DRPruning: Efficient Large Language Model Pruning through Distributionally Robust Optimization(Deng et al., 2025) 논문 리뷰
- 특정 도메인의 성능 불균형을 막기 위한 Structured Pruning
1. Introduction
- LLM은 뛰어난 성능을 내지만 모델 크기가 커지고 연산량이 많아지는 단점이 있다. structured pruning을 통해 모델 크기를 줄이고 추론 속도를 올릴 수 있으나, 도메인(분야)이나 작업(task)이 다양한 데이터에 대해 프루닝 후 성능이 고르게 떨어지지 않고 특정 도메인에서 상대적으로 더 나빠지는 문제가 있다. (즉 프루닝 → 도메인 간 성능 불균형 → bias가 생긴다.)
- 이를 해결하기 위해 논문은 Distriubutionally Robust Optimization(DRO) 개념을 차용하여 “ Pruning + 다도메인 데이터 분포 변화: Dynamic data distribution)을 통해 모델이 만든 도메인에서 보다 균형 있게 성능을 회복하도록 하는 방법인 DRPruning을 제안한다.
Why is this important?
- LLM이 커질수록 비용,메모리, 연산 모두 커지고 “모델을 가볍게 하면서도 성능을 유지”하는 것이 실용적 중요성이 높다.
- 구조적 프루닝은 단순히 작은 모델을 만드는 방법이지만, 다양한 데이터 분포(도메인)에서 성능이 불균형하게 나빠지는 문제가 있다. 프루닝 후 모델이 A 도메인에선 괜찮지만 B 도메인에선 성능이 크게 떨어진다면, 실제 응용에서는 공정성, 일반화 등의 측면에서 문제가 된다.
- 본 논문은 이런 도메인 간 불균형을 해결하려는 시도로, 단순히 모델을 작게 만드는 것 이상으로 “데이터 분포를 조정하면서 프루닝” 한다는 점에서 차별성이 있다.
2. Backgroud
2.1 Structured Pruning
Pruning은 Neural Network 를 경량화 하고자 할 때 사용하는 방법.
연결된 모든 node를, parameter가 0에 가깝다거나 훈련을 거의 안 했다는 지표를 판단하여 pruning 한다.
- 구조적 프루닝(Structured Pruning): 모델의 일부 구조(예: 층(layer), 헤드(attention head), 중간 피드포워드 네트워크(ffn)의 hidden dimension 등)를 완전히 제거하거나 축소하는 방식이다. 이는 비구조적(unstructured) 프루닝(임의의 weight를 0으로 만드는 방식)보다 하드웨어 친화적일 수 있다. 논문에서는 Sheared Llama (Xia et al., 2024) 프루닝 방식을 기반으로 한다.
모델의 각 모듈(예: attention head, FFN channel)을 mask vector 로 제어
- 유지
- 제거
→ 이 mask vector 스위치를 학습으로 자동 조정해서 어떤 걸 살리고 어떤걸 자를지 스스로 결정하게 함
-
L0 정규화: 모듈 제거하라고 독려
- 더 많이 0으로 만들어 자르자라는 신호를 주는 벌칙이 L0 정규화
- 문제: mask vector Z 는 0/1뿐이어서 미분 불가
-
Hard- Concrete 분포: 부드러운 가짜 스위치
- 그래서 학습 중엔 0/1 대신 0과 1 사이를 오가는 “가짜 스위치(Hard-concrete)” 방법을 쓰고, 마지막에 진짜 0/1로 딱 결정을 내리는 트릭을 씀.
- 마스크를 매개변수화하기 위해 ℓ₀-regularization (Louizos et al., 2018) + hard concrete 분포(hard concrete distribution)를 사용함.
- 스위치 는 원래 0 또는 1
- 학습 중엔 (hard concrete gate)로 두고 미분/학습
- 손실 = 언어모델 손실 + L0 정규화.
- 학습 끝나면 로 딱 잘라냄
-
Lagrange multipliers 라그랑주 승수 적용
- 프루닝 후 목표 구조(target configuration)를 만족시키기 위해 라그랑주 승수를 적용
- 예를 들어 “이 층에 헤드 8개 중에 4개만 남겨” 같은 목표 개수가 있지만.
- 학습이 진행되면 스위치 합 이 4와 다를 수 있음
- 그래서 “목표와 다르면 벌점”을 주는 항을 손실에 추가 → 결국 정확히 4개 근처로 맞춰짐
- 프루닝 후 목표 구조(target configuration)를 만족시키기 위해 라그랑주 승수를 적용
- 최종적으로 모델 파라미터 θ 와 마스크 z 를 함께 최적화하는 손실(loss) 함수가 구성된다. 자세히 말하면
모델 언어모델링 손실 + 프루닝 제약 손실이 함께 최적화된다. - 요약하자면: 구조적 프루닝은 모델을 경량화하는 훌륭한 도구이지만, 그 자체로 도메인 간 성능 불균형 문제를 자동으로 해결하진 않는다.
2.2 분포론적 강건최적화 (Distributionally Robust Optimization, DRO)
DRO는 머신러닝 모델이 여러 가능한 데이터 분포(distribution) 중 “가장 불리한(worst-case)” 분포에 대해서도 잘 작동하게끔 설계하는 최적화 기법이다. 예컨대, 여러 그룹(group) 또는 도메인(domain)이 있다면 그 중 가장 성능이 떨어지는 그룹을 고려해 최적화하는 방식이다.
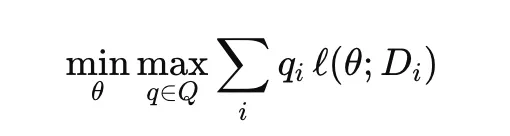
여기서 는 도메인 i의 데이터이고, 은 각 도메인에 할당된 가중치(weight)이다.
는 도메인 i의 손실,
는 가중치 벡터가 가질 수 있는 가능한 분포 집합이다.
→ 모델 θ를 바꿔서, worst-case 도메인도 불리하지 않게 성능이 떨어지는 것을 최소화 하자
- 이런 방식은 일반화(generalization)와 그룹 간 불균형(group imbalance) 문제를 완화하는 데 사용되어 왔다. 하지만 하이퍼파라미터(예: 참조 손실(reference loss), 기준 데이터 비율(reference data ratio) 등)를 적절히 설정하는 것이 어렵다는 문제가 있다.
3. Our Proposed DRPruning Method
3.1 Distributionally Robust Pruning
프루닝과 이어지는 사전학습(continued pretraining) 단계에 DRO를 통합한다.
- 먼저 프루닝을 통해 모델을 작게 만들고, 이어서 사전학습(또는 계속 학습) 단계를 통해 모델 성능을 회복시킨다. 이 과정에서 데이터가 여러 도메인에 걸쳐 있을 때, 도메인마다 회복 속도가 다르고 손실(loss)도 차이가 날 수 있다.
- 따라서 드러나는 문제: 프루닝 후 어떤 도메인은 빨리 회복하고, 어떤 도메인은 느리면 전체 모델은 도메인 간 격차가 커질 수 있다.
- 이를 막기 위해, DRPruning은 각 도메인의 평가 손실(validation loss 또는 evaluation loss) 를 이용해서 그 도메인이 얼마나 뒤처지는지를 추정하고, 그에 따라 “다음 학습 스텝에서 해당 도메인의 데이터를 더 많이 사용하도록(data proportion을 증가)” 하거나 가중치를 더 부여하는 방식으로 데이터 비율(q)과 손실 기준을 동적으로 조정한다.
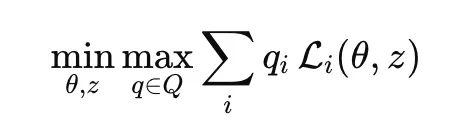
-
각 도메인 i에서 현재 손실 를 계산
-
손실이 참조값(reference loss) 보다 크면
→ 그 도메인의 데이터 비율 ↑ (더 공부시킴)
-
손실이 참조값보다 작으면
→ ↓ (덜 공부시킴)
이 과정을 반복하면서
모델은 잘린 상태에서도 모든 도메인에서 공평한 실력을 유지하게 됨
- θ: 모델 파라미터 (가중치)
- z: 어떤 부분을 남길지/자를지 결정하는 마스크
- qi: 각 도메인 데이터의 비율
- : i번째 도메인의 손실
즉, “마스크를 조정하면서 모델을 작게 만들되,
도메인 간 성능이 고르도록(손실이 균형잡히게) 학습하자”
3.2 참조 손실(Reference Loss) 및 예측
- 여기서는 “각 도메인이 이정도 손실(loss)을 가져야 한다”라는 참조 손실(reference loss, 등으로 표기됨) 개념을 도입한다.
- 이유: 단순히 ‘가장 손실이 큰 도메인’에 무작정 집중하면 자칫 모델이 특이 도메인에 과도하게 치우칠 수 있고, 학습이 불안정해질 수 있다. 따라서 각 도메인이 달성해야 할 ‘목표 손실치’(참조 손실)를 설정해두고, 그 손실에서 얼마나 벗어났는지에 따라 가중치 조정 및 데이터 비율 조정한다.
- 그런데 이 참조 손실을 사람이 일일이 설정하기 어렵고, 모델 크기, 데이터양, 학습 스텝 등에 따라 달라지기 때문에 본 논문에서는 스케일링 법칙(scaling laws) 을 이용해 “학습 끝나고 나면 손실이 이 정도일 것이다”라고 예측하고 그것을 참조 손실로 사용한다.
- 예컨대, 파라미터 수 및 학습 스텝 수 등이 주어졌을 때, 아래와 같은 형태로 손실이 감소할 것이라는 것을 가정을 두고 이를 참조 손실로 설정한다.
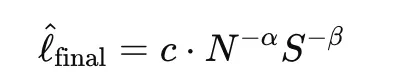
3.3 Dynamic Potential Distribution(동적 잠재 분포)
- 이 절은 데이터 비율(잠재 분포, potential distribution) 를 단순히 고정하거나 손실 기준만으로 바꾸는 것이 아니라, 점진적으로 도메인이 학습에서 뒤처질수록 이 도메인의 데이터 비율(reference data ratio)을 증가시키는 전략을 제시한다.
- 보다 구체적으로:
기존 DRO 방식은 가 가능한 모든 분포 집합안에 있다고 가정하고 최악의 경우에 대응하지만, 이는 지나치게 보수적(over-conservative)일 수 있고 결국 가장 나쁜 도메인만 집중 학습하게 될 수 있다. - 이를 보완하기 위해, 본 논문은 가 “어느 정도 참조 데이터 비율(reference data ratio) ” 주변의 -divergence ball 내에 있다고 가정한다.
- 그리고 학습이 진행됨에 따라, 만약 어떤 도메인이 손실이 크면 그 도메인의 참조 비율 를 조금씩 증가시켜 그 도메인 데이터 사용 비중을 높인다. 이렇게 하면 학습이 덜 된 도메인으로 자원을 점진적으로 옮겨갈 수 있다.
- 이런 방식으로 DRPruning은 프루닝된 모델이 다양하고 불균형한 도메인 분포에서도 균형 잡힌 성능(balanced performance) 을 갖게 하려 한다.
