참고1 : https://www.youtube.com/watch?v=em_lOAp8DJE
참고2 : https://public.roboflow.com/
1. 데이터 준비
-
YOLO v8 을 사용하여 학습하기 위한 커스텀 데이터는 어떤 것을 사용해도 괜찮지만, 이미지 데이터와 정답 데이터가 함께 제공되는 Roboflow( https://public.roboflow.com/ ) 사이트에서 데이터셋을 다운받아 사용하는 것이 좋다.
-
실습에 사용될 데이터는 다음 링크에서 다운받았다
https://universe.roboflow.com/brad-dwyer/aquarium-combined/dataset/6# -
실습 환경 : COLAB
2. 데이터 다운로드 및 확인 작업
# 데이터 다운로드
# !wget은 파일을 인터넷에서 다운로드할 때 사용하는 리눅스 언어이다.
# 앞에 !를 붙이면 코랩에서 리눅스 명령어 실행가능
# -O ~는 다운로드한 파일을 특정 이름으로 저장하는 옵션이다.
# 주소명 : 데이터를 다운로드 할 URL 이다.
!wget -O Aquarium_Data.zip https://universe.roboflow.com/ds/vkq9OQq7Ju?key=kWlaRqt2gg- 데이터 압축풀기
# ZIP파일 열기 및 압축 해제
# 파일을 열어 target_file이라는 객체로 사용
# extractall 은 ZIP파일에 있는 모든 파일을 지정한 폴터 Aquarium_Data에 압축 해체하는 함수.
import zipfile
with zipfile.ZipFile('Aquarium_Data.zip') as target_file:
target_file.extractall('Aquarium_Data')
- YAML파일 확인해보기
YAML 이란?
- YAML(Yet Another Markup Language 또는 YAML Ain't Markup Language)은 데이터 직렬화 형식 중 하나로, 사람이 읽기 쉽고 작성하기 쉬운 방식으로 데이터를 표현할 수 있게 만든 언어입니다.
주로 구성 파일이나 데이터 저장에 많이 사용되며, 특히 파이썬과 같은 프로그래밍 언어와의 호환성이 좋습니다.- 예시
train: /content/train val: /content/val nc: 3 # 클래스 수 names: ['fish', 'jellyfish', 'shark']- `train`: 훈련 데이터의 경로를 나타냅니다. `val`: 검증 데이터의 경로를 나타냅니다. `nc`: 탐지할 클래스의 수를 나타냅니다. `names`: 클래스 이름 리스트로, 이 경우 'fish', 'jellyfish', 'shark' 세 가지를 탐지하도록 설정됩니다.
# !cat: cat은 리눅스 명령어로, 파일의 내용을 출력하는 명령입니다. 이 또한 !를 붙여서 Colab에서 리눅스 명령어를 실행하는 형태입니다.
# /content/Aquarium_Data/data.yaml: data.yaml 파일은 YOLO 모델 학습 시 데이터를 정의하는 설정 파일입니다.
# 이 파일에는 훈련 및 검증 데이터의 경로, 클래스 수, 클래스 이름 등이 포함되어 있습니다. 이 경로에서 해당 파일을 읽어와 내용을 출력하는 역할을 합니다.
!cat /content/Aquarium_Data/data.yaml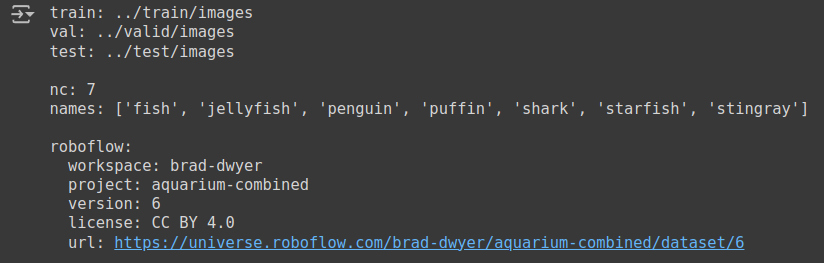
3. 커스텀 데이터에 맞는 YAML 파일 만들기
- 다운받은 데이터가 저장된 디렉토리를 변경해주어야 한다.
- 코랩을 사용하고 있기에, train/ valid/ test 디렉토리를 커스텀 해주어야 함
- 학습 데이터의 경로를 코랩의 절대경로로 지정해주어야함
# 커스텀 데이터에 맞는 YAML 파일을 만들어주여야 한다.
# YOLO8 학습과 검증에 필요한 train, valid 데이터의 디렉토리 경로와 Detection 하고 싶은 클래스 개수, 그리고 해당 클래스의 이름이 저장되어 있는 YAML파일을 반드시 만들어야함
!pip install PyYAMLimport yaml
# YOLO8 학습과 검증에 사용되는 train, valid 가 저장되어 있는 디렉토리 경로
data = {'train': '/content/Aquarium_Data/train/images/',
'val': '/content/Aquarium_Data/valid/images/',
'test': '/content/Aquarium_Data/test/images/',
'names': ['fish', 'jellyfish', 'penguin', 'puffin', 'shark', 'starfish', 'stingray'], # Detection 하고 싶은 클래스 개수와 클래스에 대응되는 클래스 이름
'nc': 7}
# 데이터 경로와 클래스 정보를 저장하고 있는 딕셔너리 객체 data를 YOLO8 학습에 필요한 Aquarium_Data.yaml에 저장
with open('/content/Aquarium_Data/data.yaml', 'w') as f:
yaml.dump(data, f)
# Aquarium_Data.yaml 읽어서 화면에 출력하기
with open('/content/Aquarium_Data/data.yaml', 'r') as f:
aquarium_data = yaml.safe_load(f)
display(aquarium_data)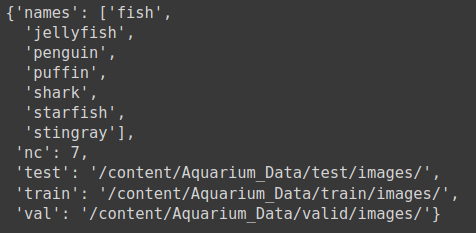
4. yolo에 필요한 라이브러리 설치 및 모델 로드
- ultralytics 라이브러리 다운로드
!pip install ultralytics
import ultralytics
ultralytics.checks()- Load a pre-trained model
# 이미 학습된 모델을 로드하기
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # MS COCO Dataset 사전학습된 yolov8n (나노) 모델을 로드
# 이 외에도, yolov8s, yolov8m, yolov8l, yolov8x 등이 있음
# YOLOv8은 MS COCO 데이터로 사전 학습되어 있기 때문에, MS COCO Dataset에 정의되어 있는 클래스 개수와 종류는 model.names를 통해 확인하기
print(type(model.names), len(model.names))
print(model.names)
5. YOLOv8 커스텀 데이터 학습하기
중요
- 앞서 커스텀한 yaml 데이터 파일을 학습 모델에 data 파라미터로 지정해야함
model.train(data= '/content/Aquarium_Data/data.yaml', epochs = 30, patience = 30, batch = 32, imgsz = 416)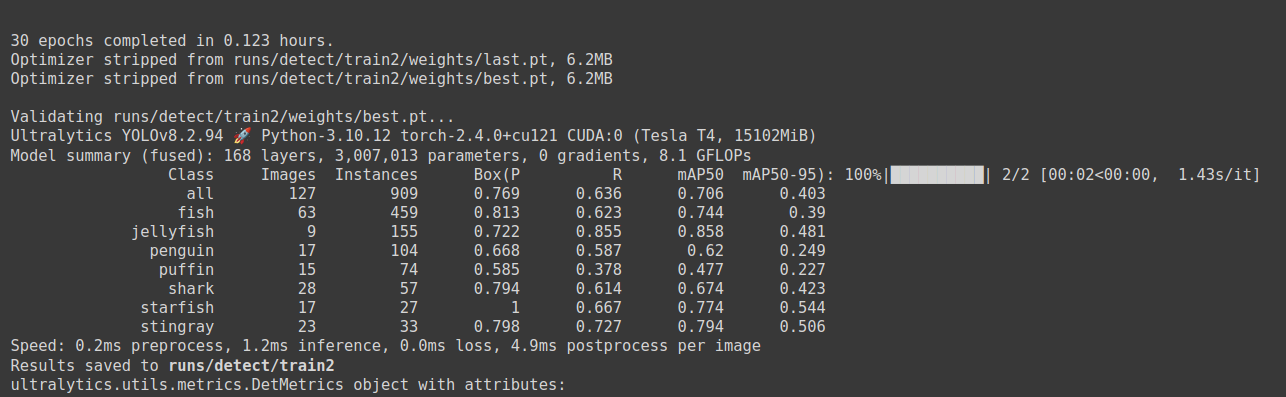
- Results 를 살펴보면, 커스텀 데이터로 학습된 모델, 즉 best.pt가 저장된 디렉토리를 확인할 수 있다
# 여기서는 data.yaml 에 기술되어 있는 커스텀 데이터로 학습되었기 때문에, 학습을 마친 후에 model.names 값을 보면
# 사전 학습된 MS COCO 데이터의 80개가 아닌 우리가 작성한 파일에서 설정한 7개의 클래스와 이름으로 바뀌어 있는 것을 알 수 있다.
print(type(model.names), len(model.names))
print(model.names)
6. 학습된 YOLOv8을 이용해서 테스트 이미지 예측
# 테스트 이미지를 사용하여 학습된 모델 확인하기
# 테스트 이미지가 저장되어 있는 디렉토리를 설정하기
results = model.predict(source = '/content/Aquarium_Data/test/images/', save = True)

- Results 에 있는 디렉토리로 이동하여 결과 확인해보기



