 있다면 보상받았던 행동의 발생 빈도가 높아진다는 이론
- 구성요소: 환경, 에이전트, 상태, 행동, 보상, 정책
- 환경: 학습을 진행하는 공간 또는 배경
- 에이전트: 환경과 상호작용하는 프로그램 (플레이어, 관측자)
- 상태: 환경에서 에이전트의 상황
- 행동: 주어진 환경의 상태에서 에이전트가 취하는 행동
- 보상: 현재 환경의 상태에서 에이전트가 어떠한 행동을 취했을 때 제공되는 것
- 양의 보상 ← 에이전트는 이를 유발하는 행동을 더 많이 취할 가능성이 높아진다
- 음의 보상
- 정책: 에이전트가 보상을 최대화하기 위해 행동하는 알고리즘을 의미
- 강화학습에서 환경은 마르코프 속성을 갖는다
- 마르코프 결정 과정 MDP: 이산 시간 확률 제어 과정. 시간에 따른 시스템의 상태 변화를 의미
- 마르코프 속성: 과거 상태와 현재 상태가 주어졌을 때 미래 상태는 오직 현재 상태에 의해 결정된다는 것
- 에이전트가 A라는 행동을 하면 환경은 다음 상태와 다음 보상을 에이전트에게 전달한다 (일련의 과정을 상태에 따라 전개하면 이러하다)
- t 시점의 상태: 에이전트가 A라는 행동을 수행 (이때 에이전트는 환경으로부터 t+1시점의 상태와 그때 받는 보상을 전달받음)
- t+1 시점의 상태: t에서 t+1로 상태 전이가 알어남으로써 에이전트는 보상을 받음
- t 시점의 상태: 에이전트가 A라는 행동을 수행 (이때 에이전트는 환경으로부터 t+1시점의 상태와 그때 받는 보상을 전달받음)
- 가치 함수: 어떤 상태에서 정책에 따라 행동할 때 얻게 되는 기대 보상을 의미
- 상태와 행동에 따라 최종적으로 어떤 보상을 제공해 줄지에 대한 예측 함수이다
- 정책 설계를 위한 평가지표이다
- 단순히 당장 받는 보상이 아니라, '앞으로' 최종적으로 받을 점수를 매기는 지표이다
- 상태-행동 가치함수도 있음
- 벨만 최적 방정식(Bellman Optimality Equation)을 적용하며
동적계획법(Dynamic Programming), 몬테카를로 방법(Monte Carlo Method), 모수적 함수(Parameterized function) 등을 사용할 수 있다
- 모델 기반 & 모델 프리
- 모델 기반의 강화학습은 실제로 환경의 설계도가 존재해 예측하며 학습이 가능하다
- 모델 프리의 경우 실제로 환경의 설계도를 구축하기 어려운 상황에서도 학습이 가능하다
대부분의 딥러닝 기반 강화학습(DQN, PPO 등)이 이에 해당한다
언어모델(LLM) 학습: 사전학습과 미세조정
- 사전학습 pre-train
언어 모델은 사전학습 과정에서 자기지도학습을 사용한다- 라벨이 없는 방대한 언어 데이터를 모델이 스스로 보조문제를 정의하고 사전학습 과정을 거친다
- 언어 데이터 자체의 본질을 스스로 학습한다
- 특정 지식을 잘 아는 상태를 만드는 것보다는. '언어라는 시스템의 통계적 확률'을 마스터하는 것이 목표이다
- 미세 조정 fine-tuning
사전학습을 완료한 언어 모델은 특정 목적에 맞게 가중치를 조정하는 fine-tuning 단계에서 지도학습을 사용한다- 사전학습된 모델의 가중치를 목적에 맞는 특정 라벨링 데이터셋을 사용하여 추가로 조정한다
- 왜 언어모델에서 파인튜닝할 때 지도학습을 사용할까?
- 언어모델에서 중요한 것은 사람의 의도를 이해하고 사람처럼 반응하는 것이다
- 즉, 사용자의 명령에 반응하는 체계를 잡는다
- 위의 목적에 따라 말투와 형식을 길들여야 하는데, 이때 보통 언어 모델을 학습시키는 설계자가 원하는 형식이 존재함
- 즉, 원하는 답이 있다.
- 원하는 목적을 이루기 위해 학습을 시킬 때에 정확도와 안정성을 확보할 수 있다는 장점
- 그렇다면, 지도학습의 단점인 다양성이 떨어지는 문제는?
학습 데이터셋의 질과 다양성을 확보한다
(그리고 해당 문제는 과적합이라 볼 수 있는데 보통 파인튜닝 과정에서 과적합이 될 정도로 데이터를 심하게 반복학습하거나 대량의 데이터를 사용하지는 않음.
혹은, Learning Rate를 아주 낮게 설정하거나 일부 층만 학습시키는 등의 장치를 쓸 수 있음.)- Ex. 다양한 프롬프트 구성, 답변 스타일의 다양화 등
- 그렇다면, 지도학습의 단점인 다양성이 떨어지는 문제는?
- 보통 법률 분야나 특정 도메인의 목적을 가진 언어 모델을 파인튜닝할 때 지도학습을 선택한다
- 언어모델에서 중요한 것은 사람의 의도를 이해하고 사람처럼 반응하는 것이다
ChatGPT에 적용된 기법 RLHF
Reinforced Learning from Human Feedback
- SFT 모델이 생성한 답변에 대해 사람의 선호도를 학습시킨 RM 모델이 점수를 매기고, 이 데이터를 기반으로 강화학습을 수행하여 AI를 인간의 의도에 맞게 정렬하는 기술
- Supervised Fine-Tuning, SFT
라벨이 지정된 데이터셋을 이용해 사람처럼 답변하는 모델을 만든다 - 어떤 답이 더 좋은 답인지 판단하는 RM 리워드 모델을 준비한다
- SFT모델의 답변을 보고 사람이 선호도를 매긴 데이터를 바탕으로 학습
- SFT모델을 복제한 PM 모델을 RM 모델로 강화학습 시킨다
- SFT단계를 거친 모델을 초기값으로 사용하여, RM모델의 점수를 잘 받도록 PPO(Proximal Policy Optimization) 알고리즘을 통해 파라미터를 업데이트
- Supervised Fine-Tuning, SFT
- 답변의 질적 우수성과 안정성 및 정렬을 확보하기 위함
- 정리
- 기존 방식의 문제점?
단순 SFT모델은 사람들이 원하는 답변(선호도)이나 안전한 답변을 제대로 구분 하지 못함
Ex. 학습한 데이터에 없는 새로운 유형의 질문이나 복잡한 도덕적 판단이 필요한 상황에서 일관된 성능을 내기 어려움- 인간의 윤리적 가이드라인을 맞춰주는 과정이 필요
- 적은 수의 레이블을 어떻게 학습에 활용했는가?
사람이 직접 피드백을 하나하나 주는 대신에, RM 모델을 통해 강화학습 진행 - 보상을 어떻게 활용했는가?
- RM모델: SFT 모델이 생성한 답변을 평가해 점수(선호도 순위)를 매김
- RM모델이 주는 점수(보상)를 최대화하는 방향으로 PPO모델이 학습됨
- KL Divergence (제약 조건): PPO모델이 보상을 받으려고 너무 이상한 답변을 내놓지 않도록, 원래 SFT 모델의 답변 스타일에서 너무 멀어지지 않게 제동을 거는 장치가 포함
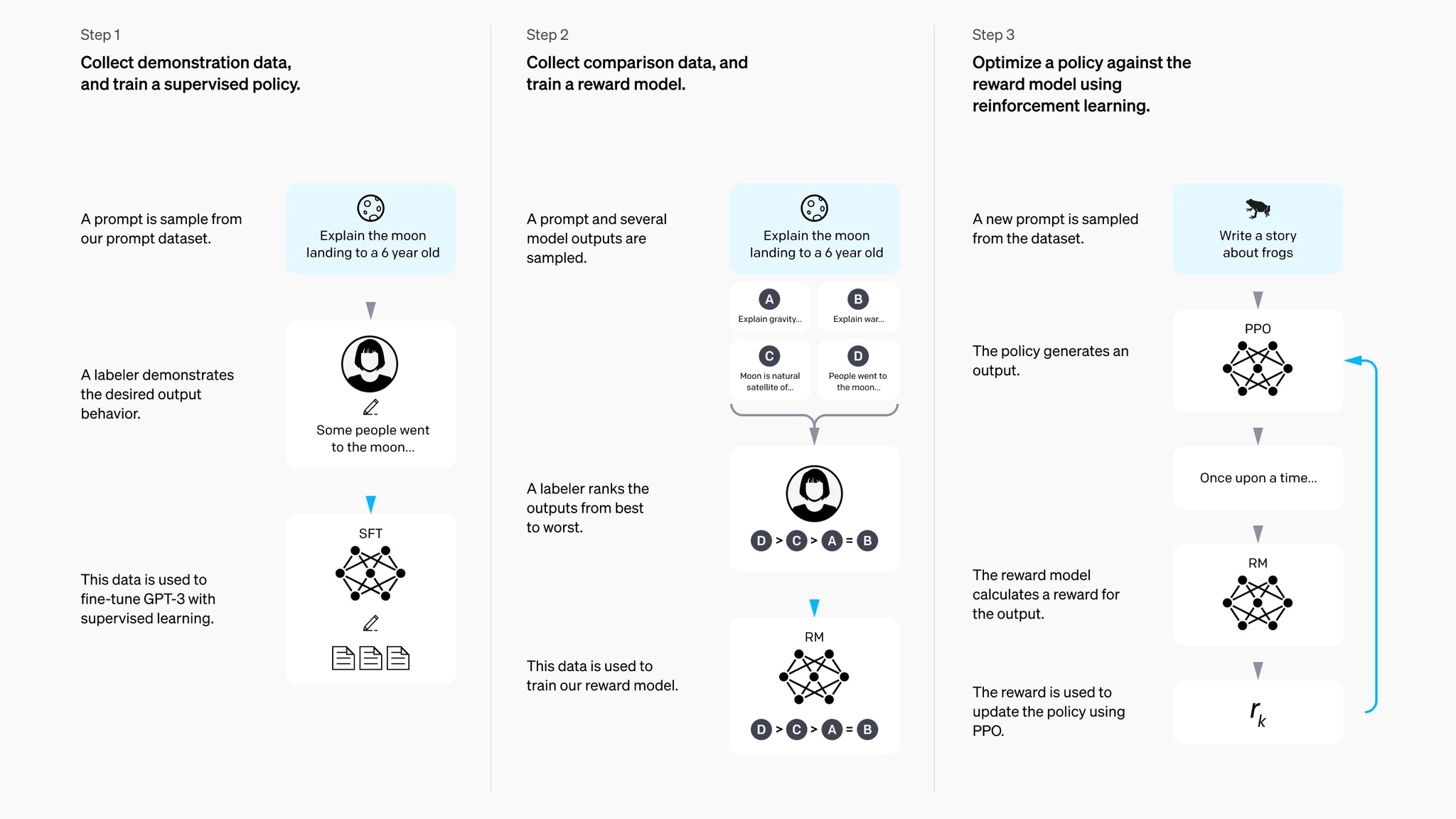
- 기존 방식의 문제점?
머신러닝 아키텍처
머신러닝 시스템의 목적을 달성하기 위한 시스템 간 상호작용, 시스템 디자인, 알고리즘에 대한 제약 및 설계를 의미
- 머신러닝 시스템의 목적은 머신러닝 시스템을 활용해 우수한 제품을 제공하는 것
- 이를 달성하기 위해서는 머신러닝 아키텍처의 각 단계가 최상의 결과와 유의미한 가치를 제공해야함
- 프로세스 및 절차(procedure)를 수립하고 지속적으로 개선해야 한다
- 프로세스에서 발생하는 문제를 최소화하기 위해 프로세스별로 dependency(의존관계)를 확인하고 비정상적인 상태를 감지해 Idempotent(멱등성)를 유지해야 함
- 또한 취약점을 확인하고 문제의 조기발견 후 해결이 중요
→ 프로세스마다 목적, 결과, 행동 및 성공기준을 결정
- 머신러닝 파이프라인의 중심은 제품!!
- 시스템이 개선/변경되더라도 안정적인 기능을 제공해야한다
- 지속적인 통합(Continuous Integration, CI)과 지속적인 서비스 제공(Continuous Delivery, CD)을 가능케 하기위해,
실행가능한 구성요소로 프로세스를 분할한다 - 제품을 안정적으로 구현하고 머신러닝 학습 작업을 자동화하기위해 워크플로를 다단계 프로세스로 분할한다
- 장애지점 격리와 재사용성도 고려된 결정이다
- 머신러닝 파이프라인의 프로세스는 크게 데이터 준비, 모델링, 모델 평가, 모델 배포로 구성되었다
데이터 준비
데이터를 수집하고 그 원시데이터를 학습에 적합하게 준비하는 단계
- 데이터 수집 Data Collection
현재 구축하려는 모델링에 필요한 데이터 형식을 정의하고 데이터를 수집한다- 데이터 레이크(Data Lake)를 구축
: 데이터의 사용 가능성, 개인 정보 포함 여부, 데이터 수집 비용
- 데이터 레이크(Data Lake)를 구축
- 데이터 정제 Data Cleansing
데이터의 품질을 보장하기 위해 오류를 수정하고 누락된 데이터를 채우며 불필요한 데이터를 제거- 정리된 데이터는 일관성과 무결성이 유지되어야 한다
이를 위해 데이터 형식, 데이터 저장 규칙, 측정 단위 등을 설정하고 제한 - 데이터베이스나 데이터 웨어하우스(Data Warehouse)를 구축
- 데이터베이스: RDBMS(PostgreSQL, Oracle 등), NoSQL(Redis, MongoDB 등)
- 데이터 웨어하우스: Hadoop, Hive, Redshift, BigQuery, Snowflake
- 정리된 데이터는 일관성과 무결성이 유지되어야 한다
- 데이터 레이블링
정제된 원시 데이터를 식별하고 데이터 가공 도구를 활용해 하나 이상의 정보를 태깅하는 과정- 분석 및 시각화
- 탐색적 데이터 분석(EDA)을 진행
- 데이터 세트를 분석해 주요한 특성을 탐색하는 접근법
- 레이블링된 데이터 특성 및 분포 등을 분석
- 사실 레이블링 이전에도 레이블링 가이드를 잡기 위한 EDA가 필수적이다
- 시각화
선그래프, 막대그래프, 히스토그램, 산점도 등을 활용해 이상치 식별, 상관관계 및 편향 분석, 가설 수립 및 변경, 데이터 패턴 등을 확인
- 탐색적 데이터 분석(EDA)을 진행
- 데이터 준비과정은 지속적으로 진행되는 프로세스이므로 학습 데이터의 불균형이나 데이터 드리프트가 발생할 수 있다 → 멱등성 유지의 중요성
- data drift: 학습 시점의 데이터 분포와 추론 시점의 데이터 분포가 달라지는 현상
즉, 입력 데이터가 변경(실제 운영 환경에서의 변화)이 일어나, 모델 정확도가 저하되는 현상
- data drift: 학습 시점의 데이터 분포와 추론 시점의 데이터 분포가 달라지는 현상
- 분석 및 시각화
모델링
다양한 알고리즘 기법을 적용해 특정 유형의 패턴을 인식하도록 학습된 시스템을 구축하는 것
- 데이터세트와 가설을 이용해 새로운 데이터에서 특징이나 패턴을 추론하고 해당 데이터에 대한 예측을 수행한다
- 주어진 데이터에서 머신러닝 모델이 사람을 대신해서 의사결정을 내릴 수 있는 시스템으로 구축하는 것이 목표
- 피처 엔지니어링 Feature Engineering
데이터세트에서 머신러닝 모델 학습에 포함될 변수나 특징을 추출하고 변환하는 작업
(현재 구축하려는 머신러닝 시스템에 적합하고 학습되기 쉬운 형태로 데이터를 변환하는 과정이다)- 특징 선택: 학습에 활용할 데이터만 선별
- 특징 샘플링: 선별된 데이터의 분포를 균등 분포로 추출하거나 계층적 샘플링 등으로 추출
- 특징 변환: 샘플링된 데이터를 숫자형 데이터로 변환
- 특징 추출: 유의미한 피처를 뽑아내는 과정
(특징을 더 작은 차원으로 축소하면서 원래 데이터의 속성을 유지하도록 변환) - 특징 구성: 기존 특징을 활용해 새로운 특징을 생성
feature generation이라고도 한다
- 모델 설계 Model Design
현재 구축하려는 시스템에 적합한 알고리즘이나 모델을 설계하고 구현하는 단계- 피처 엔지니어링을 통해 생성된 데이터 중 어떠한 필드를 입력값과 출력값으로 활용할지 선택
- 어떠한 인공신경망 구조(CNN, RNN, ANN 등)를 시스템에 활용할지 설정
- 제약사항(비지니스 요구사항. 응답 속도, 비용 등)에 따라 그대로 사용하거나 기본 구조를 변경해 설계
- 구조 설계가 완료됐다면 비용함수(Cost Function)를 비롯해 하이퍼파라미터 등을 정의하고 모델학습을 진행함
- 모델 학습 Model Training
최적의 모델을 선정하고 학습을 통해 최적화된 모델 매개변수를 찾아내는 과정- 학습 데이터로 매개변수를 갱신하고, 검증 데이터로 과적합을 방지하며 하이퍼파라미터를 튜닝한다
- 피처엔지니어링을 통해 입력된 데이터는 인공 신경망을 지나가면서 값이 변경되는데,
이를 예측값이라 한다 - 예측값과 출력값의 차이가 줄어들 수 있게 모델의 매개변수가 갱신됨
- 출력값은 데이터 레이블링에서 생성된 라벨이다
모델학습 Flow 도식화
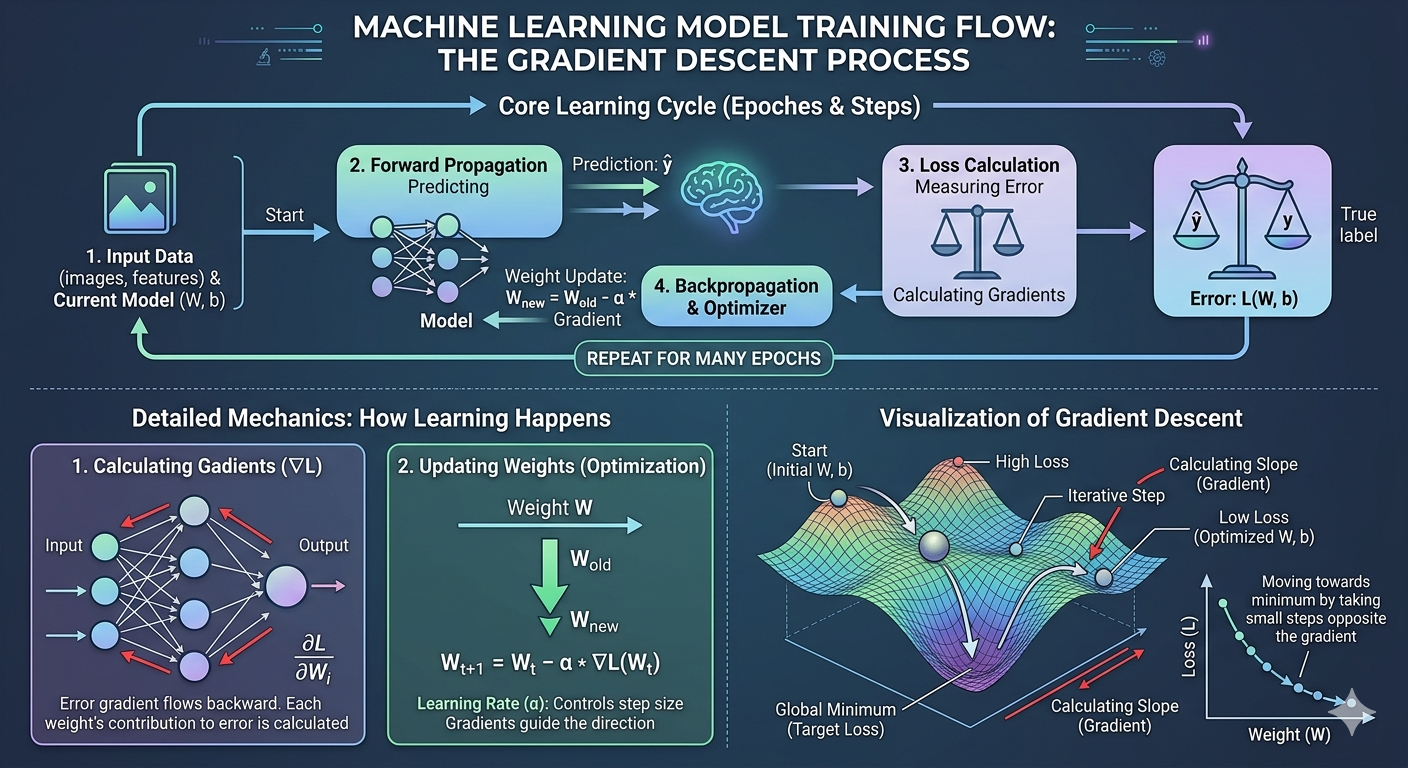
- 모델학습은 오차를 줄여나가는 순환 루프이다
- Gradient Descent 기반 모델은 어떻게 학습할까?
- 현재 가중치 상태에서 손실 함수의 기울기를 계산한다
- 계산된 기울기의 반대 방향으로 이동한다
그래야 기울기가 감소하기 때문 - 학습률: 한 번에 얼마나 크게 이동할지 결정하는 보폭
- 모델이 학습한다는건 어떤 의미?
- 손실함수의 값을 최소화하는 파라미터 조합을 찾는 최적화 과정이다
- 모델이 어떤 부분을 얼마나 수정해야 정답에 가까워질 지를 스스로 깨닫고 내부 설정을 변경하는 것
- 손실함수의 값을 최소화하는 파라미터 조합을 찾는 최적화 과정이다
- 실제 학습이 수행되는건 어떤 단계?
- 위의 flow 도식화 부분에서 가중치 업데이트 (역전파) 부분이 실제 학습이 일어나는 시점이다
- Optimizer가 가중치를 새로 갱신하는 단계
모델 평가
알고리즘 특성이나 비즈니스 목적에 따라 다양하게 존재하며, 평가를 통해 나온 지표로 머신러닝 모델의 성능을 점검하고, 시스템의 신뢰성을 확인할 수 있다
- 유의미한 성능이 나올 때까지 앞선 프로세스들을 반복 수행한다
- 모델 검증 Model Validation
모델을 학습시킨 이후 모델의 성능을 확인하고 서비스 목적에 부합하는지 판단- 모델의 안정성 및 신뢰성을 확인하고 다양한 평가 방식을 적용해 모델의 적합성을 판단한다
- 예기치 못한 오류를 확인하는 과정도 포함됨
- 온라인 검증 방법
프로덕션 환경에서 A/B 테스트(버전 대조실험)를 진행한다- 사용자의 트래픽, 클릭률, 유저 반응 등을 확인할 수 있다
- (이 방법은 서비스 환경에 배포되고 머신러닝 파이프라인이 1회 이상 진행됐을 때 사용가능함)
- 오프라인 검증 방법
모델 학습에 사용되지 않은 데이터로 테스트 데이터의 예측값을 실제값과 비교해 모델의 성능을 확인- 피처 엔지니어링 단계에서 나눈 테스트 데이터로 평가를 진행
- 모델의 성능 향상이나 안정화를 위해 추가로 진행해야 하는 일을 결정하거나 모델 배포 및 서비스화에 대한 의사결정을 한다
- 성능 개선 Performance Improvement
- 데이터 중심 개선
데이터의 수나 특징의 수를 늘려 학습 데이터를 개선- Baseline Model 기준 모델이 어느정도 성능을 보여준다면 데이터나 특징의 증가를 통해 확실하게 성능을 증가시킬 수 있다
- 모델 중심 개선
- 인공 신경망의 구조를 변경하거나 모델 매개변수를 확장해 더 고도화된 예측을 할 수 있게 모델을 변경
- 하이퍼파라미터 최적화를 통해 성능을 개선
학습 횟수나 초깃값 설정을 의미
- 데이터 중심 개선
모델 배포
머신러닝 시스템을 서비스화하거나 상용화하는 단계로 모델 서빙 과정을 의미
- 모델 서빙: 머신러닝 모델의 예측값을 사용자에게 제공하는 것
- 예측값을 제공하는 방법
- 배치 인퍼런스 → 데이터를 가져와서 처리할 전용 서버망(내부 서비스망)에 배포 입력 데이터를 배치로 묶어 한 번에 추론
- 특정 주기마다 여러 데이터를 한 번에 묶어 처리하기 때문에 대규모 요청사항을 수월하게 처리할 수 있음
- 일정 주기마다 처리된 결과는 보통 데이터베이스에 적재해 사용자에게 제공
- 일정 주기마다 처리하므로 실시간으로 예측값이 제공되지는 않는다
- 온라인 인퍼런스 → API 서비스 환경 (클라우드 또는 내부 서버) 클라우드 환경이나 내부 서버 망에서 RESTful API 기반으로 요청이 올 때마다 즉시 예측값을 제공한다
- 실시간성으로 인해 일정 시간 이하의 응답 시간을 보장해야한다
- 순간적으로 얼마나 많은 유저에게 요청이 올 지 모르기 때문에 프로비저닝까지 신경 써야 한다 (오토스케일링)
- 프로비저닝: 필요한 자원을 쓸 수 있도록 미리 준비해두는 것
- 유저에게 즉각 제공해야하기 때문에 모니터링 시스템 구축과 서비스 장애에 대한 즉각 대응이 요구된다
- 에지 인퍼런스 → 로봇, 컴퓨터, 휴대전화와 같은 디바이스에 배포 배치나 온라인과 달리 인프라를 크게 요구하지 않지만 하드웨어에 직접 배포하기 때문에 더 복잡한 버전 관리 방법이 요구된다
- 즉, 중앙 서버 의존도는 낮으나, 개별 기기의 자원 제약이 큼
- 업데이트 시에도 복원 및 백업 시스템 구축, 정교한 모니터링 시스템이 요구된다
- 디바이스가 서로 상이하므로 동일한 기능, 모델, 데이터에 대해서도 예측값이 다를 수 있다 → 모델의 성능을 객관적으로 평가하기 어려움
- 하드웨어의 영향을 받음
- 온라인과 배치의 중간 형태인 하이브리드 관점도 존재한다
배치로 미리 계산해두고, 요청 시 실시간으로 계산을 조합하는 방식
- 배치 인퍼런스 → 데이터를 가져와서 처리할 전용 서버망(내부 서비스망)에 배포 입력 데이터를 배치로 묶어 한 번에 추론
MLOps
Machine Learning Operations
- 머신러닝 모델을 소프트웨어 개발 수명 주기(SDLC)에 통합하는 방법
- 개발자와 운영자가 협업해 애플리케이션의 개발 주기를 단축하고 소프트웨어의 릴리스 속도와 안정성을 높이기 위한 DevOps에서 유래되었다
- MLOps는 머신러닝 모델을 구축하고 학습시키는 데이터 과학자와 머신러닝 모델을 프로덕션 시스템에 통합하고 운영 및 배포 자동화를 적용시키는 데이터 엔지니어 간의 협업을 포함한다
- 주요 목적:
프로덕션 환경에서 머신러닝 모델을 더 쉽게 배포하고 시스템 상태를 모니터링하며 효율적으로 유지 관리하는 것- 지속적인 통합 CI
모델의 코드 변경 사항을 빌드하고 테스트하는 프로세스를 자동화
(ML에서는 코드 및 구성요소만 테스트하고 검증하는것이 아니라, 데이터, 데이터 스키마, 모델도 테스트하고 검증하는 것이다) - 지속적인 서비스 제공 CD
모델의 변경사항을 프로덕션 환경에 배포하는 프로세스를 자동화
(학습된 모델 뿐만 아니라, 모델을 자동으로 재학습하고 배포하는 ML 파이프라인 자체를 배포)- continuous training, CT: 새로운 데이터가 유입될 때 모델을 자동으로 재학습시키는 MLOps만의 고유한 속성
- 프로그래밍형 인프라 IaC
모델의 인프라 구성을 코드로 관리해 자동으로 구축, 관리, 프로비저닝한다 - 지속적인 모니터링
프로덕션 환경에서 발생할 수 있는 문제와 배포된 머신러닝 모델의 성능을 모니터링 - 데이터 관리
모델을 학습하는 데 사용되는 데이터를 관리하고 테스트 데이터세트에 대한 모델의 성능을 검증
- 지속적인 통합 CI
- MLOps 아키텍처
- 참고링크
- 머신러닝 아키텍처를 포함한 운영 및 배포 자동화를 포함
- 데이터 레이크에 적재된 원시 데이터셋을 활용해 모델을 구축하며 배포된 모델의 성능과 상태를 지속적으로 모델링하고 필요에 따라 업데이트
- 실제 환경/서비스에 반영된 모델은 모델 평가 결과와 다를 수 있다
- 데이터 분석을 통해 유저의 반응을 확인하고 추가적인 모델 학습이나 개선이 이뤄짐
- 온라인 인퍼런스 환경으로 배포한 경우,
서비스 장애에 대해 즉갖거으로 대응할 수 있는 환경을 갖춰야 한다
- 피처스토어
- 모델에 사용된 특성이나 속성 또는 결괏값은 새로운 모델을 구축할 때 내부 조직에서 활용할 수 있다
- 피처 엔지니어링의 결과물이 여기에 저장됨
- MLOps를 적용하려면 조직의 규모가 비교적커야하고 머신러닝 시스템을 활발하게 사용하고 있어야 한다
- 구현하기위해서는 인프라 및 자동화 구축에 상당한 투자가 필요하며 데이터 과학자와 엔지니어 간의 협업을 필요로 한다 (또한, 둘의 기술 격차가 없어야 함)
