오늘의 학습목표
- 데이터셋을 훈련, 검증, 테스트로 분리하는 이유와 사용법을 이해한다
- 최적화를 위한 튜닝방법의 종류와 각각의 효과를 이해한다
- 모델 학습의 목표를 이해하고 일반화 성능을 높이기 위한 방법들을 살펴본다
이 포스트의 전반적인 개념은 주로 해당 도서의 3장을 참조하고 있습니다.
[파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습] - 윤대희,김동화,손종민,진현두0. 들어가며
- 모집단 / 표본집단
- 미적분 / 확률과 통계 / 기하로 이뤄지는 수능 수학이 있다고 생각해 봅시다.
- 편의를 위해 미적분 문제 100개, 확통 100개, 기하 100개의 문제가 있다고 생각했을 때,
- 측정하고자 하는 모집단 → 수능 수학 전체에서의 능력 → 미적분/확률과 통계/기하 문제의합
- 우리가 얻을 수 있는 데이터 = 표본집단 → 앞서 말한 문제 100개에서 모종의 방법으로 가져온 문제들의 집합
- 여기서 문제.
- 수능 수학이라는 일반적인 분야를 잘 하고 싶은데, 미적분 문제만 주구장창 풀었다(모델 학습)
- → 확률 통계와 기하가 섞인 문제집에서 높은 점수를 받기 어려움.
- 문제집을 받았는데, 미적분은 240개, 확률과 통계와 기하는 각각 30개만 있는 문제집을 풀었다
- → 상대적으로 미적분을 잘 푸는 것에 비해 확률과 통계/기하는 점수가 낮음.
- 해결책 : 문제를 무작위로 뽑아오자 !
- 10개의 문제를 뽑아왔을 때 → 문제의 분포가 불균형할 확률이 높음.
- 100개의 문제를 뽑아왔을 때 → 문제의 분포가 상대적으로 고르게 분산되어 있음.
- 300개 문제 모두를 뽑아왔을 때(모집단 전체 활용) → 문제의 분포가 모집단과 일치함
- 일반화하자면, 모집단에서 가져온 데이터 양이 많을 수록 모집단을 더 정확하게 표현한다고 생각할 수 있음.
- 따라서, 문제를 많이 뽑아올 수록 수능 수학 실력이라는 일반적인 능력을 발달시키기 좋아짐.
- 수능 수학이라는 일반적인 분야를 잘 하고 싶은데, 미적분 문제만 주구장창 풀었다(모델 학습)
- 과적합:
- 수능 수학 전 출제범위를 잘 풀어야 하는데 미적분만 잘 풀게 되는 현상
- 혹은, 표본집단이 가지고 있는 패턴만을 과하게 학습한 나머지(예시 : 미적분의 비중이 높은 수학 문제집) 학습한 모델과 모집단에 최적화된 모델의 성능이 동떨어지는 경우
- 한 가지 트릭으로, 모집단 전체를 뽑아와서 비교하는 것이 아니라 모집단에서 뽑아온 다른 종류의 표본을 사용해 성능을 측정
- → test set
- 더 나아가서, 표본집단에(뽑아온 문제집) 최적화한 모델이 모집단(’일반적인’ 문제)에서 상대적으로 낮은 현상을 내는 현상.
- 과소적합
- 수능 수학을 모두 잘 한다고 보기에는 알고 있는 개념의 수/문제 풀이 방법(모델 복잡도)의 가짓수가 부족해서, 최적화되었다고 보기에는 학습량이 부족한 경우.
과대적합과 과소적합
두 개념 모두 아래의 공통점을 지니고 있다
- 성능 저하
기본적으로 모델의 성능을 저하시킨다- 과대적합은 훈련 데이터에서는 잘 수행되는 것처럼 보이더라도 새로운 데이터에서는 제대로 값을 예측하지 못함
- 과소적합은 새로운 데이터에 대해 예측을 수행하지 못하며, 전반적으로 모델의 성능이 좋지 못하는 경우
- 모델 선택 실패
두 개념 모두 모델을 변경하거나 모델 구조를 개선하여 문제 완화가 가능하다- 과대적합: 모델의 구조가 너무 복잡해 훈련 데이터에만 의존하게 되어 성능이 저하됨
- 과소적합: 모델이 구조가 너무 단순해 데이터의 특징을 제대로 학습하지 못함
- 편향-분산 트레이드오프
낮은 편향과 낮은 분산을 가져야한다- 분산이 높으면 추정치에 대한 변동 폭이 커지고,
데이터가 갖고 있는 노이즈까지 학습 과정에 포함되어 과대적합 문제를 일으킴 - 편향이 높으면 추정치가 항상 일정한 값을 갖게 될 확률이 높다
데이터의 특징을 제대로 학습하지 못해 과소적합 문제를 일으킴 - 편향과 분산은 서로 반비례관계이다
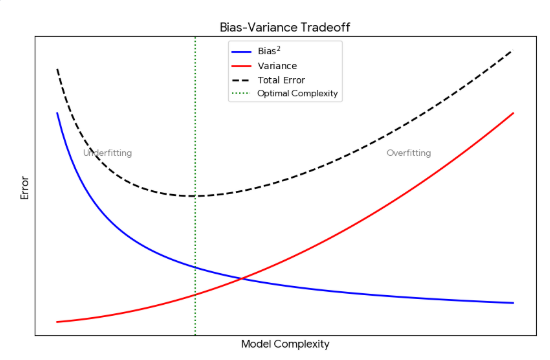
- 모델이 복잡해질수록 분산은 커지고 편향은 작아짐
(모델이 단순해질수록 분산은 작아지고 편향은 커짐) - 오류를 최소화하기 위해 분산과 편향의 균형을 맞춰야 함
- 모델이 복잡해질수록 분산은 커지고 편향은 작아짐
- 분산이 높으면 추정치에 대한 변동 폭이 커지고,
문제 해결
과대적합은 모델의 일반화 능력을 저하해 문제가 발생.
과소적합은 모델이 데이터의 특징을 제대로 학습할 수 없을 때 발생.
- 데이터 수집
훈련 데이터에서 노이즈를 학습하지 않으면서 일반적인 규칙을 찾을 수 있도록 학습 데이터의 수를 증가시키는 방법 - 피처 엔지니어링
신규 데이터 수집이 어려운 경우. 변수나 특징을 추출하거나 피처를 더 작은 차원으로 축소- 모델이 더 학습하기 쉬운 형태의 데이터로 변환
(노이즈에 더 강건하 모델 구축이 가능해짐)
- 모델이 더 학습하기 쉬운 형태의 데이터로 변환
- 모델 변경
- 과대적합: 모델의 계층을 축소하거나 더 간단한 모델로 변경
- 과소적합: 모델의 계층을 확장하거나 더 복잡한 모델로 변경
- 조기 중단 Early Stopping
과대적합이 발생하기 전에 모델 학습을 중단하는 방법- 모델 학습 시에 검증 데이터세트로 성능을 지속적으로 평가해 모델의 성능이 저하되기 전에 조기 중단
- 배치 정규화 Batch Normalization
모델의 계층마다 평균과 분산을 조정해 내부 공변량 변화를 줄인다- 모델 성능과 모델 안정성 향상 효과
- 뒤에서 더 자세히 다룸
- 가중치 초기화 Weight Initialization
매개변수를 최적화하기 전에 가중치 초깃값을 설정하는 프로세스- 학습 시 기울기가 매우 커지거나 작아지는 문제는 학습을 어렵게 만들거나 불가능하게 함
- 적절한 초기 가중치를 설정해 과대적합을 방지할 수 있다
- 정칙화 Regularization
목적함수에 패널티를 부여하는 방법- 모델을 일부 제한해 과대적합을 방지
- 학습 조기 중단, L1정칙화, L2정칙화, 드롭아웃, 가중치 감쇠 등
- 뒤에서 자세히 다룸
배치 정규화
내부 공변량 변화(Internal Covariate Shift)를 줄여 과대적합을 방지하는 기술
- 인공 신경망을 학습할 때 입력값을 배치 단위로 나눠 학습을 진행
- 배치 단위로 나눠 학습하는 경우 상위 계층의 매개변수가 갱신될 때마다 현재 계층에 전달되는 데이터의 분포도 변경됨
- 각 계층은 배치 단위의 데이터로 인해 계속 변화되는 입력 분포를 학습하게 됨
- 그래서, 인공 신경망의 성능과 안정성이 낮아져 학습 속도가 느려진다!
- 내부 공변량 변화란?
- 계층마다 입력 분포가 변경되는 현상
- 은닉층에서 다음 은닉층으로 전달될 때 입력값이 균일해지지 않아, 가중치가 제대로 갱신되지 않을 수 있음
즉, 학습이 불안정해지고 느려져 가중치가 일정한 값으로 수렴하기 어렵다 - 또한, 초기 가중치 값에 민감해져 일반화하기 어려워져 더 많은 학습 데이터를 요구함
- 위의 문제들을 해결하기 위해 각 계층에 배치 정규화를 적용
- 각 계층에 대한 입력이 일반화되고 독립적으로 정규화가 수행
- 더 빠르게 값에 수렴할 수 있음
- 입력이 정규화되므로 초기 가중치에 대한 영향도 줄어듦
- 위의 원리를 반박하는 논문
배치 정규화(BN)가 Internal Covariate Shift(ICS)를 감소시키기 때문이 아니라, 손실 함수 지형(Loss Landscape)을 부드럽게 만들어 최적화를 돕는다
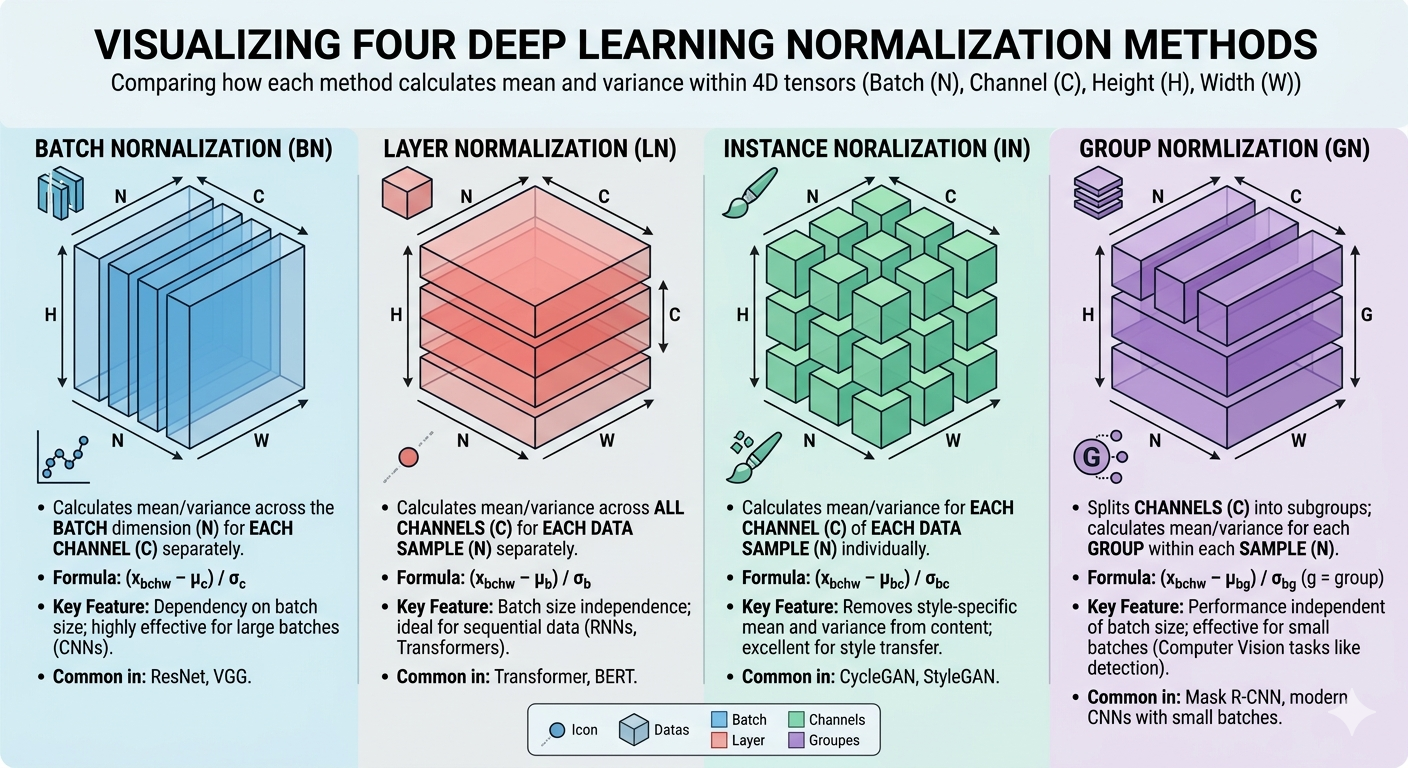
정규화 종류
앞서 본, 배치 정규화는 이미지 분류 모델에서 효과적
- 계층 정규화 Layer Normalization
- 인스턴스 정규화 Instance
- 그룹 정규화 Group
- 3D feature map의 요소
- 설명을 쉽게하기 위해 해당 블록을 이미지,텍스트 데이터라 가정- 차원 D: 이미지 데이터의 크기(너비, 높이)나 어휘사전의 크기, 공간적 정보
(H x W) - 채널 C: 이미지 데이터의 채널이나 시간 간격(Timestep), 피처의 종류
ex. RGB값
- 차원 D: 이미지 데이터의 크기(너비, 높이)나 어휘사전의 크기, 공간적 정보
- BN
미니 배치에서 계산된 평균 및 분산을 기반으로 계층의 입력을 정규화- 이미지 데이터 전체를 대상으로 정규화 수행하지 않고 각각의 이미지 데이터에 채널별로 정규화 수행
- CV관련 모델 중 합성곱 신경망(CNN)이나 다층 퍼셉트론(MLP)과 같은 순반향 신경망에서 주로 사용
- LN
미니 배치의 샘플 저체를 계산하는 방법이 아닌, 채널 축으로 계산- 미니 배치 샘플 간의 의존관계XX
- 샘플이 서로 다른 길이를 가지더라도 정규화 가능
- 신경망 모델 중 자연어 처리에 주로 사용되며 순환 신경망(RNN)이나 트랜스포머 기반 모델에서 주로 사용
- IN
채널과 샘플을 기준으로 정규화- 각 샘플에 대해 개별적으로 수행되므로, 입력이 다른 분포를 갖는 작업에 적합
- 생성적 적대 신경망(GAN)이나 이미지의 스타일을 변환하는 스타일 변환(Style Transfer) 모델에서 주로 사용
- GN
- 채널을 N개의 그룹으로 나누고 각 그룹 내에서 정규화를 수행
- 그룹을 하나로 설정하면 인스턴스 정규화와 동일
- 그룹의 개수를 채널의 개수와 동일하게 설정하면 계층 정규화와 동일
- 배치 크기가 작거나 채널 수가 많은 경우에 주로 사용
- 합성곱 신경망(CNN)의 배치 크기가 작으면 배치 정규화가 배치의 평균과 분산이 데이터세트를 대표한다고 보기 어렵기 때문에 그 대안으로 사용
- 채널을 N개의 그룹으로 나누고 각 그룹 내에서 정규화를 수행
- 3D feature map의 요소
배치 정규화 풀이

- 는 입력값. 는 배치 정규화가 적용된 결괏값
- m: 미니 배치 내 데이터 수
ɛ (입실론): 분산이 0일 때 분모가 0이 되는 것을 방지하는 아주 작은 값 - : 학습가능한 매개변수
- 활성화 함수에서 발생하는 음수의 영역을 처리할 수 있게 값을 조절하는 스케일 값과 시프트 값
- 주로 의 초깃값은 1, 의 초깃값은 0
- 정규화 클래스 (Code)
torch.nn.BatchNorm1d(num_features) #2d/3d 입력 데이터에 배치 정규화
torch.nn.BatchNorm2d(num_features) #4d 입력 데이터에 수행
torch.nn.BatchNorm3d(num_features) #5d
torch.nn.LayerNorm(normalized_shape) #정규화하려는 차원 크기로 계층 정규화
torch.nn.InstanceNorm1d(num_features) #2d/3d 입력 데이터에 인스턴스 정규화
torch.nn.InstanceNorm2d(num_features) #4d
torch.nn.InstanceNorm3d(num_features) #5d
torch.nn.GroupNorm(num_groups, num_channels) #그룹과 채널을 나눠 정규화가중치 초기화
Weight Initialization
모델의 초기 가중치를 설정하는 것
- 모델 매개변수에 적절한 초깃값을 설정하면
- 기울기 폭주나 소실 문제를 완화할 수 있다
- 모델의 수렴 속도를 향상시켜 전반적인 학습 프로세스가 개선된다
상수 초기화
초기 가중치 값을 모두 같은 값으로 초기화
- 예를 들어, 0이나 0.1과 같이 매우 작은 양의 상숫값으로 모든 가중치를 동일하게 할당
- 대표적인 값 (각각의 특징)
- 0
- 모든 가중치를 0으로 초기화하면 입력이 무시되어 출력이 항상 0
(활성화 함수에 따라 0.5일수도 있음) - 역전파 시 모든 기울기가 0으로, 가중치가 전혀 업데이트 되지 않아 학습이 불가능
- 모든 가중치를 0으로 초기화하면 입력이 무시되어 출력이 항상 0
- 1 또는 특정 상수(Constant)
- 0이 아니더라도 모든 뉴런이 동일한 입력을 받아 같은 출력을 생성
- 네트워크의 다중 뉴런 구조를 무의미하게 만듦
- 단위행렬(Unit Matrix)
- 가중치 행렬을 단위행렬로 설정하면 입력이 그대로 전달되지만, 배열구조에서 모든 뉴런이 동일하게 작동
- 디랙 델타 함수(Dirac Delta Function)
- 대각선은 1, 나머지는 0으로 설정하는 함수 형태
(크로네커 델타의 배열 버전) - 입력 인덱스와 출력 인덱스가 같을 때만 1을 전달하지만,
역시 대칭성을 유지해 뉴런 구분이 없다
- 대각선은 1, 나머지는 0으로 설정하는 함수 형태
- 0
- 구현이 간단하고 계산 비용이 거의 들지 않지만,
일반적으로 사용되지 않는다- 왜?
모두 같은 값으로 초기화하면 배열 구조의 가중치에서는 문제가 발생- 대칭 파괴(Breaking Symmetry) 현상
같은 층의 뉴런들이 완벽한 대칭성을 갖는 경우- 순전파: 모든 뉴런이 동일한 가중합과 출력을 계산
- 역전파: 동일한 기울기가 모든 가중치에 적용되어, 업데이트 후에도 대칭이 유지됨
- 모든 노드가 동일한 출력을 생성하여 학습이 되지 않는다
- 대칭 파괴(Breaking Symmetry) 현상
- 왜?
- 스칼라값을 입력으로 받는 매우 작은 모델이나 퍼셉트론 등에 적용하거나, 편향을 초기화 하는 경우 0이나 0.01 등의 형태로 초기화하는 데 사용
무작위 초기화
초기 가중치의 값을 무작위 값이나 특정 분포 형태로 초기화
-
대표적으로 무작위(Random), 균등 분포(Uniform Distribution), 정규 분포(Normal D), 잘린 정규 분포(Truncated Normal D), 희소 정규 분포 초기화(Sparse ND Initialization)
- 균등 분포:
지정 범위에서 값이 동일한 확률로 샘플링 - 정규 분포:
평균 0, 표준편차 를 가진 가우시안 분포에서 샘플링 - 잘린 정규 분포:
정규분포에서 극단값을 잘라내고 재샘플링 - 희소 정규 분포:
가중치 중 일정 비율만 랜덤 값으로 초기화하고 나머지는 0으로 설정
- 균등 분포:
-
대칭 파괴 문제를 방지
-
간단하고 가장 많이 사용되는 초기화 방법
-
계층이 적거나 하나만 있는 경우에는 보편적으로 적용가능하지만,
계층이 많고 깊어질수록 활성화 값이 양 끝단에 치우치게 되어 기울기 소실 현상 발생- 결과적으로 상수 초기화와 동일한 문제를 일으킬 수 있다
- Xavier/He 분산 스케일링이 필요하다
제이비어 & 글로럿 초기화
Xavier Initialization는 Glorot Initialization 라고도 한다
균등 분포나 정규 분포를 사용해 가중치를 초기화
- 각 노드의 출력 분산이 입력 분산과 동일하도록 가중치를 초기화
- 확률 분포 초기화와의 주요 차이?
- 확률 분포 초기화: 앞서 살펴 본 무작위 초기화에서 분포를 사용하는 경우
- 동일한 표준 편차를 사용하지 않고 은닉층의 노드 수에 따라 다른 표준 편차를 할당
- 평균이 0인 정규 분포와 현재 계층의 입력 및 출력 노드 수를 기반으로 계산되는 표준 편차로 가중치를 초기화하여 수행
- 이전 계층의 노드 수와 다음 계층의 노드 수에 따라 표준 편차가 계산됨
- 입력 데이터의 분산이 출력 데이터에서 유지되도록 가중치를 초기화하므로,
시그모이드나 하이퍼볼릭 탄젠트를 활성화 함수로 사용하는 네트워크에서 효과적!- 값이 튀지 않고 안정적인 분산을 유지하기 때문이다
- Xavier가 해결한 문제
- 너무 큰 가중치: 활성화값이 양 끝단에 포화 (기울기 소실)
- 너무 작은 가중치: 활성화값이 0 근처 (기울기 소실)
- 해결: 출력 분산을 입력과 동일하게 유지 (중앙 선형 영역 유지)
카이밍 & 허 초기화
Kaiming Initialization은 He Initialization라고도 한다
- 제이비어 초기화와 마찬가지로
- 균등 분포나 정규 분포를 사용해 가중치를 초기화
- 각 노드의 출력 분산이 입력 분산과 동일하도록 가중치를 초기화
- 제이비어와 차이?
- 현재 계층의 입력 뉴런 수를 기반으로만 가중치를 초기화
- 제이비어 초기화에서 발생한 문제점을 보완한 방법
- 무슨 문제점?
ReLU함수의 죽은 뉴런 문제를 급증 시킴- 이전 계층의 입력 뉴런도 같이 사용하기 때문
층마다 분산이 줄어들어 0으로 수렴하게 됨
- 이전 계층의 입력 뉴런도 같이 사용하기 때문
- 해결: 현재 계층의 입력 뉴런 수만 이용
그래서, ReLU를 활성화 함수로 사용하는 네트워크에서 효과적
- 무슨 문제점?
- 순방향 신경망 네트워크에서 가중치를 초기화할 때 효과적
- 왜?
현재 계층의 입력만 독립적으로 고려하기 때문
- 왜?
직교 초기화
Orthogonal Initialization
- 특잇값 분해(Singular Value Decomposition, SVD)를 활용해 자기 자신을 제외한 나머지 모든 열, 행 벡터들과 직교이면서 동시에 단위 벡터인 행렬을 만드는 방법
- 장단기 메모리(Long Short-Term Memory, LSTM) 및 게이트 순환 유닛(Gated Recurrent Units, GRU)과 같은 순환 신경망(RNN)에서 주로 사용
- 순방향 신경망에서 사용하지 않는 이유?
직교행렬의 고윳값의 절댓값은 1- 행렬 곱을 여러 번 수행하더라도 기울기 폭주나 기울기 소실이 발생하지 않음
- 가중치 행렬의 고윳값이 1에 가까워지도록 해 RNN에서 기울기가 사라지는 문제를 방지하는데 사용
- 고윳값 1: 장기 의존성 학습을 도움
- 모델이 특정 초기화 값에 지나치게 민감해지므로 순방향(Feedforward Neural Network, FFN)에선 사용하지 않는다
- 직교 행렬은 항상 회전만 한다. (변형 어려움)
즉, 표현력 제한 문제 발생 - 층마다 다른 독립적인 역할을 요구하는 순방향과 성격이 다름
- RNN의 경우 동일 가중치를 반복 사용하는 게 좋음
- 직교 행렬은 항상 회전만 한다. (변형 어려움)
- 순방향 신경망에서 사용하지 않는 이유?
가중치 초기화 함수
(p.177-178)
정칙화 Regularization
모델 학습 시 발생하는 과대적합 문제를 방지하기 위해 사용되는 기술
-
모델이 암기가 아니라 일반화(Generalization)할 수 있도록 손실 함수에 규제(Penalty)를 가하는 방식
- 암기란?
모델이 데이터의 특성이나 패턴을 학습하는 것이 아니라,
훈련 데이터의 노이즈를 학습할 대 발생 - 일반화란?
모델이 새로운 데이터에서도 정확한 예측을 할 수 있음을 의미
- 암기란?
-
노이즈에 강건하고 일반화된 모델을 구축하는 것이 목표
- 특정 피처나 특정 패턴에 너무 많은 비중을 할당하지 않도록 손실함수에 규제를 가해 모델의 일반화 성능을 향상시킴
- 학습 데이터들의 작은 차이에 덜 민감해져 모델의 분산 값이 낮아짐
즉, 모델이 학습할 때 의존하는 피처 수를 줄임으로써 모델의 추론 능력을 개선일반화 성능 vs. 추론 능력
일반화 성능 추론 능력 새로운 데이터에서의 정확도 itmaster98.tistory 미지의 문제 해결 과정 Train/Test 성능 격차 측정 논리적·창의적 사고 능력 정량적 (Accuracy, F1 등) 정성적 (문제 해결 과정)
-
정칙화는 모델이 비교적 복잡하고 학습에 사용되는 데이터의 수가 적을 때 활용
- 모델이 단순한 경우,
모델의 매개변수의 수가 적어 정칙화가 필요XX
- 모델이 단순한 경우,
L1 Regularization
Lasso regularization 라고도 한다
- L1Norm 방식을 사용해 규제하는 방법
- L1Norm은 벡터 또는 행렬값의 절댓값 합계를 계산
- 손실 함수에 가중치 절댓값의 합을 추가해 과대적합을 방지
- 모델 학습 시 값이 크지 않은 가중치들(불필요한 가중치)은 0으로 수렴
피처의 수가 줄어듦 (차원 축소) - 특징 선택 효과
- 모델 학습 시 값이 크지 않은 가중치들(불필요한 가중치)은 0으로 수렴
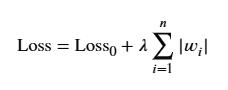
- : 규제 강도. (하이퍼파라미터이다)
0보다 큰 값으로 설정- 규제강도가 0에 가까워질수록 모델은 더 많은 특징을 사용해 과대적합에 민감하다
- 반대로 너무 높으면 대부분의 가중치가 0에 수렴되므로 과소적합 문제에 노출됨
- : 규제 강도. (하이퍼파라미터이다)
- 희소한 모델이 될 수도 있다(한계)
- 불필요한 특징을 적당히 삭제함으로써 모델의 성능이 올라갈 수 있지만,
- 예측에 사용되는 피처 수가 줄어들어 정보의 손실로 이어지기도 함
- 주로 선형 모델에 적용
- 왜?
선형모델은 다중공선성 문제가 발생하면 과적합이 일어나는 경우가 많음.
그래서 피처를 정리해 중요한 피처에 집중하는 라쏘가 효과적 - 선형 회귀 모델에 L1 정칙화를 적용하는 것을 라쏘 회귀라 한다
- 왜?
L2 Regularization
Ridge regularization라고도 한다
- L2Norm 방식을 사용해 규제
- L2Norm은 벡터 또는 행렬 값의 크기를 계산
- 손실함수에 가중치 제곱의 합을 추가해 과대적합 방지
- L1과 비교해서 L2의 특징
- 하나의 특징이 너무 중요한 요소가 되지 않도록 규제를 가하는 것에 의미를 둠
- L1에 비해,
- 가중치 값들이 비교적 균일하게 분포된다
- 가중치를 0으로 만들지 않고 0에 가깝게 만든다
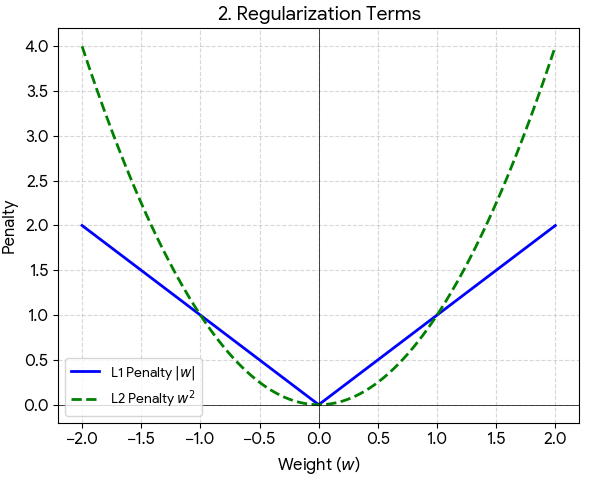
- L1 regularization은 선형적인 특성을 가지므로 가중치가 0이 아닌 곳에서는 모든 값에 고정적인 값을 추가
- L2 regularization은 비선형적인 특성을 가지므로 가중치가 0에 가까워질수록 규제값이 줄어듦
-
항목 L1 (Lasso) L2 (Ridge) 모델링 희소 모델 밀집 모델 특징 선택 자동 선택 (β=0\beta=0β=0) 없음 (모두 축소) 이상치 민감도 낮음 (희소성) 높음 (제곱 효과) 가중치 효과 일부 0, 희소 골고루 축소, 균일 학습 안정성 덜 안정적 안정적
- 주로 심층 신경망 모델에서 사용
- 가중치들이 균일하게 작아지기 때문
- 선형 회귀 모델에서 L2 정칙화를 사용하는 경우 릿지 회귀라고 함
L1, L2 Reularization의 계산복잡도 문제
- 코드에서는 둘다 간단히 적용이 되지만,
- 모델의 가중치를 모두 계산해 모델을 갱신하므로 계산복잡도 문제가 발생한다
- 또한, L1은 미분이 불가능해 역전파 계산하는 데 더 많은 리소스를 소모
L2도 매개변수의 제곱값을 계산하고 저장해야하므로 많은 리소스를 소모 - 하이파라미터인 lambda도 여러 번 반복해 최적의 람다값을 찾아야 한다
L1, L2 정칙화 + 조기 중지 / 드롭아웃
- 과대적합을 효과적으로 방지
- 단독 사용의 한계
- L1/L2만 : 검증 손실 모니터링 부족, 과소적합 위험
- train loss를 최소화하는 과정에 집중돼있어 valid loss를 확인하고 스스로 멈추지 못함 (검증 손실 모니터링 부족 문제)
그래서, 조기중지가 필요
- train loss를 최소화하는 과정에 집중돼있어 valid loss를 확인하고 스스로 멈추지 못함 (검증 손실 모니터링 부족 문제)
- 조기중지만: 가중치 여전히 과대
- 드롭아웃만: 구조적 과적합 가능
- 뉴런 랜덤 제거로 특정 뉴런에 의존하는 것을 방지하지만,
네트워크 구조 자체의 복잡성은 해결이 안됨
(특정 피처를 누락시켜도 계층 자체가 딥한 문제가 과적합을 일으킬 수 잇음)
- 뉴런 랜덤 제거로 특정 뉴런에 의존하는 것을 방지하지만,
- L1/L2만 : 검증 손실 모니터링 부족, 과소적합 위험
- 조합 효과:
- L1/L2: 모델의 복잡도 완화
- 드롭아웃: 뉴런 다양성 증가 (앙상블 효과)
- 조기중지: 최적 타이밍 정지
- 그렇다면, 정칙화는 다양하게 사용하는 것이 좋은가?
- 위와 같이 각자의 단점은 보완하고 시너지가 있는 조합의 경우처럼 사용하는 것은 좋지만,
- 무작정 정칙화들을 같이 사용한다고 좋은 건 아님.
- 위의 경우는 왜 좋은 조합일까?
각 정칙화의 규제 시점/대상이 다르기 때문
- 위의 경우는 왜 좋은 조합일까?
- 적절한 다양성과 검증셋 피드백을 통해 규제강도(하이퍼파라미터) 값을 잘 조정해야 한다
- 적절한 다양성이란?
서로 다른 시점/대상을 규제하는 기법들의 조합
- 적절한 다양성이란?
가중치 감쇠 Weight Decay
모델이 더 작은 가중치를 갖도록 손실 함수에 규제를 가하는 방법
- 일반적으로 가중치 감쇠가 L2정칙화와 동의어로 사용되지만, 가중치 감쇠는 손실 함수에 규제 항을 추가하는 기술 자체를 의미
- 파이토치나 텐서플로와 같은 딥러닝 라이브러리에서는 최적화 함수에 적용하는 L2 정규화 의미로 사용된다
- 즉, 파이토치의 가중치 감쇠는 L2 정규화와 동일
최적화 함수에서weight_decay하이퍼파라미터 설정을 통해 구현할 수 있다
모멘텀 Momentum
경사 하강법 알고리즘의 변형 중 하나
- 이전에 이동했던 방향과 기울기의 크기를 고려하여 가중치를 갱신
- 지수 가중 이동평균을 사용
- 이전 기울기 값의 일부를 현재 기울기 값에 추가해 가중치를 갱신
- 이전 기울기 값에 의해 설정된 방향으로 더 빠르게 이동
일종의 관성(momentumn)효과를 얻을 수 있다
- 이전 기울기 값에 의해 설정된 방향으로 더 빠르게 이동
- 수식

- : 모멘텀 계수 (하이퍼파라미터)
과거의 방향을 얼마나 유지할지 결정- 0.0~1.0 사이의 값
- 일반적으로 0.9를 사용
- 0으로 설정하면 경사하강법과 동일
- 모멘텀 값
이전 모멘텀 값
- : 모멘텀 계수 (하이퍼파라미터)
- 파이토치의 모멘텀은 가중치 감쇠 적용 방법처럼 최적화 함수의
momentum하이퍼파라미터를 설정해 구현 가능
엘라스틱 넷 Elastic-Net
L1 정칙화와 L2 정칙화를 결합해 사용하는 방식
- 희소성과 작은 가중치의 균형을 맞춘다
- 두 정칙화 방식의 선형 조합으로 사용하며,
혼합 비율을 설정해 가중치를 규제
- 혼합 비율()은 0~1 사이의 값을 사용 (하이퍼파라미터)
1이면 라쏘, 0이면 릿지와 동일
- 혼합 비율()은 0~1 사이의 값을 사용 (하이퍼파라미터)
- L1, L2 정칙화보다 트레이드오프 문제를 더 유연하게 대처할 수 있다
- 혼합비율로 상황에 따라 최적화 가능 (tradeoff)
- 각 정칙화의 장점을 최대한 활용할 수 있지만,
균형적인 규제를 가하기 위해 새로운 하이퍼파라미터의 값도 조정해야하므로 더 많은 튜닝이 필요 - 두 정칙화의 계산 복잡도 문제가 있어 마찬가지로 더 많은 리소스를 소모
- 특징의 수가 샘플의 수보다 더 많을 때 유의미한 결과를 가져온다
- 왜?
L1,L2가 피처를 직접 규제하는 방식이기 때문
(고차원에서 더 효과적이다)- 그래서, 상관관계가 있는 특징을 더 잘 처리
- 왜?
드롭아웃 Dropout
정칙화 기법 중 하나로, 모델의 훈련 과정에서 일부 노드를 일정 비율로 제거하거나 0으로 설정해 과대적합을 방지하는 간단하고 효율적인 방법
- 과대적합을 발생시키는 이유 중, 모델 학습 시 발생하는 노드간 동조화(Co-adaptation)현상 과 연관
- 동조화 현상이란?
모델 학습 중 특정 노드의 가중치나 편향이 큰 값을 갖게 되면 다른 노드가 큰 값을 갖는 노드에 의존하는 것 - 드롭아웃은 특정 노드의 의존성이 갖게되는 것을 방지해준다
- 동조화 현상이란?
- 일부 노드 제거
- 투표 효과
- 모델 평균화
- 한계
- 모델 평균화 효과를 얻기 위해 다른 드롭아웃 마스크를 사용해 모델을 여러번 훈련시켜야 하므로 훈련시간이 증가
- 모든 노드를 사용해 학습하지 않으므로,
데이터세트가 많지 않다면 오히려 성능이 저하될 수 있다- 드롭아웃 적용 시에는 충분한 데이터세트와 비교적 깊은 모델에 적용
- 신경망 패키지의
Dropout클래스로 쉽게 구현 가능하다p베르누이 분포의 모수를 의미 (하이퍼파라미터)
각 노드의 제거 여부를 확률적으로 선택- 이 과정은 순방향 메서드에서 드롭아웃을 적용한 계층 노드에 적용 (훈련시에만)
- 다른 하이퍼파라미터들과 다르게,
일반적으로 고정적인 값을 사용.
- 일반적으로 배치 정규화와 동시에 사용하지 않는다
- 서로의 정칙화 효과를 방해할 수 있기 때문
- 배치 정규화의 경우 내부 공변량 변화를 줄여 과대적합을 방지
- 드롭아웃은 일부 노드를 삭제
- 같이 사용하면 모델은 순방향 과정에서 다른 활성화 분포를 가지게 됨
(배치 정규화의 의미가 사라짐) - 만약 같이 사용하는 경우가 발생한다면?
드롭아웃, 배치정규화 순으로 적용한다 (교재 내용)- Dropout이 일부 뉴런을 0으로 만들기 때문에, 그 이후에 BN을 배치해야 0이 된 뉴런들을 포함한 실제 데이터 분포를 다시 정규화할 수 있다는 입장
- 근데, 실제로는?
보통: conv -> batch norm -> activation -> dropout -> pooling 진행- BN은 학습 데이터의 평균과 분산을 계산하여 정규화한다. 만약 Dropout을 먼저 쓰면 매 배치마다 무작위로 뉴런이 꺼지면서 통계값이 요동치게 됨. 이로 인해 BN이 고정된 통계값을 학습하기 어려워져 성능이 떨어지는 'Variance Shift(분산 이동)' 현상이 발생할 수 있다
- 서로의 정칙화 효과를 방해할 수 있기 때문
- 일반적으로 성능 향상의 이점을 얻는다
- 비교적 많은 특징을 사용해 학습하는 이미지 인식이나 음성 인식 모델에서 성능이 향상되는 결과를 보임
드롭아웃의 p값 튜닝
- 위에서는 일반적으로 고정적인 값을 사용한다고 했는데, 또 다른 입장도 존재함
- 표준적인 가이드라인과 결정 기준
- Hidden Layers (은닉층): 보통 0.5 (50%)를 가장 많이 사용합니다.
- 힌튼 교수(Geoffrey Hinton)의 논문에서 제안된 수치로, 무작위성을 극대화하여 앙상블 효과를 가장 잘 얻을 수 있는 지점입니다.
- Input Layer (입력층): 보통 0.2 (20%) 이하로 낮게 잡거나 아예 사용하지 않습니다.
- 입력 데이터(이미지 픽셀, 단어 등) 자체를 너무 많이 지워버리면 모델이 아예 정보를 읽지 못할 수 있기 때문입니다.
- Output Layer (출력층): 사용하지 않습니다. 최종 결과값은 모든 정보를 취합해야 하므로 드롭아웃을 걸지 않는 것이 원칙입니다.
- Hidden Layers (은닉층): 보통 0.5 (50%)를 가장 많이 사용합니다.
- 위에서 일반적으로 고정한다고 했지만, 사실 상황에 따라 달라지는 것이기 때문에,
- validation 성능에 따라 튜닝을 해야 한다
- 참고로 당연히 하나의 에폭 속 같은 계층 내에서는 같은 p 값을 쓴다
다른 계층이면 계층별로 다르게 p값을 설정할 수 있다
드롭아웃과 앙상블 효과
- 앙상블효과: 여러 모델을 조화를 이뤄서 합치는 느낌
- 테스트 단계에서의 '평균화(Averaging)'
앙상블의 핵심은 "여러 모델의 예측값을 평균 내어 정답률을 높이는 것"
- 드롭아웃의 작동: 테스트 시에는 모든 노드를 켭니다. 이때 각 노드의 출력값에 드롭아웃 비율(p)을 곱해줍니다
- 같은 값을 곱해주는게 어떻게 평균화라는거지?
학습할 때에는 p확률에 따라 실제로 몇가지 노드를 뽑아서 사용했으나, 테스트에서는 모든 데이터를 사용해야하므로. 각 노드의 출력값에 p(0~1)를 곱해주어 적용해주는 것
- 의미: 이는 학습 때 훈련시켰던 수많은 서브 네트워크들의 예측치를 하나로 합쳐서(Weight Averaging) 결과를 도출하는 과정으로 해석됩니다.
- 학습 시: 확률 p만큼만 노드를 썼으니, 값이 들쑥날쑥함.
- 테스트 시: 모든 노드를 다 켜면 학습 때보다 값이 너무 커짐.
- 조정: 그래서 p를 곱해 '학습 때 노드들이 평균적으로 내뱉던 강도'로 맞춤.
- 이 과정이 수학적으로 '앙상블 모델들의 예측값을 평균 내는 것'과 근사한 효과를 준다 - 드롭아웃은 배치마다 랜덤하게 뉴런을 켜기 때문에 각 배치를 다른 모델. 고유한 하위 신경망으로 보는 관점이 있다
- 즉, 별도의 모델 여러 개를 돌리지 않고도 단 하나의 모델로 '앙상블 효과'를 낸다고 볼 수 있음
그레이디언트 클리핑 Gradient Clipping
모델을 학습할 때 기울기가 너무 커지는 현상을 방지
- 배경:
과대적합 모델은 특정 노드의 가중치가 너무 크다는 특징을 갖음- 높은 가중치는 높은 분산 값을 갖게 하여 모델의 성능이 저하
- 해결:
위의 문제를 해결하기 위해 가중치 최댓값을 규제해 최대 임곗값을 초과하지 않도록 기울기를 잘라(Clipping) 설정한 임곗값으로 변경- 최대 임곗값을 넘는 경우 기울기 벡터의 방향을 유지하면서 기울기를 잘라 규제한다
- 일반적으로 L2노름을 사용해 최대 기울기를 규제
- 최대 임곗값: 하이퍼파라미터
- 사용자가 설정
(값을 설정할 때에는 여러 번 실험을 통해 경험적으로 신중히 선택) - 0.1이나 1과 같이 작은 크기의 임곗값을 적용
학습률 조절과 비슷한 효과를 얻음 - 높으면 모델의 표현력이 떨어지고, 낮으면 오히려 학습이 불안정하다
- 사용자가 설정
- 순환 신경망(RNN)이나 LSTM 모델을 학습하는데 주로 사용
- 두 모델은 기울기 폭주에 취약
- 가중치 값에 대한 엄격한 제약 조건을 요구하는 상황이나
모델이 큰 기울기에 민감한 상황에서 유용하게 활용 - 역전파를 수행한 이후와 최적화 함수를 반영하기 전에 호출
데이터 증강 및 변환
Data Augmentation
- 데이터가 가진 고유한 특징을 유지한 채 변형하거나 노이즈를 추가해 데이터세트의 크기를 인위적으로 늘리는 방법
- 모델은 학습 데이터가 가진 특징의 패턴을 학습해 새로운 데이터를 분석
- 모델의 과대적합을 줄이고 일반화 능력을 향상
- 데이터 수집은 법적 문제, 데이터 품질, 데이터 신뢰도 등 다양한 문제가 있는데,
데이터 증강을 이용하면 기존 데이터의 품질을 유지한 채 특징을 살려 모델 학습에 사용이 가능하다- 모델의 분산과 편향을 줄일 수 있다
- 잘못된 정보가 들어오는 문제 발생 XX
- 데이터 불균형 완화
- 한계
- 하지만, 너무 많은 변형이나 노이즈를 추가하면
기존 데이터가 가진 특성이 파괴될 수도 있다- 데이터의 일관성이 사라진다
- 특정 알고리즘을 적용해 생성하므로 데이터 수집보다 더 많은 비용이 들 수 있다
- 하지만, 너무 많은 변형이나 노이즈를 추가하면
정칙화와 비교
- 목적이 갖다
- 과적합 방지
- 일반화 향상
- 접근이 다르다
- augmentation: 인위적으로(품질유지) 데이터를 증가
- regularization: 모델 복잡도를 감소
텍스트 데이터 증강
문서 분류 및 요약, 문장 번역과 같은 자연어 처리 모델을 구성할 때 데이터세트의 크기를 쉽게 늘리기 위해 사용된다
- 알아두면 좋은 라이브러리
sacremoses,NLTK: 텍스트를 토큰화하고 정규화하는 라이브러리
- 삽입 및 삭제
- 교체 및 대체
- 역번역
이미지 데이터 증강
객체 검출 및 인식, 이미지 분류와 같은 이미지 처리 모델을 구성할 때 데이터세트의 크기를 쉽게 늘리기 위해 사용
- 알아두면 좋은 라이브러리
torchvision이미지 데이터를 증강하고 변형하기 위한 기본적인 메서드 제공
imguag토치비전 라이브러리에서 제공하지 않는 증강 방법 제공 - 변환 적용 방법
- 회전 및 대칭
- 자르기 및 패딩
- 크기 조정
- 변형
- 색상 변환
- 노이즈
- 컷아웃 및 무작위 지우기
- 혼합 및 컷믹스
정리표
| 구분 | category | 이름 | 효과 | name |
|---|---|---|---|---|
| 텍스트 | Character | OCR | 디지털화 과정의 인식 오류를 모사하여 강건함 증대 | OcrAug |
| 텍스트 | Character | Keyboard | 키보드 거리 기반 오타(Typo)를 생성하여 사용자 입력 노이즈 대응 | KeyboardAug |
| 텍스트 | Character | Random | 문자 삽입, 교체, 삭제를 통해 단어 내부 노이즈 생성 | RandomCharAug |
| 텍스트 | Word | Spelling | 사전에 정의된 철자 오류로 교체하여 문법적 오차 학습 | SpellingAug |
| 텍스트 | Word | Word Embeddings | Word2Vec, GloVe 등을 이용해 유사한 벡터를 가진 단어로 교체 | WordEmbsAug |
| 텍스트 | Word | TF-IDF | 단어의 중요도(TF-IDF)가 낮은 단어를 추출하여 유사한 중요도의 단어로 교체 | TfIdfAug |
| 텍스트 | Word | Contextual Word Embeddings | BERT, RoBERTa 등을 사용해 문맥 흐름에 자연스러운 단어로 교체 | ContextualWordEmbsAug |
| 텍스트 | Word | Synonym | 유의어로 교체하여 문장 의미를 유지한 채 표현의 다양성 확보 | SynonymAug |
| 텍스트 | Word | Antonym | 반의어로 교체하여 부정적 문맥이나 대조 관계를 학습 | AntonymAug |
| 텍스트 | Word | Random Word | 단어 삭제, 교체, 삽입을 통해 단어 수준의 변동성 부여 | RandomWordAug |
| 텍스트 | Word | Split | 한 단어를 무작위로 쪼개어 미등록어(OOV) 대응력 향상 | SplitAug |
| 텍스트 | Word | Back Translation | 타국어 번역 후 재번역을 통해 문장 구조의 유연성 확보 | BackTranslationAug |
| 텍스트 | Word | Reverse Word | 단어의 순서를 뒤집어 어순 변화에 대한 모델의 내성 강화 | ReservedAug |
| 텍스트 | Sentence | Contextual Word Embedding | 문장 수준에서 BERT 등을 이용해 문맥에 맞는 새로운 문장 생성 | ContextualWordEmbsForSentenceAug |
| 텍스트 | Sentence | Abstractive Summarization | 긴 문장을 핵심 의미 위주로 요약하여 데이터의 집약도 향상 | AbstSummAug |
| 이미지 | Crop | CenterCrop | 배경 노이즈를 줄여 중요한 객체 중심 학습을 돕기도 함 | CenterCrop |
| 이미지 | Crop | FiveCrop | 여러 시야에서의 입력을 제공, 테스트 타임 증강에도 사용 | transforms.FiveCrop |
| 이미지 | Crop | RandomCrop | 객체 위치 변화에 덜 민감 | transforms.RandomCrop |
| 이미지 | Crop | RandomSizedCrop | RandomResizedCrop의 구버전. 현재는 대체됨 | transforms.RandomSizedCrop |
| 이미지 | Crop | RandomResizedCrop | 스케일.비율 변화에 강건 | transforms.RandomResizedCrop |
| 이미지 | Crop | TenCrop | FiveCrop + 좌우 뒤집기 조합. 보다 강력한 테스트 타임 증강 | transforms.TenCrop |
| 이미지 | Color | ColorJitter | 다양한 조명.색감 상황에 대한 강건성 향상 | transforms.ColorJitter |
| 이미지 | Color | Grayscale | 색 정보를 제거해 모양.윤곽 위주로 특징을 학습하도록 유도 | transforms.Grayscale |
| 이미지 | Color | RandomGrayscale | 색상에 덜 의존하고 형태에 더 집중하게 함 | transforms.RandomGrayscale |
| 이미지 | Geometric | Pad | 가장자리에 여백을 추가해 이후 랜덤 크롭/이동 증강과 결합. 위치변화에 덜 민감 | transforms.Pad |
| 이미지 | Geometric | RandomAffine | 이동·스케일·회전·시어 등을 한 번에 랜덤 적용, 기하학적 변형에 대한 불변성 향상. | transforms.RandomAffine |
| 이미지 | Geometric | RandomVerticalFlip | 설정한 확률에 따라 이미지를 상하 반전 | transforms.RandomVerticalFlip |
| 이미지 | Geometric | RandomHorizontalFlip | 설정한 확률에 따라 이미지를 좌우 반전 | transforms.RandomHorizontalFlip |
| 이미지 | Geometric | RandomPerspective | 이미지에 무작위 원근 변환을 적용 | transforms.RandomPerspective |
| 이미지 | Geometric | RandomRotation | 이미지를 지정한 각도 범위 내에서 무작위 회전 | transforms.RandomRotation |
| 이미지 | Composition | RandomApply | 주어진 변환 리스트를 설정한 확률로 묶어서 적용 | transforms.RandomApply |
| 이미지 | Composition | RandomChoice | 변환 리스트 중 하나를 무작위로 선택하여 적용 | transforms.RandomChoice |
| 이미지 | Composition | RandomOrder | 변환 리스트의 순서를 무작위로 섞어서 적용 | transforms.RandomOrder |
| 이미지 | Noise/Erasure | RandomErasing | 이미지의 임의 영역을 지우거나 노이즈로 채움 | transforms.RandomErasing |
| 이미지 | Blur | GaussianBlur | 이미지에 가우시안 블러를 적용하여 흐리게 만듦 | transforms.GaussianBlur |
| 이미지 | Resize | Resize | 이미지의 크기를 지정한 사이즈로 변경 | transforms.Resize |
| 이미지 | Resize | Scale | Resize의 구버전. | transforms.Scale |
| 이미지 | Conversion | Normalize | 텐서 데이터를 평균과 표준편차로 정규화 | transforms.Normalize |
| 이미지 | Conversion | ToTensor | PIL 이미지나 ndarray를 FloatTensor(0~1 사이)로 변환 | transforms.ToTensor |
| 이미지 | Conversion | ToPILImage | 텐서나 ndarray를 PIL 이미지로 변환 | transforms.ToPILImage |
| 이미지 | Conversion | ConvertImageDType | 텐서 이미지의 데이터 타입(dtype)을 변환 | transforms.ConvertImageDtype |
| 이미지 | Interpolation | InterpolationMode | 이미지 크기 변경(Resize, Rotation 등) 시 픽셀 값을 채우는 보간 알고리즘 정의 | transforms.InterpolationMode |
| 이미지 | Others | LinearTransformation | 미리 계산된 행렬로 백색화(Whitening) 변환 적용 | transforms.LinearTransformation |
| 이미지 | Others | Lambda | 사용자가 정의한 커스텀 함수를 변환에 적용 | transforms.Lambda |
사전 학습된 모델
Pre-trained Model이란 대규모 데이터세트로 학습된 딥러닝 모델로 이미 학습이 완료된 모델을 의미
- 사전 학습된 모델 자체를 현재 시스템에 적용하거나 사전 학습된 임베딩(Embeddings) 벡터를 활용해 모델을 구성할 수 있다
- 이미 학습된 모델의 일부를 활용하거나, 추가학습을 통해 모델의 성능을 끌어낼 수 있다
- 이미 다양한 작업에서 성능을 검증하는 모델(pre-trained)을 사용하면 안정되고 우수한 성능을 기대할 수 있다
- 대규모 데이터세트에서 데이터의 특징을 학습했으므로 유사한 작업에 대해서도 우수한 성능을 기대할 수 있음
- 처음부터 모델을 훈련시키지 않아도 돼서
학습에 필요한 시간이 대폭 감소- 모델 개발 프로세스를 가속화
- 모델의 성능을 향상
- 사전 학습된 모델은 전이 학습(Transfer Learning)과 같은 작업 뿐 아니라 백본 네트워크(Backbone Networks)로 사용된다
- 대규모 데이터에서 학습한 지식을 활용하여 소량의 데이터로도 우수한 성능을 달성할 수 있다
백본 Backbone
입력 데이터에서 특징을 추출해 최종 분류기에 전달하는 딥러닝 모델이나 딥러닝 모델의 일부를 의미
- 관련 개념은 합성곱 신경망 모델인 VCG, ResNet, MaskR-CNN 논문 등에서 직간접적으로 언급됨
- 합성곱 계층이 입력 이미지를 고차원 특징 벡터로 변환해 이미지 분류 작업을 돕는 특징 추출기의 역할로 사용할 수 있다는 점에서 백본이라는 용어가 등장
- 백본 네트워크는 입력 데이터에서 특징을 추출하므로,
노이즈와 불필요한 특성을 제거하고 가장 중요한 피처를 추출할 수 있다 - 활용 예시
- 이미지에서 객체를 검출하는 합성곱 신경망
- 객체 검출 모델이 아닌 포즈 추정 모델이나 이미지 분할 모델로 확장할 때
- 모델을 구성할 때 백본을 활용한다고 해서 모델의 성능이 급격히 좋아지는 것은 아님!
- 장단점이 존재한다
- 즉, 해결하려는 작업에 적합한 백본을 선택할 것.
- 백본으로 사용하는 딥러닝 모델에는 많은 매개변수가 존재하며 학습 데이터에 따라 쉽게 과대적합될 수 있음
- 사전 학습된 백본은 미세 조정이나 전이 학습을 적용해 과대적합을 피해야한다
- 현재 작업에 적합한 백본을 찾기 위해 다양한 백본을 적용해가며 성능을 모니터링
- 백본으로 사용하는 딥러닝 모델에는 많은 매개변수가 존재하며 학습 데이터에 따라 쉽게 과대적합될 수 있음
- 자연어 처리와 컴퓨터비전 작업에서 백본이 되는 모델은 BERT, GPT, VGG-16, ResNet과 같이 초대규모 딥러닝 모델 hyper-scale deep learning models 을 사용
전이 학습 Transfer Learning
어떤 작업을 수행하기 위해 이미 사전 학습된 모델을 재사용해 새로운 작업이나 관련 도메인의 성능을 향상시킬 수 있는 기술을 의미
- 특정 영역의 대규모 데이터세트에서 사전 학습된 모델을 다른 영역의 작은 데이터세트로 미세 조정해 활용
- source domain 사전학습한 대규모 데이터세트
- target domain 다른 영역의 작은 데이터세트
- source domain에서 학습한 지식을 활용해 target domain에서 모델의 성능을 향상시킴
- 전이학습의 구조
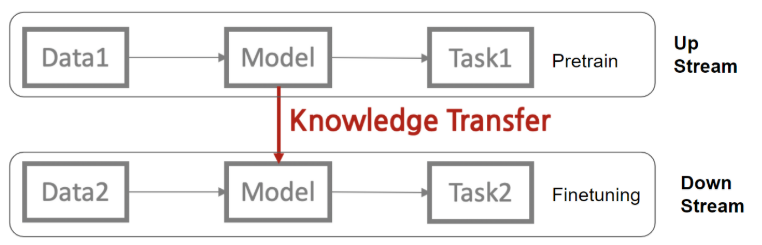
- 업스트림 영역, 다운스트림 영역으로 구분
- 사전 학습된 모델을 업스트림 모델
전이 학습 파이프라인 중 시작 부분에 위치- 대규모 특정 도메인에 대한 특징과 특성이 학습돼야 함
- 미세 조정된 모델을 다운스트림 모델
전이 학습 파이프라인 중 마지막 부분에 위치- 업스트림 모델에서 학습한 지식을 활용해 작은 규모의 타깃 도메인을 학습
귀납적 전이 학습
Inductive Transfer Learning
- 기존에 학습한 모델의 지식을 활용해 새로운 작업을 수행하기 위한 방법 중 하나
- 모델의 일반화 능력을 향상
- 기존 모델의 학습된 지식을 새로운 작업으로 이전함으로써 작업 효율성과 성능을 향상
- 자기주도적 학습 Self-taught Learning
비지도 전이 학습의 유형 중 하나- 소스 도메인의 데이터셋에서 양은 많으나 레이블링된 데이터의 수가 매우 적거나 없을 때 사용
- 레이블이 없는 대규모 데이터셋에서 특징을 추출하는 오토 인코더와 같은 모델을 학습
- 저차원 공간에서 레이블링된 데이터로 미세 조정
- 소스 도메인의 데이터셋에서 양은 많으나 레이블링된 데이터의 수가 매우 적거나 없을 때 사용
- 다중 작업 학습 Multi-task Learning
레이블이 지정된 소스 도메인과 타깃 도메인 데이터를 기반으로 모델에 여러 작업을 동시에 가르치는 방법
-모델 구조가 아래 두가지로 나뉜다- 공유 계층 Shared Layers
소스 도메인과 타깃 도메인의 데이터셋에서 모델을 사전학습- 서로 다른 작업의 특징을 맞추기 위해 동시에 학습되므로 하나의 작업에 과대적합 되지 않아 일반화된 모델을 얻을 수 있다
- 성능 향상에 기여
- 서로 다른 작업의 특징을 맞추기 위해 동시에 학습되므로 하나의 작업에 과대적합 되지 않아 일반화된 모델을 얻을 수 있다
- 작업별 계층 Task Specific Layer
단일 작업을 위해 작업별 계층마다 타깃 도메인 데이터셋으로 미세 조정하는 방법으로 모델을 구성- 작업마다 서로 다른 학습 데이터셋을 사용하여 미세조정한다
- 공유 계층 Shared Layers
변환적 전이 학습
Transductive Transfer Learning
- 소스 도메인과 타깃 도메인이 유사하지만 완전히 동일하지 않은 경우
- 소스 도메인은 레이블이 존재
- 타깃 도메인은 레이블이 존재XX
- 도메인 적응(Domain Adaptation)
소스 도메인과 타깃 도메인의 특징 분포를 전이시키는 방법- 소스 도메인과 타깃 도메인의 특징 분포가 다를 때, 두 도메인의 특징 공간/분포를 정렬하도록 학습하는 방법
- 두 도메인은 유사하지만 특징 공간과 분포는 서로 다르며, 이 차이를 줄이도록 표현을 학습
- 타깃 도메인에서 모델의 성능을 향상시키는 것이 목적이므로,
필요한 경우 소스 도메인이 조정될 수 있음
- 표본 선택 편향/공변량 이동(Sample Selection Bias/Covariance Shift)
소스 도메인과 타깃 도메인의 분산과 편향이 크게 다를 때 표본은 선택해 표본이나 공변량을 이동 시키는 방법- 두 도메인이 완전히 동일하지 않아 학습 데이터에서는 좋은 성능을 보였어도 테스트 데이터에서는 안 좋을 수 있음
(학습 분포와 실제 테스트 분포가 다른 상황) - 무작위/비무작위 샘플링 방법이나 도메인 적응, 가중치 재부여를 통해 해당 학습치만 전이시키는 방법
- 해당 학습치만 전이?
소스 샘플에 위의 방법을 적용해 타깃 분포에 맞추는 것
- 해당 학습치만 전이?
- 두 도메인이 완전히 동일하지 않아 학습 데이터에서는 좋은 성능을 보였어도 테스트 데이터에서는 안 좋을 수 있음
비지도 전이 학습
Unsupervised Transfer Learning
- 소스 도메인과 타깃 도메인 모두 레이블이 지정된 데이터가 없는 전이 학습 방법
- 소스 도메인에서 타깃 도메인의 성능을 개선하는 데 사용할 수 있는 특징 표현을 학습
- 위의 자기주도적 학습의 과정을 생각하면 된다
- 대표적인 방법으로는 생성적 적대 신경망(Generative Adversarial Network, GAN)과 군집화(Clustering)가 있다
제로-샷 전이 학습
Zero-shot Transfer Learning
원-샷 전이 학습
One-shot Transfer Learning
- 서포트 셋: 학습에 사용될 대표 샘플
각 클래스당 하나 이상의 대표 샘플로 이뤄짐 - 쿼리 셋: 클래스를 분류하기 위한 입력 데이터
분류 대상 데이터로, 서포트 셋에서 수집한 샘플과는 다른 샘플이어야 한다 - 서포트 셋의 대표 샘플과 쿼리 셋 간의 거리를 측정하여 쿼리 셋과 가장 가까운 서프트셋의 대표 샘플의 클래스로 분류됨
- 거리 측정 방법: 유클리드 거리, 코사인 유사도 등
정리표
| 유형 | 세부유형 | 소스도메인 | 타깃도메인 | 특징 |
|---|---|---|---|---|
| 귀납적 전이학습 - 자기주도적학습 (Self-supervised TL) | 대표: SimCLR, MoCo, BYOL | 대규모 레이블 없는 이미지 (ImageNet 등) | 동일 도메인, 레이블 없는 타깃 데이터 | 자기 레이블 생성 → 표현 학습 → fine-tuning |
| 귀납적 전이학습 - 다중 작업 학습 (Multi-task Learning) | Hard/Soft Parameter Sharing | 여러 관련 태스크 데이터셋 (레이블 O) | 동일 도메인, 다중 태스크 (레이블 O) | 공유 표현 → 다중 태스크 동시 학습 |
| 변환적 전이학습 (Transductive TL) | 도메인 적응 (DANN, MMD) | 소스 도메인 (다른 분포) (레이블 O) | 타깃 도메인 (다른 분포) (레이블 X) | 소스→타깃 분포 정렬, 레이블 없음 |
| 비지도 전이학습 (Unsupervised TL) | Autoencoder 기반 특징 학습 | 소스 도메인 (대규모) (레이블 X) | 동일/다른 도메인, 레이블 없음 | 레이블 없이 특징 표현 학습 |
| 제로샷 학습 (Zero-shot Learning) | Cross-modal transfer (CLIP 등) | 대규모 언어/이미지 데이터 (프리트레인) (레이블 O) | 동일 도메인, 샘플 0개 (레이블 X) | 타깃 샘플 없이 클래스 설명으로 예측 |
| 원샷 학습 (One-shot Learning) | Siamese Network 기반 | 대규모 이미지 데이터 (프리트레인) (레이블 O) | 동일 도메인, 샘플 1개 (레이블 X) | 1개 샘플로 새로운 클래스 학습 |
특징 추출 및 미세 조정
Feature Extraction 및 Fine-tuning
- 전이 학습에 사용되는 일반적인 기술
- 특징 추출은 타깃 도메인이 소스 도메인과 유사하고 타깃 도메인의 데이터셋이 적을 때 사용
- 두 도메인이 매우 유사하면 타깃 도메인으로 학습 시에도 소스 도메인의 가중치나 편향도 유사
- 특징 추출 계층은 동결해 학습하지 않고 기존에 학습된 모델의 가중치를 사용
- 예측 모델마다 요구하는 출력 노드의 수가 다르므로 모델의 분류기(Classifier)만 재구성해 학습
- 미세 조정은 특징 추출 계층을 일부만 동결하거나 동결하지 않고 타깃 도메인에 대한 학습을 진행
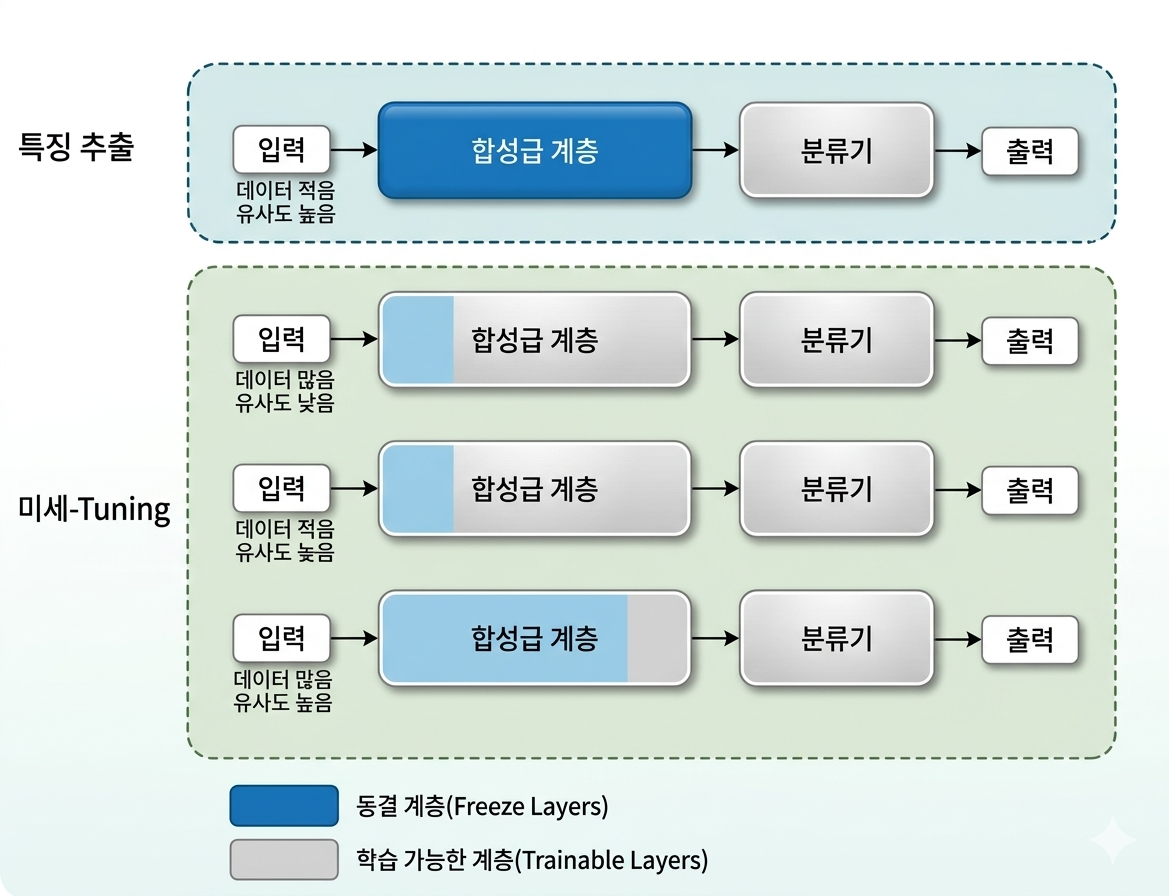
- 위 이미지에서 헷갈릴 부분 다시 정리
- 미세 조정에서 데이터가 많고 유사도는 낮은 경우엔 모든 계층을 동결하지 않는다 (그림이 잘못 생성됨)
- 계층을 동결한다?
특정 부분의 가중치 값이 변하지 않도록 고정한다는 의미 - 타겟 도메인의 목적에 따라 분류기를 새롭게 구성
- 위 이미지에서 헷갈릴 부분 다시 정리
