참고 : https://pseudo-lab.github.io/Tutorial-Book/chapters/object-detection/Ch1-Object-Detection.html
객체탐지(Object Detection)란?
객체 탐지(obeject detection)는 이미지나 영상에서 특정 객체를 식별하고, 그 위치와 종류를 파악하는 기술입니다.- 이는 단순히 이미지에 무엇이 있는지 알려주는 분류(Classification)와는 달리, 객체의 존재 여부뿐만 아니라 위치 정보까지 제공합니다.
1. Object Localization (객체의 위치 탐지)
Object Localization은 객체 탐지의 첫 번째 단계입니다.
이미지 내에서 객체의 위치를 찾아내는 과정으로, 객체의 중심이나 영역을 표시하는 Bounding Box(바운딩 박스)를 그리는 것을 말합니다.
Localization이란 단어 그대로 "어디에 있는지"를 찾는 것이 중요하며, 어떤 객체가 어느 위치에 있는지를 알아내는 것이 주요 목표입니다.

1-1. Bounding Box (바운딩 박스)
Bounding Box는 이미지 내에서 객체를 감싸는 직사각형의 박스입니다.
객체 탐지에서는 각 객체의 좌표를 통해 바운딩 박스를 그려 객체의 위치를 나타냅니다.
예를 들어, 고양이가 있는 이미지를 탐지한다면, 고양이를 둘러싼 직사각형이 생성되며, 이를 통해 컴퓨터가 고양이의 위치를 인식하게 됩니다.
바운딩 박스의 두 가지 표현 방식
-
좌상단(x_min, y_min)과 우하단(x_max, y_max) 좌표 방식:
왼쪽 위 모서리의 좌표 (x_min, y_min)
오른쪽 아래 모서리의 좌표 (x_max, y_max)
이 방식은 이미지의 절대 좌표를 기준으로 박스를 정의하는 방법입니다. -
중심점 좌표 (cx, cy)와 너비(width), 높이(height) 방식:
바운딩 박스의 중심점 좌표 (cx, cy)
바운딩 박스의 너비 width와 높이 height
이 방식은 박스의 중심을 기준으로 박스의 크기(너비와 높이)를 정의하는 방법입니다.- 이 방식은 객체 탐지 모델에 따라 사용되는 표현 방식이 달라질 수 있습니다.
예를 들어,YOLO(You Only Look Once)와 같은 모델에서는 중심점 좌표와 박스의 너비/높이로 바운딩 박스를 정의하는 것이 일반적입니다.
반면, R-CNN 계열의 모델에서는 좌상단과 우하단 좌표를 사용하는 경우도 있습니다.
- 이 방식은 객체 탐지 모델에 따라 사용되는 표현 방식이 달라질 수 있습니다.

[출처 : https://pseudo-lab.github.io/Tutorial-Book/chapters/object-detection/Ch1-Object-Detection.html ]
1-2. Intersection Over Union (IoU)
-
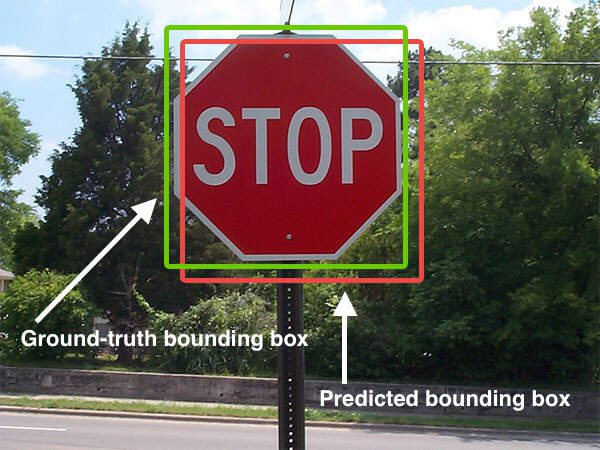
Bounding Box가 생성되면, 그 위치가 얼마나 정확한지를 평가하는 방법이 필요합니다.
그때 사용되는 것이 바로Intersection Over Union (IoU)입니다. -
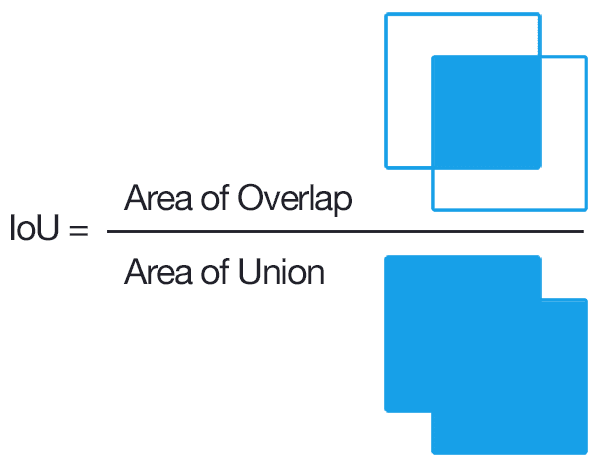
IoU는 예측된 바운딩 박스와 실제 객체가 존재하는 영역(정답 바운딩 박스)이 얼마나 겹치는지를 계산하는 값입니다.
이 값은 0에서 1 사이의 값을 가지며, 1에 가까울수록 예측이 정확한 것입니다.
-
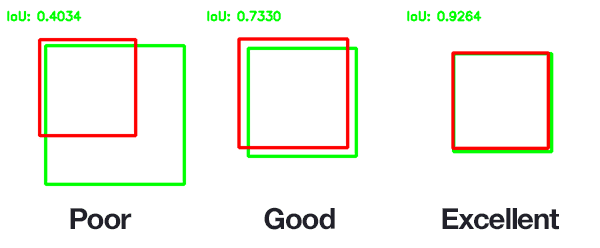
IoU는 0에서 1까지의 값을 가지며, 1에 가까울수록 두 바운딩 박스가 일치하는 것입니다.
모델의 성능을 평가할 때, 일반적으로 IoU가 0.5 이상일 경우 객체가 잘 탐지되었다고 판단하지만, 이 임계값 설정은 상황에 따라 조정될 수 있습니다.
너무 높게 설정하면 일부 객체를 놓칠 위험이 있고, 너무 낮게 설정하면 불필요한 바운딩 박스가 많이 남을 수 있습니다.
2. 객체를 탐지하기 위한 방법
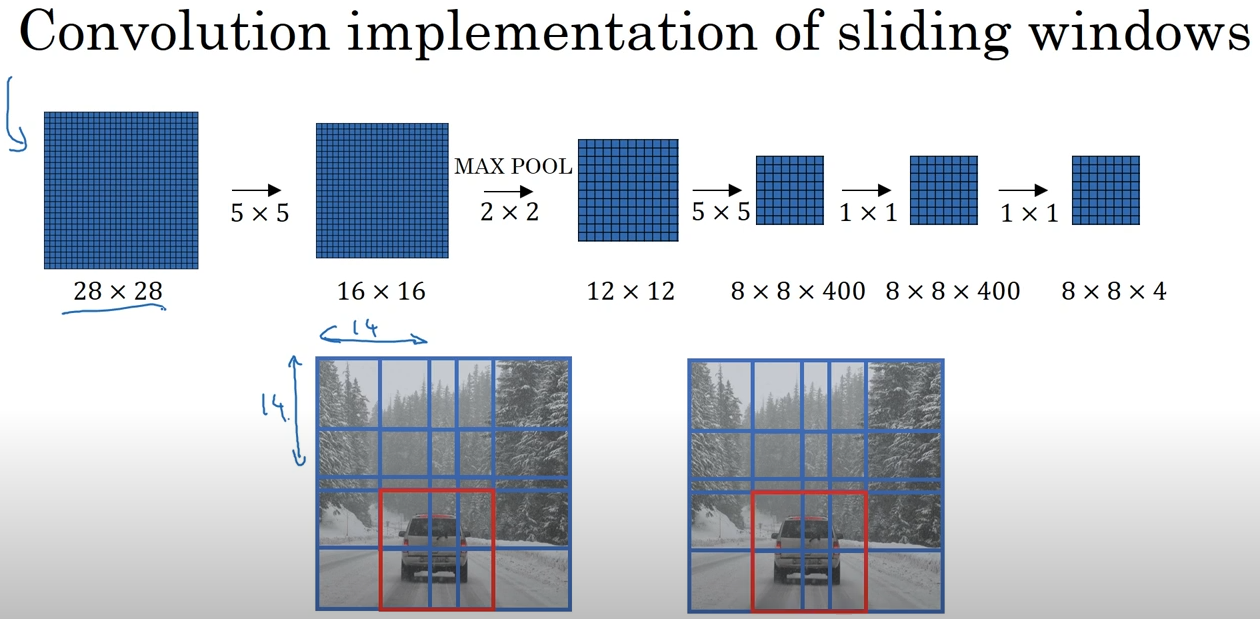
2-1. Sliding Window 방식
-
Sliding Window는 초기 객체 탐지 방식으로, 이미지 내의 작은 영역을 일정 간격으로 이동시키며 해당 영역에 객체가 있는지를 검사하는 방법입니다.
이 방식에서는 다양한 크기의 윈도우를 사용해, 이미지를 일일이 스캔하면서 객체를 탐지합니다. -
한계점:
- 계산 비용이 매우 큽니다.
- 비효율성: 이미지에서 중요한 영역만 선택할 수 없었습니다.
- 객체 크기의 다양성 처리 부족: 다양한 크기의 객체를 처리하기 위해 윈도우 크기를 여러 번 바꿔야 해서 시간이 많이 소요되었습니다.

2-2. Convolutional Neural Networks (CNN)의 도입
참고 : https://www.youtube.com/watch?v=XdsmlBGOK-k&list=PLkDaE6sCZn6Gl29AoE31iwdVwSG-KnDzF&index=26
- CNN은 객체 탐지 문제에서 크게 두 가지 개선을 가져왔습니다:
- 특징 추출의 자동화:
CNN은 이미지에서 의미 있는 특징(엣지, 패턴 등)을 필터를 통해 자동으로 학습합니다.
이는 Sliding Window처럼 직접적으로 모든 영역을 탐지하는 대신, 학습된 필터로 중요한 특징을 인식하는 방식입니다. - 계산 비용 절감:
CNN의 컨볼루션 연산은 필터를 이용해 이미지를 효율적으로 처리하므로, Sliding Window 방식보다 훨씬 빠르고 효과적입니다.
- CNN 기반 방법의 한계:
객체 위치를 정확하게 예측하는 데 어려움이 있었습니다.
CNN은 이미지를 작은 특징맵으로 줄이면서 특징을 추출하기 때문에, 정확한 좌표 예측이 어려운 문제가 발생했습니다.
CNN만으로는 다양한 크기의 객체나 위치를 효과적으로 탐지할 수 없었습니다.
2-3. Non-Maximum Suppression (NMS)
참고 : https://www.youtube.com/watch?v=VAo84c1hQX8&list=PLkDaE6sCZn6Gl29AoE31iwdVwSG-KnDzF&index=28
-
NMS는 중복된 바운딩 박스를 제거하여 객체 탐지의 정확도를 높이는 중요한 역할을 합니다.
-
지금까지 객체 감지의 문제점:
알고리즘이 같은 물체를 여러 번 감지해서 어떤 물체를 한 번이 아니라 여러 번 감지할 수도 있음 -
NMS 는 알고리즘이 각 물체를 한 번씩만 감지하게 보장한다.

-
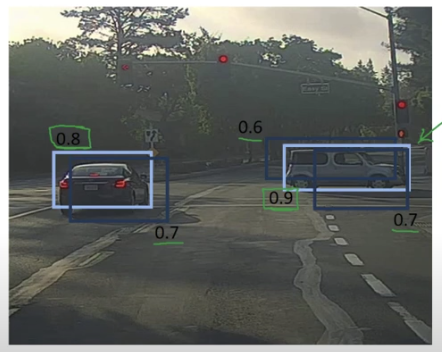
위의 사진에서 자동차를 탐지할 때, 각각의 셀은 자동차를 찾았다고 생각할 것이다.
-
여기서 NMS가 어떻게 작동하는지 살펴보자.

-
이런식으로각 물체마다 여러 개가 감지될 수 있는데, NMS 는 감지된 것을 정리하는 것이다.
- 여기서 감지확률이 가장 큰 값을 살펴보면 0.9이다
- 그러면 해당 바운딩 박스를 강조하고, NMS가 그 직사각형과 가장 많이 겹치는 (즉, IOU가 가장 높은) 직사각형들을 억제시킨다.
- 그러면 0.6, 0.7의 바운딩 박스는 억제된다.
- 다음으로 가장 높은 감지확률을 살펴보면 왼쪽 차의 0.8이다.
- 위와 동일한 과정으로 NMS를 적용시켜 겹치는 직사각형들을 억제시킨다.
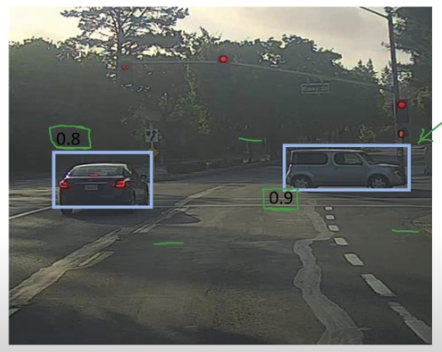
- 즉 NMS 란 확률(Pc)의 최댓값을 도출하고, 최댓값이 아닌 것들을 억제한다는 의미이다.
2.4 Anchor Boxes
지금까지 객체 감지의 문제점 : 각각의 격자 셀이 오직 하나의 물체만 감지할 수 있는가?
-> 만약 격자셀이 여러 개의 물체를 감지하고 싶다면 어떻게 해야할까?
-> 보행자와 자동차의 중심점이 거의 같은 위치에 있으며 같은 격자 셀에 존재함

-
Anchor Boxes는 이미지를 고정된 그리드로 나누고, 각 그리드 셀마다 다양한 비율과 크기를 가지는 박스(Anchor Boxes)를 미리 설정한 후, 이 박스를 기반으로 객체를 탐지하는 방식입니다. -
이 방법을 사용한 이유:
- 객체의 다양한 크기와 비율을 처리하기 위해:
객체는 이미지 속에서 크기나 비율이 매우 다양할 수 있습니다.
Anchor Boxes는 다양한 비율과 크기를 미리 설정해 두고, 해당 위치에 어떤 객체가 있을지 예측하는 방식을 사용하여 이를 해결했습니다. - 효율적인 탐지:
Anchor Boxes는 미리 정의된 고정된 박스들로 모든 위치를 한번에 탐색할 수 있기 때문에, 이전 방식보다 훨씬 빠릅니다.
예시

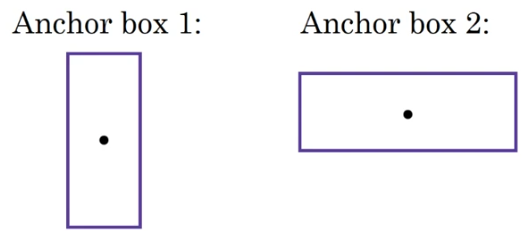
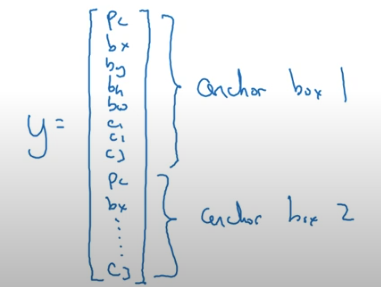
- 위 사진에서 앵커 박스 (Anchor Boxes) 2개를 가지고 두 예측을 결합하기
( 더 많은 앵커박스를 사용할 수 있지만 여기서는 2개만 사용)
원래는 격자 셀에서 y 가 보행자, 자동차, 오토바이의 세 클래스를 감지하는 벡터를 도출한다고 하면 두 개의 감지 모두 출력하는 것은 불가능하다.
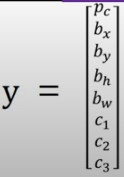
따라서 위의 벡터 대신 아래와 같은 벡터를 사용한다.
(앵커박스 1에 대한 결과 값과, 앵커박스 2에 대한 결과값을 반복하기)
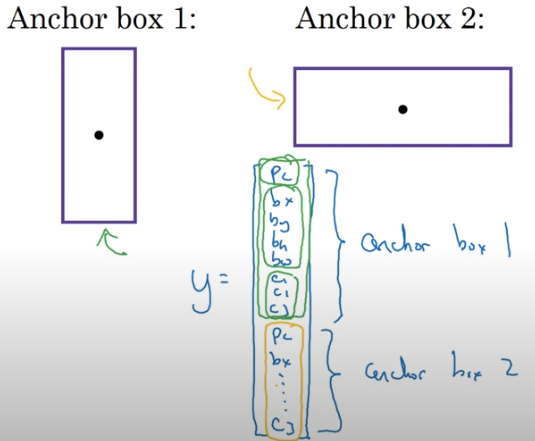
여기서 보행자의 모양이 앵커박스 2보다 앵커박스 1과 더 비슷하기 때문에 8개의 숫자를 사용해서 부호화 한다.
- Pc 는 보행자가 있음을 의미하고
- bx, by, bw, bh는 보행자를 둘러싼 박스를 부호화 하며
- c1,c2,c3는 물체가 보행자라는 것을 부호화 한다.
- 자동차를 둘러싼 바운딩 박스는 앵커박스 2와 비슷하기에 위와 같은 방법을 통해 부호화한다.
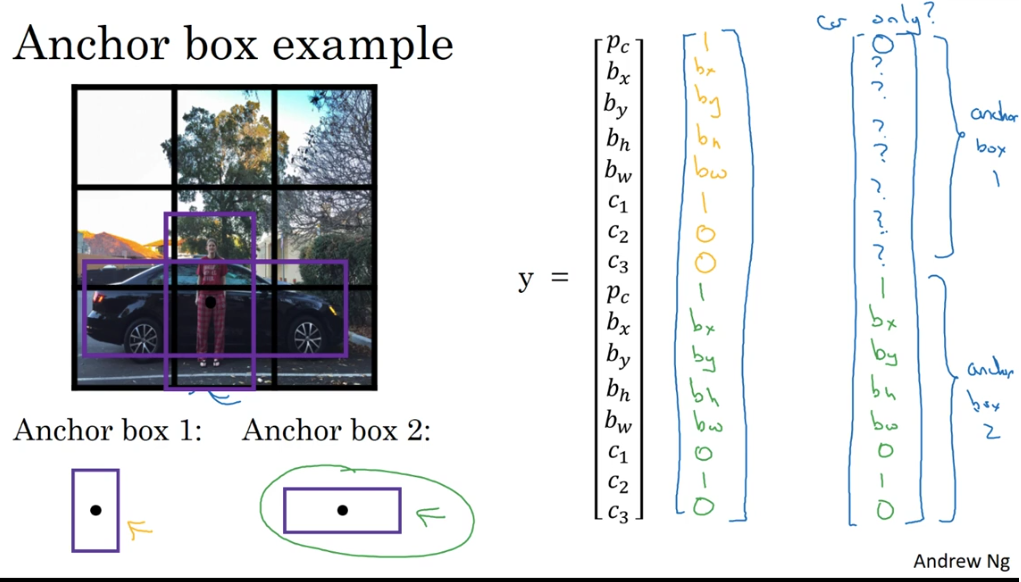
- 셀에 차만 존재한다면 보행자가 있을 확률인 Pc를 0으로 하고 나머지는 신경쓰지 않는다.
그리고 앵커박스 2에 대한 값에는 위 사진과 같이 Pc 에 1과, c2가 자동차를 의미하므로 1을 대입해준다.
