TIL: PyTorch Tensors, Backpropagation, Loss Functions, Optimizers & Activation Functions
TIL
오늘의 학습목표
- 텐서의 연산과 데이터 종류에 따른 텐서의 형태를 이해한다
- 오차역전파법을 이해하고 체인룰을 통한 역전파 과정을 계산그래프로 설명할 수 있다
- 모델의 학습 과정을 이해하고 코드로 구현한다
- 활성화함수, 손실, 옵티마이저의 종류와 특성을 이해한다
이 포스트의 전반적인 개념은 주로 해당 도서의 3장을 참조하고 있습니다.
[파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습] - 윤대희,김동화,손종민,진현두0.들어가며 - 키워드 정리
-
손실함수
- 손실(Loss) : 모델이 예측한 값과 실제 값의 차이
- 손실함수(loss function) : 예측값과 실제값 사이의 오차 관계를 표현하는 함수 (수치화)
-
미분
- 접선의 기울기
- 각 파라미터들이 최종 출력 값에 주는 영향을 파악하기 위해서 사용하는 방법
-
편미분
계수(혹은 파라미터, 에서의 n). loss를 최소화하기 위해 조절할 수 있는 변수가 2개 이상이라고 봤을 때, k의 값을 어떻게 조정해야 할 지 모름
이 경우에, 각각의 Y1, Y2, Y3 등등에 대해 편미분을 활용하여 loss(Y)를 최소화하는 각각의 값을 구함.
- x는 고정시키고 y값만 조정하는 경우 → y에 대한 편미분 (x에 대한 경우도 마찬가지)
그래서, 각각의 항을 편미분한 값을 x’, y’ 이라고 하고 하나의 벡터로 정의
[ x’, y’ ] → 이를 gradient vector라고 한다
그래서 저 gradient vector를 이용하면 어느 방향으로 이동할 지가 정해진다
-
gradient
- 어느 방향으로 가야 loss가 줄어드는지, 빨라지는지를 나타내는 기울기 벡터 (방향값을 가진다)
-
gradient descent
- 경사 하강법: 기울기(오차)가 줄어드는 방향으로 진행 (최종 목표지점은 기울기가 0)
-
chain rule
- 전제: 가장 앞에 있는 입력값 x 에 변화가 생겼을 때(움직였을 때), 중간에 여러 값들이 있고, 가장 마지막 출력값 y 는 어떤 변화를 갖는지(움직이게 되는지) 알 수 없다
- 그래서 x부터 y에 이르기까지의 일련의 과정을 중첩된 함수로 보면,
- 합성 함수의 미분 (chain rule)에 의해서 x가 y에게 주는 영향력을 계산할 수 있다
-
역전파
- 학습의 단계
- 앞에 있던 입력값들, 파라미터들에게 최종값에게 각자가 얼마나 영향을 미쳤는지를 전달해주는 단계
-
순전파
- 각각의 계수들이 어떤 활성화 함수를 거쳐서 최종 loss를 구하게 되었는지까지의 상세한 과정을 열거
-
optimizer
- 역전파 과정을 통해 알게된 영향력 등 정보를 토대로 각 파라미터들을 loss를 최소화하는 방향으로 업데이트 하는 과정
-
활성화함수
- 입력층에서 출력층에 이르기까지 사이에 있는 은닉층에 적용됨
- 즉, 이전 층의 가중치 합을 받아서 다음층으로 전달할 출력 값을 결정하는 비선형 함수
선형 함수 → 비선형 함수 (데이터의 표현력 증대 역할)
텐서 Tensor
넘파이 라이브러리의 ndarray 클래스와 유사한 구조로 배열이나 행렬과 유사한 파이토치의 기본 자료 구조(자료형)
- 파이토치에서는 텐서를 사용해 모델의 입출력뿐만 아니라 모델의 매개변수를 부호화(Encode)하고 GPU를 활용해 연산을 가속화할 수 있다
- 파이토치는 GPU 가속을 적용할 수 있으므로 CPU 텐서와 GPU 텐서로 나눠지고 각각의 텐서를 상호변환하거나 GPU 사용여부를 설정한다
(넘파이와 파이토치의 차이점) - 공통점은 수학계산, 선형 대수 연산을 비롯해 전치, 인덱싱, 슬라이싱, 임의 샘플링 등 다양한 텐서연산을 진행한다
- 파이토치는 GPU 가속을 적용할 수 있으므로 CPU 텐서와 GPU 텐서로 나눠지고 각각의 텐서를 상호변환하거나 GPU 사용여부를 설정한다
- N차원 텐서 시각화
- 0차원 텐서: 스칼라
크기만 있는 물리량으로, 모든 값의 기본형태 - 1차원: 벡터 []
- 파이썬의1차원 리스트와 비슷.
- 스칼라 값들을 하나로 묶은 형태로 간주.
- (N,) 의 차원을 갖는다
- 2차원: 행렬
- 회색조 이미지를 표현하거나 좌표계로 활용
- 벡터값들을 하나로 묶은 형태로 간주.
- (N,M)으로 표현
- 3차원 이상: 배열
- 각각의 차원을 구별하기 위해 N차원 배열 또는 N차원 텐서로 표현
- 이미지를 표현하기에 가장 적합한 형태 (3차원 텐서)
- 행렬을 세 개 생성해 겹쳐 놓은 구조로 볼 수 있다
각각 R, G, B로 표현 - 행렬값을 하나로 묶은 형태로 간주.
- (N,M,K)로 표현
- 이미지의 경우 (C, H, W)로 표현
C: 채널 H: height, W: width
- 이미지의 경우 (C, H, W)로 표현
- 행렬을 세 개 생성해 겹쳐 놓은 구조로 볼 수 있다
- 4차원 텐서
- 3차원 배열들을 하나로 묶은 형태.
이미지 여러 개의 묶음으로 볼 수 있다- (N,C,H,W)로 표현
N은 이미지의 개수를 의미
- (N,C,H,W)로 표현
- 파이토치를 통해 이미지 데이터를 학습시킬 때 주로 사용
- 3차원 배열들을 하나로 묶은 형태.
- 0차원 텐서: 스칼라
텐서 생성
torch.tensor() 입력된 데이터를 복사해 텐서로 변환하는 함수
torch.Tensor() 텐서의 기본형으로 텐서 인스턴스를 생성하는 클래스
- 소문자 tensor는 값이 무조건 존재해야 하고,
- 대문자 Tensor는 값이 없는 경우 비어 있는 텐서를 생성한다- 실습

- torch.tensor()는 자동으로 자료형을 할당하므로 입력되니 데이터 형식을 참조해 Int 형식으로 할당됨
- torch.Tensor()는 기본 유형이 Float이므로 정수형을 할당하더라도 float 형태로 변환해서 생성한다
- LongTensor(), FloatTensor 외에도 Int, Double, Boolean 형식이 있다
텐서 속성
형태 shape, 자료형 dtype, 장치 device가 존재
- 형태와 자료형은 넘파이 배열에서 사용하는 형태와 유사
- 형태는 텐서의 차원
- 자료형은 텐서에 할당된 데이터 형식을 의미
- 장치는 GPU 가속 여부를 의미
- 실습

- rand()는 0과 1 사이의 무작위 숫자를 균등분포로 생성하는 함수
- 매개변수로 사용한 1,2는 생성하려는 텐서의 형태를 의미
- float32의 형식을 가지며, GPU 가속 여부를 설정하지 않았기에 cpu 장치를 사용해 연산한다
- rand()는 0과 1 사이의 무작위 숫자를 균등분포로 생성하는 함수
차원 변환
가장 많이 사용되는 메서드 중 하나로 머신러닝 연산 과정이나 입출력 변환 등에 많이 활용
- 실습

- 텐서.reshape()
자료형 설정
텐서에 있어서 자료형은 가장 중요한 요소이다
- 텐서의 자료형 설정도 기존 넘파이의 자료형 설정 방식과 동일하나 선언 방식에 있어서 차이점이 존재
- 실습

- 텐서의 자료형 설정에 입력되는 인수는
torch.*형태로 할당- torch.float이 아닌 그냥 float을 할당해도 오류 없이 작동하지만,
자료형 관점에서 두 데이터는 다른 자료형을 갖는다 - torch.float은 32비트 부동 소수점 형식
float은 64비트 부동 소수점- float은 더 큰 범위의 숫자를 저장하게 되고, 이로 인해 더 많은 메모리를 필요로 한다
즉, 일부 학습 과정에서 더 많은 자원을 필요로 하게 된다
- float은 더 큰 범위의 숫자를 저장하게 되고, 이로 인해 더 많은 메모리를 필요로 한다
- 그러니, 텐서를 선언할 때는 가능한 한
tensor.*형태로 정확한 자료형을 할당하자!!
- torch.float이 아닌 그냥 float을 할당해도 오류 없이 작동하지만,
- 텐서의 자료형 설정에 입력되는 인수는
장치 설정
GPU 학습에서 가장 중요한 설정
- 장치 설정을 정확하게 할당하지 않으면 실행 오류 runtime error가 발생하거나 CPU 연산이 되어 학습하는 데 오랜 시간이 소요된다
- 실습
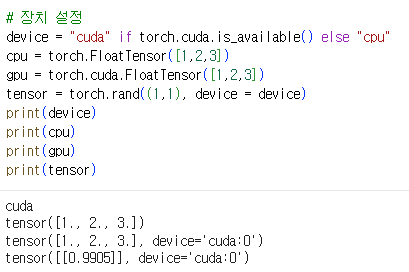
- 장치 속성 변수를 선언해 현재 소스 코드에 활용되는 장치를 통일시킬 수 있다
torch.cuda.is_availabe()CUDA 사용 여부를 확인
- Tensor 클래스의 경우 device 매개변수가 존재하지만, CUDA용 클래스가 별도로 존재하므로
torch.cuda.Tensor클래스를 사용한다- 특정 데이터에서 복사해 적용하는 경우 device 매개변수에 장치값을 할당
- 장치 속성 변수를 선언해 현재 소스 코드에 활용되는 장치를 통일시킬 수 있다
- device 속성에는 cpu, cuda, mps, mkldnn, opengl, opencl, ideep, hip, msnpu, xla 등이 있다
- CUDA: NVIDIA가 개발한 병렬 컴퓨팅 플랫폼 및 프로그래밍 모델
- 애플 실리콘이 탑재된 맥에서는 CUDA 가속이 아닌 MPS를 통한 GPU 가속을 적용
device = "mps" if torch.backends.mps.is_available() and torch.backends.mps.is_built() else "cpu"
장치 변환
cpu장치를 사용하는 텐서와 gpu 장치를 사용하는 텐서는 상호 간 연산이 불가능
- cpu장치를 사용하는 텐서와 넘파이 배열 간 연산은 가능
- gpu장치를 사용하는 텐서와 넘파이 배열 간 연산은 불가능
- 넘파이 배열 데이터를 학습에 활용하려면 gpu 장치로 변환해야한다
- 실습

- 장치 간 상호 변환은 cuda와 cpu 메서드를 사용
cuda()cpu장치로 선언된 값을 gpu로 변환cpu()gpu장치로 선언된 값을 cpu로 변환- 이외에도
to()로 장치를 간단하게 변환할 수 있다
to 메서드는 파이토치에서 지원하는 모든 장치 간의 텐서 변환을 수행- 가령 맥에서는 cuda 메서드가 지원되지 않으므로 to 메서드를 활용해 MPS 장치로 변환할 수 있다
넘파이 배열의 텐서 전환
대부분의 행렬 연산 라이브러리는 넘파이 배열을 사용
- 넘파이나 다른 라이브러리의 데이터를 파이토치에 활용하려면 텐서 형식으로 변환해야 한다
- 실습

- 앞에서 배운
torch.tensor와torch.Tensor에 넘파이 배열을 그대로 입력하는 방법 from_numpy()메서드를 통해 변환하는 방법
- 앞에서 배운
텐서의 넘파이 배열 변환
추론된 결과를 후처리하거나 결괏값을 활용할 때 주로 사용
- 텐서는 기존 데이터 형식과 다르게 학습을 위한 데이터 형식으로 모든 연산을 추적해 기록
- 이 기록을 통해 역전파 등과 같은 연산이 진행돼 모델 학습이 이뤄짐
- 즉, 텐서의 데이터가 어떻게 변경되고 관리됐는지 기록됨
- 실습

detach()현재 연산 그래프에서 분리된 새로운 텐서를 반환- 텐서는 모든 연산이 기록되기 때문
- 새로운 텐서로 생성한 다음,
numpy()메서드를 통해 변환- gpu장치라면 cpu장치로 변환 후 넘파이 배열로 변환해야 한다
- 텐서는 넘파이 배열과 유사하지만, 모델 학습에 특화된 데이터이므로
정확한 데이터 형식을 취해야 한다!- 텐서 유형 정리 (p.54참조)
가설 Hypothesis
두 개 이상의 변수의 관계를 검증 가능한 형태로 기술하여 변수 간의 관계를 예측하는 것을 의미
- 어떠한 현상에 대해 이론적인 근거를 토대로 통계적 모형을 구축
- 데이터를 수집해 해당 현상에 대한 데이터의 정확한 특성을 식별해 검증
- 크게 연구가설과 귀무가설, 대립가설로 나눌 수 있다
- Research Hypothesis
연구자가 검증하려는 가설로, 귀무가설을 부정하는 것으로 설정한 가설을 증명하려는 가설 - Null Hypothesis
통계학에서 처음부터 버릴 것을 예상하는 가설- 변수 간 차이나 관계가 없음을 통계학적으로 증명
- Alternative Hypothesis
귀무가설과 반대되는 가설. 귀무가설이 거짓이라면 대안으로 참이 되는 가설- 즉, 연구가설과 동일하다고 볼 수 있음
- Research Hypothesis
- 결국 정리하면, 연구가설이 주인공이고 귀무가설과 대리가설은 통계적 가설 검정을 위한 준비물이다
Ex.- 연구가설: 나의 기상 시간이 평균적으로 오전 7시가 아니다
- 귀무가설: t = 7
- 대립가설 (1): t != 7
- 대립가설 (2): t < 7
- 대립가설 (3): t < 7
머신러닝에서의 가설
통계적 가설 검정이다
- 데이터와 변수 간의 관계가 있는지 확률론적으로 설명하게 된다
즉, 머신러닝에서의 가설은 독립변수X와 종속변수Y를 가장 잘 매핑시킬 수 있는 기능을 학습하기 위해 사용한다 - 가설은 '단일 가설'과 '가설 집합'으로 표현할 수 있다
- 단일 가설: 입력을 출력에 매핑하고 평가하고 예측하는 데 사용할 수 있는 단일 시스템
- 로 표현
- 가설 집합: 출력에 입력을 매핑하기 위한 가설 공간.
모든 가설을 의미- 로 표현
- 단일 가설: 입력을 출력에 매핑하고 평가하고 예측하는 데 사용할 수 있는 단일 시스템
- 선형회귀의 경우를 생각하면 데이터들을 표시한 점들을 잘 표현하기 위해 그린 선이 가설이라고 볼 수 있다
- H(x): 가설
- W: weight 가중치
- b: bias 편향
- 마지막으로 학습이 된 결과를 모델이라 부르며, 이 모델을 통해 새로운 입력에 대한 결과값을 예측한다
- 추세선(Trend Line) 같은 단순한 방식도 통계적 머신러닝 방법이다
통계적 가설 검정 사례
t-검정(t-test) 이 대표적이다
- 쌍체 t-검정과 비쌍체 t-검정으로 더 세분화할 수 있다
- paird t-test: 동일한 항목 또는 그룹을 두 번 테스트할 때 사용
- 동일 집단에 대한 약물 치료 전후 효과 검정
- 동일 집단에 대한 학습 방법 전후 효과 검정
- unpaired t-test: 등분산성(homoskedasticity)을 만족하는 두 개의 독립적인 그룹 간의 평균을 비교하는 데 사용
- 제약연구에서 서로 다른 두 개의 독립적인 집단(실험군,대조군) 간에 유의미한 차이가 있는지 조사
- 서울과 인천의 무작위로 선택된 참가자 1,000명의 평균 통근 거리 조사
- paird t-test: 동일한 항목 또는 그룹을 두 번 테스트할 때 사용
- 쌍체와 비쌍체 모두 가설은 동일하다
- 귀무가설(): 두 모집단의 평균 사이에 유의한 차이가 없다
- 대립가설(): 두 모집단의 평균 사이에 유의한 차이가 있다
- 머신러닝의 통계적 가설을 적용한다면 비쌍체 t-검정을 사용해야한다
- 독립변수와 종속변수. 변수들의 샘플 데이터는 독립항등분포를 따른다
(머신러닝의 대전제) - 즉, 독립적인 그룹 간의 평균을 비교하는 것
- 독립변수와 종속변수. 변수들의 샘플 데이터는 독립항등분포를 따른다
- 실습(성별에 따른 키 차이 검정)
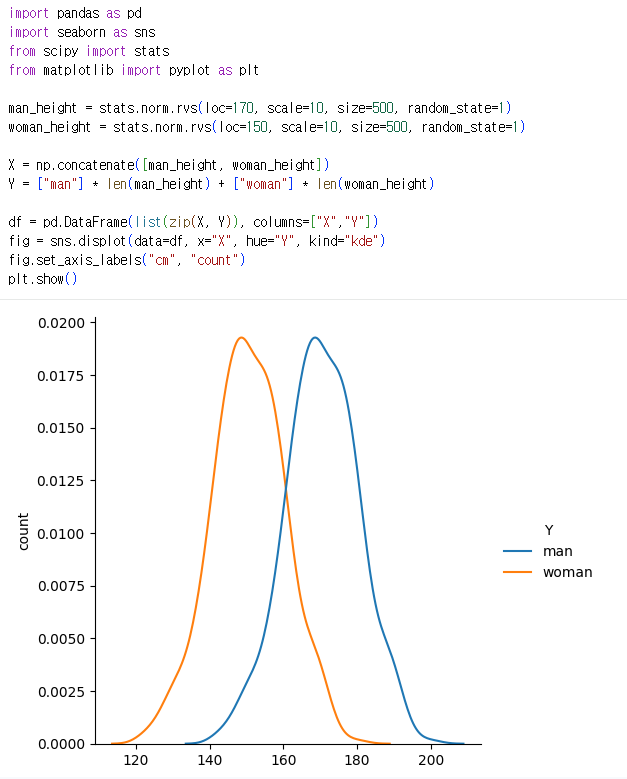
stats.norm.rvs는 특정 평균(loc)와 표준편차(scale)를 따르는 분포에서 데이터를 샘플링하는 함수- 남녀 각각 총 500개의 데이터를 샘플링함
- 데이터 합치기 및 구조화
X = np.concatenate()500개의 남자 키와 여자키를 일려로 이어 붙여 총 1000개의 숫자 리스트를 생성
Y = ...앞의 500개는 'man', 뒤의 500개는 'woman'이라는 라벨을 붙여줌 - 결과해석
- 남성의 평균 키가 여성의 평균 키보다 높다
- 실습2 (비쌍체 t-검정으로 확인하기)

- 성별 차이에 대한 유의미성을 판단하기 위해 통계량 또는 유의 확률을 확인
유의 확률: 통계적 가설 검정에서 귀무가설이 참이라는 전제하에, 관찰된 데이터(또는 더 극단적인 데이터)가 우연히 발생할 확률- 통계량이 크고 유의확률이 작다면 귀무가설이 참일 확률이 낮다
- 귀무가설:
- 대립가설:
- 일반적으로 유의 확률이 0.05보다 작으며 * 표기로 유의하다고 간주
- 유의 확률이 0.001보다 작으면 ** 표기로 더 많이 유의하다고 판단
- 위의 경우, 유의 확률이 매우 작으므로 사람의 키가 성별을 구분하는 데 매우 유의미한 변수라는 것으로 확인됨
- 성별 차이에 대한 유의미성을 판단하기 위해 통계량 또는 유의 확률을 확인
손실 함수 Loss Function
단일 샘플의 실제값과 예측값의 차이가 발생했을 때 오차가 얼마인지 계산하는 함수
- 인공 신경망은 실제값과 예측값을 통해 계산된 오찻값을 최소화해 정확도를 높이는 방법으로 학습이 진행됨
- 이때 오차를 계산하는데, 손실함수를 사용
- 목적함수, 비용함수 라고 부르기도 한다
- Objective Function
함숫값의 결과를 최댓값 또는 최솟값으로 최적화하는 함수 - Cost Function
전체 데이터에 대한 오차를 계산하는 함수
손실함수 ⊂ 비용함수 ⊂ 목적함수
- Objective Function
- 가설이 실젯값을 얼마나 정확하게 표현하는 지 계산하는데 손실함수를 이용한다
- 어떤 손실함수를 언제 써야할까?
- 기본적으로 풀고자하는 문제에 따라 적절히 선택해야 한다
- 회귀문제: MSE, MAE
- 분류문제: BCE, CE
loss와 cost
- loss: 데이터 포인트 하나(또는 배치 하나)에 대한 오차
- cost: 데이터 전체에 대한 오차
제곱 오차, 오차 제곱합, 평균 제곱 오차
연속형 변수에 사용되는 손실함수이다
- Squared Error, SE
실젯값에서 예측값을 뺀 값의 제곱- 제곱 오차는 오차를 제곱하기 때문에 오차의 방향은 알 수 없다 (음인지, 양인지)
하지만, 오차에선는 방향보다는 크기가 중요하므로 제곱을 하는 것 - 절댓값을 사용하지 않는 이유?
제곱을 적용하면 오차가 큰 값이 더 두드러지게 확대되는 효과가 있어 오차의 간극을 빠르게 확인할 수 있다
- 제곱 오차는 오차를 제곱하기 때문에 오차의 방향은 알 수 없다 (음인지, 양인지)
- Sum of Squared for Error, SSE
제곱오차를 모두 더한 값- 제곱 오차는 각 데이터의 오차를 의미하므로 가설(모델 자체)에 대해서는 알기 어렵다
- 그래서, SSE는 제곱 오차를 다 더해 하나의 값으로 만들어 가설이나 모델을 평가
- Mean Squared Error, MSE
오차 제곱합에서 평균을 취하는 방법- SSE와 의미로는 큰 차이가 없지만,
SSE는 데이터가 많아질수록 커지므로 오차가 큰 것인지, 데이터가 많은 것인지 판단하기 어려움 - 가설의 품질을 측정할 수 있다
- 오차가 0에 가까워질수록 높은 품질
- 회귀분석에서 많이 사용되는 손실 함수
- 최대 신호 대 잡음비(Peak Signal-to-noise ratio, PSNR)를 계산할때도 사용
- RMSE
- SSE와 의미로는 큰 차이가 없지만,
교차 엔트로피 Cross-Entropy
이산형 변수에 사용되는 손실함수이다
- 실젯값의 확률분포(p)와 예측값의 확률분포(q) 차이를 계산
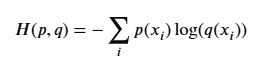
- 예시 (고양이, 호랑이, 개를 분류)
- 고양이 이미지가 모델에 입력
- 각각 예측 확률 (0.6, 0.3, 0.1)
- 실젯값 (1, 0, 0)
- CE값은 0.5108
계산 과정을 보면 실젯값이 0인 호랑이,개에 대해서는 연산이 되지않음.
- 틀렸을 경우 패널티가 크다
최적화 Optimization
목적 함수의 결괏값을 최적화하는 변수를 찾는 알고리즘
-
머신러닝은 손실 함수를 활용해 최적의 해법이나 변수를 찾는 것이 목표
- 손실 함수의 값이 최소가 되는 변수를 찾는다면 새로운 데이터에 대해 더 정교한 예측이 가능
-
최적화 알고리즘은 실제값과 예측값의 차이를 계산해 오차를 최소로 줄일 수 있는 가중치와 편향을 계산
-
가중치와 오차의 그래프에서 기울기(gradient)가 0에 가까워질 때 최적의 가중치를 갖는다
최적의 가중치와 편향을 갖는 가설은 오찻값이 0에 가까운 함수가 된다 = 가중치와 오차에 대한 도함수의 변화량이 0에 가깝다 = 가중치와 오차에 대한 그래프의 극값이 가설을 가장 잘 표현하는 가중치와 오차가 된다
경사 하강법 Gradient Descent
함수의 기울기가 낮은 곳으로 계속 이동시켜 극값에 도달할 때까지 반복하는 알고리즘
- 함수의 기울기가 가장 낮은 곳에 도달할 때 최적의 해를 갖게 된다
그래서, 경사 하강법을 활용해 가중치를 갱신한다 - 가중치 갱신 방법 (뒤에 나오는 수식을 이해하면 충분하다)
- 이외에도 최적화 알고리즘에는 모멘텀(Momentum), Adagrad(Adaptive Gradient), Adam(Adaptive Moment Estimation) 등이 있다
Optimizer 수식 해석
- w(t+1) 새로 업데이트된 가중치
- w(t) 현재 가중치
- **η** (에타) : 학습률 learning rate
- ∂L/∂w : 기울기- loss값을 줄여나가기 위해 learning rate와 미분값(기울기)를 곱한 값을 현재 가중치에서 빼준 값으로 새로운 가중치를 업데이트한다
- learning rate는 한번 가중치를 업데이트할 때 얼마나 이동할 지. 보폭값을 조절해주기 위한 파라미터 (optimizer에 의해 변경된다)
데이터세트와 데이터로더
배치학습을 깔끔하고 효율적으로 하기 위한 규격화된 도구이다
- 데이터세트: 데이터의 집합
입력값과 결괏값의 정보를 제공하건나 일련의 데이터 묶음을 제공- 구조는 일반적으로 DB의 Table과 같은 형태
- 제공되는 데이터의 구조나 패턴은 매우 다양
전처리 단계가 필요한 경우가 있다 - 데이터를 변형하고 매핑하는 코드(전처리과정)를 학습 과정에 직접 반영하면 모듈화(Modularization), 재사용성(Reusable), 가독성(Readability) 등을 떨어뜨리는 주요 원인이 된다
- 이런 현상을 방지하고 코드를 구조적으로 설계할 수 있도록 데이터세트와 데이터로더를 사용하는 것!
Dataset
- 학습에 필요한 데이터 샘플을 정제하고 정답을 저장하는 기능을 제공
- 앞선 선형 변환 함수, 오차함수처럼 클래스 형태로 제공된다
- 초기화 메서드
__init - 호출 메서드
__getitem__ - 길이 반환 메서드
__len__
를 재정의하여 활용
- 초기화 메서드
- 코드

- 초기화 메서드: 입력된 데이터의 전처리 과정을 수행
학습에 사용될 데이터를 선언하고, 학습에 필요한 형태로 변형하는 과정을 진행 - 호출 메서드: 학습을 진행할 때 사용되는 하나의 행을 불러오는 과정
입력된 색인(Index)에 해당하는 데이터 샘플을 반환 - 길이 반환 메서드: 학습에 사용된 전체 데이터세트의 개수를 반환
- 초기화 메서드: 입력된 데이터의 전처리 과정을 수행
- 모델학습에서 임의의 데이터세트를 구성할 때 파이토치에서 지원하는 데이터세트 클래스를 상속받아 사용
DataLoader
데이터세트에 저장된 데이터를 어떠한 방식으로 불러와 활용할지 정의
- 배치 크기(batch_size), 데이터 순서 변경(shuffle), 데이터 로드 프로세스 수(num_workers) 등의 기능을 제공
- 배치 크기는 학습에 사용되는 데이터의 개수가 너무 많아 한 번의 에폭에서 모든 데이터를 메모리에 올릴 수 없을 때 데이터를 나누는 역할
- 모든 배치를 대상으로 학습을 완료하면 한 번의 에폭이 완료됨
1000개의 데이터 샘플에서 batch_size=100 이면 10번의 배치가 완료될 때 1번의 에폭이 진행된 것
- 모든 배치를 대상으로 학습을 완료하면 한 번의 에폭이 완료됨
- 데이터 순서 변경은 모델이 데이터 간의 관계가 아닌 데이터의 순서로 학습되는 것을 방지하고자 수행
- 행의 순서를 변경하는 개념
- 데이터 로드 프로세스 수는 데이터를 불러올 때 사용할 프로세스의 개수
- 데이터를 불러오는 데 시간이 오래 소요되는 것을 최소화
- 배치 크기는 학습에 사용되는 데이터의 개수가 너무 많아 한 번의 에폭에서 모든 데이터를 메모리에 올릴 수 없을 때 데이터를 나누는 역할
모델/데이터세트 분리
파이토치에서 모델은 인공 신경망 모듈을 활용해 구현
- 모델은 데이터에 대한 연산을 수행하는 계층을 정의하고, 순방향 연산을 수행
- 클래스 구조를 활용해 복잡한 구조의 인공 신경망을 모듈화해 빠르게 구축. 관리가 쉽다
- 모델 구현은 신경망 패키지의 모듈 클래스를 활용
- 새로운 모델 클래스를 생성 시, 모듈 클래스를 상속받아 임의의 서브 클래스를 생성
- 모듈 클래스는 다른 모듈 클래스를 포함할 수 있어 트리구조로 중첩이 가능하다
모듈 클래스
- 초기화 메서드
__init__과 순방향 메서드forward를 재정의하여 활용
- 초기화 메서드: 신경망에 사용할 계층을 초기화
- super함수로 모듈 클래스의 속성을 초기화
super함수로 부모 클래스를 초기화하면 서브 클래스인 모델에서 부모 클래스 속성을 사용할 수 있게 해준다 - 학습에 사용되는 계층을 초기화 메서드에 선언
self.conv1,self.conv2인스턴스가 모델의 매개변수
- super함수로 모듈 클래스의 속성을 초기화
- 순방향 메서드: 모델이 어떤 구조를 갖게 될지를 정의
- 모델 매개변수를 활용해 신경망 구조를 설계
- 모듈 클래스의 순간 호출 메서드
__call__이 순방향 메서드를 실행
(모듈 클래스를 통해 모델을 정의해 모델 객체를 호출하는 순간 순방향 메서드가 실행됨)
- 초기화 메서드: 신경망에 사용할 계층을 초기화
- 초기화 메서드에서 super함수로 부모 클래스를 초기화해서 역방향 연산을 정의하지 않아도
파이토치의 자동 미분 기능인 autograd에서 계산해준다
모델 평가
- 테스트 데이터세트나 임의의 값으로 모델을 확인하거나 평가할 때는
기울기 계산을 비활성화하는 no_grad 클래스를 활용한다- 자동 미분 기능을 사용하지 않도록 설정해 메모리 사용량을 줄여 추론에 적합한 상태로 변경
- 모델을 평가모드로 변경
eval()- 평가모드로 변경하지 않으면 일관성 없는 추론 결과를 반환하므로 반드시 선언해야 한다
- 평가 단계에서 모델이 테스트 데이터에 대해 좋은 성능을 보인 경우, 해당 모델을 저장했다가 다시 활용할 수 있다
데이터세트 분리
머신러닝에서 사용되는 전체 데이터세트(Original Dataset)는 두가지 또는 세가지로 나눌 수 있다
- 훈련용 데이터, 테스트 데이터
- 훈련용 데이터, 검증용 데이터, 테스트 데이터
- training data
학습하는 데 사용 - validation data
학습이 완료된 모델을 검증- 주로 구조가 다른 모델의 성능 비교를 위해 사용하는 데이터세트
(모델은 계층이 다르거나 하이퍼파라미터에 따라 학습 결과가 달라짐)
- 주로 구조가 다른 모델의 성능 비교를 위해 사용하는 데이터세트
- testing data
검증용 데이터를 통해 결정된 성능이 가장 우수한 모델을 최종 테스트하기 위한 목적- 최종 모델의 성능을 평가
- training data
모델 저장 및 불러오기
파이토치 모델은 직렬화(serialize)와 역직렬화(Deserialize)를 통해 객체를 저장하고 불러올 수 있다
- 모델 저장
- 파이썬이 피클(Pickle)을 활용해 파이썬 객체 구조를 binary protocols로 직렬화
- 모델에 사용된 텐서나 매개변수를 저장
- 모델 불러오기
- 저장된 객체 파일을 역직렬화해 현재 프로세스의 메모리에 업로드
- 주로 모델 학습이 모두 완료된 이후에 저장하거나,
특정 에폭이 끝날 때마다 저장한다- 모델 파일의 확장자는 주로
.pt나.pth로 저장- .pt는 PyTorch 모델 파일 또는 TorchScript 파일을 나타냄
- .pth는 Path에서 따왔고, 모델의 가중치 파일 경로를 나타내는 관용적 명칭
- 모델 파일의 확장자는 주로
체크포인트 저장/불러오기
체크포인트는 학습 과정의 특정 지점마다 저장하는 것을 의미
- 데이터의 개수가 많고 깊은 구조의 모델을 학습하면 오랜 시간이 소요됨
- 그래서 학습 시 오류가 발생하거나 시스템 리소스 과부하 등으로 학스이 정상적으로 마무리되지 않을 수 있다
- 위와 같은 현상을 방지하기 위해 일정 에폭마다 학습된 결과를 저장해 나중에 이어서 학습 가능
활성화 함수
인공 신경망에서 사용되는 은닉층을 활성화하기 위한 함수
- 입력 데이터의 값을 정해진 수식에 따라 변환하는 식
- 활성화란?
인공 신경망의 뉴런의 출력값을 선형에서 비선형으로 변환하는 것- 즉, 활성화함수는 네트워크가 데이터의 복잡한 패턴을 기반으로 학습하고 결정을 내릴 수 있게 제어한다
- 가중치와 편향으로 이루어진 노드를 선형에서 비선형으로 갱신하는 역할
- 네트워크에 포함된 노드는 출력값에 동일한 영향을 미치지 않음
즉, 노드마다 전달돼야 하는 정보량이 다르다- 각 피처별로 중요한 피처는 가중치를 높게 주는 등
- 네트워크에 포함된 노드는 출력값에 동일한 영향을 미치지 않음
- 비선형성을 추가하여 신경망이 복잡한 패턴을 학습할 수 있도록 한다
- 선형이면 왜 안돼?
- 신경망의 각 계층을 거쳐도 결국 하나의 선형 변환으로 귀결되므로 다층 구조의 의미가 사라진다
이진 분류
참 또는 거짓의 형태나 A그룹 또는 B그룹으로 데이터를 나누는 것
- 분류 결과가 맞다면 1 (true, a그룹에 포함)을 반환,
아니라면 0을 반환- 참 또는 거짓으로 결과를 분류하기 때문에 논리 회귀(로지스틱 회귀, Logistic Regression)또는 논리 분류(Logistic Classification)라고도 한다
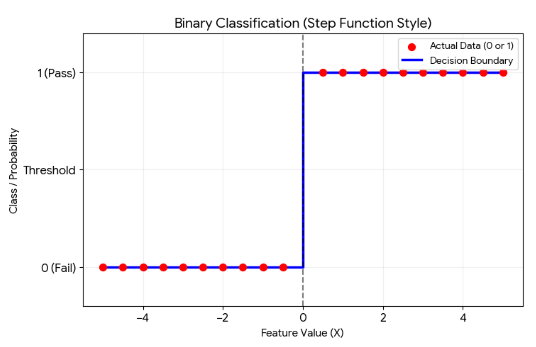
- 이런식으로 데이터가 딱 나뉜다면 좋겠지만, 실제 데이터들을 보면 특정 그룹으로 나누기엔 모호한 경우가 존재한다
- 그래서, 관측치는 0~1 범위로 예측된 점수를 반환하며
데이터를 0또는 1로 분류하기 위해 임계값을 정한다- 임계값이 0.5인 경우,
Y가 0.5보다 작은 값은 거짓, 0.5보다 큰 값은 참이 된다
- 임계값이 0.5인 경우,
- 또한, 실제 데이터는 위의 그래프처럼 Y값이 0~1의 범위를 갖지 않을 가능성이 높다
- 0~1 범위를 갖게 하기 위해 시그모이드 함수와 같은 활성화 함수를 적용한다
- 참 또는 거짓으로 결과를 분류하기 때문에 논리 회귀(로지스틱 회귀, Logistic Regression)또는 논리 분류(Logistic Classification)라고도 한다
시그모이드 함수
Sigmoid Function
- S자형 곡선 모양으로, 반환값은 0~1 범위를 갖는다
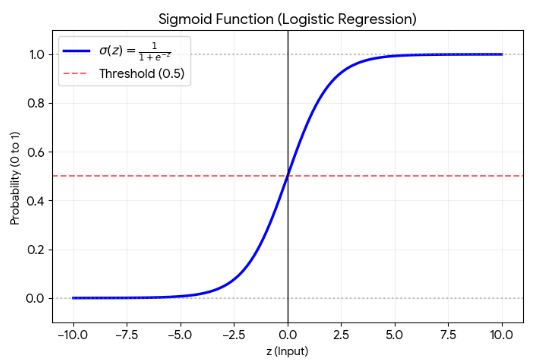
- 이진 분류 신경망의 출력 계층에서 활성화 함수로 사용
- 수식
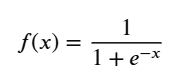
- x의 계수가 0에 가까워질수록 완만한 경사를 갖게 된다
- 주로 로지스틱 회귀에 사용
- 로지스틱 회귀: 독립변수X의 선형 결합을 활용하여 결과를 예측
종속변수Y를 범주형 데이터를 대상으로 계산하기 때문에 해당 데이터의 결과가 특정 분류로 나뉜다 (즉, 분류에서도 사용된다)
- 로지스틱 회귀: 독립변수X의 선형 결합을 활용하여 결과를 예측
- 장점
- 유연한 미분값을 가지므로, 입력에 따라 값이 급격하게 변하지 않는다
- 출력의 범위가 0~1사이로 제한됨으로써 정규화 중 기울기 폭주 (Exploding Gradient) 문제가 발생하지 않고 미분식이 단순한 형태를 지님
- 한계
- 기울기 폭주를 방지하는 대신 기울기 소실(Vanishing Gradient) 문제를 일으킨다
- 매우 큰 입력값이 들어와도 최대 1의 값을 갖게된다
- 즉, 계층이 많아지면 점점 값이 0에 수렴되는 문제가 발생
그래프를 보면 양쪽 끝으로 갈수록 평평한 곡선이 그려지므로 미분을 하면, 즉 기울기가 0에 가깝다 - 이런 문제 때문에, 은닉층에서는 활성화 함수로 사용하지 않는다
- Y 출력값의 중심이 0이 아니므로 입력 데이터가 항상 양수인 경우,
기울기는 모두 양수 또는 음수가 되어 기울기가 지그재그 형태로 변동하는 문제- 즉, 학습 방향을 잡지 못한다
- 기울기 폭주를 방지하는 대신 기울기 소실(Vanishing Gradient) 문제를 일으킨다
이진 교차 엔트로피 (손실함수)
Binary Cross Entropy, BCE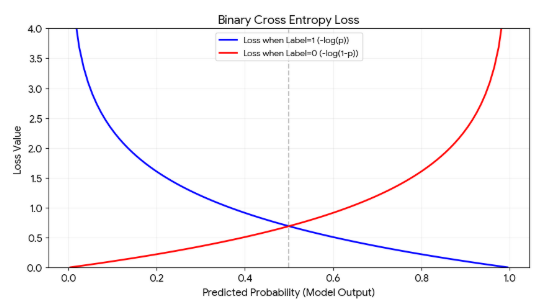
- 배경
MSE를 이진분류에 사용하면 예측값과 실젯값의 차이가 작으면 계산되는 오차도 작아져 학습을 원활하게 하기 어렵다- 0~1 사이의 범위에 있으면 제곱의 힘이 발휘되지 않음
- 시그모이드함수의 단점을 더 악화시킴
- 두 가지 로그 함수를 교차해 오차를 계산
- 실젯값이 1일 때 적용하는 수식과 0일 때 적용하는 수식 2가지
- 로그함수를 이용하므로 불일치하는 비중이 높을수록 높은 손실 값을 반환
(로그의 진수가 0에 가까워질수록 무한대로 발산하는 특성)
- 수식
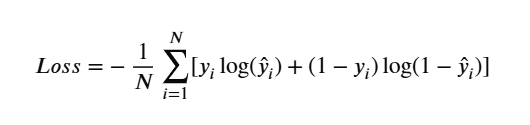
- 두 로그 식을 합쳐 기울기가 0이 되는 지점을 찾는다
- 정답이 1이면 앞의 식만 동작 (푸른선만 남음)
- 정답이 0이면 뒤의 식만 동작 (붉은선만 남음)
- 오차를 계산하기 위해 각 손실값의 평균을 반환
- 두 로그 식을 합쳐 기울기가 0이 되는 지점을 찾는다
계단 함수
Step Function
- 이진 활성화 함수 Binary Activation Function 라고도 한다
- 퍼셉트론에서 최초로 사용한 활성화 함수
- 입력값의 합이 임계값을 넘으면 0을 출력하고 넘지 못하면 1을 출력
위의 이진 분류에서 봤던 그래프도 이것 - 딥러닝에서는 사용하지 않는다!!
- 임계값에서 불연속점을 갖기 때문
- 즉, 미분이 불가능하다
- 역전파 과정에서 데이터가 극단적으로 변경된다
임곗값 함수
Threshold Function
임곗값보다 크면 입력값을 그대로 전달하고 임곗값보다 작으면 특정 값으로 변경
- 선형 함수와 계단 함수의 조합으로 볼 수 있다
- 출력이 0 또는 1인 이진 분류 작업을 위해 신경망에서 자주 사용되는 활성화 함수이다
- 그러나, 입력에 대한 함수의 기울기를 계산할 수 없으므로 네트워크를 최적화하기 어렵다.
- 특별한 경우가 아니라면 사용하지 않는다
하이퍼볼릭 탄젠트 함수
Hyperbolic Tangent Function
- 시그모이드 함수와 유사하지만 출력값의 중심이 0이고, -1~1의 범위를 갖는다
- 즉, 시그모이드 함수보다 기울기 소실이 비교적 덜 발생
- 하지만. 입력값이 4보다 큰 경우 출력값이 1에 수렴하므로 동일하게 기울기 소실이 발생
- 시그모이드처럼 출력값의 최대가 1이기 때문에 기울기 소실이 발생한다고 이해하면 될 것 같습니다
- 4라는 값이 나온 이유는 tanh함수의 특성상 4라는 값부터 0.9993으로 기울기가 0에 매우 가까워지기 때문
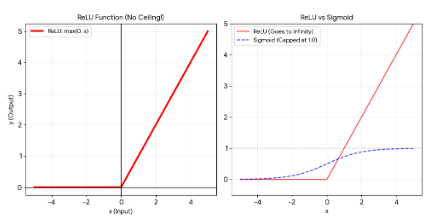
ReLU함수
Rectified Linear Unit Function
- 0보다 작거나 같으면 0을 반환. 0보다 크면 선형 함수에 대입하는 구조
- 입력값이 양수라면 출력값이 제한되지 않아 기울기 소실이 발생하지 않음
- 입력값이 음수인 경우 항상 0을 반환해 가중치나 편향이 갱신되지 않을 수 있다
- 가중치 합이 음수가 되면 해당 노드는 죽은 뉴런 (Dead Neuron, Dying ReLU)이 된다
- 수식이 간단해 순전파나 역전파 과정의 연산이 매우 빠르다
LeakyReLU 함수
Leaky Rectified Linear Unit Function
- 음수 기울기(negative slope)를 제어하여 죽은 뉴런 현상을 방지하기 위해 사용
- 작은 값이라도 출력시켜 기울기를 갱신한다
작은 값을 출력시키면 더 넓은 범위의 패턴을 학습할 수 있어, 네트워크의 성능을 향상시키는데 도움이 될 수 있다 - 양수의 경우 ReLU와 동일하게 동작
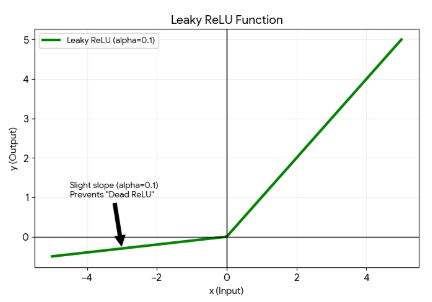
- 작은 값이라도 출력시켜 기울기를 갱신한다
PReLU함수
Parametric Rectified Linear Unit Function
- LeakyReLU함수와 형태가 동일하지만,
- 음수 기울기 값을 고정값이 아닌 학습을 통해 갱신되는 값으로 간주
음수 기울기(negative slope, a)가 지속해서 값이 변경됨- 즉, 학습 데이터세트에 영향을 받음
- 음수 기울기 값을 고정값이 아닌 학습을 통해 갱신되는 값으로 간주
ELU 함수
Exponential ~
- 지수 함수를 사용하여 부드러운 곡선의 형태를 갖음
- 앞선 ReLU함수들과 달리, 음의 기울기에서 비선형 구조를 갖는다
- 0에서 출력값이 끊어지지 않는다
- 즉, 입력값이 0인 경우에도 출력값이 급변하지 않아 GD의 수렴 속도가 비교적 빠름
- 더 복잡한 연산을 진행하므로 학습 속도는 더 느린다
- 그러나, 데이터의 복잡한 패턴과 관계를 학습하는 네트워크의 능력을 향상시키는 데 도움이 될 수 있음
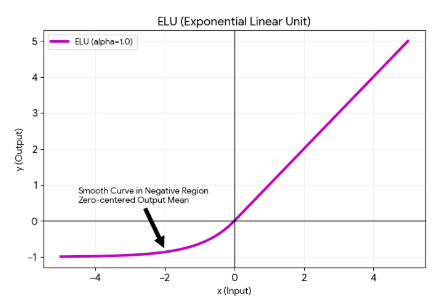
- 그러나, 데이터의 복잡한 패턴과 관계를 학습하는 네트워크의 능력을 향상시키는 데 도움이 될 수 있음
소프트맥스 함수
Softmax Function
- 차원 벡터에서 특정 출력값이 k 번째 클래스에 속할 확률을 계산
- 클래스에 속할 확률을 계산하는 함수이므로,
은닉층에서 사용하지 않고 출력층에서 사용
(주로 다중분류에 이용한다)
- 클래스에 속할 확률을 계산하는 함수이므로,
- 네트워크의 출력을 가능한 클래스에 대한 확률 분포로 매핑
- 이 외에도 소프트민 함수(Softmin function), 로그 소프트맥스 함수 등이 있다
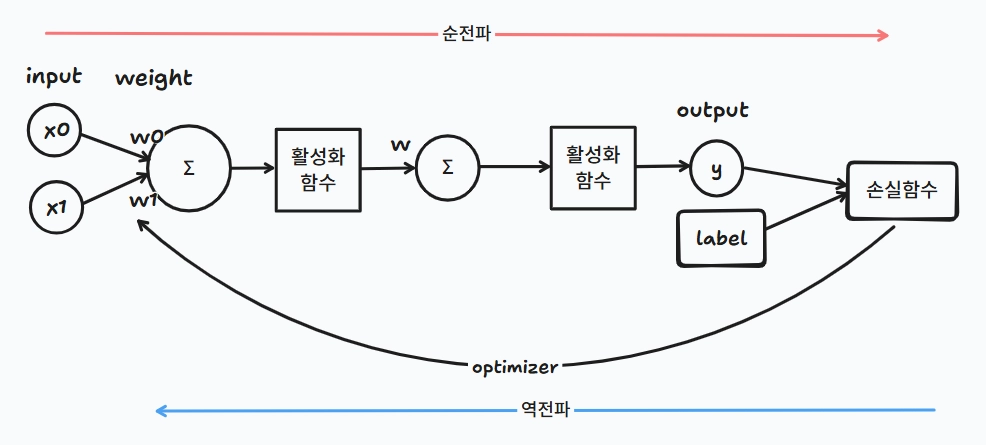
순전파와 역전파
Forward Propagation 순전파
- 순방향 전달(forward pass)라고도 한다
- 입력이 주어지면 신경망의 출력을 계산하는 프로세스
- 입력 데이터를 기반으로 신경망을 따라 입력층부터 출력층까지 차례대로 변수를 계산하고 추론한 결과를 전달
- 디테일하게 보자
- 입력값이 들어온다
- 계층마다 가중치와 편향으로 계산된 값이 활성화 함수에 전달된다
- 활성화 함수에서 출력값이 계산되고,
이 값을 손실 함수에서 실젯값과 함께 연산해 오차를 계산한다
Back propagation 역전파
- 순전파 방향과 반대로 연산이 진행
- 학습 과정에서 순전파 과정을 통해 나온 오차를 활용해 각 계층의 가중치와 편향을 최적화한다
- 오차를 줄이는 방향으로 하이퍼파라미터를 조정하여 모델을 똑똑하게 만드는 학습 과정 안에
역전파(분석)와 최적화(수정) 과정이 있는 것
- 오차를 줄이는 방향으로 하이퍼파라미터를 조정하여 모델을 똑똑하게 만드는 학습 과정 안에
- 각각의 가중치와 편향을 최적화하기 위해 연쇄 법칙(Chain Rule)을 활용
- 결과(오차)가 잘못된 책임을 뒤에서부터 앞으로 거슬러 올라가며 나누어 묻는 것
- 왜 연쇄 법칙이 필요?
최종 오차를 줄이고 싶은데 정작 수정해야할 값은 저 앞단의 가중치와 편향이다- 오차와 두 하이퍼파라미터 사이에 여러 계산 단계가 겹쳐있는데 이를 한번에 계산할 수는 없음
- 연쇄 법칙을 사용하면 복잡한 미분을 잘게 쪼개서 곱할 수 있다
퍼셉트론 Perceptron
인공 신경망의 한 종류
- 출력이 0 또는 1인 작업을 의미하는 이진 분류 작업에 사용되는 간단한 모델
- 신경 세포 neuron이 신호를 전달하는 구조와 유사한 방식으로 구현
- 가지돌기는 입력값을 전달받는 역할
- 신경세포체는 입력값을 토대로 특정 연산을 진행했을 때 임곗값보다 크면 전달.
작으면 전달하지 않는다 - 시냅스는 여러 퍼셉트론을 연결한 형태
- Threshold Logic Unit, TLU 형태를 기반으로 하며,
계단 함수를 적용해 결과를 반환- 입력값과 노드의 가중치를 곱한 값을 모두 더했을 때 임곗값보다 크면 1 작으면 0을 출력
단층 퍼셉트론
Single Layer Perceptron
- 하나의 계층을 갖는 모델
- 은닉층이 없다
- 입력값과 각각의 가중치가 함께 노드에 전달
- 노드 내에서 일어나는 일
- 전달된 입력값과 가중치를 곱한 값
- 편향을 더한 값이
- 활성화 함수에 전달
- 활성화 함수에서 출력값이 계산됨
- 노드 내에서 일어나는 일
- 한계
- 단층 퍼셉트론은 AND, OR, NAND 게이트와 같은 구조를 갖는 모델을 구현이 가능하다
- 직선 하나로 나눌 수 있는(선형 분리 가능) 모든 이진 분류 작업에서 여전히 가장 심플하고 강력한 기본 모델
- OR 게이트 그래프로 표현
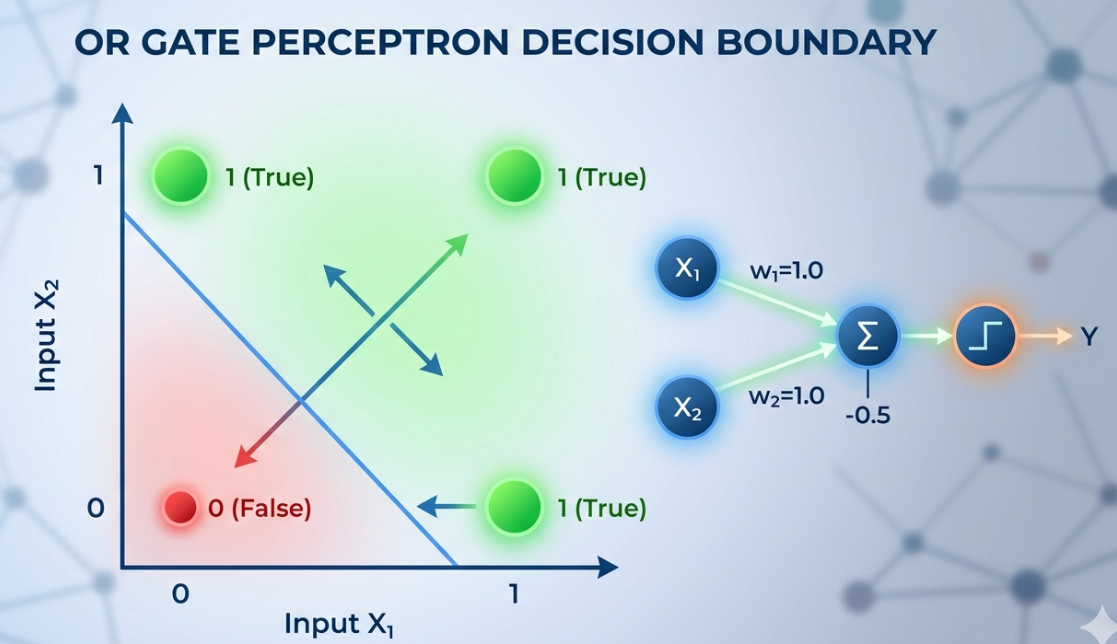
- 하지만, XOR 게이트처럼 하나의 기울기로 표현하기 어려운 구조에서는 적용하기 어렵다
(0,0), (1,1) = 0 / (1,0),(0,1) = 1 인데 이를 직선 하나로 나눌 수가 없음- 이런 문제를 해결하기 위해 다층 퍼셉트론을 활용
- 단층 퍼셉트론은 AND, OR, NAND 게이트와 같은 구조를 갖는 모델을 구현이 가능하다
다층 퍼셉트론
Multi layer Perceptron
단층 퍼셉트론을 여러 개 쌓아 은닉층을 생성
- 은닉층이 한 개 이상인 퍼셉트론 구조
- 은닉층을 2개 이상 연결한다면 심층 신경망(Deep Neural Network, DNN)이라 부름
- 학습 방법 정리
- 입력층부터 출력층까지 순전파 진행
- 출력값(예측값)과 실젯값으로 오차 계산
- 오차를 퍼셉트론의 역방향으로 보내면서 입력된 노드의 기여 측정
- 손실 함수를 편미분해 기울기 계산
- 연쇄 법칙(Chain rule)을 통해 기울기를 계산
- 입력층에 도달할 때까지 노드의 기여도 측정
- 모든 가중치에 최적화 알고리즘 수행
- 은닉층의 수가 늘어날수록 더 복잡한 문제가 해결 가능
- 물론, 갱신해야할 가중치나 편향도 늘어나므로 많은 학습 데이터와 연산량을 필요로 한다
정리하기
모델의 학습
데이터를 입력했을 때 예측값이 정답과 가까워지도록 모델 내부의 가중치와 편향을 반복적으로 조정하는 과정
손실함수
손실 함수(Loss function)는 모델이 얼마나 틀렸는지(모델의 출력이 실제 값과 얼마나 차이나는지) 수치로 알려주는 함수입니다. 모델이 풀어야 할 문제라고도 볼 수도 있습니다.
모델의 학습은 손실을 줄이는 방향으로 진행되기 때문에, 손실 함수는 매우 중요합니다.
| Task | 손실함수 이름 | 특징 | name | |
|---|---|---|---|---|
| 일반 회귀 (오차의 크기 자체가 중요할 때) | MAE 평균 절대 오차 손실 | 입력 X와 대상(정답) Y의 각 요소 사이에서 평균 절대 오차(MAE)를 측정하는 기준(객체)을 생성. 오차의 절댓값 평균. 이상치에 강함 | nn.L1Loss | |
| 일반 회귀 (큰 오차를 강하게 처벌하고 싶을 때) | MSE 평균 제곱 오차 손실 | 입력X와 대상(정답) Y의 각 요소 사이에서 평균 제곱 오차(제곱된 L2 norm)를 측정하는 기준(객체)을 생성. 오차큰 오차에 민감하여 수렴이 빠름 | nn.MSELoss | |
| 다중 분류 (이미지 분류 등 정답이 하나인 경우) | 교차 엔트로피 손실 | 이 기준(객체)은 입력로짓(logits)과 대상(정답) 사이의 교차 엔트로피 손실을 계산. 여러 클래스 중 하나를 고를 때 표준적으로 사용 | nn.CrossEntropyLoss | |
| 시퀀스 인식 (음성 인식, OCR 등 입력과 출력 길이가 다를 때) | CTC 손실 (연결주의 시계열 분류) | 입력과 출력의 길이가 다른 시퀀스 학습(OCR, 음성 인식) | nn.CTCLoss | |
| 다중 분류 (마지막 층에 LogSoftmax를 썼을 때) | 음의 로그 가능도(우도) 손실 | Log-Softmax 결과와 결합하여 사용 | nn.NLLLoss | |
| 카운트 데이터 예측 (단위 시간당 사건 발생 횟수 예측) | 포아송 음의 로그 가능도 손실 | 데이터가 포아송 분포를 따를때(사건 발생 횟수 등) | nn.PoissonNLLLoss | |
| 불확실성 추정 회귀 (평균과 분산을 함께 예측할 때) | 가우시안 음의 로그 가능도 손실 | 가우시안 분포(정규분포)를 가정하여 오차의 확률 밀도를 최적화 | nn.GaussianNLLLoss | |
| 확률 분포 학습 (지식 증류, 두 분포를 비슷하게 만들 때) | 쿨백-라이블러 발산 손실 | 두 확률 분포가 얼마나 유사한지 측정 | nn.KLDivLoss | |
| 이진 분류 (Yes/No 구분, 최종 확률값 입력) | 이진 교차 엔트로피 손실 | 두개 클래스(Yes/No) 구분시 사용 | nn.BCELoss | |
| 이진 분류 (수치적으로 안정적인 Sigmoid 결합형) | 시그모이드 포함 이진 교차 엔트로피 손실 | 두개 클래스(Yes/No) 구분시 사용. | nn.BCEWithLogitsLoss | |
| 랭킹/순위 매기기 (두 데이터 중 무엇이 더 우선인지 학습) | 마진 랭킹 손실 | 두 입력 중 어느 것이 더 큰지/가까운지 학습 | nn.MarginRankingLoss | |
| 비선형 임베딩 학습 (두 데이터가 같은지/다른지 판단) | 힌지 임베딩 손실 | 두 데이터가 같은지 다른지에 따라 거리 제약 | nn.HingeEmbeddingLoss | |
| 다중 레이블 분류 (한 샘플에 정답이 여러 개 일 때) | 다중 레이블 마진 손실 | 하나의 데이터에 여러개의 Label이 있을 수 있는 상황을 처리. 확률(Softmax)기반이 아니라 점수(Score)간의 간격(Margin)을 최적화하여 클래스 간의 구분을 명확히함 | nn.MultiLabelMarginLoss | |
| Robust 회귀 (이상치가 많은 데이터 학습 시) | 후버 손실 | 오차가 작을 때는 MSE처럼 작동하여 정밀하게 수렴하고 오차가 커지면 L1(절대값)처럼 작동하여 이상치에 덜 민감해짐 | nn.HuberLoss | |
| 객체 탐지 (바운딩 박스 위치 회귀 시 표준) | Smooth L1 손실 | 매개변수를 통해 L1과 L2 구간이 바뀌는 지점을 조절, L1의 이상치 저항성과 L2의 수렴 안정성을 모두 갖춰 객체 탐지의 ‘박스좌표’ 예측에 최적화 | nn.SmoothL1Loss | |
| 이진 분류 (로지스틱 손실 기반의 분류) | 소프트 마진 손실 | 두개의 클래스를 구분할 때 정답 Label을 1 또는 -1로 설정하여 학습, 로지스틱 회귀와 유사하지만 마진(Margin) 개념을 사용하여 클래스간의 경계를 최대한 넓히려고 노력함 | nn.SoftMarginLoss | |
| 다중 레이블 분류 (여러 정답을 확률적으로 최적화) | 다중 레이블 소프트 마진 손실 | 하나의 입력 데이터에 대해 여러 개의 정답 클래스가 동시에 존재할 수 있는 상황에 적합. | nn.MultiLabelSoftMarginLoss | |
| 유사도 학습 (두 벡터가 얼마나 같은 방향을 보는지 학습) | 코사인 임베딩 손실 | 두 입력 벡터(x1, x2)가 유사한지(1) 또는 다른지(-1)를 알려주는 레이블(y)가 필요, 두 벡터 사이의 코사인 유사도를 이용하며 값이 1에 가까울 수록 두 벡터의 방향이 같음을 의미, 데이터의 크기 변화에 민감하지 않고 안정적 | nn.CosineEmbeddingLoss | |
| 다중 분류 (힌지 손실 기반의 분류) | 다중 마진 손실 | 정답 클래스의 점수가 다른 모든 오답 클래스의 점수보다 최소한 마진(Margin)만큼은 더 크도록 학습, 확률(Softmax)을 계산하지 않고 각 클래스의 출력값 자체의 차이를 직접 비교 | nn.MultiMarginLoss | |
| 검색/인식 (얼굴 인식 등 유사도 비교) | 트리플렛(삼중항) 마진 손실 | 세 개의 입력(Anchor, Positive, Negative)을 동시에 사용하여 학습, 단순한 거리 비교를 넘어 두 거리 사이에 최소한 마진만큼의 차이가 나도록 강제하여 분별력을 극대화 | nn.TripletMarginLoss | |
| 사용자 정의 거리 학습 (특정 거리 함수를 써서 유사도 학습) | 거리 기반 트리플렛 마진 손 | 기존 TripletLoss와 동일하게 Anchor,Positive,Negative 세개의 입력을 사용, distance_fuction인자를 통해 사용자가 원하는 거리 측정방식(코사인 거리, 맨해튼 거리 등)을 직접 지정할 수 있다는 것 | nn.TripletMarginWithDistanceLoss |
활성화 함수
- 활성화함수가 없다면, 여러 층을 쌓아도 결국 하나의 선형함수로 수렴합니다. 모델을 아무리 깊게 쌓아도 하나의 설명으로 귀결되는 셈입니다.
- 반면 활성화함수를 사용하여 비선형성을 추가하면, 복잡하고 다양한 패턴을 학습할 수 있게 됩니다. 즉, 레이어를 의미 있게 만들어주는 역할을 합니다.
| Task | 활성화 함수 이름 | 특징 | name |
|---|---|---|---|
| 학습 속도 향상 및 평균 출력을 0에 가깝게 유도 | 지수 선형 유닛 | 평균 활성화가 0에 가까움, 입력이 음수일 때 지수 함수를 사용하여 평균을 0으로 유도, 학습 속도를 높임, 죽은 ReLU 방지, 음수 영역에서도 미분값이 0이 아니므로 노드가 아예 멈춰버리는 현상을 해결 | nn.ELU |
| 희소 코딩 및 특정 범위 값 제거 | 하드 슈링크 | 입력값의 절대값이 ʎ 보다 작으면 0으로 만들고 크면 입력값을 그대로 유지함. 중요하지 않은 미세한 신호(노이즈등)를 완전히 제거하여 데이터의 핵심 특징만 남김, 임계점 지점에서 값이 갑자기 튀는 불연속적인 특성이 있어, 학습시 기울기 전달에 주의 필요 | nn.Hardshrink |
| 경량화 모델의 시그모이드 대체 (계산 효율) | 하드 시그모이드 | 지수연산 대신 ReLU와 유사한 선형 연산을 사용하여 계산 속도가 매우빠름. 입력이 아주 작으면 0, 아주 크면 1, 그 사이(보통-3~+3)에서는 직선으로 연결됨, 하드웨어 가속기(NPU등)에서 정수 연산으로 변환하기 쉬워 모델 경량화에 유리함 | nn.Hardsigmoid |
| 값 범위 제한 및 연산 비용 절감 | 하드 탄젠트 | 입력값이 지정된 최소값(min)보다 작으면 min, 최대값(max)보다 크면 max로 고정함, 복잡한 지수 계산 없이 단순한 if문이나 min/max 연산만으로 작동하여 매우 빠름, 제한범위 내에서는 기울기가 1인 직선이므로, Tanh 보다 기울기소실(Vanishing Gradient)문제가 적음 | nn.Hardtanh |
| 모바일용 CNN 표준 활성함수 | 하드 스위시 | 원래 Swish는 성능은 좋지만 연산이 무거운데 이를 선형적으로 근사하여 계산량을 대폭 줄임, ReLU와 달리 0 근처에서 부드러운 곡선 형태를 띠어, 역전파 시 기울기 정보가 더 풍부하게 전달됨, 딥러닝 모델의 깊이가 깊어져도 성능 저하가 적어, 최신 경량화 모델의 표준 활성화 함수로 자리잡 | nn.Hardswish |
| 죽은 ReLU 방지 (음수 기울기 허용) | 리키 렐루 | 입력이 음수일 때 0이 아닌 작은 값(기본 0.01)을 곱해 전달하여 노드 사멸(Dying ReLU)현상을 방지함, 모든 구간에서 기울기가 존재하므로 깊은 신경망에서도 학습 신호가 끝까지 잘 전달됨, 계산이 매우 빠르면서도 성능이 우수하여 GAN이나 복잡한 객체 탐지 모델의 표준 활성화 함수로 쓰임. | nn.LeakyReLU |
| 로그 가능도 손실 계산 보조 | 로그 시그모이드 | 일반 시그모이드는 출력이 0에 너무 가까워지면 계산 오류가 생길 수 있는데 로그를 씌워 이를 음수 큰 값으로 펼쳐서 해결함, 입력이 커질 수록 0에 수렴하고 입력이 작을 수록 음수 방향으로 무한히 작아지는 형태를 띰, 음의 로그 우도와 결함하여 이진 분류용 손실함수를 밑바닥부터 구현할 때 사용됨. | nn.LogSigmoid |
| 트랜스포머 모델의 핵심 (데이터 간 관계 추출) | 멀티헤드 어텐션 | 어텐션을 여러개(Head)로 나누어 병력로 수행함으로써 데이터의 다양한 특징을 동시에 포착함. 데이터 사이의 거리가 멀어도 직접 연결하여 관계를 계산하므로 전역적인 문맥 파악에 탁월함. Q,K,V 세가지 요소를 사용하여 정보를 효율적으로 검색함 | nn.MultiheadAttention |
| 학습 데이터 맞춤형 ReLU (음수 기울기를 학습) | 파라미터 렐루 | 음수 영역의 기울기가 고정값이 아니라 역전파를 통해 업데이트되는 파라미터임, 데이터셋의 분포에 따라 각 채널별로 혹은 전체 노드가 서로 다른 기울기를 가지도록 설정 가능함. | nn.PReLU |
| 딥러닝 표준 은닉층 활성함수 | 렐루 | max(0,x)형태로 계산이 매우 단순하여 학습 및 추론 속도가 압도적으로 빠름. 양수 영역에서 기울기가 항상 1이므로 층이 매우 깊어져도 학습 신호가 잘 전달됨, 0 이하의 값은 모두 0으로 만들어, 중요한 특징만 활성화시키는 효과가 있음. | nn.ReLU |
| 저정밀도 모델 안정화 | 렐루6 | 입력이 6보다 크면 무조건 6으로 출력하여 소수점 연산 시 값이 너무 커져서 발생하는 오차를 방지함, 8비트 정수 연산 등 저밀도 연산 환경에서 모델의 성능 저하를 최소화함. MobileNetV2와 같은 효율 중심의 아키텍처에서 핵심 활성화 함수로 채택됨. | nn.ReLU6 |
| 과적합 방지 및 규제 | 랜덤 렐루 | 학습시 음수 영역의 기울기를 정해진 범위(lower, upper)내에서 매번 랜덤하게 샘플링하여 적용함. 평가시에는 무작위성을 배제하고 학습 때 사용한 범위의 평균값을 고정 기울기로 사용함, 모델에 노이즈를 주입하는 효과가 있어 데이터가 적은 환경에서 모델이 더 탄탄하게 학습됨. | nn.RReLU |
| 자기 정규화 (깊은 MLP의 안정적 학습) | 스케일 지수 선형 유닛 | 층을 통과할때마다 데이터의 평균을 0, 분산을 1로 유지하여 Batch Norm없이도 깊은 망 학습 가능 | nn.SELU |
| 미분 가능성 확보를 위한 ELU 변형 | 연속 지수 선형 유닛 | 깊은 신경망에서 가중치가 업데이트될 때 갑작스러운 값의 변화를 방지하는 효과가 있음. | nn.CELU |
| 최신 NLP 모델 (BERT, GPT 등) 표준 | 가우시안 오차 선형 유닛 | 입력을 단순히 자르는게 아니라 가우시안 분포의 누적 분포함수를 이용해 부드럽게 마스킹함, x<0 영역에서도 아주 미세하게 값이 존재한며, 0 근처에서 매우 매끄러운 곡선을 그려 기울기 전달이 극대화됨, 자연어 처리와 컴퓨터 비전의 최신모델에서 ReLU보다 훨씬 높은 성능을 보여줌 | nn.GELU |
| 이진 분류 출력층 (확률값 출력) | 시그모이드 | Applies the Sigmoid function element-wise. | nn.Sigmoid |
| 깊은 신경망 성능 개선 | 시그모이드 선형 유닛 | Applies the Sigmoid Linear Unit (SiLU) function, element-wise. | nn.SiLU |
| 최신 객체 탐지 성능 최적화 | 미시 | Applies the Mish function, element-wise. | nn.Mish |
| 항상 양수인 값 예측 (ReLU의 매끄러운 버전) | 소프트플러스 | Applies the Softplus function element-wise. | nn.Softplus |
| 데이터 압축 및 노이즈 제거 보조 | 소프트 슈링크 | Applies the soft shrinkage function element-wise. | nn.Softshrink |
| 완만한 포화가 필요한 회귀/분류 | 소프트사인 | Applies the element-wise Softsign function. | nn.Softsign |
| RNN 및 LSTM 계열의 은닉층 | 하이퍼볼릭 탄젠트 | Applies the Hyperbolic Tangent (Tanh) function element-wise. | nn.Tanh |
| 잠재 변수 학습 및 특정 특징 추출 | 탄젠트 슈링크 | Applies the element-wise Tanhshrink function. | nn.Tanhshrink |
| 특정 값 이하 차단 (사용자 정의 ReLU) | 임계값 함수 | Thresholds each element of the input Tensor. | nn.Threshold |
| 언어 모델의 정보 흐름 제어 및 게이팅 | 게이트 선형 유닛 | Applies the gated linear unit function. | nn.GLU |
왜 다양한 활성화 함수를 사용할까
- 활성화 함수에 따라 모델의 성능이 달라질 수 있을까요?
- 모델이 역전파라는 과정을 통해 학습을 할 때, 활성화 함수의 미분값을 계속 곱하면서 뒤로 전달하게 된다
- 이 과정에서 여러가지 문제가 발생할 수 있음
- 시그모이드 같은 함수의 경우 입력값이 커지면 미분값이 0이 됨 (Gradient Vanishing)
- ReLU는 음수에서 미분값이 0이 됨 (죽은 ReLU) → 뉴런이 계속 0이라는 값 밖에 출력을 못하게 되는 상황
- 위의 예시처럼 각 활성화 함수마다 단점이 존재하고 각 장점에 맞는 용도에 따라 사용해야 한다
- 모델이 역전파라는 과정을 통해 학습을 할 때, 활성화 함수의 미분값을 계속 곱하면서 뒤로 전달하게 된다
- 좋은 활성화 함수라는 건 어떤 걸까요?
- 모델이 비선형성을 학습하게 하는 함수
- 역전파 과정에서 기울기 소실(Gradient Vanishing)을 일으키지 않는 함수 (안정적으로 앞쪽 계층까지 기울기가 전달되도록 함)
Optimizer
| name | Default | Has foreach? | Has fused? | 장점/단점 | 특징 |
|---|---|---|---|---|---|
Adadelta | foreach | yes | no | 학습률 설정이 필요 없음 / 학습 속도가 다소 느릴 수 있음 | 학습률(LR)을 직접 설정할 필요 없이 과거 그래디언트의 창을 이용해 적응형으로 조절 |
Adafactor | for-loop | no | no | 메모리 사용량이 극히 적음 / 설정이 복잡하고 일반 모델에선 비효율적임 | 메모리 효율적인 최적화 도구. 주로 거대한 언어 모델 학습에 사용 |
Adagrad | foreach | yes | yes (cpu only) | Sparse 희귀 데이터에 강함 / 학습이 길어지면 학습률이 0이 되어 조기 종료됨 | 자주 등장하지 않는 특징에 대해 더 큰 업데이트를 수행 (Sparse 데이터에 유리) |
Adam | foreach | yes | yes | 가장 범용적이고 빠름 / 하이퍼파라미터에 민감하고 최종 수렴 성능이 낮을 수 있음 | 모멘텀 + RMSprop 결합. 딥러닝에서 가장 범용적으로 쓰이는 표준 Optimizer |
AdamW | foreach | yes | yes | 가중치 감쇠 개선으로 Adam보다 일반화가 뛰어남 / 튜닝이 여전히 필요함 | Adam의 가중치 감쇠 방식을 개선하여 일반화 성능을 높인 버전 |
SparseAdam | for-loop | no | no | 희소 텐서 최적화에 특화 / 밀집 텐서에는 사용할 수 없음 | 희소 행렬 전용 Adam. 임베딩 층 최적화 등에 특화 |
Adamax | foreach | yes | no | Adam보다 안정적인 학습 / Adam보다 덜 대중적이고 성능 차이가 크지 않음 | Adam의 무한 노름 기반 변형. 가끔 Adam보다 안정적인 학습을 보임 |
ASGD | foreach | yes | no | 수렴 지점이 더 안정적임 / 메모리 사용량이 두 배로 늘어남 | 평균화된 SGD. 계산 효율을 유지하며 더 나은 수렴 지점을 찾음 |
LBFGS | for-loop | no | no | 정밀한 최적화 기능 / 메모리 소모가 극심하고 미니배치 학습에 부적합함 | 2차 미분 정보를 활용하는 강력한 최적화 알고리즘. 메모리 소모가 커서 작은 모델에 적합. |
Muon | for-loop | no | no | 특정 구조에서 고속 학습 / 최신 기법이라 호환성이나 검증이 더 필요함 | 최근 추가된 행렬 직교화 기반 최적화 도구. 특정 아키텍처에서 고속 학습. |
NAdam | foreach | yes | no | Nesterov 모멘텀으로 더 빠른 수렴 / 연산량이 Adam보다 조금 더 많음 | Adam에 Nesterov 모멘텀을 추가하여 수렴 속도를 더 끌어올린 버전 |
RAdam | foreach | yes | no | 초기 학습이 매우 안정적임 / 수렴 속도가 일반 아담보다 느릴 때가 있음 | Rectified Adam. 학습 초기 단계의 불안정한 그래디언트 분산을 수동 없이 교정. |
RMSprop | foreach | yes | no | 비정상적인 데이터 (RNN) 드에 강함 / 하이퍼파라미터 설정에 따라 성능 차이가 큼 | 과거 그래디언트의 지수 이동 평균으 사용하여 학습률을 지능적으로 조절 (RNN에 자주 쓰임) |
Rprop | foreach | yes | no | 배치가 클 때 안정적임 / 미니배치 단위 학습에서는 성능이 매우 떨어짐 | 그래디언트의 크기가 아닌 부호(sign)만 보고 업데이트 크기를 결정 (Full-batch에 적합) |
SGD | foreach | yes | yes | 튜닝 시 최고의 성능 (일반화 포) / 초기 학습률 설정이 매우 렵고 느림 | • 가장 기본적인 최적화 방식. 모멘텀을 추가하면 수렴 성능이 대폭 향상. - weignt, bias등의 최적화하려는 변수와 학습률을 통해 최적화를 적용. |
