A Survey on Efficient Inference for Large Language Models (Zhou et al., 2024) 논문
개요
이 논문은 대형 언어 모델(LLM: Large Language Models)의 추론(inference) 과정을 중심으로, 자원 제약 환경에서 더 효율적으로 작동하게 만드는 다양한 기술들을 정리한 리뷰(survey)
- 왜 LLM 추론이 비효율적인가? 그 원인은 무엇인가? (챕터 2)
- 효율화를 위한 분류체계(taxonomy) 제시 — 데이터 수준(data-level), 모델 수준(model-level), 시스템 수준(system-level) (챕터 3)
- 각 수준별로 기존 연구와 기법들 정리 (챕터 4, 5, 6)
- 응용 시나리오 및 토의 (챕터 7)
- 결론 및 향후 연구 방향 (챕터 8)
Section 2: 배경 및 효율성 병목 요인 (Background & Bottlenecks)
- 대부분의 LLM은 Transformer 구조 기반 → Self-Attention과 Feed-Forward Network로 구성됨.
- 이 구조는 강력하지만 입력 길이에 따라 연산량이 폭증. 이 섹션은 LLM이 왜 “비효율적일 수밖에 없는지”를 수학적으로 설명함.
2.1 LLM 개념 및 발전
- 최근 LLM들이 자연어 이해 (NLU), 생성 (NLG), 추론(reasoning), 코드 생성(code generation) 등 다양한 영역에서 뛰어난 성능을 보여주고 있음.
- 하지만 이 모델들이 커질수록 연산량, 메모리 접근비용, 저장공간 요구 등이 급격히 증가함.
2.2 효율성 지표
- “추론 효율”은 보통 지연(latency), 처리량(throughput), 전력/에너지 소비, 메모리 사용량/저장용량 등으로 측정 가능함
2.3 병목 요인 분석
논문에서는 LLM 추론이 비효율이 되는 주된 원인 세 가지를 들고 있음:
- 모델 크기 (Model size): 파라미터 수가 많으면 계산량·메모리 접근량이 증가함.
- 어텐션 연산의 이차(Quadratic) 복잡도: Transformer 기반 모델에서 입력 길이가 늘면 self-attention 연산 비용이 입력 길이 제곱에 비례해서 증가함.
- 자동회귀 디코딩(Autoregressive Decoding): 한 토큰씩 생성하며 매 스텝마다 이전 상태(예: KV cache)를 참조해야 하므로 메모리 및 연산 오버헤드가 크다는 점.
이 병목들 때문에 단순히 모델을 키우거나 데이터를 많이 쓰는 방식으로는 자원 제한 환경에서 LLM을 효과적으로 운용하기 어렵다는 것.
Section 3: 분류체계(Taxonomy)
“어떤 차원에서 효율화를 논할 수 있는가”라는 틀을 제시
주요 분류 :
- 데이터 수준 (Data-level optimization): 입력/출력에 대한 최적화, 프롬프트 입력 길이 감소, 불필요한 토큰 제거 등
- 모델 수준 (Model-level optimization): 모델 구조 변경, 파라미터 감소, 경량화, 압축, 특수 어텐션 기법 등
- 시스템 수준 (System-level optimization): 하드웨어/소프트웨어/프레임워크 수준에서의 최적화, 배치처리(batch processing), 메모리 관리, 병렬화 등
이 분류는 이후 각 챕터에서 다루는 기법들을 체계적으로 정리하는 데 사용됨
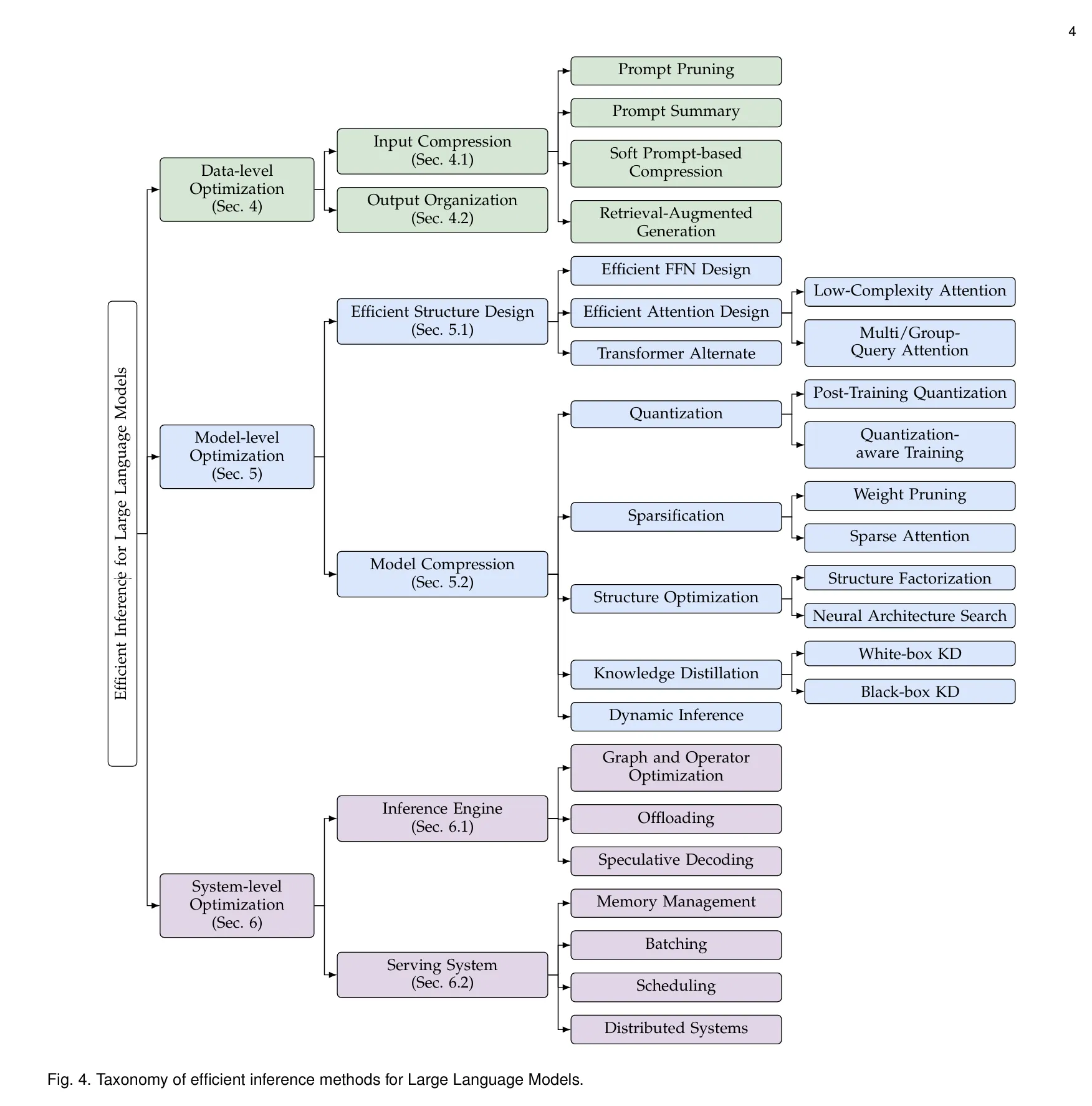
Section 4: 데이터 수준 최적화 (Data-level Optimization)
입출력 데이터 최적화 전략:
- 입력 압축(Input compression): Model에 전달하는 입력 프롬프트(prompt)나 문장 길이를 줄이거나, 불필요한 토큰을 제거해서 계산량을 줄임.
- 대표 기법: Prompt Compression, Token Reduction, Prompt Pruning
- 출력 최적화(Output organization): 생성(디코딩) 과정에서 생성되는 출력 토큰의 구조나 생성 방식 자체를 바꿔 효율을 높이는 방법.
- 대표 기법: Early Exit(디코딩 중 토큰 별 혹은 레이어 별로 조기 중단하여 연산 절감) , Adaptive Sampling( 디코딩 과정의 토큰 샘플링을 동적으로 조정하여 불필요한 탐색을 줄임)
- 프리에이치(prefill) 최적화: LLM이 생성 과정 전에 입력을 처리하는 단계에서 불필요한 연산을 줄이는 기법 등.
- 대표 기법: KV-cache 재사용, Prefix reuse, Partial batch prefill 등
LLM의 추론 파이프라인 단계 [입력 → 생성 → 초기 연산 ]을 기준으로 효율화를 나눈 것.
이 챕터의 목적은 “모델 내부 구조나 하드웨어를 바꾸지 않고도, 데이터와 입력/출력 설계만으로 추론 비용을 낮출 수 있는 방법”을 설명하는 데 있음
Section 5: 모델 수준 최적화 (Model-level Optimization)
모델 자체 구조나 파라미터, 연산 방식 등을 바꿔 효율화를 꾀하는 방법들을 정리:
| 상위 전략 | 주요 목표 | 설명 |
|---|---|---|
| ① 경량화 구조 (Lightweight Architectures) | 모델 구조 자체를 더 효율적으로 설계 | 계산량 줄이는 아키텍처 설계 (예: 작은 FFN, 모듈화, 구조적 공유) |
| ② 어텐션 최적화 (Efficient Attention) | Self-Attention의 이차 복잡도(O(n²)) 줄이기 | Sparse/Linear/Low-rank 어텐션으로 연산량 감소 |
| ③ 모델 압축/축소 (Model Compression / Reduction) | 기존 모델의 파라미터 수나 정밀도 줄이기 | Pruning, Quantization 등 |
| ④ 혼합 전문가 구조 (Mixture of Experts, MoE) | 입력별로 일부만 계산 | 여러 전문가 중 일부만 활성화해 효율성 향상 |
| 기법 | 속하는 전략 | 이유 / 논문 내 분류 설명 |
|---|---|---|
| Pruning (프루닝) | 3. 모델 압축/축소 (Model Compression) | 불필요한 파라미터(가중치, 뉴런, 헤드 등)를 제거하여 모델 크기와 연산량 감소. |
| Quantization (양자화) | 3. 모델 압축/축소 (Model Compression) | 32-bit → 16/8/4-bit 등으로 정밀도 낮춰 메모리 및 연산량 절감. |
| LoRA (Low-Rank Adaptation) | 1. 경량화 구조 (Lightweight Architecture) + 부분적 압축(PEFT) | 모델 전체를 학습하지 않고 저랭크 행렬만 추가 학습 → 구조적 경량화. 논문에서는 “parameter-efficient fine-tuning (PEFT) methods such as LoRA”를 lightweight adaptation 기법으로 분류함. |
| Adapter | 1. 경량화 구조 (Lightweight Architecture) | LoRA와 유사하게 모델 내부에 작은 모듈 추가해 효율적으로 학습/추론. 논문에서 “adapters and prefix-tuning as lightweight extensions for efficient inference”로 포함됨. |
| Sparse Attention / Linear Attention | 2. 어텐션 최적화 (Efficient Attention) | 입력 토큰 전체가 아니라 일부(혹은 근사) 토큰만 어텐션 → O(n²) → O(n log n) 또는 O(n). 예: Linformer, Longformer, Performer. |
| MoE (Mixture-of-Experts) | 4. 혼합 전문가 구조 (Mixture of Experts) | 여러 “전문가(서브모델)” 중 일부만 활성화 → 연산량 줄이면서 성능 유지. “MoE and sparse activation architectures for efficiency” |
“모델이 하는 연산량 자체를 줄이거나, 같은 연산량으로 더 많은 일을 하게 만드는 구조적 개선”
Section 6: 시스템 수준 최적화 (System-level Optimization)
여기서는 하드웨어/소프트웨어/시스템 설계 측면에서 LLM 추론을 더 효율적으로 만드는 접근:
- 배치처리(Batching) 및 병렬처리(Parallelism): 여러 요청을 묶어서 처리하거나 여러 연산을 동시다발적으로 처리해 처리량(throughput)을 향상하고 자원 활용을 극대화함.
- Batching/Prefill 병렬화: 여러 입력 요청을 묶어 GPU에 올리거나, Prefill 단계(입력 처리)를 병렬 수행하여 GPU 활용도 및 처리량 향상
- 메모리 관리 및 캐시(KV-cache, 메모리 단편화 등): 디코딩 과정에서 사용하는 키/값 캐시, 메모리 단편화 문제를 해결하여 디코딩 속도를 향상시키고, 중복 연산을 방지함
- KV Cache 재사용: 디코딩 중 반복되는 Key/Value 연산 결과를 캐싱하여 재활용 ⇒ 중복 계산 제거, 디코딩 속도 향상.
- KV Cache 재사용: 디코딩 중 반복되는 Key/Value 연산 결과를 캐싱하여 재활용 ⇒ 중복 계산 제거, 디코딩 속도 향상.
- 하드웨어 가속(Hardware accelerators): GPU, TPU, 특수 NPU에서 최적화된 커널(kernel) 사용 및 메모리 접근패턴 개선하여 하드웨어 수준에서 연산 효율을 개선함.
- Offloading/Paging: GPU 메모리에 다 안 들어가는 모델/캐시를 CPU 또는 디스크로 분산(offload) 시켜 관리하여 대형 모델을 효율적으로 실행 가능하게 함.
- 서비스 시스템 설계(Serving system design): 엔터프라이즈 환경이나 클라우드/엣지 배포에서 요청 스케줄링, 리소스 예측, 지연시간/처리량 균형 맞추기 → 실제 LLM 서비스의 안정성 및 효율성 확보
- Serving Optimization: 다수의 사용자 요청을 효율적으로 스케줄링,큐잉,우선순위를 처리하여 latency와 throughput 간 트레이드오프 조절.
“좋은 모델 설계만큼이나, 그것을 실제로 돌리는 시스템 환경이 중요하다”
