출처1 :https://www.youtube.com/watch?v=9s_FpMpdYW8&list=PLkDaE6sCZn6Gl29AoE31iwdVwSG-KnDzF&index=30
출처2 : https://www.youtube.com/watch?v=O78V3kwBRBk&t=1898s
1. YOLO가 만들어지게 된 배경
-
객체 탐지는 이미지나 영상에서 특정 물체가 어디에 있는지와 그것이 무엇인지를 동시에 알아내는 기술입니다.
전통적으로는 R-CNN, Fast R-CNN 등의 기술이 주로 사용되었습니다.
하지만 이 기술들은 다음과 같은 단점이 있었습니다:- 느린 속도: 각 이미지에 대해 많은 계산이 필요하고, 여러 단계를 거쳐야 하므로 실시간 처리에 부적합했습니다.
- 복잡한 구조: 각 이미지에서 일일이 후보 영역을 탐지하고 그 후에 분류 작업을 수행해야 했기 때문에 구현이 복잡하고 비효율적이었습니다.
-
이를 해결하기 위해
YOLO(You Only Look Once)라는 기법이 등장했습니다.
YOLO는 이미지 전체를 한 번에 처리하여 객체를 탐지하는 방식으로, 속도와 정확도를 크게 향상시킨 혁신적인 방법입니다.
2. YOLO의 핵심 개념
- YOLO는 기존 객체 탐지 기법과는 다른 방식으로 이미지를 처리합니다.
그 핵심 개념은 "이미지를 한 번만 본다"는 것에 있습니다.
-
이미지 그리드로 나누기:
YOLO는 입력 이미지를 여러 개의 격자(grid)로 나눕니다. -
각 그리드에서 객체 탐지:
각 격자 셀은 그 안에 객체가 있는지 없는지를 판단하고, 객체가 있다면 그 객체의 경계 상자(bounding box)와 클래스(사람, 자동차, 개 등)를 예측합니다. -
예측 값 출력: YOLO는 각 격자에 대해 다음과 같은 정보를 예측합니다:
- Bounding Box: 객체의 위치와 크기를 나타내는 4개의 값 (x, y, w, h).
- Confidence Score: 해당 그리드에 객체가 있을 확률.
- Class Prediction: 객체가 어떤 종류인지(예: 사람, 자동차 등) 예측.
- 실시간 처리 가능: YOLO의 큰 장점은 이미지 전체를 한 번만 보고 모든 예측을 동시에 수행하기 때문에 매우 빠르다는 점입니다. 이는 실시간 객체 탐지에 적합합니다.
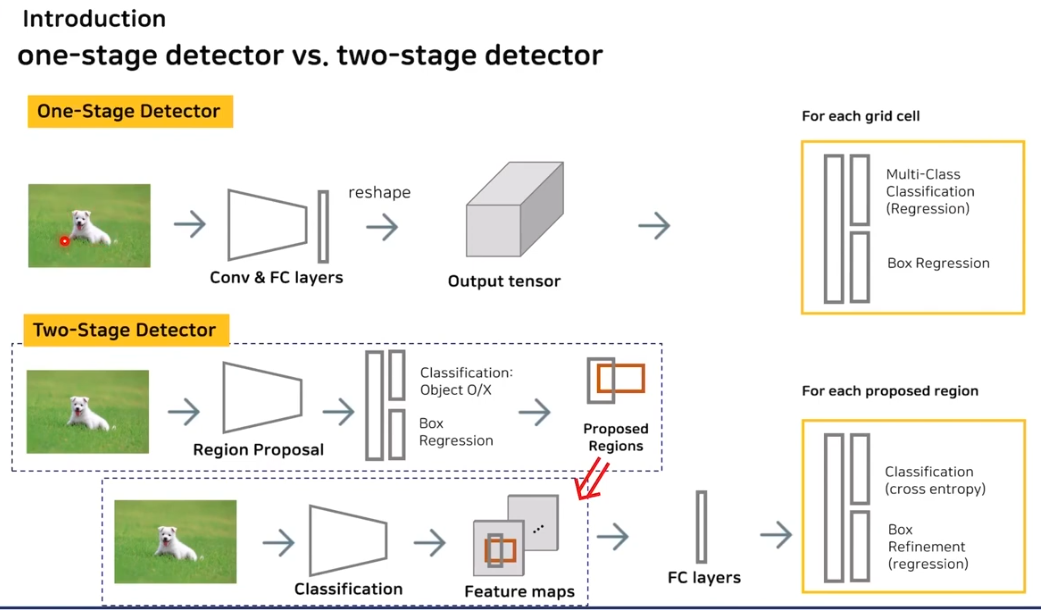
2-1. YOLO의 1스테이지(One-Stage) vs 2스테이지(Two-Stage) 탐지 방식
-
YOLO가 등장하기 전에는 주로 2-스테이지 방식의 객체 탐지 방법이 사용되었습니다. 이 방식의 대표적인 예로는 R-CNN, Fast R-CNN, Faster R-CNN 같은 모델들이 있습니다.
-
2-스테이지 방식:-
1단계: 후보 영역 추출 (Localization)
먼저 이미지에서 객체가 있을 법한 여러 후보 영역을 추출합니다.
이 과정에서 Region Proposal Network(RPN)과 같은 기법을 사용해 이미지의 여러 위치를 탐색합니다. -
2단계: 객체 분류 및 위치 조정 (Classification)
추출된 후보 영역을 기반으로, 해당 영역 안에 어떤 객체가 있는지 분류하고, 객체의 경계 상자(bounding box) 좌표를 보다 정밀하게 조정합니다. -
이 과정은 비교적 복잡하고 계산량이 많기 때문에 실시간 처리가 어렵다는 단점이 있습니다.
-
-
YOLO의
1-스테이지 방식:-
반면, YOLO는 1-스테이지 방식으로 동작합니다.
이는 이미지 전체를 한 번에 처리하여 후보 영역 추출과 객체 분류를 동시에 수행하는 방식입니다. -
이미지를 격자로 나눈 후, 각 격자에서 객체가 있을 확률을 계산합니다.
그리드에서 각 객체의 경계 상자(bounding box)를 예측하고, 동시에 객체의 클래스를 분류합니다. -
이 과정은 한 번의 연산으로 이루어지기 때문에 속도가 매우 빠르며, 실시간 처리에 적합합니다.
YOLO는 "You Only Look Once", 즉 "한 번만 본다"는 이름처럼 이미지 전체를 한 번에 처리하여 객체 탐지를 빠르게 수행합니다.
-
Process
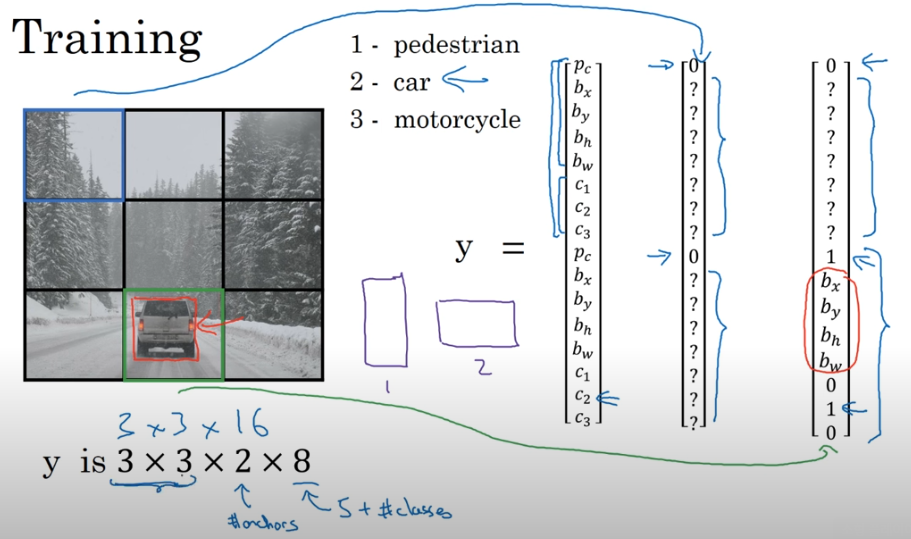
- 어떻게 훈련 세트를 구성하는지 살펴보기
보행자 / 차 / 오토바이 세 가지 물체를 검출하는 알고리즘을 훈련한다고 가정
- 두 개의 앵커박스를 사용한다면, y = (3, 3, 2, 8) 의 shape을 갖는다
- 가로 격자, 세로 격자, 앵커 박스 개수, 차원
- 여기서 차원은 Pc, bx, by, bh, bw + class 3개 = 8 이다
- 9개의 cell 에서 나머지 8개는 어떠한 객체도 없기에 y 가 밑의 사진에 보이는 것과 같이 표현된다
- 자동차가 있는 cell 에서는 차의 가로폭이 더 길기에, 앵커 박스 2에 해당하는 변수들에 값을 대입해준다
- 최종 결과는 3x3x16의 부피를 갖게된다
- 앵커박스의 수가 많아지거나, cell의 수가 많아진다면 부피는 달라지게 됨
ex) 19x19x5x8 / 19x19x2x8
- 앵커박스의 수가 많아지거나, cell의 수가 많아진다면 부피는 달라지게 됨
- 여기서 Pc 가 0이라면, 신경망 내에서는 그 밑의 bounding box 변수들과 클래스의 변수는 노이즈 처리되어 계산이 된다
즉, conv 신경망은 100x100x3의 이미지를 입력값으로 받아서 3x3x16 같은 결과를 도출해낸다

다른 예시
-
각 격자 셀에서 2개의 bounding boxes가 생김

-
낮은 확률 예측 제거

-
NMS 를 실행하여 최종 검출

객체 탐지에 대한 많은 아이디어들을 모두 포함시킨 것이 yolo이다.
